Spark MLlib回归算法------线性回归、逻辑回归、SVM和ALS
1、线性回归:
(1)模型的建立:
回归正则化方法(Lasso,Ridge和ElasticNet)在高维和数据集变量之间多重共线性情况下运行良好。
数学上,ElasticNet被定义为L1和L2正则化项的凸组合:
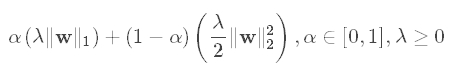
通过适当设置α,ElasticNet包含L1和L2正则化作为特殊情况。例如,如果用参数α设置为1来训练线性回归模型,则其等价于Lasso模型。另一方面,如果α被设置为0,则训练的模型简化为ridge回归模型。
(2)实战:
利用线性回归+随机梯度下降算法构建一个线性模型,并进行预测,最后计算均方误差(Mean Squared Errors)来对模型进行评估。
val conf = new SparkConf().setAppName("LeanerRegressionModelDemo").setMaster("local[4]")
val sc = new SparkContext(conf)
val data = sc.textFile("C://Users//BIGDATA//Desktop//文件//BigData//Spark//7.SparkMLlib_2//resource//resource//ridge-data//lpsa.data")
val parsedData = data.map { line =>
val parts = line.split(',')
LabeledPoint(parts(0).toDouble, Vectors.dense(parts(1).split(' ').map(_.toDouble)))
}.cache()
// Building the model
val numIterations = 20
val model = LinearRegressionWithSGD.train(parsedData, numIterations)
// Evaluate model on training examples and compute training error
val valuesAndPreds = parsedData.map { point =>
val prediction = model.predict(point.features)
(point.label, prediction)
}
val MSE = valuesAndPreds.map{ case(v, p) => math.pow((v - p), 2)}.reduce(_ + _)/valuesAndPreds.count
println("training Mean Squared Error = " + MSE)
2、逻辑回归:
(1)数学公式
逻辑回归一般是用来预测二元分类的,它的线性方法可以用公式(1)进行描述,它的损失函数用公式(2)进行描术:
f(w):=λR(w)+1n∑i=1nL(w;xi,yi) (1)
这里,xi∈Rd 代表训练数据, 1≤i≤n , yi∈R对应的是labels.
目标函数f有两部分:正则化和损失函数,前者的作用是为了去躁,后者是用来评估训练数据模型的误差。在w中损失函数L(w;.)是一个典型的凸函数。固定的正则化参数λ≥0(代码中用regParam 表示),用来权衡两目标间的最小损失。
下面是sparkmllib当中的损失函数和它对应的梯度下降方法数学表达式:
接下来的正则化函数公式:
sign(w) 是由 (±1)组成的向量。
L(w;x,y):=log(1+exp(−ywTx)) (2)
对于二元分类问题,训练输出一个预测模型,给定一组向量X,能过通过公式(3)进行预测。
f(z)=1/(1+e−z) (3)
其中 z=wTx,(数学公式不好弄,T代表转置),默认情况下,f(wTx)>0.5代表正面,其他就是反面。
在sparkmllib当中,我们使用 mini-batch
gradient descent 和 L-BFGS 来解决逻辑回归,推荐使用L-BFGS算法,因为它收敛更快。
(2)实战:
val conf = new SparkConf().setAppName("LogisticRegressionDemo").setMaster("local")
val sc = new SparkContext(conf)
// Load training data in LIBSVM format.
val data = MLUtils.loadLibSVMFile(sc, "C://Users//BIGDATA//Desktop//文件//BigData//Spark//7.SparkMLlib_2//resource//resource//sample_libsvm_data.txt")
// Split data into training (60%) and test (40%).
val splits = data.randomSplit(Array(0.6, 0.4), seed = 11L)
val training = splits(0).cache()
val test = splits(1)
// Run training algorithm to build the model
val model = new LogisticRegressionWithLBFGS()
.setNumClasses(10)
.run(training)
// Compute raw scores on the test set.
val predictionAndLabels = test.map { case LabeledPoint(label, features) =>
val prediction = model.predict(features)
(prediction, label)
}
// Get evaluation metrics.
val metrics = new MulticlassMetrics(predictionAndLabels)
val precision = metrics.precision
println("Precision = " + precision)
// Save and load model
model.save(sc, "target/tmp/scalaLogisticRegressionWithLBFGSModel")
val sameModel = LogisticRegressionModel.load(sc,
"target/tmp/scalaLogisticRegressionWithLBFGSModel")
3、Svm:
(1)方法简介:
支持向量机SVM是一种二分类模型。它的基本模型是定义在特征空间上的间隔最大的线性分类器。支持向量机学习方法包含3种模型:线性可分支持向量机、线性支持向量机及非线性支持向量机。当训练数据线性可分时,通过硬间隔最大化,学习一个线性的分类器,即线性可分支持向量机;当训练数据近似线性可分时,通过软间隔最大化,也学习一个线性的分类器,即线性支持向量机;当训练数据线性不可分时,通过使用核技巧及软间隔最大化,学习非线性支持向量机。线性支持向量机支持L1和L2的正则化变型。
(2)基本原理
支持向量机,因其英文名为support vector machine,故一般简称SVM。SVM从线性可分情况下的最优分类面发展而来。最优分类面就是要求分类线不但能将两类正确分开(训练错误率为0),且使分类间隔最大。SVM考虑寻找一个满足分类要求的超平面,并且使训练集中的点距离分类面尽可能的远,也就是寻找一个分类面使它两侧的空白区域(margin)最大。这两类样本中离分类面最近,且平行于最优分类面的超平面上的点,就叫做支持向量(下图中红色的点)。
svm
假设超平面可描述为:
(wx+b=0, win R^n, bin R )
其分类间隔等于 (frac{2}{||w||}) 。其学习策略是使数据间的间隔最大化,最终可转化为一个凸二次规划问题的求解。
分类器的损失函数(hinge loss铰链损失)如下所示:
(L(w;x,y):=max(0,1-yw^Tx))
默认情况下,线性SVM是用L2 正则化来训练的,但也支持L1正则化。在这种情况下,这个问题就变成了一个线性规划。
线性SVM算法输出一个SVM模型。给定一个新的数据点,比如说 (x) ,这个模型就会根据 (w^Tx) 的值来进行预测。默认情况下,如果 (w^Tx ge 0) ,则输出预测结果为正(因为我们想要损失函数最小,如果预测为负,则会导致损失函数大于1),反之则预测为负。
(3)实战:
下面的例子具体介绍了如何读入一个数据集,然后用SVM对训练数据进行训练,然后用训练得到的模型对测试集进行预测,并计算错误率。以iris数据集为例进行分析。iris以鸢尾花的特征作为数据来源,数据集包含150个数据集,分为3类,每类50个数据,每个数据包含4个属性,是在数据挖掘、数据分类中非常常用的测试集、训练集。
val conf = new SparkConf().setAppName("LogisticRegressionDemo").setMaster("local")
val sc = new SparkContext(conf)
//读取数据
/*
首先,读取文本文件;然后,通过map将每行的数据用“,”隔开,在我们的数据集中,每行被分成了5部分,前4部分是鸢尾花的4个特征,最后一部分是鸢尾花的分类。
把这里我们用LabeledPoint来存储标签列和特征列。LabeledPoint在监督学习中常用来存储标签和特征,其中要求标签的类型是double,特征的类型是Vector。
所以,我们把莺尾花的分类进行了一下改变,"Iris-setosa"对应分类0,"Iris-versicolor"对应分类1,其余对应分类2;然后获取莺尾花的4个特征,存储在Vector中。
*/
val data = sc.textFile("C://Users//BIGDATA//Desktop//文件//BigData//Spark//7.SparkMLlib_2//resource//resource//iris.data")
val parsedData = data.map { line =>
val parts = line.split(',')
LabeledPoint(if(parts(4)=="Iris-setosa") 0.toDouble else if (parts(4) =="Iris-versicolor") 1.toDouble
else 2.toDouble, Vectors.dense(parts(0).toDouble,parts(1).toDouble,parts(2).toDouble,parts(3).toDouble))
}
//构建模型:
/*
* 因为SVM只支持2分类,所以我们要进行一下数据抽取,这里我们通过filter过滤掉第2类的数据,只选取第0类和第1类的数据。然后,我们把数据集划分成两部分,其中训练集占60%,测试集占40%:
* 接下来,通过训练集构建模型SVMWithSGD。这里的SGD即著名的随机梯度下降算法(Stochastic Gradient Descent)。
* 设置迭代次数为1000,除此之外还有stepSize(迭代步伐大小),regParam(regularization正则化控制参数),miniBatchFraction(每次迭代参与计算的样本比例),initialWeights(weight向量初始值)等参数可以进行设
*/
val splits = parsedData.filter { point => point.label != 2 }.randomSplit(Array(0.6, 0.4), seed = 11L)
val training = splits(0).cache()
val test = splits(1)
val numIterations = 1000
val model = SVMWithSGD.train(training, numIterations)
//模型评估
/*
我们清除默认阈值,这样会输出原始的预测评分,即带有确信度的结果。
如果设置了阈值,则会把大于阈值的结果当成正预测,小于阈值的结果当成负预测。
最后,我们构建评估矩阵,把模型预测的准确性打印出来:
*/
model.clearThreshold()
val scoreAndLabels = test.map { point =>
val score = model.predict(point.features)
(score, point.label)
}
scoreAndLabels.foreach(println)
model.setThreshold(0.0)
scoreAndLabels.foreach(println)
val metrics = new BinaryClassificationMetrics(scoreAndLabels)
val auROC = metrics.areaUnderROC()
println("Area under ROC = " + auROC)
4、als:
(1)算法介绍:
协同过滤常被用于推荐系统。这类技术目标在于填充“用户-商品”联系矩阵中的缺失项。Spark.ml目前支持基于模型的协同过滤,其中用户和商品以少量的潜在因子来描述,用以预测缺失项。Spark.ml使用交替最小二乘(ALS)算法来学习这些潜在因子。
(2)显式与隐式反馈
基于矩阵分解的协同过滤的标准方法中,“用户-商品”矩阵中的条目是用户给予商品的显式偏好,例如,用户给电影评级。然而在现实世界中使用时,我们常常只能访问隐式反馈(如意见、点击、购买、喜欢以及分享等),在spark.ml中我们使用“隐式反馈数据集的协同过滤“来处理这类数据。本质上来说它不是直接对评分矩阵进行建模,而是将数据当作数值来看待,这些数值代表用户行为的观察值(如点击次数,用户观看一部电影的持续时间)。这些数值被用来衡量用户偏好观察值的置信水平,而不是显式地给商品一个评分。然后,模型用来寻找可以用来预测用户对商品预期偏好的潜在因子。
(3)正则化参数
我们调整正则化参数regParam来解决用户在更新用户因子时产生新评分或者商品更新商品因子时收到的新评分带来的最小二乘问题。这个方法叫做“ALS-WR”它降低regParam对数据集规模的依赖,所以我们可以将从部分子集中学习到的最佳参数应用到整个数据集中时获得同样的性能。
参数:
alpha:
类型:双精度型。
含义:隐式偏好中的alpha参数(非负)。
checkpointInterval:
类型:整数型。
含义:设置检查点间隔(>=1),或不设置检查点(-1)。
implicitPrefs:
类型:布尔型。
含义:特征列名。
itemCol:
类型:字符串型。
含义:商品编号列名。
maxIter:
类型:整数型。
含义:迭代次数(>=0)。
nonnegative:
类型:布尔型。
含义:是否需要非负约束。
numItemBlocks:
类型:整数型。
含义:商品数目(正数)。
numUserBlocks:
类型:整数型。
含义:用户数目(正数)。
predictionCol:
类型:字符串型。
含义:预测结果列名。
rank:
类型:整数型。
含义:分解矩阵的排名(正数)。
ratingCol:
类型:字符串型。
含义:评分列名。
regParam:
类型:双精度型。
含义:正则化参数(>=0)。
seed:
类型:长整型。
含义:随机种子。
userCol:
类型:字符串型。
含义:用户列名。
(4)实战:
val conf = new SparkConf().setAppName("als").setMaster("local[4]")
val sc = new SparkContext(conf)
//val root = als.getClass.getResource("/")
val data = sc.textFile("C://Users//BIGDATA//Desktop//文件//BigData//Spark//7.SparkMLlib_2//resource//resource//als//test.data")
val ratings = data.map(_.split(',') match { case Array(user, item, rate) =>
Rating(user.toInt, item.toInt, rate.toDouble)
})
// Build the recommendation model using ALS
val rank = 10
val numIterations = 10
val model = ALS.train(ratings, rank, numIterations, 0.01)
// Evaluate the model on rating data
val usersProducts = ratings.map { case Rating(user, product, rate) =>
(user, product)
}
val predictions =
model.predict(usersProducts).map { case Rating(user, product, rate) =>
((user, product), rate)
}
val ratesAndPreds = ratings.map { caseRating(user, product, rate) =>
((user, product), rate)
}.join(predictions)
val MSE = ratesAndPreds.map { case ((user, product), (r1, r2)) =>
val err = (r1 - r2)
err * err
}.mean()
println("Mean Squared Error = " + MSE)
// Save and load model
model.save(sc, "C://tmp")
val sameModel = MatrixFactorizationModel.load(sc, "C://tmp")