Hive常用的数据类型概述
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.基本数据类型
|
Hive数据类型 |
对应Java数据类型 |
长度(数据取值范围) |
备注 |
|
TINYINT |
byte |
1 byte有符号(即最高位为"符号位",下同)整数(取值范围为:-128~127) |
|
|
SMALINT |
short |
2 byte有符号整数(取值范围为: -32768~32767) |
|
|
INT |
int |
4 byte有符号整数(取值范围为: -2147483648~2147483647) |
|
|
BIGINT |
long |
8 byte有符号整数(取值范围为: -9223372036854775808~9223372036854775807) |
|
|
BOOLEAN |
boolean |
布尔类型(取值范围:true,false) |
|
|
FLOAT |
float |
4 byte的单精度浮点数(1位符号位,8位指数,23位小数) |
其中小数部分(2 ** 23)对应最大的十进制数字为:8388608,这是一个7位十进制数字。 可惜呀,这个数字要比9999999小,因此为了百分百保证精度,我们通常说float精度可以保证十进制的6位运算。 |
|
DOUBLE |
double |
8 byte的双精度浮点数(1位符号位,11位指数,52位小数) |
其中小数部分(2 ** 52)对应最大的十进制数字为:4503599627370496,这是一个16位十进制数字。 同理,这个数字要比9999999999999999小,因此为了百分百保证精度,我们通常说double精度可以保证十进制的15位运算。 |
|
STRING |
string |
可以使用单引号('')或者双引号("")定义字符串,他是一个字符集合。 |
当然,关于字符集合自然会设计到字符编码问题哟~ |
|
TIMESTAMP |
|
时间类型 |
|
|
BINARY |
|
字节数组 |
|
温馨提示:
对于Hive的String类型相当于MySQL数据库的varchar类型,该类型是一个可变的字符串。不过它不能声明其中最多能存储多少个字符,但理论上它可以存储2GB的字符数。
在Java编程中,如果double类型都无法表示的精度,可以使用java中的BigDecimal类型,它能支持跟高精度的运算哟~
二.集合数据类型
Hive有三种复杂数据类型ARRAY、MAP和STRUCT。如下所示: ARRAY: 数组是一组具有相同类型和名称的变量的集合。这些变量称为数组的元素,每个数组元素都有一个编号,编号从零开始。与Java中的Array类似。 MAP: MAP是一组键-值对元组集合,使用数组表示法可以访问数据。与Java中的Map类似。 STRUCT: 和c语言中的struct类似,都可以通过“点”符号访问元素内容。
接下来我们来一起看一个案例,来体会一下这三种复杂数据类型。
1>. 假设某表有如下两行,我们用JSON格式来表示其数据结构(注释内容为Hive中的访问格式)。
{ "name": "曹操", "friends": ["荀彧" , "典韦"] , //列表Array, "children": { //键值Map, "曹昂": 30, "曹丕": 25, "曹彰":22, "曹冲":18 } "address": { //结构Struct, "street": "丞相府" , "city": "许昌" } }, { "name": "刘备", "friends": ["诸葛亮" , "庞统"] , //列表Array, "children": { //键值Map, "刘禅": 25, "刘永": 20, "刘理":15 } "address": { //结构Struct, "street": "武担山", "city": "成都" } }, ...
2>.基于上述数据结构,我们在Hive里创建对应的表,并导入数据。
[root@hadoop105.yinzhengjie.com ~]# vim sanguo.txt [root@hadoop105.yinzhengjie.com ~]# [root@hadoop105.yinzhengjie.com ~]# cat sanguo.txt 曹操,荀彧_典韦,曹昂_:30_曹丕:25_曹彰:22_曹冲:18,丞相府_许昌 刘备,诸葛亮_庞统,刘禅:25_刘永:20_刘理:15,武担山_成都 [root@hadoop105.yinzhengjie.com ~]# 温馨提示: MAP,STRUCT和ARRAY里的元素间关系都可以用同一个字符表示,这里用"_"。
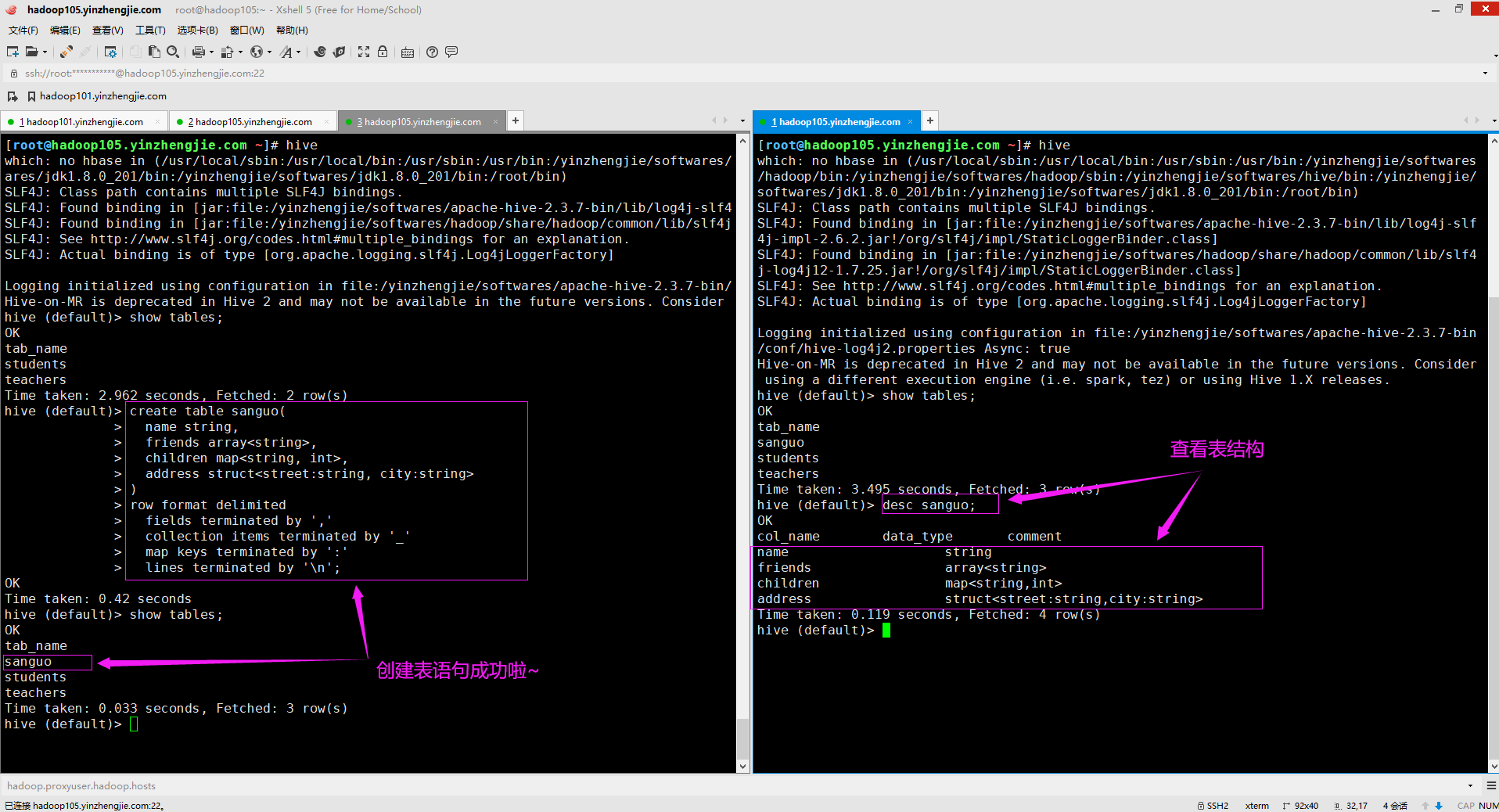
3>.Hive上创建测试表(sanguo)
create table sanguo( name string, friends array<string>, children map<string, int>, address struct<street:string, city:string> ) row format delimited fields terminated by ',' collection items terminated by '_' map keys terminated by ':' lines terminated by ' '; 行格式定义(row format delimited)参数含义如下所示: fields terminated by ',' 指定列分隔符。 collection items terminated by '_' 指定MAP STRUCT 和 ARRAY 的分隔符(数据分割符号) map keys terminated by ':' 指定MAP中的key与value的分隔符 lines terminated by ' '; 指定行分隔符,若不指定,则默认为" "。
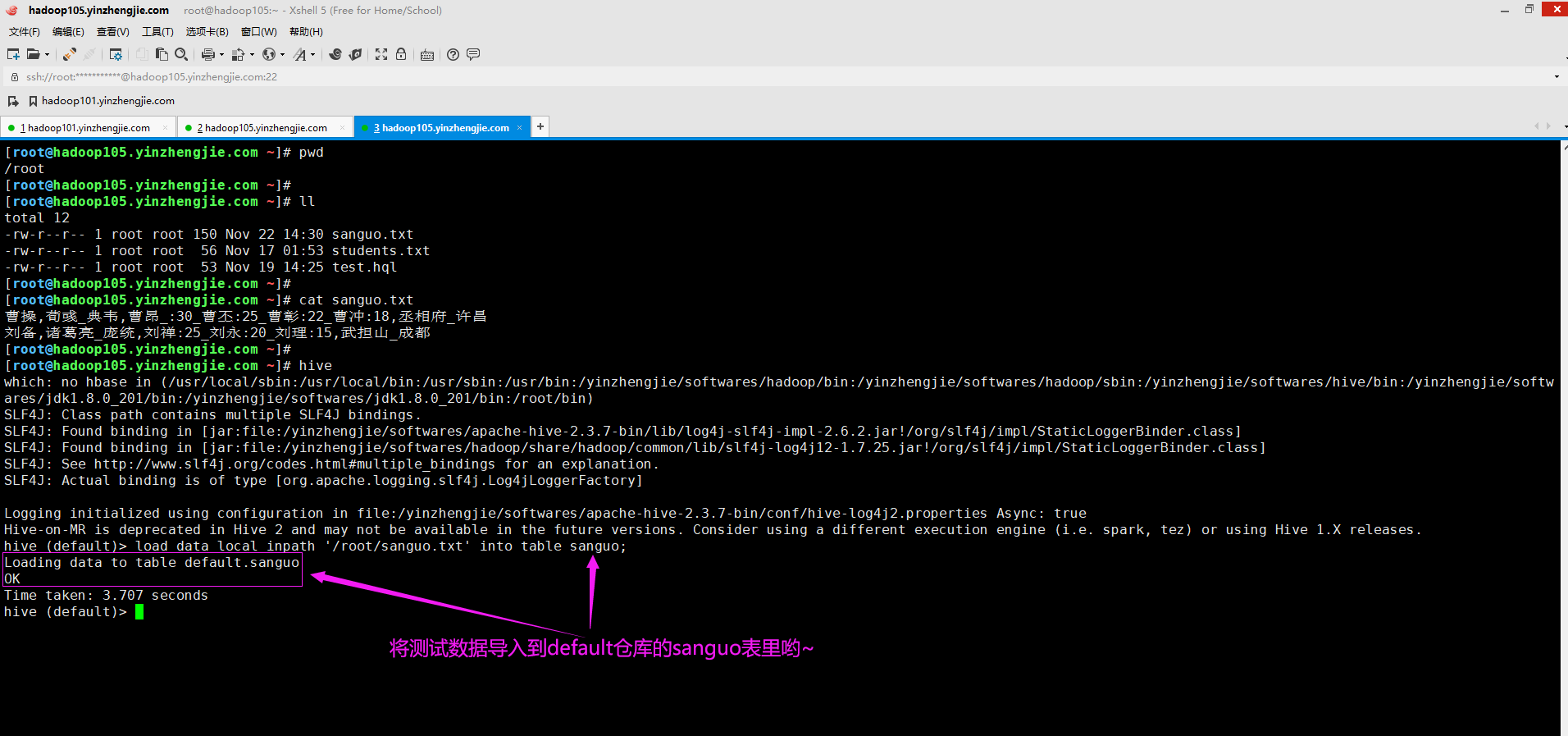
4>.导入文本数据到测试表
load data local inpath '/root/sanguo.txt' into table sanguo;
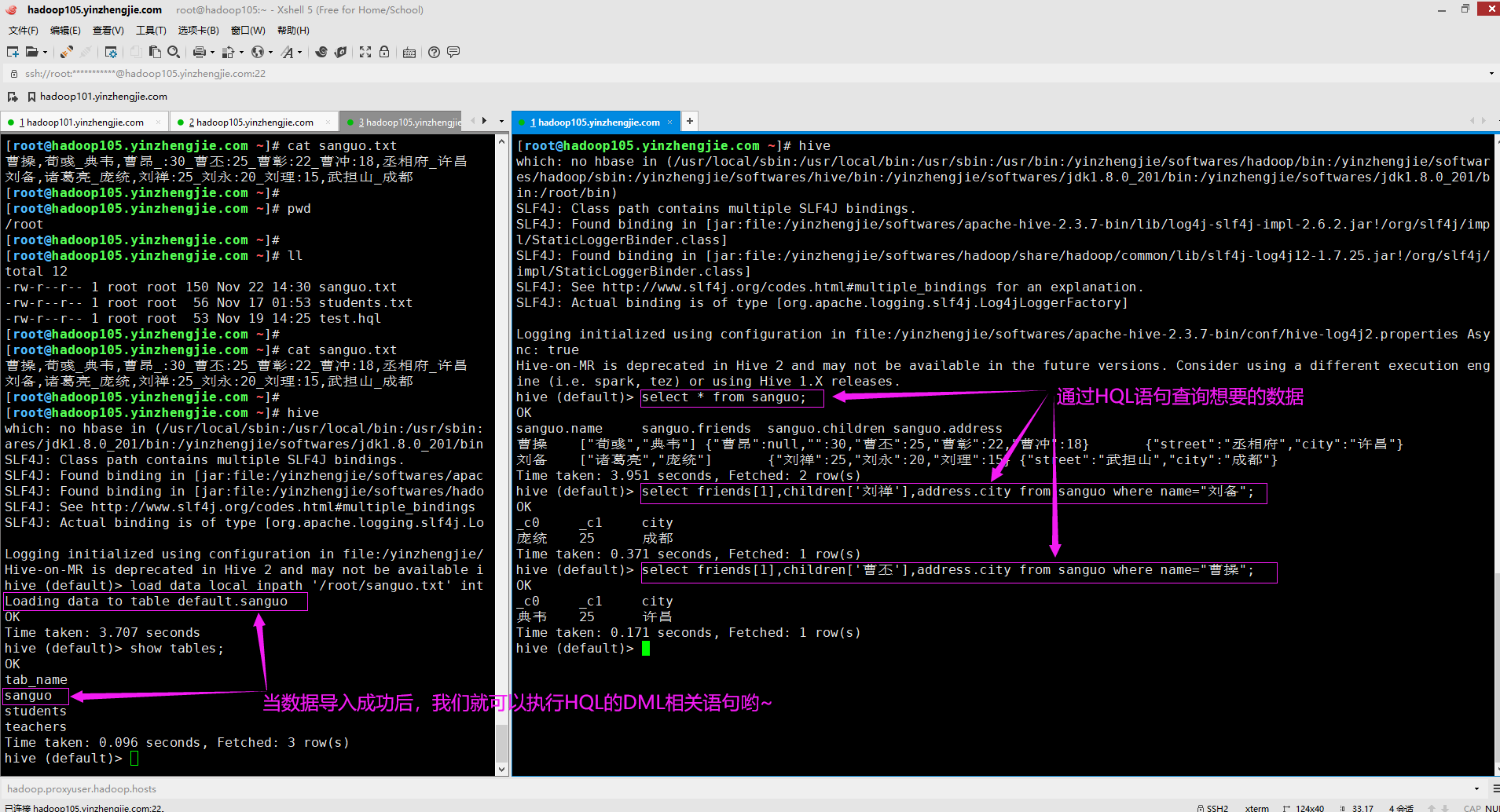
5>.访问三种集合列里的数据,以下分别是ARRAY,MAP,STRUCT的访问方式
select * from sanguo; select friends[1],children['刘禅'],address.city from sanguo where name="刘备"; select friends[1],children['曹丕'],address.city from sanguo where name="曹操";
三.类型转换
1>.类型转换概述
Hive的原子数据类型(其实就是基础数据类型)是可以进行隐式转换的。
类似于Java的类型转换,例如某表达式使用INT类型,TINYINT会自动转换为INT类型。
但是Hive不会进行反向转化,例如,某表达式使用TINYINT类型,INT不会自动转换为TINYINT类型,它会返回错误,除非使用CAST操作进行强制类型转换。
综上所述,隐式类型转换我们称为自动类型转换,它可以从小的范围转换到大的范围。强制类型转换则是从大的类型范围转换为小的类型范围(可能存在数据丢失的风险)。
2>.隐式类型转换规则
隐式类型转换规则如下所示: (1)任何整数类型都可以隐式地转换为一个范围更广的类型,如TINYINT可以转换成INT,INT可以转换成BIGINT。 (2)所有整数类型、FLOAT和STRING类型都可以隐式地转换成DOUBLE。 (3)TINYINT、SMALLINT、INT都可以转换为FLOAT。 (4)BOOLEAN类型不可以转换为任何其它的类型。
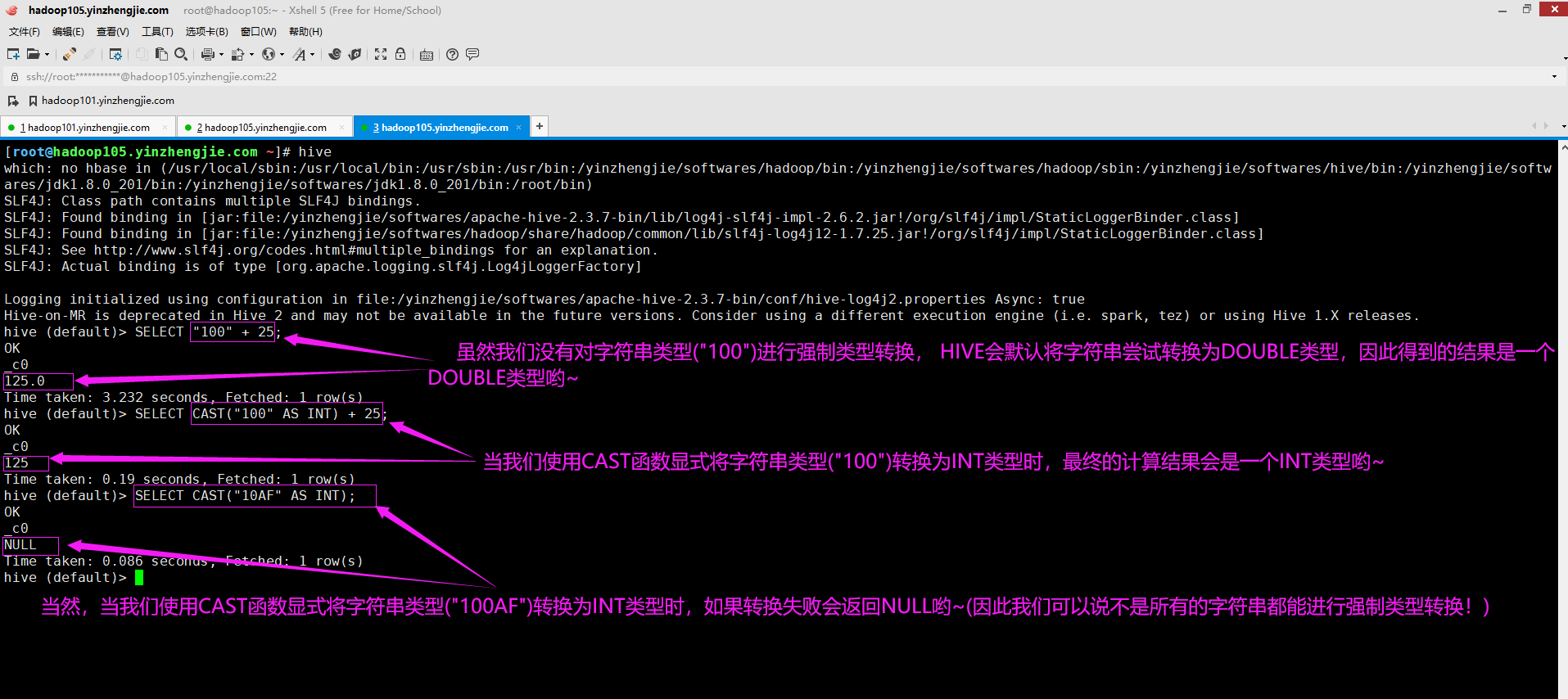
3>.强制类型转换(可以使用CAST操作显示进行数据类型转换)
SELECT "100" + 25; // 这里会自动发生类型转换,将字符串类型转换成DOUBLE类型。 SELECT CAST("100" AS INT) + 25; // 这里我们将字符串类型转换为INT类型。 SELECT CAST("10AF" AS INT); // 当类型转换失败时会返回NULL。