学习笔记:CentOS7学习之二十五:shell中色彩处理和awk使用技巧
本文用于记录学习体会、心得,兼做笔记使用,方便以后复习总结。内容基本完全参考学神教育教材,图片大多取材自学神教育资料,在此非常感谢MK老师和学神教育的优质教学。希望各位因学习需求而要进行转载时,能申明出处为学神教育,谢谢各位!
25.1 Shell中的色彩处理
shell脚本中echo显示内容带颜色显示,echo显示带颜色,需要使用参数-e
格式1: echo -e “�33[背景颜色;文字颜色m 要输出的字符 �33[0m”
格式2:echo -e “e[背景颜色;文字颜色m要输出的字符e[0m”
例:绿底蓝字
[root@xuegod63 ~]# echo -e "�33[42;34m hello world�33[0m"
[root@xuegod63 ~]# echo -e "e[42;34m hello worlde[0m"
如图:

注:其中42的位置代表底色,34的位置代表的是字的颜色,0m是清除所有格式
1、字背景颜色和文字颜色之间是英文的分号";"
2、文字颜色后面有个m
3、字符串前后可以没有空格,如果有的话,输出也是同样有空格
4、echo显示带颜色,需要使用参数-e ,-e 允许对下面列出的加反斜线转义的字符进行解释.
常见shell输入带颜色文字: 3x代表字的颜色,4x代表背景色
-
echo -e "�33[30m 黑色字 �33[0m"
-
echo -e "�33[31m 红色字 �33[0m"
-
echo -e "�33[32m 绿色字 �33[0m"
-
echo -e "�33[33m 黄色字 �33[0m"
-
echo -e "�33[34m 蓝色字 �33[0m"
-
echo -e "�33[35m 紫色字 �33[0m"
-
echo -e "�33[36m 天蓝字 �33[0m"
-
echo -e "�33[37m 白色字 �33[0m"
-
echo -e "�33[40;37m 黑底白字 �33[0m"
-
echo -e "�33[41;37m 红底白字 �33[0m"
-
echo -e "�33[42;37m 绿底白字 �33[0m"
-
echo -e "�33[43;37m 黄底白字 �33[0m"
-
echo -e "�33[44;37m 蓝底白字 �33[0m"
-
echo -e "�33[45;37m 紫底白字 �33[0m"
-
echo -e "�33[46;37m 天蓝底白字 �33[0m"
-
echo -e "�33[47;30m 白底黑字 �33[0m"
25.2 awk基本应用
grep和egrep:文本过滤的
sed:流编辑器,实现编辑的
awk:文本报告生成器,实现格式化文本输出
25.2.1 概念
AWK是一种优良的文本处理工具,Linux及Unix环境中现有的功能最强大的数据处理引擎之一。这种编程及数据操作语言的最大功能取决于一个人所拥有的知识。awk命名:Alfred Aho Peter 、Weinberger和brian kernighan三个人的姓的缩写。
awk---->gawk 即: gun awk
在linux上常用的是gawk,awk是gawk的链接文件
man gawk----》pattern scanning and processing language 模式扫描和处理语言。
pattern [ˈpætn] 模式 ; process [ˈprəʊses] 处理
任何awk语句都是由模式和动作组成,一个awk脚本可以有多个语句。模式决定动作语句的触发条件和触发时间。
模式:
正则表达式 : /root/ 匹配含有root的行 /*.root/
关系表达式: < > && || + *
匹配表达式: ~ !~
动作:
变量 命令 内置函数 流控制语句
它的语法结构如下:
awk [options] 'BEGIN{ print "start" } ‘pattern{ commands }’ END{ print "end" }' file
其中:BEGIN END是AWK的关键字部,因此必须大写;这两个部分开始块和结束块是可选的
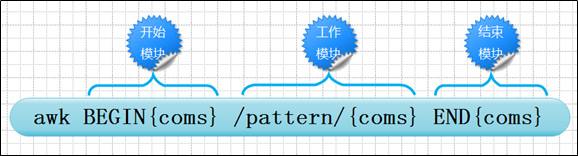
特殊模块:
BEGIN语句设置计数和打印头部信息,在任何动作之前进行
END语句输出统计结果,在完成动作之后执行
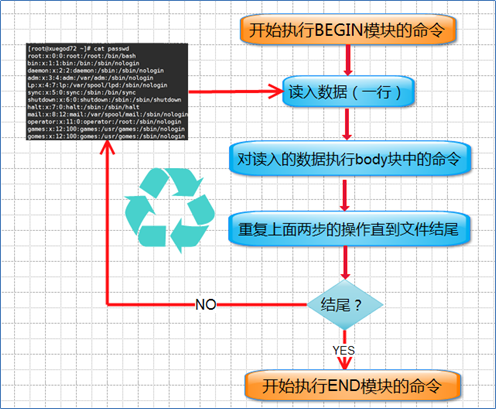
通过上面我们可以知道;AWK它工作通过三个步骤
1、读:从文件、管道或标准输入中读入一行然后把它存放到内存中
2、执行:对每一行数据,根据AWK命令按顺序执行。默认情况是处理每一行数据,也可以指定模式
3、重复:一直重复上述两个过程直到文件结束
AWK支持两种不同类型的变量:内建变量,自定义变量
awk内置变量(预定义变量)
- $n 当前记录的第n个字段,比如: $1表示第一个字段,$2表示第二个字段
- $0 这个变量包含执行过程中当前行的文本内容
- FILENAME 当前输入文件的名
- FS 字段分隔符(默认是空格)
- NF 表示字段数,在执行过程中对应于当前的字段数,NF:列的个数
- FNR 各文件分别计数的行号
- NR 表示记录数,在执行过程中对应于当前的行号
- OFS 输出字段分隔符(默认值是一个空格)
- ORS 输出记录分隔符(默认值是一个换行符)
- RS 记录分隔符(默认是一个换行符)
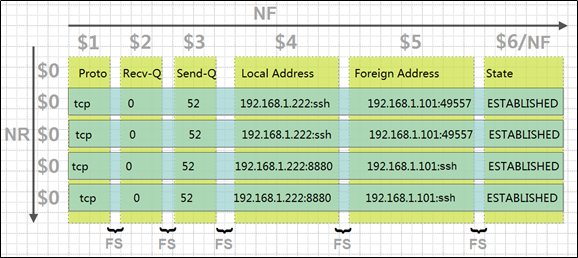
25.2.2实例演示
常用的命令选项:
-F fs指定分隔符
-v 赋值一个用户自定义变量
-f 指定脚本文件,从脚本中读取awk命令
1)分隔符的使用
用法:-Ffs 其中fs是指定输入分隔符,fs可以是字符串或正则表达式;分隔符默认是空格
常见写法:
-F: 使用:作为分隔符
-F, 使用,作为分隔符
-F[Aa] 使用【Aa】作为分隔符
例1:
[root@CentOs7_64_1_128 tmp]# echo "AA BB CC DD"|awk '{print $2}'
BB
[root@CentOs7_64_1_128 tmp]# echo "AA|BB|CC|DD"|awk -F"|" '{print $2}'
BB
[root@CentOs7_64_1_128 tmp]# echo "AA,BB,CC,DD"|awk -F"," '{print $2}'
BB
[root@CentOs7_64_1_128 tmp]# awk -F":" '{print $1}' /etc/passwd
root
bin
daemon
adm
lp
sync
shutdown
halt
mail
operator
games
ftp
nobody
ods
pegasus
例2:指定多个分隔符
[root@CentOs7_64_1_128 tmp]# echo "A123kjsafaifkjfkasi"|awk -F "fk" '{print $2}'
j
例3:使用FS指定分隔符
[root@CentOs7_64_1_128 tmp]# echo "A123kjsafaifkjfkasi"|awk 'BEGIN{FS="fk"} {print
$2}'j
例4:过滤出本系统的IP地址
[root@CentOs7_64_1_128 tmp]# ifconfig ens33|grep netmask
inet 192.168.87.128 netmask 255.255.255.0 broadcast 192.168.87.255
[root@CentOs7_64_1_128 tmp]# ifconfig ens33|grep netmask|awk '{print $2}'
192.168.87.128
2)关系运算符的使用
例1:
[root@CentOs7_64_1_128 tmp]# echo "AA BB CC DD"|awk '{print $2}'
BB
例2:
[root@CentOs7_64_1_128 tmp]# awk '{print $2+10}' b.txt
12
[root@CentOs7_64_1_128 tmp]# echo "one two three four"|awk '{print $4}'
four
[root@CentOs7_64_1_128 tmp]# echo "one two three four"|awk '{print $NF}'
four
[root@CentOs7_64_1_128 tmp]# echo "one two three four"|awk '{print $(NF-2)}' # 打印倒数第三列
two
例2:打印出passwd文件中用户UID小于10的用户名和它登录使用的shell
参数: $NF 最后一列
[root@CentOs7_64_1_128 tmp]# awk -F":" '$3<10{print $1 $NF}' /etc/passwd
root/bin/bash
bin/sbin/nologin
daemon/sbin/nologin
adm/sbin/nologin
lp/sbin/nologin
sync/bin/sync
shutdown/sbin/shutdown
halt/sbin/halt
mail/sbin/nologin
awk -F":" '$3<10{print $1"<====>"$NF}' /etc/passwd # 在S1和$NF之间加入<====>
root<====>/bin/bash
bin<====>/sbin/nologin
daemon<====>/sbin/nologin
adm<====>/sbin/nologin
lp<====>/sbin/nologin
sync<====>/bin/sync
shutdown<====>/sbin/shutdown
halt<====>/sbin/halt
mail<====>/sbin/nologin
在(1和)NF之间加一下 tab
[root@CentOs7_64_1_128 tmp]# awk -F":" '$3<10{print $1" "$NF}' /etc/passwd
root /bin/bash
bin /sbin/nologin
daemon /sbin/nologin
adm /sbin/nologin
lp /sbin/nologin
sync /bin/sync
shutdown /sbin/shutdown
halt /sbin/halt
mail /sbin/nologin
输出多个列时,可以加,分隔一下.
[root@CentOs7_64_1_128 tmp]# awk -F":" '$3<10{print $1" "$3" "$NF}' /etc/passwd
root 0 /bin/bash
bin 1 /sbin/nologin
daemon 2 /sbin/nologin
adm 3 /sbin/nologin
lp 4 /sbin/nologin
sync 5 /bin/sync
shutdown 6 /sbin/shutdown
halt 7 /sbin/halt
mail 8 /sbin/nologin
例2:打印出系统中UID大于1000且登录shell是/bin/bash的用户
[root@CentOs7_64_1_128 tmp]# awk -F":" '{$3>=1000 && $NF=="/bin/bash"}{print $1" "
$NF}' /etc/passwdroot /bin/bash
bin /sbin/nologin
daemon /sbin/nologin
adm /sbin/nologin
lp /sbin/nologin
sync /bin/sync
shutdown /sbin/shutdown
halt /sbin/halt
mail /sbin/nologin
operator /sbin/nologin
games /sbin/nologin
ftp /sbin/nologin
nobody /sbin/nologin
ods /sbin/nologin
pegasus /sbin/nologin
systemd-network /sbin/nologin
dbus /sbin/nologin
polkitd /sbin/nologin
apache /sbin/nologin
unbound /sbin/nologin
libstoragemgmt /sbin/nologin
colord /sbin/nologin
rpc /sbin/nologin
gluster /sbin/nologin
rpcuser /sbin/nologin
nfsnobody /sbin/nologin
amandabackup /bin/bash
saslauth /sbin/nologin
abrt /sbin/nologin
rtkit /sbin/nologin
pulse /sbin/nologin
3)在脚本中的一些应用
例:统计当前内存的使用率
[root@CentOs7_64_1_128 tmp]# vim cachefree.sh
#!/bin/bash
echo "当前系统的内存使用率为:"
USEFREE=`free -m|grep Mem|awk '{print $3/$4*100"%"}'`
echo -e "内存使用百分比:e[31m$USEFREEe[0m"
[root@CentOs7_64_1_128 tmp]# bash cachefree.sh
当前系统的内存使用率为:
内存使用百分比:17.0063%
25.3 awk高级应用
命令格式:
awk [-F | -f | -v ] ‘BEGIN {} /pattern匹配代码块,可以是字符串或正则表达式 / {command1;command2} END {}’file
- -F 指定分隔符
- -f 调用脚本
- -v 定义变量
‘{}’ 引用代码块
{…} 命令代码块,包含一条或多条命令
BEGIN 初始化代码块
/ str / 匹配代码块,可以是字符串或正则表达式
{print A;print B} 多条命令使用分号分隔
END 结尾代码块
在awk中,pattern有以下几种:
1) empty空模式,这个也是我们常用的
2) /regular expression/ 仅处理能够被这个模式匹配到的行
例:打印以root开头的行
[root@CentOs7_64_1_128 tmp]# awk -F":" '/^root/{print $0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
- 行范围匹配 startline,endline
例1:输出行号大于等于3且行号小于等于6的行
[root@CentOs7_64_1_128 tmp]# awk -F":" '(NR>=3&&NR<=6){print NR,$0}' /etc/passwd
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
内置变量的特殊用法:
- $0 表示整个当前行
- NF 字段数量 NF(Number 数量 ; field 字段)
- NR 每行的记录号,多文件记录递增 Record [ˈrekɔ:d]
- 制表符
- 换行符
- ~ 匹配
- !~ 不匹配
- -F'[:#/]+' 定义三个分隔符
例1:使用NR行号来定位,然后提取IP地址
[root@CentOs7_64_1_128 tmp]# ifconfig ens33|awk 'NR==2{print $2}'
192.168.87.128
注:NR==2表示行号
例2:NR与FNR的区别
[root@CentOs7_64_1_128 tmp]# awk '{print NR" "$0}' /etc/hosts /etc/hostname
# NR两个文件行号会统一计数,第二个文件不会从1重新开始
1 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdoma
in42 ::1 localhost localhost.localdomain localhost6 localhost6.localdoma
in63
4 192.168.87.128 CentOs7_64_1_128
5 CentOs7_64_1_128
[root@CentOs7_64_1_128 tmp]# awk '{print FNR" "$0}' /etc/hosts /etc/hostname
# FNR不同的文件行号会重新开始基数,新的文件行号会重新从1开始计算
1 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdoma
in42 ::1 localhost localhost.localdomain localhost6 localhost6.localdoma
in63
4 192.168.87.128 CentOs7_64_1_128
1 CentOs7_64_1_128
注:对于NR来说,在读取不同的文件时,NR是一直加的 ;
对于FNR来说,在读取不同的文件时,它读取下一个文件时,FNR会从1开始重新计算的
例3:使用3种方法去除首行
[root@CentOs7_64_1_128 tmp]# route -n|grep -v Kernel #过滤含有Kernel的行
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.87.2 0.0.0.0 UG 100 0 0 ens33
192.168.87.0 0.0.0.0 255.255.255.0 U 100 0 0 ens33
192.168.122.0 0.0.0.0 255.255.255.0 U 0 0 0 virbr0
[root@CentOs7_64_1_128 tmp]# route -n|sed 1d # 删除第一行
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.87.2 0.0.0.0 UG 100 0 0 ens33
192.168.87.0 0.0.0.0 255.255.255.0 U 100 0 0 ens33
192.168.122.0 0.0.0.0 255.255.255.0 U 0 0 0 virbr0
[root@CentOs7_64_1_128 tmp]# route -n|awk 'NR!=1{print $0}' # 去除行号为1的行
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.87.2 0.0.0.0 UG 100 0 0 ens33
192.168.87.0 0.0.0.0 255.255.255.0 U 100 0 0 ens33
192.168.122.0 0.0.0.0 255.255.255.0 U 0 0 0 virbr0
例4:匹配,使用awk查出以包括root字符的行
[root@CentOs7_64_1_128 ~]# awk -F: '/root/{print $0}' /etc/passwd # 查询包含root的行
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
[root@CentOs7_64_1_128 ~]# awk -F: '/root/' /etc/passwd # 查询包含root的行
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
[root@CentOs7_64_1_128 ~]# awk -F: '!/root/{print $0}' /etc/passwd # 查询不包含root的行
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
nobody:x:99:99:Nobody:/:/sbin/nologin
[root@CentOs7_64_1_128 ~]# awk -F: '/^root/{print $0}' /etc/passwd # 查询以root开头的行
root:x:0:0:root:/root:/bin/bash
[root@CentOs7_64_1_128 ~]# awk -F: '/bash$/{print $0}' /etc/passwd # 查询以bash结尾的行
root:x:0:0:root:/root:/bin/bash
amandabackup:x:33:6:Amanda user:/var/lib/amanda:/bin/bash
postgres:x:26:26:PostgreSQL Server:/var/lib/pgsql:/bin/bash
yangjie:x:1000:1000:yangjie:/home/yangjie:/bin/bash
例5:条件表达式
表达式?if-true:if-false 问号前面是条件,如果条件为真执行if-true,为假执行if-false
例1:如果passwd中UID小于10,则给变量USER赋值成aaa,否则赋值成bbb
awk -F: '{$3<10?USER="aaa":USER="bbb";print $1,USER}' /etc/passwd
root aaa
bin aaa
daemon aaa
adm aaa
lp aaa
sync aaa
shutdown aaa
halt aaa
mail aaa
operator bbb
games bbb
ftp bbb
nobody bbb
ods bbb
pegasus bbb
systemd-network bbb
dbus bbb
polkitd bbb
apache bbb
unbound bbb
libstoragemgmt bbb
用if(条件){命令1;命令2}elif(条件){命令;}else{命令}中,在比较条件中用( )扩起来,在AWK中,如果条件为1为真,0为假
例:如果UID大于10 ,则输出user=>用户名,否则输出pass=>用户名
[root@CentOs7_64_1_128 ~]# awk -F: '{if($3<10){print "user=>"$1}else{print "pass=>"$1}}' /etc/passwd
user=>root
user=>bin
user=>daemon
user=>adm
user=>lp
user=>sync
user=>shutdown
user=>halt
user=>mail
pass=>operator
pass=>games
pass=>ftp
pass=>nobody
pass=>ods
pass=>pegasus
pass=>systemd-network
pass=>dbus
pass=>polkitd
pass=>apache
pass=>unbound
pass=>libstoragemgmt
~ 匹配
!~ 不匹配
例:查出行号小于等于5且包括bin/bash的行
[root@CentOs7_64_1_128 ~]# awk -F: '(NR<=5 && $NF~"bin/bash"){print $0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
[root@CentOs7_64_1_128 ~]# awk -F: '(NR<=5 && $NF!~"bin/bash"){print $0}' /etc/passwd
# 查找行号小于等于5,且不包括bin/bash的行
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
例6:格式化输出
printf命令:格式化输出 printf “FORMAT”,item1,item2.......
format使用注意事项:
1、其与print命令的最大不同是,printf需要指定format样式
2、format用于指定后面的每个item的输出格式
3、printf语句不会自动打印换行符;
4、format格式的指示符都以%开头,后跟一个字符;如下:
| 格式 | 说明 |
|---|---|
| %c | 显示字符的ASCII码 |
| %d, %i | 十进制整数 |
| %e, %E | 科学计数法显示数值 |
| %f | 显示浮点数 |
| %g, %G | 以科学计数法的格式或浮点数的格式显示数值 |
| %s | 显示字符串 |
| %u | 无符号整数 |
| %% | 显示%自身 |
例1:输入passwd文件中的第1列内容,输出时不会换行
wk -F: '{printf "%s/n",$1}' /etc/passwd
root/nbin/ndaemon/nadm/nlp/nsync/nshutdown/nhalt/nmail/noperator/ngames/nftp/nnobody/nods/npegasus/nsystemd-network/nd
bus/npolkitd/napache/nunbound/nlibstoragemgmt/ncolord/nrpc/ngluster/nrpcuser/nnfsnobody/namandabackup/nsaslauth/nabrt/nrtkit/npulse/nradvd/nqemu/nchrony/ntss/ngeoclue/nhacluster/nusbmuxd/ncockpit-ws/nntp/nsssd/ndirsrv/nsetroubleshoot/nnamed/nhsqldb/ntomcat/npkiuser/nsaned/ngdm/ngnome-initial-setup/npcp/nkdcproxy/nipaapi/nmysql/nsshd/navahi/npostgres/npostfix/noprofile/ntcpdump/nyangjie/n[root@CentOs7_64_1_128 ~]#
例2:输出的字母前面添加自定义字符串USERNAME:
[root@CentOs7_64_1_128 ~]# awk -F: '{printf "USERNAME: %s
",$1}' /etc/passwd
USERNAME: root
USERNAME: bin
USERNAME: daemon
USERNAME: adm
USERNAME: lp
USERNAME: sync
USERNAME: shutdown
USERNAME: halt
USERNAME: mail
USERNAME: operator
USERNAME: games
USERNAME: ftp
USERNAME: nobody
USERNAME: ods
...
USERNAME: pulse
例3:对(1和)NF都做格式化输出
[root@CentOs7_64_1_128 ~]# awk -F: '{printf "%s %s
",$1,$NF}' /etc/passwd
# 格式化输出$1和$NF,中间加入 制表符
root /bin/bash
bin /sbin/nologin
daemon /sbin/nologin
adm /sbin/nologin
lp /sbin/nologin
sync /bin/sync
shutdown /sbin/shutdown
halt /sbin/halt
mail /sbin/nologin
operator /sbin/nologin
games /sbin/nologin
ftp /sbin/nologin
[root@CentOs7_64_1_128 ~]# awk -F: '{printf "USERNAME:%s====%s
",$1,$NF}' /etc/passwd
# 格式化输出$1,$NF,中间插入“====”
USERNAME:root====/bin/bash
USERNAME:bin====/sbin/nologin
USERNAME:daemon====/sbin/nologin
USERNAME:adm====/sbin/nologin
USERNAME:lp====/sbin/nologin
USERNAME:sync====/bin/sync
USERNAME:shutdown====/sbin/shutdown
USERNAME:halt====/sbin/halt
USERNAME:mail====/sbin/nologin
USERNAME:operator====/sbin/nologin
USERNAME:games====/sbin/nologin
USERNAME:ftp====/sbin/nologin
USERNAME:nobody====/sbin/nologin
USERNAME:ods====/sbin/nologin
awk修饰符:
N: 显示宽度;
-: 左对齐;
一个字母占一个宽度。默认是右对齐
例4:显示前5行时用10个字符串右对齐显示。如果要显示的字符串不够10个宽度,以字符串的左边自动添加。一个字母占一个宽度。默认是右对齐
[root@CentOs7_64_1_128 ~]# awk -F: '(NR<=5){printf "%10s
",$1}' /etc/passwd
root
bin
daemon
adm
lp
例5:显示前5行时用10个宽度,左对齐显示
[root@CentOs7_64_1_128 ~]# awk -F: '(NR<=5){printf "%-10s
",$1}' /etc/passwd
root
bin
daemon
adm
lp
例子6:显示前5行时,第1列使用15个字符宽度左对齐输出,最后一列使用15个字符宽度右对齐输出
[root@CentOs7_64_1_128 ~]# awk -F: '(NR<=5){printf "%-15s%15s",$1,$NF}' /etc/passwd
root /bin/bashbin /sbin/nologindaemon /sbin/nologinadm /sbin/nolog
inlp /sbin/nologin[root@CentOs7_64_1_128 ~]# awk -F: '(NR<=5){printf "%-15s%15s
",$1,$NF}' /etc/passwdroot /bin/bash
bin /sbin/nologin
daemon /sbin/nologin
adm /sbin/nologin
lp /sbin/nologin
例7:使用开始和结束模块来格式化输出
[root@CentOs7_64_1_128 tmp]# vim test.awk
BEGIN{
print "UserID SHELL"
print "------------------------"
FS=":" # 设置分隔符为:
}
$3>=500 && $NF~"sbin/nologin"{ # 设置匹配条件,UID>=500且最后一列包含sbin/nologin
printf "%-20s%20s
",$1,$NF # 格式化输出第一列为20字符宽度左对齐,第二列为20字符宽度右对齐
}
END{
print "------------------------"
}
~
[root@CentOs7_64_1_128 tmp]# awk -f test.awk /etc/passwd # 调用test.awk文件对/etc/passwd进行格式化输出
UserID SHELL
------------------------
ods /sbin/nologin
polkitd /sbin/nologin
unbound /sbin/nologin
libstoragemgmt /sbin/nologin
colord /sbin/nologin
gluster /sbin/nologin
nfsnobody /sbin/nologin
saslauth /sbin/nologin
chrony /sbin/nologin
geoclue /sbin/nologin
cockpit-ws /sbin/nologin
sssd /sbin/nologin
dirsrv /sbin/nologin
setroubleshoot /sbin/nologin
saned /sbin/nologin
gnome-initial-setup /sbin/nologin
pcp /sbin/nologin
kdcproxy /sbin/nologin
ipaapi /sbin/nologin
------------------------