首先看下Map的框架图
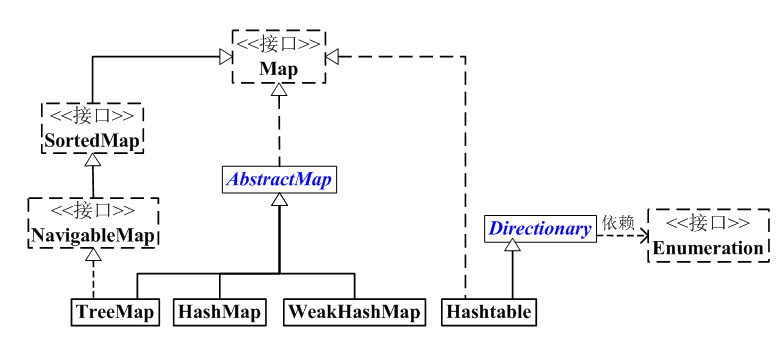
1、Map概述
1、Map是键值对映射的抽象接口
2、AbstractMap实现了Map中绝大部分的函数接口,它减少了“Map实现类”的重复编码
3、SortedMap有序的“键值对”映射接口
4、NavigableMap是继承与SortedMap的,支持导航函数的接口
5、HashMap Hashtable TreeMap WeakHashMap 这4个类是“键值对”映射的实现类,他们各有区别
HashMap 是基于“拉链法”实现的散列表。一般用于单线程的程序中
HashTable 也是基于“拉链发”实现的散列表, 他一般用户多线程程序中
WeakHashMap 也是基于"拉链法"实现的散列表,它一般也用于单线程程序中,相比HashMap, WeakHashMap中的键是弱键,当弱键被GC回收时,它对应的键值对也会被从WeakHashMap中删除;而HashMap中的键是强健
TreeMap 是有序的散列表,它是通过红黑树实现的。它一般用于单线程中存储有序的映射
HashMap和HashTable的异同
第2.1部分 HashMap和Hashtable的相同点
HashMap和Hashtable都是存储“键值对(key-value)”的散列表,而且都是采用拉链法实现的。
存储的思想都是:通过table数组存储,数组的每一个元素都是一个Entry;而一个Entry就是一个单向链表,Entry链表中的每一个节点就保存了key-value键值对数据。
添加key-value键值对:首先,根据key值计算出哈希值,再计算出数组索引(即,该key-value在table中的索引)。然后,根据数组索引找到Entry(即,单向链表),再遍历单向链表,将key和链表中的每一个节点的key进行对比。若key已经存在Entry链表中,则用该value值取代旧的value值;若key不存在Entry链表中,则新建一个key-value节点,并将该节点插入Entry链表的表头位置。
删除key-value键值对:删除键值对,相比于“添加键值对”来说,简单很多。首先,还是根据key计算出哈希值,再计算出数组索引(即,该key-value在table中的索引)。然后,根据索引找出Entry(即,单向链表)。若节点key-value存在与链表Entry中,则删除链表中的节点即可。
上面介绍了HashMap和Hashtable的相同点。正是由于它们都是散列表,我们关注更多的是“它们的区别,以及它们分别适合在什么情况下使用”。那接下来,我们先看看它们的区别。
第2.2部分 HashMap和Hashtable的不同点
1 继承和实现方式不同
HashMap 继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。
Hashtable 继承于Dictionary,实现了Map、Cloneable、java.io.Serializable接口。
HashMap的定义:
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable { ... }
Hashtable的定义:
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable { ... }
从中,我们可以看出:
1.1 HashMap和Hashtable都实现了Map、Cloneable、java.io.Serializable接口。
实现了Map接口,意味着它们都支持key-value键值对操作。支持“添加key-value键值对”、“获取key”、“获取value”、“获取map大小”、“清空map”等基本的key-value键值对操作。
实现了Cloneable接口,意味着它能被克隆。
实现了java.io.Serializable接口,意味着它们支持序列化,能通过序列化去传输。
1.2 HashMap继承于AbstractMap,而Hashtable继承于Dictionary
Dictionary是一个抽象类,它直接继承于Object类,没有实现任何接口。Dictionary类是JDK 1.0的引入的。虽然Dictionary也支持“添加key-value键值对”、“获取value”、“获取大小”等基本操作,但它的API函数比Map少;而且 Dictionary一般是通过Enumeration(枚举类)去遍历,Map则是通过Iterator(迭代器)去遍历。 然而‘由于Hashtable也实现了Map接口,所以,它即支持Enumeration遍历,也支持Iterator遍历。关于这点,后面还会进一步说明。
AbstractMap是一个抽象类,它实现了Map接口的绝大部分API函数;为Map的具体实现类提供了极大的便利。它是JDK 1.2新增的类。
2 线程安全不同
Hashtable的几乎所有函数都是同步的,即它是线程安全的,支持多线程。
而HashMap的函数则是非同步的,它不是线程安全的。若要在多线程中使用HashMap,需要我们额外的进行同步处理。 对HashMap的同步处理可以使用Collections类提供的synchronizedMap静态方法,或者直接使用JDK 5.0之后提供的java.util.concurrent包里的ConcurrentHashMap类。
3 对null值的处理不同
HashMap的key、value都可以为null。
Hashtable的key、value都不可以为null。
我们先看看HashMap和Hashtable “添加key-value”的方法
HashMap的添加key-value的方法
 View Code
View CodeHashtable的添加key-value的方法
View Code根据上面的代码,我们可以看出:
Hashtable的key或value,都不能为null!否则,会抛出异常NullPointerException。
HashMap的key、value都可以为null。 当HashMap的key为null时,HashMap会将其固定的插入table[0]位置(即HashMap散列表的第一个位置);而且table[0]处只会容纳一个key为null的值,当有多个key为null的值插入的时候,table[0]会保留最后插入的value。
4 支持的遍历种类不同
HashMap只支持Iterator(迭代器)遍历。
而Hashtable支持Iterator(迭代器)和Enumeration(枚举器)两种方式遍历。
Enumeration 是JDK 1.0添加的接口,只有hasMoreElements(), nextElement() 两个API接口,不能通过Enumeration()对元素进行修改 。
而Iterator 是JDK 1.2才添加的接口,支持hasNext(), next(), remove() 三个API接口。HashMap也是JDK 1.2版本才添加的,所以用Iterator取代Enumeration,HashMap只支持Iterator遍历。
5 通过Iterator迭代器遍历时,遍历的顺序不同
HashMap是“从前向后”的遍历数组;再对数组具体某一项对应的链表,从表头开始进行遍历。
Hashtabl是“从后往前”的遍历数组;再对数组具体某一项对应的链表,从表头开始进行遍历。
HashMap和Hashtable都实现Map接口,所以支持获取它们“key的集合”、“value的集合”、“key-value的集合”,然后通过Iterator对这些集合进行遍历。
由于“key的集合”、“value的集合”、“key-value的集合”的遍历原理都是一样的;下面,我以遍历“key-value的集合”来进行说明。
HashMap 和Hashtable 遍历"key-value集合"的方式是:(01) 通过entrySet()获取“Map.Entry集合”。 (02) 通过iterator()获取“Map.Entry集合”的迭代器,再进行遍历。
HashMap的实现方式:先“从前向后”的遍历数组;对数组具体某一项对应的链表,则从表头开始往后遍历。
View CodeHashtable的实现方式:先从“后向往前”的遍历数组;对数组具体某一项对应的链表,则从表头开始往后遍历。
View Code6 容量的初始值 和 增加方式都不一样
HashMap默认的容量大小是16;增加容量时,每次将容量变为“原始容量x2”。
Hashtable默认的容量大小是11;增加容量时,每次将容量变为“原始容量x2 + 1”。
HashMap默认的“加载因子”是0.75, 默认的容量大小是16。
View Code当HashMap的 “实际容量” >= “阈值”时,(阈值 = 总的容量 * 加载因子),就将HashMap的容量翻倍。
View CodeHashtable默认的“加载因子”是0.75, 默认的容量大小是11。
View Code当Hashtable的 “实际容量” >= “阈值”时,(阈值 = 总的容量 x 加载因子),就将变为“原始容量x2 + 1”。
View Code7 添加key-value时的hash值算法不同
HashMap添加元素时,是使用自定义的哈希算法。
Hashtable没有自定义哈希算法,而直接采用的key的hashCode()。
HashMap添加元素时,是使用自定义的哈希算法。
View Code Hashtable没有自定义哈希算法,而直接采用的key的hashCode()。
View Code8 部分API不同
Hashtable支持contains(Object value)方法,而且重写了toString()方法;
而HashMap不支持contains(Object value)方法,没有重写toString()方法。
最后,再说说“HashMap和Hashtable”使用的情景。
其实,若了解它们之间的不同之处后,可以很容易的区分根据情况进行取舍。例如:(01) 若在单线程中,我们往往会选择HashMap;而在多线程中,则会选择Hashtable。(02),若不能插入null元素,则选择Hashtable;否则,可以选择HashMap。
但这个不是绝对的标准。例如,在多线程中,我们可以自己对HashMap进行同步,也可以选择ConcurrentHashMap。当HashMap和Hashtable都不能满足自己的需求时,还可以考虑新定义一个类,继承或重新实现散列表;当然,一般情况下是不需要的了。
HashMap和WeakHashMap异同
3.1 HashMap和WeakHashMap的相同点
1 它们都是散列表,存储的是“键值对”映射。
2 它们都继承于AbstractMap,并且实现Map基础。
3 它们的构造函数都一样。
它们都包括4个构造函数,而且函数的参数都一样。
4 默认的容量大小是16,默认的加载因子是0.75。
5 它们的“键”和“值”都允许为null。
6 它们都是“非同步的”。
3.2 HashMap和WeakHashMap的不同点
1 HashMap实现了Cloneable和Serializable接口,而WeakHashMap没有。
HashMap实现Cloneable,意味着它能通过clone()克隆自己。
HashMap实现Serializable,意味着它支持序列化,能通过序列化去传输。
2 HashMap的“键”是“强引用(StrongReference)”,而WeakHashMap的键是“弱引用(WeakReference)”。
WeakReference的“弱键”能实现WeakReference对“键值对”的动态回收。当“弱键”不再被使用到时,GC会回收它,WeakReference也会将“弱键”对应的键值对删除。
这个“弱键”实现的动态回收“键值对”的原理呢?其实,通过WeakReference(弱引用)和ReferenceQueue(引用队列)实现的。 首先,我们需要了解WeakHashMap中:
第一,“键”是WeakReference,即key是弱键。
第二,ReferenceQueue是一个引用队列,它是和WeakHashMap联合使用的。当弱引用所引用的对象被垃圾回收,Java虚拟机就会把这个弱引用加入到与之关联的引用队列中。 WeakHashMap中的ReferenceQueue是queue。
第三,WeakHashMap是通过数组实现的,我们假设这个数组是table。
接下来,说说“动态回收”的步骤。
(01) 新建WeakHashMap,将“键值对”添加到WeakHashMap中。
将“键值对”添加到WeakHashMap中时,添加的键都是弱键。
实际上,WeakHashMap是通过数组table保存Entry(键值对);每一个Entry实际上是一个单向链表,即Entry是键值对链表。
(02) 当某“弱键”不再被其它对象引用,并被GC回收时。在GC回收该“弱键”时,这个“弱键”也同时会被添加到queue队列中。
例如,当我们在将“弱键”key添加到WeakHashMap之后;后来将key设为null。这时,便没有外部外部对象再引用该了key。
接着,当Java虚拟机的GC回收内存时,会回收key的相关内存;同时,将key添加到queue队列中。
(03) 当下一次我们需要操作WeakHashMap时,会先同步table和queue。table中保存了全部的键值对,而queue中保存被GC回收的“弱键”;同步它们,就是删除table中被GC回收的“弱键”对应的键值对。
例如,当我们“读取WeakHashMap中的元素或获取WeakReference的大小时”,它会先同步table和queue,目的是“删除table中被GC回收的‘弱键’对应的键值对”。删除的方法就是逐个比较“table中元素的‘键’和queue中的‘键’”,若它们相当,则删除“table中的该键值对”。
本文转自:http://www.cnblogs.com/skywang12345/p/3311126.html