计算机由美国人发明,最早的字符编码为ASCII,只规定了英文字母数字和一些特殊字符与数字的对应关系。最多只能用8位来表示(一个字节),即:2**8=256,所以,ASCII最多只能表示256个符号。
由于ASCII无法存储全球语言的对应关系,中国定义了 gb2312,日本定义了 Shift_JIS,韩国定义了 Euc-kr。
此时,当一篇文档中同时出现多国语言时,不论使用哪一种编码方式,都会出现乱码。
由此,定义了一个世界性的标准:Unicode
ASCII,用 1个字节(8位二进制)表示一个字符
Unicode,统一用2个字节(16位二进制)表示一个字符,可代表 2**16-1=65535个字符。
但Unicode中存放了 与其他编码的映射关系,所以才能够兼容万国,链接: https://pan.baidu.com/s/1dEV3RYp
字母x, 用ASCII表示,是十进制的120,二进制 0111 1000 汉字中已经超出了ASCII的编码范围,用Unicode编码是十进制的20013,二进制的 01001110 00101101 用Unicode表示,二进制 0000 0000 0111 1000 所以,unicode兼容ASCII,也兼容万国,是 世界的标准
此时,新的问题出现了,当一篇文档通篇是英文时,使用Unicode会比ASCII,多耗费一倍的空间,在存储与传输上十分的低效。
又出现了把 Unicode编码 转化为 "可变长编码"的 UTF-8编码,常用的英文字母编码为1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码为4-6个字节。
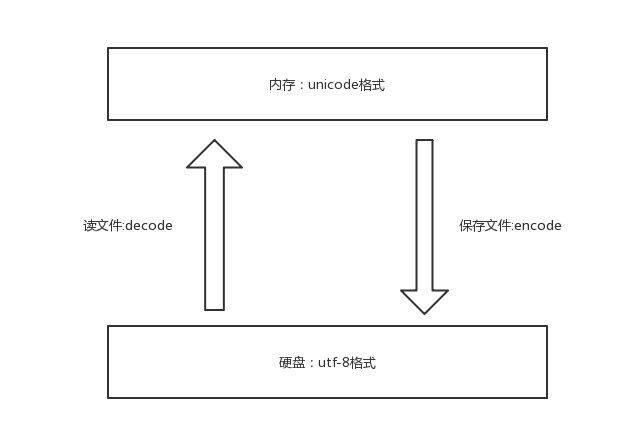
总结:
内存中统一使用Unicode,浪费空间来换取可以转换为任意编码,不乱码
硬盘中可以采用各种编码方式,如:utf-8,保证 存放于硬盘或者基于网络传输的数据量很小,提高传输效率与稳定性。
保证不乱码的核心方法:字符按照什么标准编码,就按照什么标准解码
内存中数据,通常使用16进制表示,2位16进制数据,即 2个2**4,即2*4个比特位,即代表一个字节,