前几天遇到了一个问题,我在页面逻辑里需要调用一个webservice,处理一个比较耗时的操作,但是我不需要知道其返回值。于是我希望asp.net能像winform一样使用自动生成的webservice异步方法
你是不是想说:在页面调用webservice的时候,直接调用其异步实现不就完了吗?
这其实是行不通的,为了实现异步调用,我们需要对页面进行小小的改动,在Page元素里加上Async=true
我们很快就会发现这样做的问题:
让我们测试一下吧,现在我们在一个webservice的Helloworld方法中放入一个Thread。Sleep(10000),然后调用他的异步实现。通过调试,我们可以发现虽然程序运行至HelloworldAsync时,非常快速的返回并往下运行,但是当所有逻辑处理完成后,页面并不Response,而是硬生生等待我们的线程睡醒了才返回。
可是如果我希望真正做到调了不管怎么办呢?
你可以使用Thread,或者ThreadPool,自己来启动一个线程,我推荐使用ThreadPool,这样的话,这些线程都会被iis的线程池管理起来,不会造成崩溃
我们来分析一下这两种模式的运用有什么特点
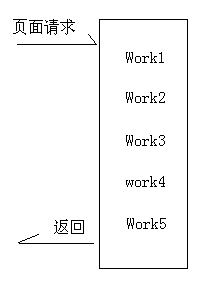
WebService自带的异步模式为下图的模式
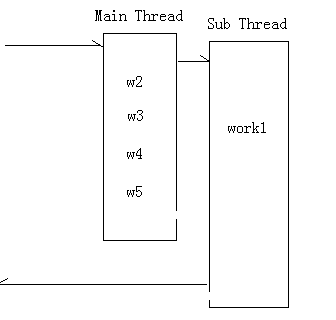
主线程调用子线程执行一个耗时操作(work1),同时执行一系列同步操作(w2...w5),然后交给w1返回
这种模式适合于work1有返回的情况,并且为了让work1得到充分的工作时间,异步调用的过程开始的越早越好,对web程序设计者而言,这里有一个很重要的问题:线程占用。。
刚才我们谈过,asp.net中每个请求都会有有一个线程来处理,而可以使用的线程是有限的,服务器会使用一个线程池来管理线程,当线程耗尽,ok,新来的请求只能蹲着排队,所以对web开发者而言,线程是个宝贵的资源,所以这个方案在并行处理的同时也增加了耗尽线程池的风险,毕竟一个请求造成了多个线程
用线程池来实现的模式属于下图
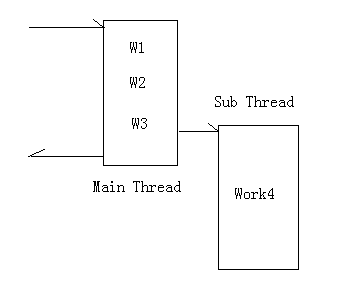
这种模式适合无返回的情况,这种情况下,对子线程的调用应该越晚越好,我们可以看到,主、子线程共存的时间越短,我们的稀缺资源线程就越安全,请注意的是,也许总的执行时间不会比同步的情况更少,但是我们很快就返回了用户界面,所以用户体验能够得到提高
使用web多线程的缺点 :
看了上面的叙述,你也许会说,那干脆把我所有的调用都改成异步调用吧,你尽管去做吧,绝对是一场灾难,因为在异步的同时,一定一会产生一个新的线程等待调用的返回,即使你调用函数的返回值为void,所以异步调用的负面效果将是会产生许多子线程,所以注意当你的调用非常耗时,这个子线程也将长期占用你的线程池,如果这样的调用大量出现,照样会消耗掉所有的可用线程
那么什么情况下适合在web上使用哪种多线程模式呢
我们来看看这段伪代码,他的用途是提交一个报告,方法传入一个报告,并从一个WebService中获得一些报告的内容,接着插入数据库,然后在文件服务器上生成一个报告文件,最后发出一个通知,让我们逐条命令的过一下这个方法,看看什么地方适合改为异步调用?(记得我们的讨论都是基于web的,关于桌面运用的多线程请参考 多线程总结一)
public void CreateReport(Report report){
//从webservice上取得报告的一些信息,不取得这些信息报告,报告是不完整的,是不能提交的
Report fullreport=CallWebService(report);
//插入数据库,很重要的工作
InsertIntoDataBase(fullreport)
try{
//生成报告文件,这里是一个耗时而且容易出错的操作
WriteStaticFile(fullreport)
}
catch{//记录错误日志。。。。}
//这个只是通知邮件
CallMailService2(fullreport)
}
第一条语句CallWebService()从一个webservice里加载一些报告的内容,这个是业务逻辑相关的,因为如果不加载的话报告内容是不完整的,不能提交,显然不能改为异步调了不管的模式,在这里你可以尝试模式一,但是这个改动是没有作用的,因为其他所有的过程,包括插入数据库,生成报告都依赖于这个方法的返回,所以如果我们在这里使用异步的话,其他的所有操作都必须等待他的返回,所以采用异步除了多增加了线程以外,一点时间也不能节省
再来看插入数据库,和上面一样也没有必要使用异步调用
生成报告这里比较有趣,确实他是一个和逻辑息息相关的操作,但是通过分析代码,我们可以看出,虽然报告生成是一个重要业务步骤,但是并没有严格到说"如果不能生成报告,就必须回滚上面的操作",并且如果操作失败,在catch中也仅仅是记录了日志,并没有需要尝试重写的逻辑,(很有可能另外的某个程序或者某人,会定时查看日志,发现有错误就重新生成文件)也就是说,就这段代码而言,生成也可以算一个额外逻辑,那么自然也可以去异步操作.可是:千万注意!!
由于生成报告需要的时间较长,那么生成报告的子线程会长时间运行,长期无法返回线程池,如果请求量太大,频率太快,那就会耗尽线程资源了.
平心而论,这个问题其实不是异步造成的,即使时同步调用,执行此操作也需要化肥很长时间,调用量太大,频率太快,也会造成排队.而且由于返回时间太长,用户体验也不会好,所以我们的这个改造应该是有益的
(注:关于报告生成,我在与一个同事讨论这种思想的时候,他就认为这个地方应该有一个写入队列,因为显然生成文件的速度和其他处理速度是不匹配的,这确实是一个比较合理的做法)