最早出现的问题情况是提供es的部门在es的外部封装了一个gateway做请求中转。
当我们转换到gateway上之后,发现了问题:
有的请求可以获取到数据,有的请求获取不到数据。
仔细分析了业务代码,抽取了一个出问题的业务请求,这个业务请求里面包含了多次对es的请求,只有最后一个es请求抛出异常,其他都正常。
ps: 我们的业务是使用php写的,使用了https://github.com/elastic/elasticsearch-php这个包进行es请求的。
初步分析
当然,我们没有把错误信息对外,首先看我们自己的日志,看到的错误信息是:
No alive nodes found in your cluster at elasticsearch/elasticsearch/src/Elasticsearch/ConnectionPool/StaticNoPingConnectionPool.php:51
这个错误第一反应是是不是新的这个gateway节点有问题啊?但是想想这是不可能的,因为并不是所有请求都不可以,而且找了gateway部门的同事问了下,也不存在对请求单独处理的逻辑。
那么继续看到StaticNoPingConnectionPool.php
public function nextConnection($force = false)
{
$total = count($this->connections);
while ($total--) {
/** @var Connection $connection */
$connection = $this->selector->select($this->connections);
if ($connection->isAlive() === true) {
return $connection;
}
if ($this->readyToRevive($connection) === true) {
return $connection;
}
}
throw new NoNodesAvailableException("No alive nodes found in your cluster");
}
这里就说明了两个函数 isAlive和readyToRevive两个都是false。
仔细分析elasticsearch-php包的代码,大致逻辑是这个包帮忙做了重试机制,重试机制的次数为配置的hosts次数。当一个请求失败的时候,它会换一个hosts进行重试。比如你设置了2个hosts,它会用第一个host做请求,如果失败了,请求第二个host,如果还失败,根据isAlive和readyToRevive判断是不是距离第一个host的失败请求一定时间了,如果超过了,则再进行一次请求。(重试两次)。当所有重试都失败了,就出现错误“No alive nodes found in your cluster”。
好了,我这里其实只设置了一个host,那么它就是第一次请求之后,返回失败,本来准备进行一次请求,但是发现第一个host已经请求过了(isAlive() == false),并且距离第一个请求时长没超过60s(readyToRevive() == fasle)于是就抛出错误。
好了,问题转到判断为什么第一个请求会失败了。
error的真面目。
这个异常实际上是把curl的错误给覆盖了。我们看不到真相。需要揭开elasticsearch-php的面纱。
追到最后,在Connections/Connection.php里面的wrapHandler
private function wrapHandler(callable $handler, LoggerInterface $logger, LoggerInterface $tracer)
{
return function (array $request, Connection $connection, Transport $transport = null, $options) use ($handler, $logger, $tracer) {
// Send the request using the wrapped handler.
$response = Core::proxy($handler($request), function ($response) use ($connection, $transport, $logger, $tracer, $request, $options) {
if (isset($response['error']) === true) {
// TODO:这里日志记录下有问题的response
if ($response['error'] instanceof ConnectException || $response['error'] instanceof RingException) {
$connection->markDead();
$transport->connectionPool->scheduleCheck();
$neverRetry = isset($request['client']['never_retry']) ? $request['client']['never_retry'] : false;
$shouldRetry = $transport->shouldRetry($request);
if ($shouldRetry && !$neverRetry) {
return $transport->performRequest(
$request['http_method'],
$request['uri'],
[],
$request['body'],
$options
);
}
在代码TODO里面日志记录下$response信息。发现了response的error信息如下:
cURL: [P]roblem (2) in the Chunked-Encoded data
错误解决
好了,这里其实把error的真身拿出来了,就可以google了。也确实给我们google到了: https://github.com/jackalope/jackalope-jackrabbit/issues/89
按照里面的方法,强行设置HTTP的version头为1.0就能解决了。
我们尝试在Connection.php里面将version头设置上:
public function performRequest($method, $uri, $params = null, $body = null, $options = [], Transport $transport = null)
{
if (isset($body) === true) {
$body = $this->serializer->serialize($body);
}
$request = [
'http_method' => $method,
'scheme' => $this->transportSchema,
'uri' => $this->getURI($uri, $params),
'body' => $body,
'headers' => [
'host' => [$this->host]
],
'version' => "1.0"
];
$request = array_merge_recursive($request, $this->connectionParams, $options);
确实解决了这个问题。
抓包
问题是可以这样解决,但是基本上来说,难道这个错误是客户端引起的么?根,还在提供es的gateway这端的。
先把version头去掉,我决定tcpdump抓包看看情况。
我使用HTTP过滤了下包显示,发现了一个奇怪的现象:
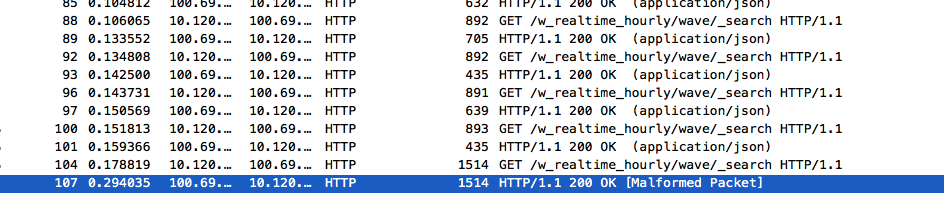
#107是response开始,我看了下实际的头:
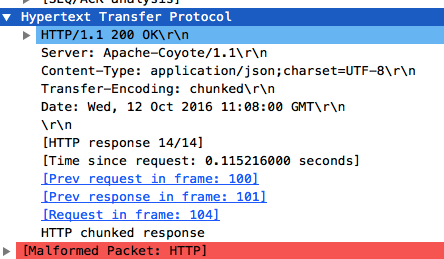
有个Transfer-Encoding: chunked。这个就代表请求结果过长,所以我把这个请求结果分段返回给客户端。
wireshark把红框框了出来。想告诉我们的是,这个chunk返回的数据并不全。
好了,这个我们基本上找到了问题的根源:
服务端支持Transfer-Encoding:chunked,但是不知道什么原因,没有全部返回所有数据。
所以第二种解决方法也出现了:服务端关闭对Transfer-Encoding:chunked的支持。
深究
但是再问一下,为什么服务端会没有全部返回正常的chunked数据呢?
还要展开下,我在wireshark中按照tcp流方式显示了这个response,发现了一个很诡异的现象:
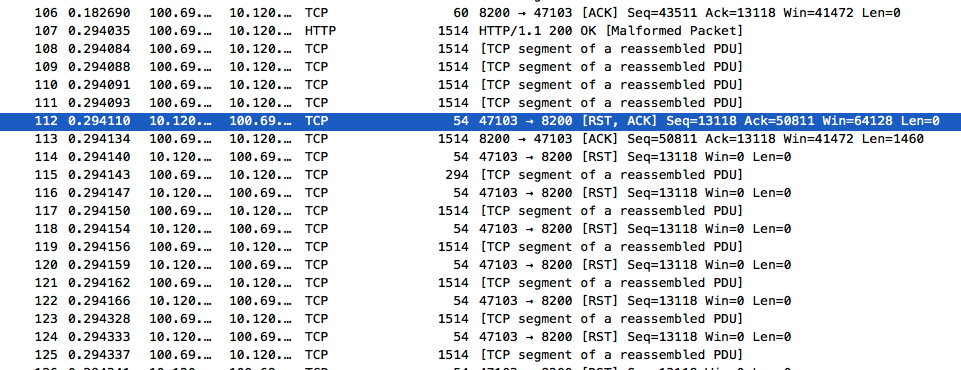
#107还是我们response的开始,然后#108,#109,#110,#111都是chunk数据,并且seq也按照如期地在顺序增长,但是到了#112,客户端这边莫名奇妙返回了一个RST。然后服务端返回了一个ACK。然后就是拒绝大戏了,服务端不断往这边送东西,客户端不断返回RST。到最后,这个连接就断开了。
所以现在的问题追结到为什么会发送#112这个请求。
看win窗口,到#114的时候win窗口已经为0了,而在后面的请求中,win窗口仍然一直为0,说明应用程序一直没有去读缓存区中获取数据。那这个问题估摸就在php-curl或者curl_lib上了。
最终章
最终也没有去追php-curl和curllib库的问题了,主要这个库公司统一部署的,不大可能由于这个问题进行修改了,最后的方法还是通过gateway服务端不使用chunk的头来解决了这个问题。