#include <stdio.h>
#include <malloc.h>
typedef struct{
int *elem; //基地址
int length;
int listsize;
}Seqlist;//定义Seq这个新的数据类型
int getGem(Seqlist L,int i,int *e){
if(i>L.length || i<1 || L.length ==0 )
return 0;
*e = *(L.elem+i-1);
printf("i的位置是%d"+i);
return 1;
}
void create(Seqlist &L){
L.elem = (int*) malloc(sizeof(int)*(L.listsize));
int a;
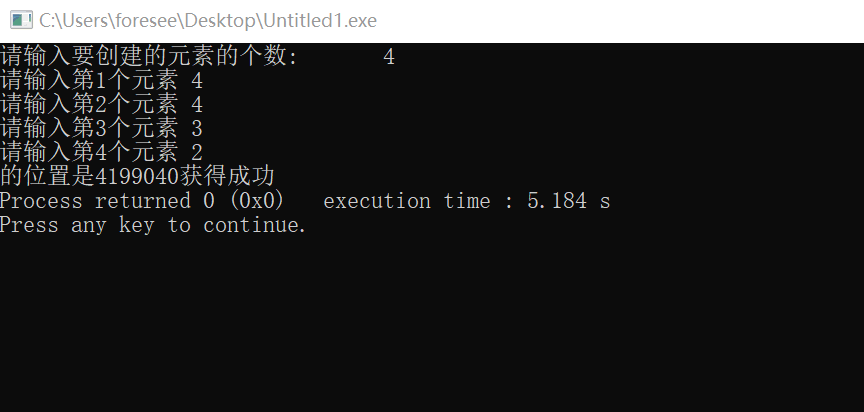
printf("请输入要创建的元素的个数: ");
scanf("%d",&a);
for(int i=0;i<a;i++){
printf("请输入第%d个元素 ",i+1);
scanf("%d",&L.elem[i]);
L.length++;
}
}
int main(){
Seqlist L;
int e ;
L.length=0;//初始化线性表的长度为0
create(L);
getGem(L,1,&e);
printf("获得成功 ");
}
存在疑问:找到第i个元素赋值给e
逻辑结构:数据对象中数据元素之间的相互关系。
物理结构:(很多书叫存储结构,是逻辑结构在计算机中结构形式)
逻辑结构有:集合结构
线性结构(元素是 一对一的关系)
树形结构
图形结构
物理结构有:
顺序结构:把数据元素存放在地址连续的存储单元里,其数据间的逻辑关系和物理关系是一致的
链式结构:把数据元素放入任意的数据单元,可以是连续的,也可以是非连续的。数据元素的存储关系不能反映逻辑结构。所以需要指针存放数据元素地址,通过地址找到元素。
线性表定义是有限个 排序的 序列,数据元素必须是相同类型。即 零个或多个数据元素的有限序列。
两种物理结构:
顺序存储结构:
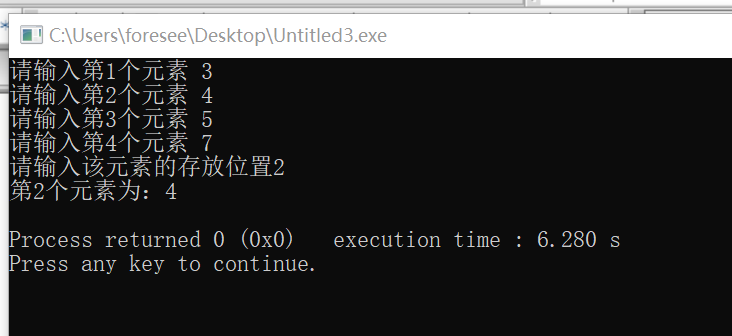
#include <stdio.h> #include <malloc.h> #define MAXSIZE 4 typedef int ElemType; //基于数组的实现 //对于线性结构,有两种保存的方法,一种是使用C语言中内置的数组,这样的结构成为顺序表; //另一种使用指针,这样的结构成为链表。 typedef struct{ ElemType data[MAXSIZE]; int length; }Seqlist;//定义Seq这个新的数据类型 // 不改变线性表,则直接传L int getGem(Seqlist L,int i,int &e){ if(i>L.length || i<1 || L.length ==0 ) return 0; e = L.data[i-1]; return 1; } // 修改线性表,则传&L void create(Seqlist &L){ for(int i=0;i<MAXSIZE;i++){ printf("请输入第%d个元素 ",i+1); scanf("%d",&L.data[i]); L.length++; } } // 插入线性表,则传&L void insert(Seqlist &L,int Postition,int e){ int k; if(L.length == MAXSIZE) //表满 return 0; if(Postition -> L.length+1 || Postition <1 ) return 0; if(Postition <= L.length){ //插入位置不在表尾(为什么可以相等) for(k = L->length-1;k>Postition;k--){ L->data[] } } } int main(){ int item; int Position; Seqlist L; L.length=0; create(L); printf("请输入该元素的存放位置"); scanf("%d",&Position); if(getGem(L,Position,item)) { printf("第%d个元素为:%d ",Position,item); //图1 结果 } }
是
链式存储结构:
下面是C的基础:
备注:void InitList(SqList *L1)和void InitList(SqList &L2)的区别。
L1是指针作为参数传给函数,这样做的原因是这个函数需要修改L1指向的内存空间。不这样做的话等到函数退出不能达到预期效果。这是入参必须是指针。
void InitList(SqList &L)这样写的原因同上一样,只不过这里需要修改的L2的值,但传给函数的值是L2的地址,这样,函数在调用L2时候会使用入参的L2的地址,达到修改L2的目的。这里入参是L2的值。
C中指针和引用的区别:
C++primer中对 对象的定义:对象是指一块能存储数据并具有某种类型的内存空间
一个对象a,它有值和地址&a,运行程序时,计算机会为该对象分配存储空间,来存储该对象的值,我们通过该对象的地址,来访问存储空间中的值
指针p也是对象,它同样有地址&p和存储的值p,只不过,p存储的数据类型是数据的地址。如果我们要以p中存储的数据为地址,来访问对象的值,则要在p前加解引用操作符"*",即*p。
对象有常量(const)和变量之分,既然指针本身是对象,那么指针所存储的地址也有常量和变量之分,常量指针是指,指针这个对象所存储的地址是不可以改变的,而指向常量的指针的意思是,不能通过该指针来改变这个指针所指向的对象。
我们可以把引用理解成变量的别名。定义一个引用的时候,程序把该引用和它的初始值绑定在一起,而不是拷贝它。计算机必须在声明r的同时就要对它初始化,并且,r一经声明,就不可以再和其它对象绑定在一起了。
实际上,你也可以把引用看做是通过一个常量指针来实现的,它只能绑定到初始化它的对象上。
*&p就是指针的引用。
关于指针和引用的对比,可以参看<<more effective C++>>中的第一条条款,引用的一个优点是它一定不为空,因此相对于指针,它不用检查它所指对象是否为空,这增加了效率

例如:++操作而言,对引用的操作直接反应到所指向的对象,而不是改变指向;而对指针的操作,会使指针指向下一个对象,而不是改变所指对象的内容。见下面的代码:
#include<iostream>
using namespace std;
int main(int argc,char** argv)
{
int i=10;
int& ref=i;
ref++;
cout<<"i="<<i<<endl;
cout<<"ref="<<ref<<endl;
int j=20;
ref=j;
ref++;
cout<<"i="<<i<<endl;
cout<<"ref="<<ref<<endl;
cout<<"j="<<j<<endl;
return 0;
}
对ref的++操作是直接反应到所指变量之上,对引用变量ref重新赋值"ref=j",并不会改变ref的指向,它仍然指向的是i,而不是j。理所当然,这时对ref进行++操作不会影响到j。
C++中的指针和->操作符(类比学习)
"->"操作符最初是运用于指针的。还记得当时老师说这个符号的时候说过:“你看这个符号的样子,它就是代表指向!”
看似 "->"等价于成员操作符了。其实不然,它只是运用于指针。比如有这样一个类(结构体和类基本上一样)TDate;要创建一个类实例,一般有下面两种:
TDate date1; //method1
TDate date2 = new TDate(); //method2
第一种方法是静态创建的,它创建于栈中,返回的是一个TDate型的对象实例。而第二种方法是动态创建,它创建于堆中,返回的不是一个对象实例,而是一个指向一个TDate型对象的指针。也就是说,new操作符返回的是一个指针,这个指针指向一个对象实例。这和java或者js或c#不一样,new出来的就直接是对象,因为这些语言中没有指针。所以c++中new出来的对象必须手动delete掉,否则其内存不会自动释放。c++中的new相当于C中的malloc(),而delete相当于C中的free()。
因为这里date1是一个对象,"."表示对象的成员,date1.x表示对象date1的成员x。而date2是一个指针,"->"表示指针的指向,date2->x表示指针指向的成员x。如果还是不太清楚,那下面的句话应该可以帮助一下理解:(*date2).x和date2->x等价。也就是说,因为date2是一个指针,那么*date2就是一个对象,这时候就可以使用成员操作符.了。之所以用(),是因为.的优先权大于*。
线性表的结点按逻辑次序依次存放在一组地址连续的存储单元里的方法。用顺序存储方法存储的线性表简称为顺序表。
一句话:用数组来存储的线性表就是顺序表
元素要插入线性表的思路:
从最后一个元素往前遍历,到i的位置停下,每个元素往后挪一位。