单表查询
单表查询语法:
select distinct 字段1,字段2,字段3 from 库.表
where 条件
group by 分组条件
having 过滤
order by 排序字段
limit n;关键字执行顺序(重点)
1、from
2、where
3、group by
4、having
5、select
7、distint
8、order by
9、limit
1.找到表:from
2.拿着where指定的约束条件,去文件/表中取出一条条记录
3.将取出的一条条记录进行分组group by,如果没有group by,则整体作为一组
4.将分组的结果进行having过滤
5.执行select
6.去重
7.将结果按条件排序:order by
8.限制结果的显示条数
where约束
where字句中可以使用:
- 比较运算符:><>= <= <> !=
- between 80 and 100 值在10到20之间
- in(80,90,100) 值是10或20或30
- like 'egon%'
pattern可以是%或_,
%表示任意多字符
_表示一个字符 - 逻辑运算符:在多个条件直接可以使用逻辑运算符 and or not
#1:单条件查询
SELECT name FROM employee
WHERE post='sale';
#2:多条件查询
SELECT name,salary FROM employee
WHERE post='teacher' AND salary>10000;
#3:关键字BETWEEN AND
SELECT name,salary FROM employee
WHERE salary BETWEEN 10000 AND 20000;
SELECT name,salary FROM employee
WHERE salary NOT BETWEEN 10000 AND 20000;
#4:关键字IS NULL(判断某个字段是否为NULL不能用等号,需要用IS)
SELECT name,post_comment FROM employee
WHERE post_comment IS NULL;
SELECT name,post_comment FROM employee
WHERE post_comment IS NOT NULL;
SELECT name,post_comment FROM employee
WHERE post_comment=''; 注意''是空字符串,不是null
ps:
执行
update employee set post_comment='' where id=2;
再用上条查看,就会有结果了
#5:关键字IN集合查询
SELECT name,salary FROM employee
WHERE salary=3000 OR salary=3500 OR salary=4000 OR salary=9000 ;
SELECT name,salary FROM employee
WHERE salary IN (3000,3500,4000,9000) ;
SELECT name,salary FROM employee
WHERE salary NOT IN (3000,3500,4000,9000) ;
#6:关键字LIKE模糊查询
通配符’%’
SELECT * FROM employee
WHERE name LIKE 'eg%';
通配符’_’
SELECT * FROM employee
WHERE name LIKE 'al__';group by分组查询
一 什么是分组?为什么要分组?
#1、首先明确一点:分组发生在where之后,即分组是基于where之后得到的记录而进行的
#2、分组指的是:将所有记录按照某个相同字段进行归类,比如针对员工信息表的职位分组,或者按照性别进行分组等
#3、为何要分组呢?
取每个部门的最高工资
取每个部门的员工数
取男人数和女人数
小窍门:‘每’这个字后面的字段,就是我们分组的依据
#4、大前提:
可以按照任意字段分组,但是分组完毕后,比如group by post,只能查看post字段,如果想查看组内信息,需要借助于聚合函数** ONLY_FULL_GROUP_BY**
#查看MySQL 5.7默认的sql_mode如下:
mysql> select @@global.sql_mode;
ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
#!!!注意
ONLY_FULL_GROUP_BY的语义就是确定select target list中的所有列的值都是明确语义,简单的说来,在ONLY_FULL_GROUP_BY模式下,target list中的值要么是来自于聚集函数的结果,要么是来自于group by list中的表达式的值。
#设置sql_mole如下操作(我们可以去掉ONLY_FULL_GROUP_BY模式):
mysql> set global sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION';
!!!SQL_MODE设置!!!
mysql> select @@global.sql_mode;
+-------------------+
| @@global.sql_mode |
+-------------------+
| |
+-------------------+
row in set (0.00 sec)
mysql> select * from emp group by post;
+----+------+--------+-----+------------+----------------------------+--------------+------------+--------+-----------+
| id | name | sex | age | hire_date | post | post_comment | salary | office | depart_id |
+----+------+--------+-----+------------+----------------------------+--------------+------------+--------+-----------+
| 14 | 张野 | male | 28 | 2016-03-11 | operation | NULL | 10000.13 | 403 | 3 |
| 9 | 歪歪 | female | 48 | 2015-03-11 | sale | NULL | 3000.13 | 402 | 2 |
| 2 | alex | male | 78 | 2015-03-02 | teacher | NULL | 1000000.31 | 401 | 1 |
| 1 | egon | male | 18 | 2017-03-01 | 老男孩驻沙河办事处外交大使 | NULL | 7300.33 | 401 | 1 |
+----+------+--------+-----+------------+----------------------------+--------------+------------+--------+-----------+
rows in set (0.00 sec)
#由于没有设置ONLY_FULL_GROUP_BY,于是也可以有结果,默认都是组内的第一条记录,但其实这是没有意义的
mysql> set global sql_mode='ONLY_FULL_GROUP_BY';
Query OK, 0 rows affected (0.00 sec)
mysql> quit #设置成功后,一定要退出,然后重新登录方可生效
Bye
mysql> use db1;
Database changed
mysql> select * from emp group by post; #报错
ERROR 1055 (42000): 'db1.emp.id' isn't in GROUP BY
mysql> select post,count(id) from emp group by post; #只能查看分组依据和使用聚合函数
+----------------------------+-----------+
| post | count(id) |
+----------------------------+-----------+
| operation | 5 |
| sale | 5 |
| teacher | 7 |
| 老男孩驻沙河办事处外交大使 | 1 |
+----------------------------+-----------+
rows in set (0.00 sec)
** GROUP BY**
单独使用GROUP BY关键字分组
SELECT post FROM employee GROUP BY post;
注意:我们按照post字段分组,那么select查询的字段只能是post,想要获取组内的其他相关信息,需要借助函数
GROUP BY关键字和GROUP_CONCAT()函数一起使用
SELECT post,GROUP_CONCAT(name) FROM employee GROUP BY post;#按照岗位分组,并查看组内成员名
SELECT post,GROUP_CONCAT(name) as emp_members FROM employee GROUP BY post;
GROUP BY与聚合函数一起使用
select post,count(id) as count from employee group by post;#按照岗位分组,并查看每个组有多少人
强调:
如果我们用unique的字段作为分组的依据,则每一条记录自成一组,这种分组没有意义
多条记录之间的某个字段值相同,该字段通常用来作为分组的依据
** 聚合函数**
强调:聚合函数聚合的是组的内容,若是没有分组,则默认一组
max:最大值
min:最小值
avg:平均值
sum:求和
示例:
SELECT COUNT(*) FROM employee;
SELECT COUNT(*) FROM employee WHERE depart_id=1;
SELECT MAX(salary) FROM employee;
SELECT MIN(salary) FROM employee;
SELECT AVG(salary) FROM employee;
SELECT SUM(salary) FROM employee;
SELECT SUM(salary) FROM employee WHERE depart_id=3;多表查询
多表查询分为以下几种:
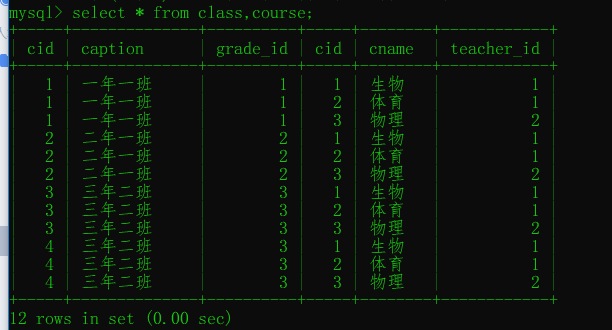
交叉连接:不适用任何匹配条件。生成笛卡尔积
内连接:只连接匹配的行
外链接之左连接:优先显示左表全部记录
外链接之右连接:优先显示右表全部记录
全外连接:显示左右两个表全部记录
#重点:外链接语法
SELECT 字段列表
FROM 表1 INNER|LEFT|RIGHT JOIN 表2
ON 表1.字段 = 表2.字段;交叉连接:不适用任何匹配条件。生成笛卡尔积
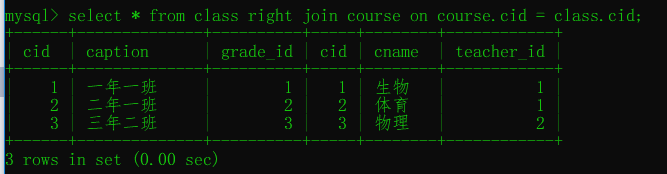
内连接:只取两张表的共同部分

左连接:在内连接的基础上保留左表的记录

右连接:在内连接的基础上保留右表的记录
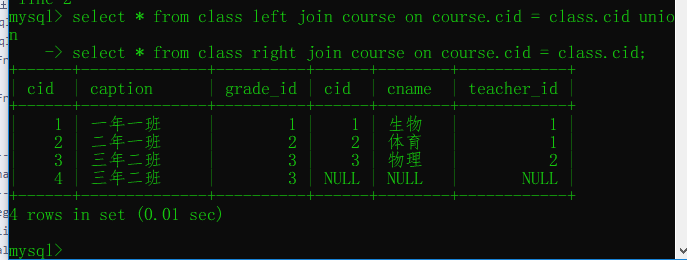
全外连接:在内连接的基础上保留左右两表没有对应关系的记录
#注意:mysql不支持全外连接 full JOIN
#强调:mysql可以使用此种方式间接实现全外连接
select * from employee left join department on employee.dep_id = department.id
union
select * from employee right join department on employee.dep_id = department.id
;