3千万电商平台用户大数据分析
前文,我们在网站用户行为分析获取了小样本群体的数据,数据集7万。
这次,我们尝试增加一些数据量。数据样本取自阿里云天池,样本数据超过1亿。
数据来源
阿里云天池:https://tianchi.aliyun.com/dataset/dataDetail?dataId=46
一:查看数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
df = pd.read_csv('E:/yizhiamumu/UserBehavior.csv',header=None, names=['user_id', 'item_id', 'item_category', 'behavior_type', 'time'],nrows=100000000)
df.info()
打印结果
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 100000000 entries, 0 to 99999999
Data columns (total 5 columns):
user_id non-null int64
item_id non-null int64
item_category non-null int64
behavior_type non-null object
time non-null int64
dtypes: int64(4), object(1)
memory usage: 3.7+ GB
df.head()
user_id item_id item_category behavior_type time
0 1 2268318 2520377 pv 1511544070
1 1 2333346 2520771 pv 1511561733
2 1 2576651 149192 pv 1511572885
3 1 3830808 4181361 pv 1511593493
4 1 4365585 2520377 pv 1511596146
# 清洗数据
df.drop_duplicates(subset=['user_id','item_id','time'],keep='first',inplace=True)
# 拆分日期数据
import datetime
import time
# 数据类型转换 将time列转换为时间格式
df['time'] = df['time'].apply(lambda unix_ts: datetime.datetime.fromtimestamp(unix_ts))
df['week']=df['time'].dt.weekday #date.weekday()返回的0-6代表周一到周日
df['date'] = pd.to_datetime(df['time'].apply(lambda unix_ts: unix_ts.strftime('%Y-%m-%d')))
df['day']=df['time'].dt.day
df['hour']=df['time'].dt.hour
df.head()
user_id item_id item_category behavior_type time week date day hour
0 1 2268318 2520377 pv 2017-11-25 01:21:10 5 2017-11-25 25 1
1 1 2333346 2520771 pv 2017-11-25 06:15:33 5 2017-11-25 25 6
2 1 2576651 149192 pv 2017-11-25 09:21:25 5 2017-11-25 25 9
3 1 3830808 4181361 pv 2017-11-25 15:04:53 5 2017-11-25 25 15
4 1 4365585 2520377 pv 2017-11-25 15:49:06 5 2017-11-25 25 15
二:大数据分析
1 日趋PV UV 数据
# 1 日趋PV UV 数据
#pv_daily记录每天用户操作次数,uv_daily记录每天不同的上线用户数量
pv_daily=df.groupby('date')['user_id'].count().reset_index().rename(columns={'user_id':'pv'})
uv_daily=df.groupby('date')['user_id'].apply(lambda x:x.drop_duplicates().count()).reset_index().rename(columns={'user_id':'uv'})
fig,axes=plt.subplots(2,1,figsize=(14,10),sharex=True)
plt.xlabel('DATE',fontsize=24)
plt.tick_params(labelsize=15)
pv_daily.plot(x='date',y='pv',ax=axes[0],fontsize=20,color='red',alpha=0.6,marker='*')
uv_daily.plot(x='date',y='uv',ax=axes[1],fontsize=20,color='red',alpha=0.6,marker='*')
axes[0].set_title('日趋PV、UV数据')
axes[0].legend(fontsize=20)
axes[1].legend(fontsize=20)

# 喵了个喵:极值严重偏颇,事实也证明数据量并不是越大越好。
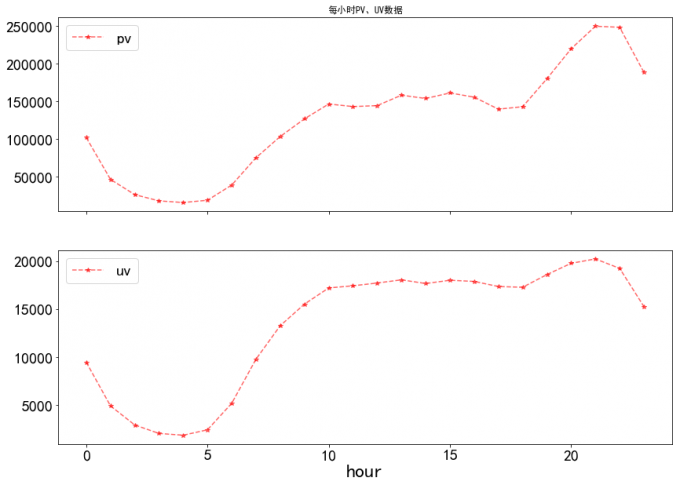
2 每小时 PV、UV 变化趋势
# 2 每小时 PV、UV 变化趋势
#pv_hour记录每小时用户操作次数,uv_hour记录每小时不同的上线用户数量
pv_hour=df.groupby('hour')['user_id'].count().reset_index().rename(columns={'user_id':'pv'})
uv_hour=df.groupby('hour')['user_id'].apply(lambda x:x.drop_duplicates().count()).reset_index().rename(columns={'user_id':'uv'})
fig,axes=plt.subplots(2,1,figsize=(14,10),sharex=True)
plt.xlabel('HOUR',fontsize=24)
plt.tick_params(labelsize=15)
pv_hour.plot(x='hour',y='pv',ax=axes[0],fontsize=20,linestyle='--',color='red',alpha=0.6,marker='*')
uv_hour.plot(x='hour',y='uv',ax=axes[1],fontsize=20,linestyle='--',color='red',alpha=0.6,marker='*')
axes[0].set_title('每小时PV、UV数据')
axes[0].legend(fontsize=20)
axes[1].legend(fontsize=20)
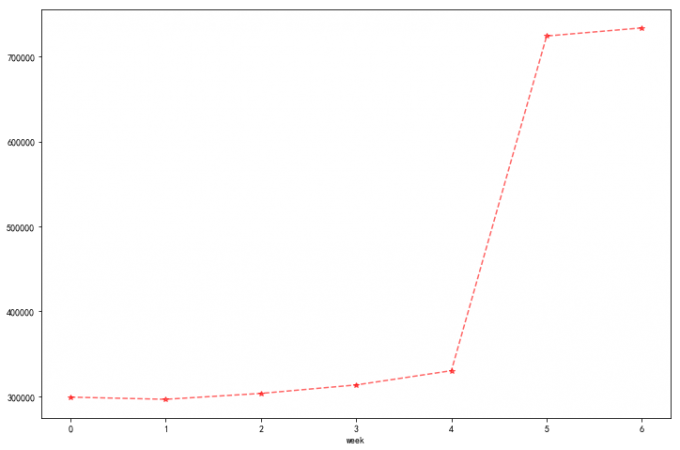
3 每周用户活跃时间段数据分析
# 3 每周用户活跃时间段数据分析:
plt.rcParams['figure.figsize']=(12,8)
df.groupby('week')['user_id'].count().plot(linestyle='--',color='red',alpha=0.6,marker='*')
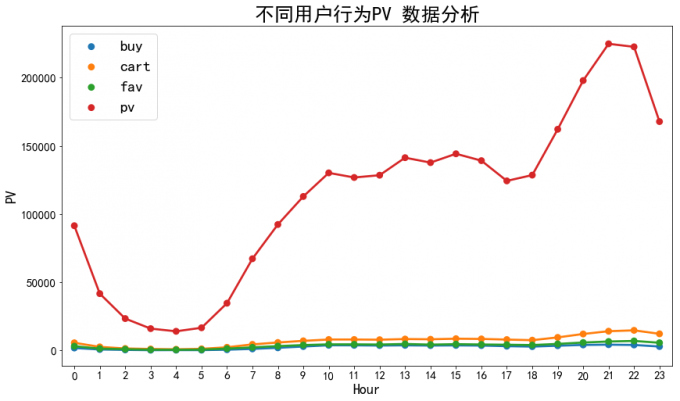
4 不同用户行为类型分析
# 4 不同用户行为类型分析
pv_behavior = df.groupby(['behavior_type','hour'])['user_id'].count().reset_index().rename(columns={'user_id':'PV'})
plt.figure(figsize=(14,8))
plt.rcParams['font.sans-serif']=['SimHei']
ax=sns.pointplot(x='hour',y='PV',hue='behavior_type',data=pv_behavior,fontsize=20)
ax.set_title('不同用户行为PV 数据分析',fontsize=25)
plt.xlabel('Hour',fontsize=18)
plt.ylabel('PV',fontsize=18)
plt.tick_params(labelsize=15)
legend = ax.legend(fontsize=20)
# 喵喵数据:
# 用户浏览pv, 喜欢fav, 收藏cart,购买buy
# 对比分析:去除用户浏览pv 数据
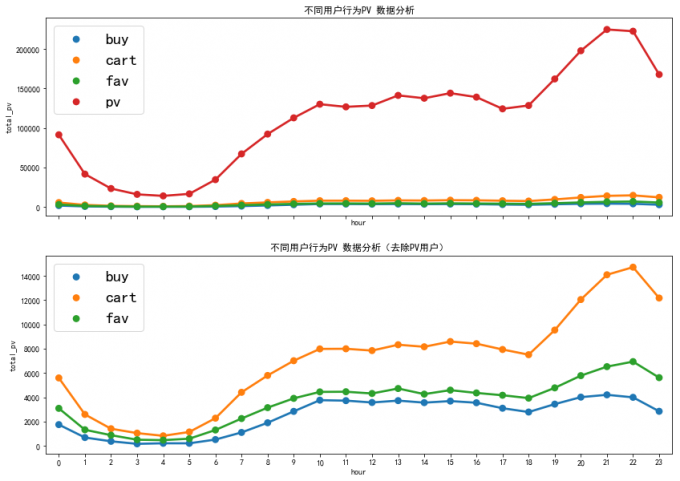
5 对比分析
# 5 对比分析
# 用户点击PV、收藏fav、加入购物车 cart、下订单buy
pv_detail=df.groupby(['behavior_type','hour'])['user_id'].count().reset_index().rename(columns={'user_id':'total_pv'})
fig,axes=plt.subplots(2,1,figsize=(14,10),sharex=True)
sns.pointplot(x='hour',y='total_pv',hue='behavior_type',data=pv_detail,ax=axes[0])
sns.pointplot(x='hour',y='total_pv',hue='behavior_type',data=pv_detail[pv_detail.behavior_type!='pv'],ax=axes[1])
axes[0].set_title('不同用户行为PV 数据分析')
axes[1].set_title('不同用户行为PV 数据分析(去除PV用户)')
axes[0].legend(fontsize=20)
axes[1].legend(fontsize=20)
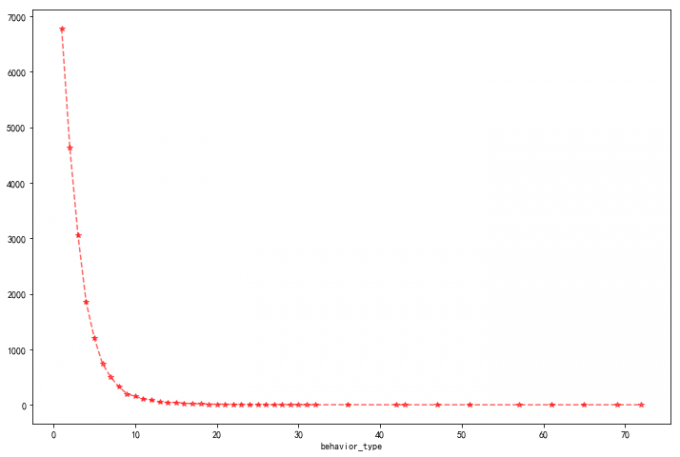
6 用户购买次数分布
# 6 用户购买次数分布
df_f=df[df['behavior_type']=='buy'].groupby('user_id')['behavior_type'].count().reset_index().groupby('behavior_type')['user_id'].count()
df_f.plot(linestyle='--',color='red',alpha=0.6,marker='*')
# 喵喵数据:
# 可以刺激用户购买欲望:购买次数集中在1-7之间,表明用户复购意愿较强,可继续引导。
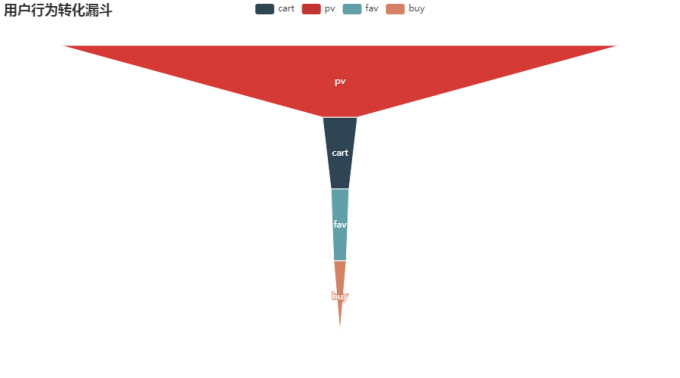
7 用户行为数据转化漏斗
# 7 用户行为数据转化漏斗
from pyecharts import options as opts
from pyecharts.charts import Bar,Pie
from pyecharts.globals import ChartType, SymbolType
from pyecharts.charts import Funnel
from pyecharts.charts import Bar
Funnel_behavior=df.groupby(['behavior_type'])['user_id'].count().reset_index().rename(columns={'user_id':'Count'}).sort_values(by='Count',ascending=False)
value=Funnel_behavior['Count'].tolist()
x=Funnel_behavior['behavior_type'].tolist()
c=Funnel()
c.add('',[list(z) for z in zip(Funnel_behavior['behavior_type'],Funnel_behavior['Count'])],label_opts=opts.LabelOpts(position="inside"))
c.set_global_opts(title_opts=opts.TitleOpts(title="用户行为转化漏斗"))
c.render_notebook()
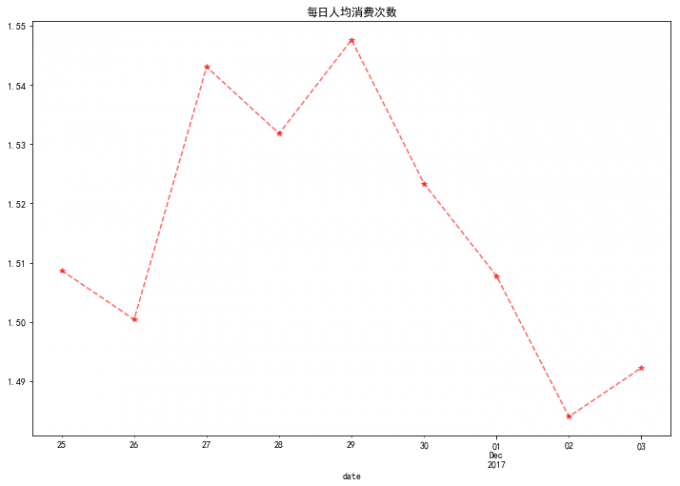
8 每日人均消费次数
# 8 每日人均消费次数
# ARPPU(average revenue per paying user)是指从每位付费用户身上获得的收入,它反映的是每个付费用户的平均付费额度。
# ARPPU=总收入/活跃用户付费数量
# 本数据无金额,用次数代替金额。人均消费次数=消费总次数/消费人数
data_use_buy=df[df.behavior_type=='buy'].groupby(['date','user_id'])['behavior_type'].count().reset_index().rename(columns={'behavior_type':'total'})
user_daily_ARPPU=data_use_buy.groupby('date').apply(lambda x:x.total.sum()/x.total.count())
user_daily_ARPPU.plot(linestyle='--',color='red',alpha=0.6,marker='*')
plt.title('每日人均消费次数')
# 喵喵数据:
# 平均每天消费次数在低值区域波动
9 同一时间段用户消费次数分布
# 9 同一时间段用户消费次数分布
data_user_buy3=df[df.behavior_type=='buy'].groupby(['user_id','date','hour'])['operation'].sum().rename('buy_count')
sns.distplot(data_user_buy3,color='red')
print('大多数用户消费:{}次'.format(data_user_buy3.mode()[0]))
大多数用户消费:1次

10 复购率
# 10 复购率
#data_rebuy为找出每个用户有消费行为的天数
data_rebuy = df[df['behavior_type']=='buy'].groupby('user_id')['time'].apply(lambda x :len(x.unique()))
print('复购率:',round(data_rebuy[data_rebuy>=2].count()/data_rebuy.count(),2))
data_rebuy.
复购率: 0.63
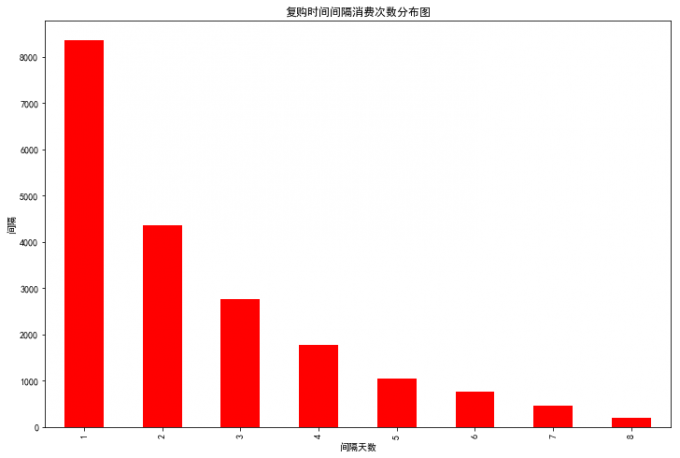
复购时间间隔消费次数分布
# 复购时间间隔消费次数分布
data_day_buy=df[df.behavior_type=='buy'].groupby(['user_id','date']).count().reset_index()
data_user_buy4=data_day_buy.groupby('user_id').date.apply(lambda x:x.sort_values().diff(1).dropna())
data_user_buy4=data_user_buy4.map(lambda x:x.days)
plt.rcParams['figure.figsize']=(12,8)
data_user_buy4.value_counts().plot(kind='bar',color='red')
plt.title('复购时间间隔消费次数分布图')
plt.xlabel('间隔天数')
plt.ylabel('间隔')
11 最受欢迎的商品类目与购买率
# 11 最受欢迎的商品类目与购买率
##按“类目item_category ”统计点击量pv
pvtop=df[df['behavior_type']=='pv']['item_category'].value_counts().sort_values(ascending=False)
pvtop.name='pv_category'
#按“类目item_category ”统计购买量buy
buytop=df[df['behavior_type']=='buy']['item_category'].value_counts().sort_values(ascending=False)
buytop.name = 'buy_category'
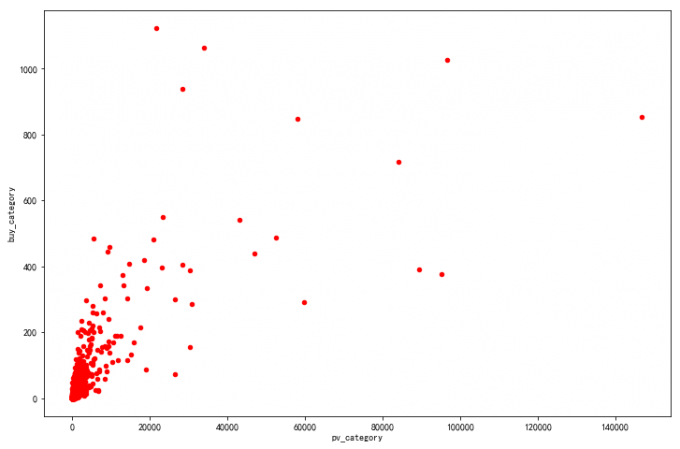
# 绘制散点图,合并(匹配 concat ,axis=1,按行拼接):
cattop=pd.concat([pvtop,buytop],axis=1,sort=False).fillna(0)
cattop.plot.scatter(x='pv_category',y='buy_category',color='red')
# 喵了喵:
# 大部分商品类目转化率不足1%:pv_category / buy_category)。
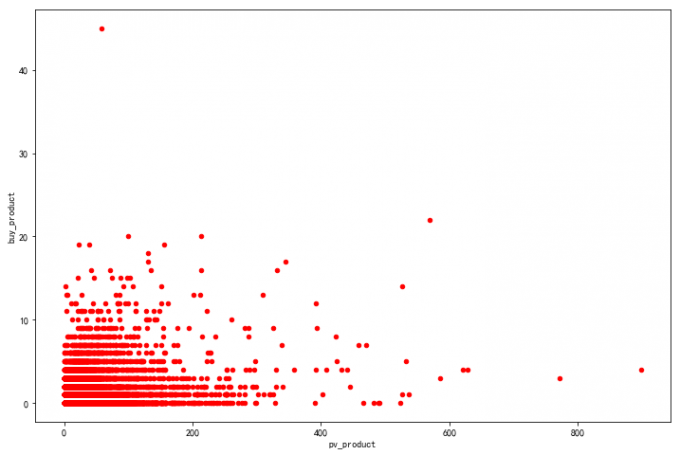
# 按“商品(item_id)”统计点击量pv
pv_p_top=df[df['behavior_type']=='pv']['item_id'].value_counts().sort_values(ascending=False)
pv_p_top.name='pv_product'
#按“商品(item_id)”统计购买量buy
buy_p_top=df[df['behavior_type']=='buy']['item_id'].value_counts().sort_values(ascending=False)
buy_p_top.name = 'buy_product'
# 绘制散点图:
producttop=pd.concat([pv_p_top,buy_p_top],axis=1,sort=False).fillna(0)
producttop.plot.scatter(x='pv_product',y='buy_product',color='red')
# 喵喵数据:
# 最受欢迎的商品浏览量在0-200之间、购买数在0-10之间
# 考虑提升一下商品的文案、展示等。
根据前文《7万网站用户行为大数据分析》,我们好像找到了KPI 翻倍的方法论:
1)基于RFM模型,及机器学习聚类分析,根据不同类型用户精准运营,运用二八理论将主要资源和精力集中于一类用户,进行个性化推荐;-70%
2)根据时间维度进行有效地拉新促活活动,以及老用户的访问。根据复购率来刺激用户的持续消费,根据留存监控用户的持续用户行为,防止流失并且对用户行为给与一定的刺激;-10%
3)对高价值用户需要提供优惠策略使其保持活跃度,针对不同用户行为人群制定针对性策略从而刺激进一步的用户行为,针对不活跃用户以及大部分的低购买用户采取相应措施刺激或者提高活跃度,引导用户尽量30天以内复购,提高用户活跃度、留存率、付费率。-10%
4)针对一些转化率低的商品,做好价格、图片等因素的改善,提高转化率。-5%
5)还有5%,你知道是什么吗?
欢迎转发、交流小数据。
欢迎关注:一只阿木木