本文将尝试从Kafka Streams的WordCount应用收到消息后如何处理来分析Kafka Streams的工作原理。
1 准备工作
1.1 Kafka Streams是什么
The easiest way to write mission-critical real-time applications and microservices.
Kafka Streams提供了一个最简单的,开发实时流处理应用的方式。因为:
- 它是一个jar包而非流处理框架。单独构建Kafka Streams应用只需要一个jar包;与其他项目集成也只需引用这个jar包。
- Kafka Streams只依赖Kafka,输入数据和输出数据都存放在Kafka中。
1.2 Kafka 集群
假设我们已经有了Zookeeper和Kafka环境,现在需要创建两个topic:
- source topic,命名为TextLinesTopic,分区数为2,WordCount应用消费的topic。
- target topic,命名为WordsWithCountsTopic,分区数为2,WordCount应用处理过的数据会发往这个topic。
创建topic的命令为:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 2 --topic topic-name
# 创建成功后,命令行显示Created topic "topic-name".
创建两个topic后,查看topic列表
bin/kafka-topics.sh --zookeeper localhost:2181 --list
# 看到创建的source topic和target topic
2 创建Kafka Streams应用
2.1 官网的WordCount应用
使用Hello Kafka Streams官网提供的入门的WordCount应用,在页面最下可以看到官网提供的WordCountApplication,如下(有小改动):
// 略去import
public class WordCountApplication {
private static final String BOOTSTRAP_SERVERS_CONFIG = "127.0.0.1:9092";
public static void main(String[] args) {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-application");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS_CONFIG);
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
// stream & source topic
KStream<String, String> textLines = builder.stream("TextLinesTopic");
// table
KTable<String, Long> wordCounts = textLines
.flatMapValues(textLine -> Arrays.asList(textLine.toLowerCase().split("\W+")))
.groupBy((key, word) -> word)
.count(Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as("counts-store"));
// target topic
wordCounts
.toStream()
.to("WordsWithCountsTopic", Produced.with(Serdes.String(), Serdes.Long()));
Topology toplogy = builder.build();
// 打印toplogy
System.out.println(toplogy.describe());
// 构建KafkaStreams
KafkaStreams streams = new KafkaStreams(toplogy, props);
Runtime.getRuntime().addShutdownHook(new Thread("streams-shutdown-hook") {
@Override
public void run() {
streams.close();
}
});
streams.start();
}
}
由上边代码可见,构建一个KafkaStreams至少需要Topology和Properties两个参数(KafkaStreams总共提供了7个public的构造函数,3个已经弃用)。
2.1.1 Topology
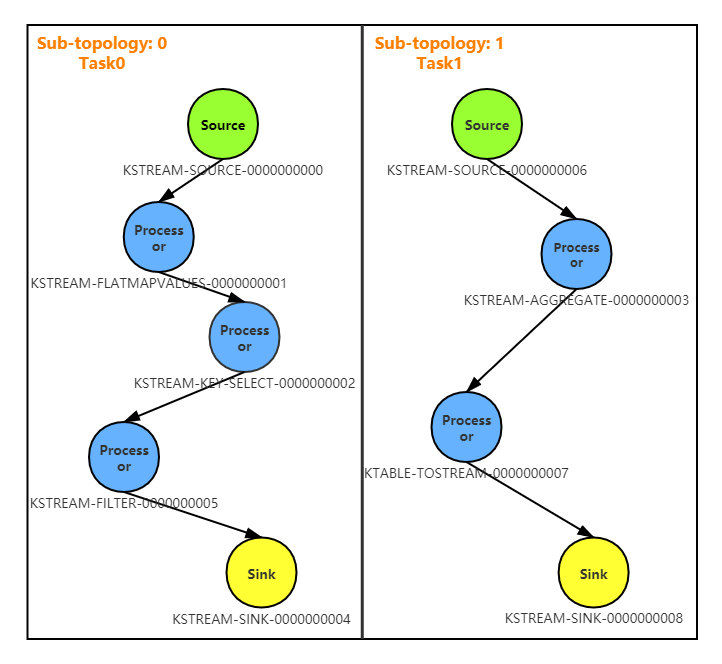
WordCount应用通过StreamsBuilder#build创建了一个Topology。在控制台把创建的拓扑打印出来,如下:
Topologies:
Sub-topology: 0
Source: KSTREAM-SOURCE-0000000000 (topics: [TextLinesTopic])
--> KSTREAM-FLATMAPVALUES-0000000001
Processor: KSTREAM-FLATMAPVALUES-0000000001 (stores: [])
--> KSTREAM-KEY-SELECT-0000000002
<-- KSTREAM-SOURCE-0000000000
Processor: KSTREAM-KEY-SELECT-0000000002 (stores: [])
--> KSTREAM-FILTER-0000000005
<-- KSTREAM-FLATMAPVALUES-0000000001
Processor: KSTREAM-FILTER-0000000005 (stores: [])
--> KSTREAM-SINK-0000000004
<-- KSTREAM-KEY-SELECT-0000000002
Sink: KSTREAM-SINK-0000000004 (topic: counts-store-repartition)
<-- KSTREAM-FILTER-0000000005
Sub-topology: 1
Source: KSTREAM-SOURCE-0000000006 (topics: [counts-store-repartition])
--> KSTREAM-AGGREGATE-0000000003
Processor: KSTREAM-AGGREGATE-0000000003 (stores: [counts-store])
--> KTABLE-TOSTREAM-0000000007
<-- KSTREAM-SOURCE-0000000006
Processor: KTABLE-TOSTREAM-0000000007 (stores: [])
--> KSTREAM-SINK-0000000008
<-- KSTREAM-AGGREGATE-0000000003
Sink: KSTREAM-SINK-0000000008 (topic: WordsWithCountsTopic)
<-- KTABLE-TOSTREAM-0000000007
由上可见,这个Topology又分为两个子拓扑,分别是子拓扑0和子拓扑1,对应Task0和Task1,具体如下:
2.1.2 Properties
WordCount应用使用了4个StreamsConfig的配置,分别是:
| key | value | describe |
|---|---|---|
| StreamsConfig.APPLICATION_ID_CONFIG | wordcount-application | 应用名。3个作用:client-id的前缀;相同的应用名组成Kafka Streams集群;内部topic的前缀 |
| StreamsConfig.BOOTSTRAP_SERVERS_CONFIG | 127.0.0.1:9092 | kafka地址,多个以","分隔 |
| StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG | Serdes.String().getClass() | key序列和反序列的类 |
| StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG | Serdes.String().getClass() | value序列和反序列的类 |
StreamsConfig所有的配置可查看Kafka Streams Configs
2.1.3 内部topic
WordCount应用启动后,会创建2个内部topic,分区数
-
wordcount-application-counts-store-repartition,子拓扑0的SinkNode会把经过处理的数据发往这个名为repartition的内部topic,子拓扑1的SourceNode会从这个名为repartition的内部topic取到经过子拓扑0处理过的数据。 -
wordcount-application-counts-store-changelog,这个topic会记录WordCount的聚合结果,changelog topic使用了kafka的Log compaction功能,可以安全地清除旧数据,以防止topic无限增长。changelog changelog用于Kafka Streams容错处理。
2.2 启动WordCount应用
启动一个WordCount应用,查看启动的日志
...
stream-thread [wordcount-application-6f260d17-7347-4e80-94ad-786753f4d683-StreamThread-1] Starting
stream-client [wordcount-application-6f260d17-7347-4e80-94ad-786753f4d683]Started Streams client
stream-thread [wordcount-application-6f260d17-7347-4e80-94ad-786753f4d683-StreamThread-1] State transition from CREATED to RUNNING
[Consumer clientId=wordcount-application-6f260d17-7347-4e80-94ad-786753f4d683-StreamThread-1-consumer, groupId=wordcount-application] Discovered group coordinator K-PC:9092 (id: 2147483647 rack: null)
[Consumer clientId=wordcount-application-6f260d17-7347-4e80-94ad-786753f4d683-StreamThread-1-consumer, groupId=wordcount-application] Revoking previously assigned partitions []
stream-thread [wordcount-application-6f260d17-7347-4e80-94ad-786753f4d683-StreamThread-1] State transition from RUNNING to PARTITIONS_REVOKED
stream-client [wordcount-application-6f260d17-7347-4e80-94ad-786753f4d683]State transition from RUNNING to REBALANCING
stream-thread [wordcount-application-6f260d17-7347-4e80-94ad-786753f4d683-StreamThread-1] partition revocation took 1 ms.
suspended active tasks: []
suspended standby tasks: []
[Consumer clientId=wordcount-application-6f260d17-7347-4e80-94ad-786753f4d683-StreamThread-1-consumer, groupId=wordcount-application] (Re-)joining group
stream-thread [wordcount-application-6f260d17-7347-4e80-94ad-786753f4d683-StreamThread-1-consumer] Assigned tasks to clients as {6f260d17-7347-4e80-94ad-786753f4d683=[activeTasks: ([0_0, 0_1, 1_0, 1_1]) standbyTasks: ([]) assignedTasks: ([0_0, 0_1, 1_0, 1_1]) prevActiveTasks: ([]) prevAssignedTasks: ([]) capacity: 1]}.
[Consumer clientId=wordcount-application-6f260d17-7347-4e80-94ad-786753f4d683-StreamThread-1-consumer, groupId=wordcount-application] Successfully joined group with generation 1
[Consumer clientId=wordcount-application-6f260d17-7347-4e80-94ad-786753f4d683-StreamThread-1-consumer, groupId=wordcount-application] Setting newly assigned partitions [wordcount-application-counts-store-repartition-0, TextLinesTopic-1, TextLinesTopic-0, wordcount-application-counts-store-repartition-1]
stream-thread [wordcount-application-6f260d17-7347-4e80-94ad-786753f4d683-StreamThread-1] State transition from PARTITIONS_REVOKED to PARTITIONS_ASSIGNED
stream-thread [wordcount-application-6f260d17-7347-4e80-94ad-786753f4d683-StreamThread-1] partition assignment took 31 ms.
current active tasks: [0_0, 0_1, 1_0, 1_1]
current standby tasks: []
previous active tasks: []
stream-thread [wordcount-application-6f260d17-7347-4e80-94ad-786753f4d683-StreamThread-1] State transition from PARTITIONS_ASSIGNED to RUNNING
stream-client [wordcount-application-6f260d17-7347-4e80-94ad-786753f4d683]State transition from REBALANCING to RUNNING
可以看到:
- streams应用state的改变:CREATED -> RUNNING -> REBALANCING -> RUNNING
- streams线程的状态state的改变:CREATED -> RUNNING -> PARTITIONS_REVOKED -> PARTITIONS_ASSIGNED -> RUNNING
- 最终应用拿到的任务是:0_0, 0_1, 1_0, 1_1,下划线前的数字是子拓扑,下划线后的数字是source topic的分区。
再启动一个WordCount应用(使用同样的APPLICATION_ID_CONFIG,与第一个应用组成集群),控制台日志分别输出:
#第一个WordCount应用日志
...
[Consumer clientId=wordcount-application-6f260d17-7347-4e80-94ad-786753f4d683-StreamThread-1-consumer, groupId=wordcount-application] Revoking previously assigned partitions [wordcount-application-counts-store-repartition-0, TextLinesTopic-1, TextLinesTopic-0, wordcount-application-counts-store-repartition-1]
stream-thread [wordcount-application-6f260d17-7347-4e80-94ad-786753f4d683-StreamThread-1] State transition from RUNNING to PARTITIONS_REVOKED
stream-client [wordcount-application-6f260d17-7347-4e80-94ad-786753f4d683]State transition from RUNNING to REBALANCING
stream-thread [wordcount-application-6f260d17-7347-4e80-94ad-786753f4d683-StreamThread-1] partition revocation took 277 ms.
suspended active tasks: [0_0, 0_1, 1_0, 1_1]
suspended standby tasks: []
[Consumer clientId=wordcount-application-6f260d17-7347-4e80-94ad-786753f4d683-StreamThread-1-consumer, groupId=wordcount-application] (Re-)joining group
stream-thread [wordcount-application-6f260d17-7347-4e80-94ad-786753f4d683-StreamThread-1-consumer] Assigned tasks to clients as {b391295c-1bee-493e-9ebf-ac4ba0302190=[activeTasks: ([1_0, 1_1]) standbyTasks: ([]) assignedTasks: ([1_0, 1_1]) prevActiveTasks: ([]) prevAssignedTasks: ([0_0, 0_1, 1_0, 1_1]) capacity: 1], 6f260d17-7347-4e80-94ad-786753f4d683=[activeTasks: ([0_0, 0_1]) standbyTasks: ([]) assignedTasks: ([0_0, 0_1]) prevActiveTasks: ([0_0, 0_1, 1_0, 1_1]) prevAssignedTasks: ([0_0, 0_1, 1_0, 1_1]) capacity: 1]}.
[Consumer clientId=wordcount-application-6f260d17-7347-4e80-94ad-786753f4d683-StreamThread-1-consumer, groupId=wordcount-application] Successfully joined group with generation 7
[Consumer clientId=wordcount-application-6f260d17-7347-4e80-94ad-786753f4d683-StreamThread-1-consumer, groupId=wordcount-application] Setting newly assigned partitions [TextLinesTopic-1, TextLinesTopic-0]
stream-thread [wordcount-application-6f260d17-7347-4e80-94ad-786753f4d683-StreamThread-1] State transition from PARTITIONS_REVOKED to PARTITIONS_ASSIGNED
stream-thread [wordcount-application-6f260d17-7347-4e80-94ad-786753f4d683-StreamThread-1] partition assignment took 229 ms.
current active tasks: [0_0, 0_1]
current standby tasks: []
previous active tasks: [0_0, 0_1, 1_0, 1_1]
stream-thread [wordcount-application-6f260d17-7347-4e80-94ad-786753f4d683-StreamThread-1] State transition from PARTITIONS_ASSIGNED to RUNNING
stream-client [wordcount-application-6f260d17-7347-4e80-94ad-786753f4d683]State transition from REBALANCING to RUNNING
# 第二个WordCount应用的日志
...
stream-thread [wordcount-application-b391295c-1bee-493e-9ebf-ac4ba0302190-StreamThread-1] Starting
stream-client [wordcount-application-b391295c-1bee-493e-9ebf-ac4ba0302190]Started Streams client
stream-thread [wordcount-application-b391295c-1bee-493e-9ebf-ac4ba0302190-StreamThread-1] State transition from CREATED to RUNNING
[Consumer clientId=wordcount-application-b391295c-1bee-493e-9ebf-ac4ba0302190-StreamThread-1-consumer, groupId=wordcount-application] Discovered group coordinator K-PC:9092 (id: 2147483647 rack: null)
[Consumer clientId=wordcount-application-b391295c-1bee-493e-9ebf-ac4ba0302190-StreamThread-1-consumer, groupId=wordcount-application] Revoking previously assigned partitions []
stream-thread [wordcount-application-b391295c-1bee-493e-9ebf-ac4ba0302190-StreamThread-1] State transition from RUNNING to PARTITIONS_REVOKED
stream-client [wordcount-application-b391295c-1bee-493e-9ebf-ac4ba0302190]State transition from RUNNING to REBALANCING
stream-thread [wordcount-application-b391295c-1bee-493e-9ebf-ac4ba0302190-StreamThread-1] partition revocation took 1 ms.
suspended active tasks: []
suspended standby tasks: []
[Consumer clientId=wordcount-application-b391295c-1bee-493e-9ebf-ac4ba0302190-StreamThread-1-consumer, groupId=wordcount-application] (Re-)joining group
[Consumer clientId=wordcount-application-b391295c-1bee-493e-9ebf-ac4ba0302190-StreamThread-1-consumer, groupId=wordcount-application] Successfully joined group with generation 7
[Consumer clientId=wordcount-application-b391295c-1bee-493e-9ebf-ac4ba0302190-StreamThread-1-consumer, groupId=wordcount-application] Setting newly assigned partitions [wordcount-application-counts-store-repartition-0, wordcount-application-counts-store-repartition-1]
stream-thread [wordcount-application-b391295c-1bee-493e-9ebf-ac4ba0302190-StreamThread-1] State transition from PARTITIONS_REVOKED to PARTITIONS_ASSIGNED
stream-thread [wordcount-application-b391295c-1bee-493e-9ebf-ac4ba0302190-StreamThread-1] partition assignment took 35 ms.
current active tasks: [1_0, 1_1]
current standby tasks: []
previous active tasks: []
stream-thread [wordcount-application-b391295c-1bee-493e-9ebf-ac4ba0302190-StreamThread-1] State transition from PARTITIONS_ASSIGNED to RUNNING
stream-client [wordcount-application-b391295c-1bee-493e-9ebf-ac4ba0302190]State transition from REBALANCING to RUNNING
可以看到,第二个应用启动后组成了集群,新的应用加入后,两个应用的任务进行了REBALANCE,第一个应用拿到了0_0, 0_1,第二个应用拿到了1_0, 1_1。REBALANCE后第一个应用的子拓扑0执行topic分区0和分区1的任务,子拓扑1没有拿到任务;第二个应用的子拓扑1执行topic分区0和分区1的任务,子拓扑0没有拿到任务。如下图:
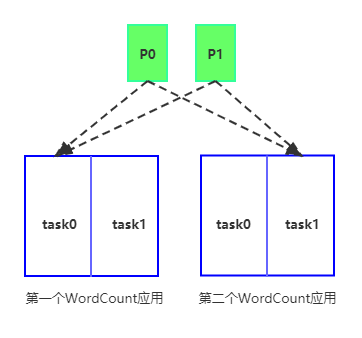
这时,如果一条消息发往source topic的1分区:
- 消息会被第一个WordCount应用子拓扑0的
SourceNode(KSTREAM-SOURCE-0000000000)拿到 - 子拓扑0处理后由子拓扑0的
SinkNode(KSTREAM-SINK-0000000004)发回到kafka的reparation分区 - 然后被第二个WordCount应用的子拓扑1(2个WordCount应用通过任务
REBALANCE后,的SourceNode(KSTREAM-SOURCE-0000000006)拿到 - 经过子拓扑1处理由
SinkNode(KSTREAM-SINK-0000000008)把最终结果发至target topic。
3 往source topic 发消息
往source topic(TextLinesTopic)发送一条消息,消息的key和value都是"hello world"。
- 1 消息被子拓扑0的
SourceNode(KSTREAM-SOURCE-0000000000)拿到。 - 2 原始消息被
Kstream#flatMapValues处理,对应子拓扑0的ProcessorNode(KSTREAM-FLATMAPVALUES-0000000001)。这个算子(Processor)会把消息的value转为小写格式在进行切分操作(以非字母数字下划线切分),这些操作并不改变原消息的key。因此,key和value都是"hello world"的消息经过Kstream#flatMapValues处理后,变成key是"hello world",value分别是"hello"和"world"的两条消息。 - 3 然后由
Kstream#groupBy处理。这个算子等价于先后调用Kstream#selectKey和Kstream#groupByKey,分别对应子拓扑0的ProcessorNode(KSTREAM-KEY-SELECT-0000000002)和ProcessorNodeKSTREAM-FILTER-0000000005)。- 3.1
Kstream#selectKey,改变消息的key。消息变为key和value分别是“hello”和“world”的两条消息。 - 3.2
Kstream#groupByKey,按key进行分组,相同的key会被分到一组(Kafka Streams进行聚合操作前必须进行分组操作)。
- 3.1
- 4 消息通过
SinkNode(KSTREAM-SINK-0000000004)将子拓扑0处理完的消息发往reparation topic。
接下来的操作由子拓扑1完成。
- 1 子拓扑1的
SourceNode(KSTREAM-SOURCE-0000000006)从reparation topic拿到分组后的消息。 - 2 由
Kstream#count处理,对应子拓扑1的ProcessorNode(KSTREAM-AGGREGATE-0000000003),count操作后消息类型变成KTable。- 2.1 local state store,将结果存进rocksdb,存储在本地。
- 2.2 将结果发往changelog topic,用于容错处理。
- 3
ProcessorNode(KTABLE-TOSTREAM-0000000007)把消息类型从KTable转化为KStream。 - 4 通过
SinkNode(KSTREAM-SINK-0000000008)将子拓扑1 count的消息发往target topic。
由于时间有限,很多Kafka Streams的概念,比如窗口等本文没有涉及。
4 概念及其他
4.1 topology
Kafka Streams 通过拓扑定义处理逻辑,拓扑由点和边组成。
- 点,分为3类:
SourceNode、SinkNode和ProcessorNode。SourceNode和SinkNode分别是拓扑的起止。SourceNode从Kafka的source topic中取消息给ProcessorNode处理,SinkNode把ProcessorNode处理完的结果发往Kafka的target topic;Processor负责处理流数据。分为Kafka Streams DSL和Processor API两类,前者提供常用的数据操作,如map、filter、join、aggregations;后者可以由开发者自己定制开发。
- 边,数据流向。
4.2 state
Stream thread的states
+-------------+
+<--- | Created (0) |
| +-----+-------+
| |
| v
| +-----+-------+
+<--- | Running (1) | <----+
| +-----+-------+ |
| | |
| v |
| +-----+-------+ |
+<--- | Partitions | |
| | Revoked (2) | <----+
| +-----+-------+ |
| | |
| v |
| +-----+-------+ |
| | Partitions | |
| | Assigned (3)| ---->+
| +-----+-------+
| |
| v
| +-----+-------+
+---> | Pending |
| Shutdown (4)|
+-----+-------+
|
v
+-----+-------+
| Dead (5) |
+-------------+
Kafka Streams的states
+--------------+
+<----- | Created (0) |
| +-----+--------+
| |
| v
| +--------------+
+<----- | Running (2) | -------->+
| +----+--+------+ |
| | ^ |
| v | |
| +----+--+------+ |
| | Re- | v
| | Balancing (1)| -------->+
| +-----+--------+ |
| | |
| v v
| +-----+--------+ +----+-------+
+-----> | Pending |<--- | Error (5) |
| Shutdown (3) | +------------+
+-----+--------+
|
v
+-----+--------+
| Not |
| Running (4) |
+--------------+
4.3 KTable与KStream
KStream,数据流,所有数据通过insert only的方式加入到这个数据流中。
Ktable,数据集,像是数据库中的表,数据以update only的方式加入。
4.4 Kafka发送消息时,如何确定分区
源码KafkaProducer#doSend在发送消息时,通过partition方法获得分区。
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
...
int partition = partition(record, serializedKey, serializedValue, cluster);
...
}
kafka提供了一个默认的partition实现DefaultPartitioner#partition
/**
* Compute the partition for the given record.
*
* @param topic The topic name
* @param key The key to partition on (or null if no key)
* @param keyBytes serialized key to partition on (or null if no key)
* @param value The value to partition on or null
* @param valueBytes serialized value to partition on or null
* @param cluster The current cluster metadata
*/
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
private int nextValue(String topic) {
AtomicInteger counter = topicCounterMap.get(topic);
if (null == counter) {
counter = new AtomicInteger(ThreadLocalRandom.current().nextInt());
AtomicInteger currentCounter = topicCounterMap.putIfAbsent(topic, counter);
if (currentCounter != null) {
counter = currentCounter;
}
}
return counter.getAndIncrement();
}
上述源码可以看到:
- 消息key是null,topic可用分区大于0时,使用根据topic获取的nextValue的值和可用分区数进行取模操作。
- 消息key是null,topic可用分区小于等于0时,获取根据topic获取的nextValue的值和总分区数进行取模操作(give a non-available partition,给了个不可用的分区)。
- 消息key不是null时,对key进行hash后和topic的分区数取模。可以保证topic的分区数不变的情况下,相同的key每次都发往同一个分区。