HDFS集中式高速缓存管理及短路读取案例
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.HDFS中集中式缓存概述
1>.Hadoop缓存概述
通常datanode从磁盘中读取数据块,但对于访问频繁的文件(例如小型Hive事实表),其对应的块可能被显式地缓存在datanode的内存中,以堆外缓存的形式存在。可以使用Hadoop的集中式缓存管理来显示缓存指定路径。可以在文件或目录级别缓存数据。当缓存路径时,NameNode会指定拥有该文件块的DataNode将这些块从磁盘缓存起来,实质上时将这些快缓存至内存中。 默认情况下,一个数据块仅缓存在一个datanode的内存中,当然可以针对每个文件配置datanode的数量。用户或应用通过在缓存池(cache pool,是一个用于管理缓存权限和资源使用的管理性分组)中增加一个cache directive来告诉namenode需要缓存哪些文件及缓存多久。 当工作集的总量大于RAM时,服务器会从内存中置换出数据,为新数据腾出空间。缓存大数据集用于查询效率不高的情况,因为很可能不会重复读取这些相同的数据集。可以考虑使用严格的SLA(服务级别协议)缓存关键工作负载的数据,以防止这些数据竞争磁盘I/O。缓存在磁盘争用的集群中特别有用。 温馨提示: Cloudera工程师进行的测试表明,与从磁盘读取数据相比,Impala等应用程序从缓存读取的速度提高了59倍。
2>.Hadoop和OS的页面缓存
Hadoop和DataNode使用操作系统的页面缓存,该缓存策略会缓存最近访问的所有数据到本地文件系统。但是,在像Hadoop这样的分布式系统中,仅使用操作系统页面缓存时不够的。由于没有每个DataNode的内存状态的全局信息,因此当提供多个HDFS副本时,客户端无法根据局部缓存性进行任务调度。所以性能有所损失,因为客户端在不知道局部缓存的情况下进行任务调度。
当客户端运行查询时,应用调度程序选择一个数据块副本位置,并在该DataNode上运行任务,且将副本拉入操作系统页面缓存。但是,调度程序不知道存储在页面缓存中的副本,因而不能利用局部缓存来分配任务。
另一个问题是,由于大多数操作系统的页面缓存使用LRU(最近最少使用)算法的修改版本来确定他们应该保存在内存中的数据,因此他们可能会从缓存中置换出用户的工作数据集。
操作系统页面缓存不好的另一个原因是,它比直接从内存读取效率低,因为直接从内存读取提供了"零读取复制(俗称零拷贝)"性能。
3>.集中式缓存的关键原则及原理概述
NameNode的集中式缓存管理遵循以下关键原则: (1)掌握集中式缓存的状态,这有助于局部缓存调度作业; (2)可预测的混合负载性能,通过集群高速缓存状态感知; (3)通过将当前数据集固定在本地缓存中而不是将其刷新到磁盘,可以实现零读取复制。 缓存池对可以使用的内存量设置限制,用户通过缓存指令管理缓存。缓存指令可以指定以下内容: (1)要缓存的HDFS文件或目录,由路径指示; (2)缓存复制因子(从1到文件的复制因子); (3)指令的缓存池。 HDFS集中式缓存管理的工作原理如下: (1)当HDFS客户端缓存文件时,它会向NameNode发送一个缓存指令,请求缓存该文件; (2)NameNode向DataNode发送缓存命令; (3)一旦缓存了数据,DataNode就会发送一个缓存报告; (4)应用调度程序可以从NameNode找到缓存信息,并依据局部缓存进行任务的调度。 DataNode在堆外内存缓存数据,这意味着缓存大量数据不会对垃圾回收产生不利影响。HDFS将缓存块从页面缓存直接映射到客户端的地址空间,这避免了重复读取的系统调用中涉及的上下文切换开销。零读取复制时结果,顾名思义,它花费了很少的时间复制数据,大部分CPU周期可用于"实际工作"。集中式高速缓存管理的另一个好处是,由于DataNode在缓存数据时会对数据进行校验,因此客户端在读取数据时可以跳过校验和验证。 可以通过将任务与高速缓存块副本进行协同定位来提高应用程序的读取性能。然后,应用程序在确定防止任务的位置时查询缓存块位置集。集群内存应用程序也更高效,因为只能固定一个块的三个副本中的一个,所以不需要再重复读取块之后将块的所有副本若如缓冲区高速缓存。
4>.配置缓存注意事项
可以使用hdfs cacheadmin命令行接口配置缓存。cacheadmin命令用于配置缓存指令和缓存池,这两个组件是缓存HDFS数据时所必须配置的关键组件。 在实现HDFS缓存时,必须增加锁定内存的操作系统限制。将"hdfs-site.xml"中的"dfs.datanode.max.locked.memory"参数设置为DataNode节点最大锁定内存软ulimit可用于缓存的最大内存量,否则在DataNode在启动时会中止。 尽管使用"ulimit -l"命令显示内存锁定限制以千字节(KB)为单位,但必须以字节(Bytes)为单位指定此属性。默认情况下,此参数设置为0,这将禁用内存中的缓存。如果本机库对DataNode不可用,则配置不起作用。
在Linux系统中,当设置"dfs.datanode.max.locked.memory"参数时,可能还需要调高"/etc/security/limits.conf"文件中"memlock"属性的值。生产环境我推荐缓存中内存设置阈值可以考虑在节点内存的5%~10%左右即可。
5>. 缓存指令
[root@hadoop101.yinzhengjie.com ~]# hdfs cacheadmin Usage: bin/hdfs cacheadmin [COMMAND] [-addDirective -path <path> -pool <pool-name> [-force] [-replication <replication>] [-ttl <time-to-live>]] [-modifyDirective -id <id> [-path <path>] [-force] [-replication <replication>] [-pool <pool-name>] [-ttl <time-to-live>]] [-listDirectives [-stats] [-path <path>] [-pool <pool>] [-id <id>]] [-removeDirective <id>] [-removeDirectives -path <path>] [-addPool <name> [-owner <owner>] [-group <group>] [-mode <mode>] [-limit <limit>] [-defaultReplication <defaultReplication>] [-maxTtl <maxTtl>]] [-modifyPool <name> [-owner <owner>] [-group <group>] [-mode <mode>] [-limit <limit>] [-defaultReplication <defaultReplication>] [-maxTtl <maxTtl>]] [-removePool <name>] [-listPools [-stats] [<name>]] [-help <command-name>] Generic options supported are: -conf <configuration file> specify an application configuration file -D <property=value> define a value for a given property -fs <file:///|hdfs://namenode:port> specify default filesystem URL to use, overrides 'fs.defaultFS' property from configurations. -jt <local|resourcemanager:port> specify a ResourceManager -files <file1,...> specify a comma-separated list of files to be copied to the map reduce cluster -libjars <jar1,...> specify a comma-separated list of jar files to be included in the classpath -archives <archive1,...> specify a comma-separated list of archives to be unarchived on the compute machines The general command line syntax is: command [genericOptions] [commandOptions] [root@hadoop101.yinzhengjie.com ~]#
如上所述,可以使用addDirective属性添加缓存指令。可以使用"-removeDirective"或"-removeDirectives"属性删除一个或多个缓存指令。可以使用"-listDirectives"选线列出所有缓存指令。也可以选择指定以下内容: (1)使用stats标志查看指令统计信息; (2)使用path属性只能查看特定路径下的指令; (3)使用pool属性只列出特定缓存池中的指令; 为了缓存文件或目录,必须使用缓存指令文件或目录的绝对路径。请注意,如果缓存绝对路径,则只会缓存该界别的文件,而不会缓存该目录下的文件。还可以指定在缓存文件或目录时的复制因子和到期时间。 在默认情况下,缓存文件或目录的复制因子为1,但可以指定更高的复制因子。可以指定集群中特定节点上复制数据块的数量。另外,在默认情况下,指令永不会过期,但可以通过ttl(time-to-live)属性来指定保持有效的时间。
6>.缓存池
可以配置只管理实体的缓存池,其用于管理里一组缓存指令。通过设置适当的权限,可以限定对特定用户和组的缓存池访问或允许用户添加或删除配置的缓存指令。集群中所有的缓存池总量等于HDFS缓存保留的聚合内存量。
配置了HDFS块缓存后,MapReduce和其它作业框架可以通过缓存块的节点上调度作业来利用缓存,从而减少通过I/O读取数据的机会。
二.缓存配置实战案例
1>.修改Linux的内存限制
[root@hadoop101.yinzhengjie.com ~]# free -h total used free shared buff/cache available Mem: 3.8G 456M 2.7G 11M 715M 3.1G Swap: 0B 0B 0B [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# cat /etc/security/limits.conf #Add by yinzhengjie * soft core unlimited * hard core unlimited * soft nproc 1000000 * hard nproc 1000000 * soft nofile 1000000 * hard nofile 1000000 * soft memlock 32000 * hard memlock 32000 * soft msgqueue 8192000 * hard msgqueue 8192000 [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# ulimit -l #很显然,我这里设置的是32MB 32000 [root@hadoop101.yinzhengjie.com ~]#
2>.修改Linux的HDFS配置文件(重启集群方能生效)
[root@hadoop101.yinzhengjie.com ~]# cat ${HADOOP_HOME}/etc/hadoop/hdfs-site.xml #修改该配置后必须重启集群,否则如下图所示并不会生效哟~ ...... <property> <name>dfs.datanode.max.locked.memory</name> <value>32000000</value> <description>用于在数据节点上的内存中缓存块副本的内存量(以字节为单位)。数据节点的最大锁定内存软限制(RLIMIT_MEMLOCK)必须至少设置为该值,否则数据节点将在启动时中止。默认情况下,此参数设置为0,这将禁用内存中缓存。如果本机库不可用于DataNode,则此配置无效。</description>
</property> ...... [root@hadoop101.yinzhengjie.com ~]#
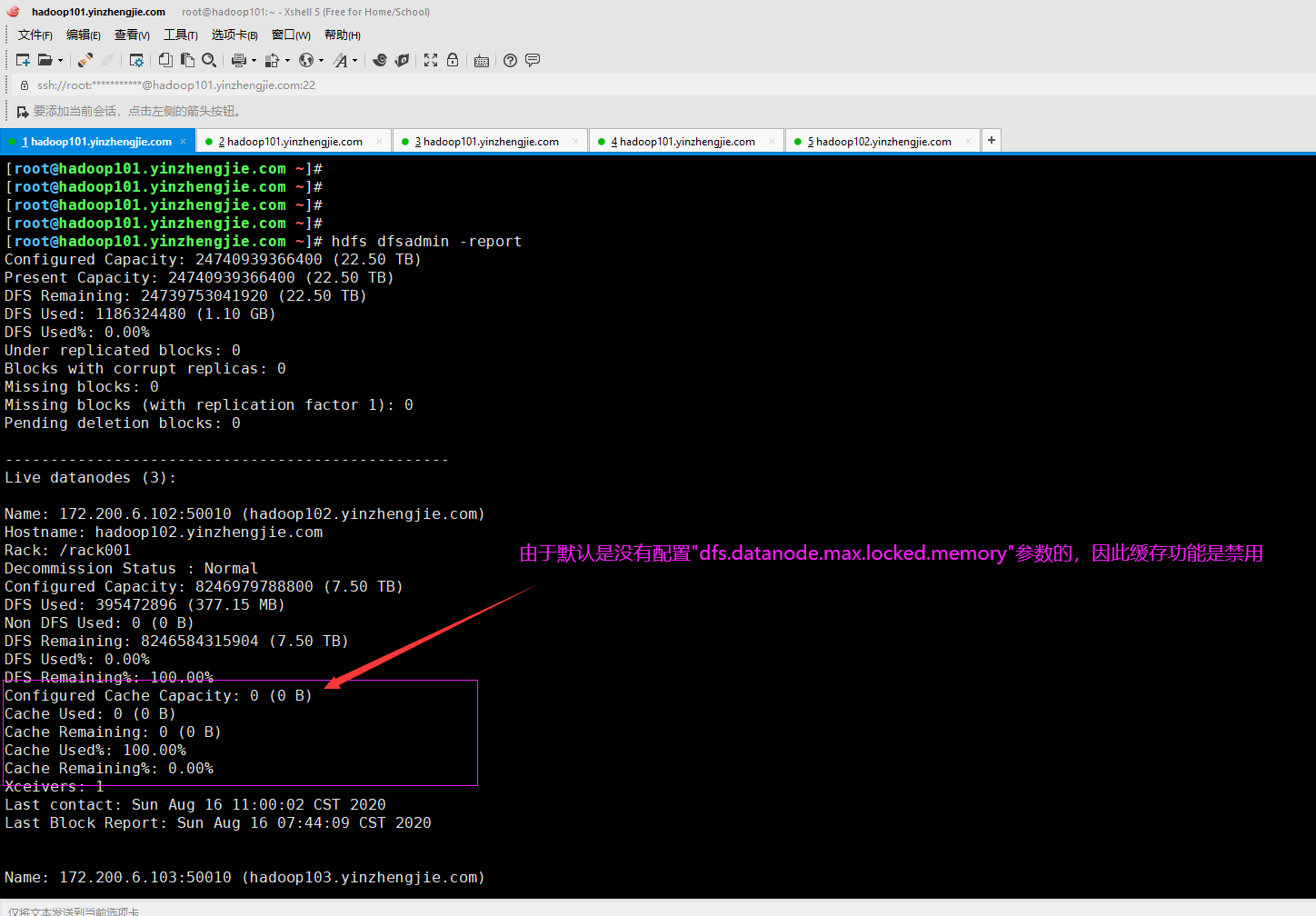


[root@hadoop101.yinzhengjie.com ~]# hdfs dfsadmin -report Configured Capacity: 24740939366400 (22.50 TB) Present Capacity: 24740939366400 (22.50 TB) DFS Remaining: 24739753041920 (22.50 TB) DFS Used: 1186324480 (1.10 GB) DFS Used%: 0.00% Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 Missing blocks (with replication factor 1): 0 Pending deletion blocks: 0 ------------------------------------------------- Live datanodes (3): Name: 172.200.6.102:50010 (hadoop102.yinzhengjie.com) Hostname: hadoop102.yinzhengjie.com Rack: /rack001 Decommission Status : Normal Configured Capacity: 8246979788800 (7.50 TB) DFS Used: 395472896 (377.15 MB) Non DFS Used: 0 (0 B) DFS Remaining: 8246584315904 (7.50 TB) DFS Used%: 0.00% DFS Remaining%: 100.00% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Sun Aug 16 11:00:02 CST 2020 Last Block Report: Sun Aug 16 07:44:09 CST 2020 Name: 172.200.6.103:50010 (hadoop103.yinzhengjie.com) Hostname: hadoop103.yinzhengjie.com Rack: /rack002 Decommission Status : Normal Configured Capacity: 8246979788800 (7.50 TB) DFS Used: 395423744 (377.11 MB) Non DFS Used: 0 (0 B) DFS Remaining: 8246584365056 (7.50 TB) DFS Used%: 0.00% DFS Remaining%: 100.00% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Sun Aug 16 11:00:02 CST 2020 Last Block Report: Sun Aug 16 07:04:02 CST 2020 Name: 172.200.6.104:50010 (hadoop104.yinzhengjie.com) Hostname: hadoop104.yinzhengjie.com Rack: /rack002 Decommission Status : Normal Configured Capacity: 8246979788800 (7.50 TB) DFS Used: 395427840 (377.11 MB) Non DFS Used: 0 (0 B) DFS Remaining: 8246584360960 (7.50 TB) DFS Used%: 0.00% DFS Remaining%: 100.00% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Sun Aug 16 11:00:00 CST 2020 Last Block Report: Sun Aug 16 10:23:18 CST 2020 [root@hadoop101.yinzhengjie.com ~]#
3>.添加名为"yinzhengjiePool" 的缓存池
[root@hadoop101.yinzhengjie.com ~]# hdfs cacheadmin -listPools #默认情况下是没有缓存池的。 Found 0 results. [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# hdfs cacheadmin -addPool yinzhengjiePool #此处我们添加一个名为"yinzhengjiePool"的缓存池 Successfully added cache pool yinzhengjiePool. [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# hdfs cacheadmin -listPools #再次查看缓存池会发现我们刚刚创建出来的缓存池。 Found 1 result. NAME OWNER GROUP MODE LIMIT MAXTTL DEFAULT_REPLICATION yinzhengjiePool root root rwxr-xr-x unlimited never 1 [root@hadoop101.yinzhengjie.com ~]#
4>.添加缓存指令
[root@hadoop101.yinzhengjie.com ~]# hdfs dfs -ls -h / Found 3 items --w------- 2 jason yinzhengjie 309.5 K 2020-08-16 11:37 /hosts drwx------ - root admingroup 0 2020-08-14 19:19 /user drwxr-xr-x - root admingroup 0 2020-08-14 23:22 /yinzhengjie [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# hdfs cacheadmin -addDirective -path /hosts -pool yinzhengjiePool #将HDFS指定路径缓存到我们刚刚创建的缓存池内。 Added cache directive 1 [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# hdfs cacheadmin -listPools Found 1 result. NAME OWNER GROUP MODE LIMIT MAXTTL DEFAULT_REPLICATION yinzhengjiePool root root rwxr-xr-x unlimited never 1 [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# hdfs cacheadmin -listPools -stats yinzhengjiePool #查看"yinzhengjiePool"该缓存池的状态。 Found 1 result. NAME OWNER GROUP MODE LIMIT MAXTTL DEFAULT_REPLICATION BYTES_NEEDED BYTES_CACHED BYTES_OVERLIMIT FILES_NEEDED FILES_CACHED yinzhengjiePool root root rwxr-xr-x unlimited never 1 505 0 0 1 0 [root@hadoop101.yinzhengjie.com ~]#
5>.通过"dfsadmin -report"命令以检查报告是否显示高速缓存
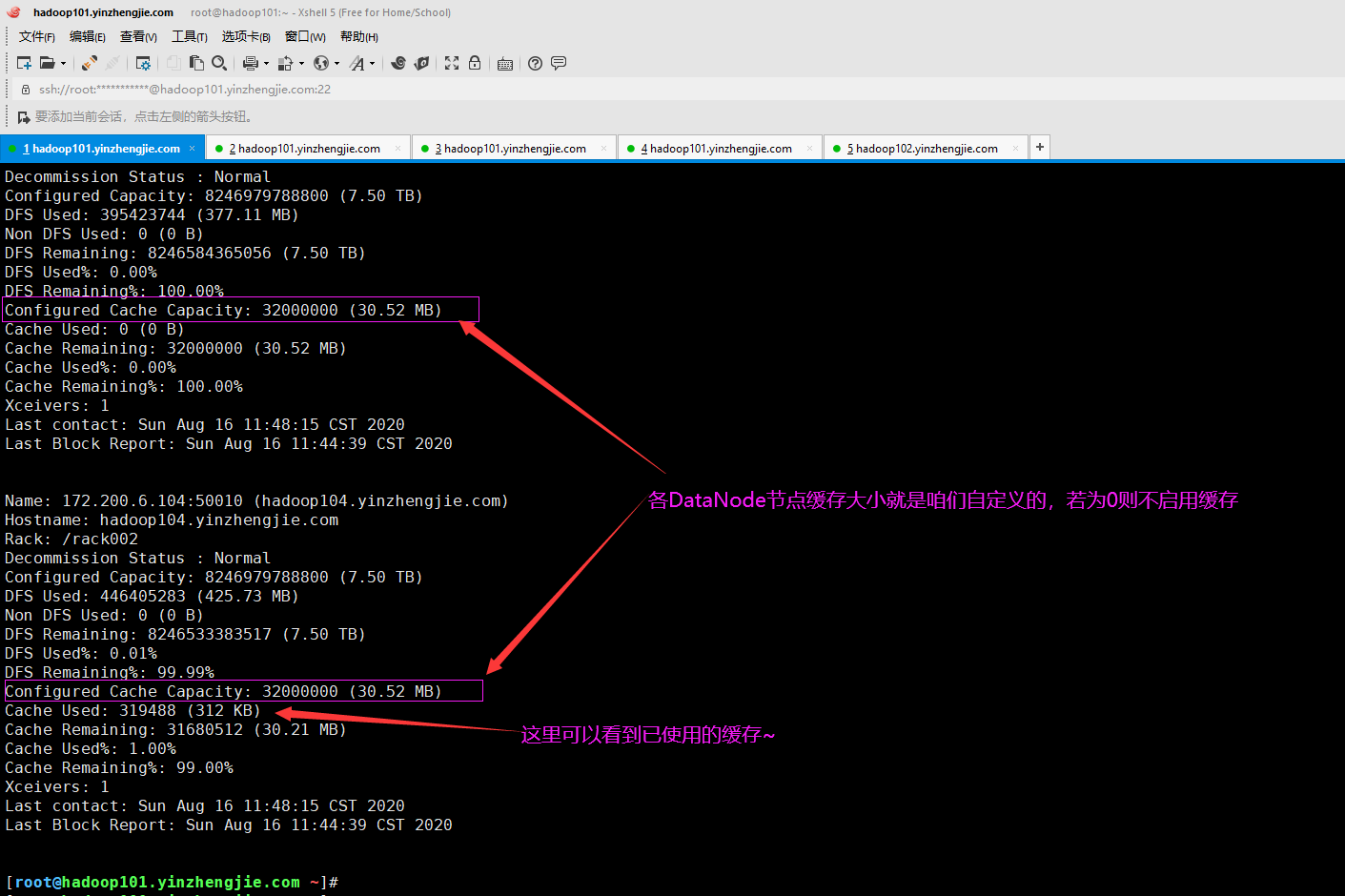
[root@hadoop101.yinzhengjie.com ~]# hdfs dfsadmin -report Configured Capacity: 24740939366400 (22.50 TB) Present Capacity: 24740939366400 (22.50 TB) DFS Remaining: 24739612456817 (22.50 TB) DFS Used: 1326909583 (1.24 GB) DFS Used%: 0.01% Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 Missing blocks (with replication factor 1): 0 Pending deletion blocks: 0 ------------------------------------------------- Live datanodes (3): Name: 172.200.6.102:50010 (hadoop102.yinzhengjie.com) Hostname: hadoop102.yinzhengjie.com Rack: /rack001 Decommission Status : Normal Configured Capacity: 8246979788800 (7.50 TB) DFS Used: 485080556 (462.61 MB) Non DFS Used: 0 (0 B) DFS Remaining: 8246494708244 (7.50 TB) DFS Used%: 0.01% DFS Remaining%: 99.99% Configured Cache Capacity: 32000000 (30.52 MB) Cache Used: 0 (0 B) Cache Remaining: 32000000 (30.52 MB) Cache Used%: 0.00% Cache Remaining%: 100.00% Xceivers: 1 Last contact: Sun Aug 16 11:48:15 CST 2020 Last Block Report: Sun Aug 16 11:44:39 CST 2020 Name: 172.200.6.103:50010 (hadoop103.yinzhengjie.com) Hostname: hadoop103.yinzhengjie.com Rack: /rack002 Decommission Status : Normal Configured Capacity: 8246979788800 (7.50 TB) DFS Used: 395423744 (377.11 MB) Non DFS Used: 0 (0 B) DFS Remaining: 8246584365056 (7.50 TB) DFS Used%: 0.00% DFS Remaining%: 100.00% Configured Cache Capacity: 32000000 (30.52 MB) Cache Used: 0 (0 B) Cache Remaining: 32000000 (30.52 MB) Cache Used%: 0.00% Cache Remaining%: 100.00% Xceivers: 1 Last contact: Sun Aug 16 11:48:15 CST 2020 Last Block Report: Sun Aug 16 11:44:39 CST 2020 Name: 172.200.6.104:50010 (hadoop104.yinzhengjie.com) Hostname: hadoop104.yinzhengjie.com Rack: /rack002 Decommission Status : Normal Configured Capacity: 8246979788800 (7.50 TB) DFS Used: 446405283 (425.73 MB) Non DFS Used: 0 (0 B) DFS Remaining: 8246533383517 (7.50 TB) DFS Used%: 0.01% DFS Remaining%: 99.99% Configured Cache Capacity: 32000000 (30.52 MB) Cache Used: 319488 (312 KB) #不难发现,仅有一个Datanode节点缓存数据啦~ Cache Remaining: 31680512 (30.21 MB) Cache Used%: 1.00% Cache Remaining%: 99.00% Xceivers: 1 Last contact: Sun Aug 16 11:48:15 CST 2020 Last Block Report: Sun Aug 16 11:44:39 CST 2020 [root@hadoop101.yinzhengjie.com ~]#
三.Short-circuit本地读(短路读取)
如果读取HDFS数据的客户端与DataNode位于同一台服务器上,则客户端可以直接拉取该文件,这比将数据传输到客户端的DataNode再读取要快。短路读取指的是由客户端直接从本地文件系统读取数据,同时使用UNIX域套接字绕过DataNode,这为客户端和DataNode之间的通信提供了通道。 短路读取(Short-circuit)本地读取不仅可提升性能,而且也会增加安全性。Hadoop的一个关键原则就是数据局限性。HDFS尝试从客户端(client)所在的同一节点读取数据,从而将大部分读取视为本地读取。 在默认情况下不启用短路读取。要使用短路读取,需要在客户端及DataNode上配置以下内容。
[root@hadoop101.yinzhengjie.com ~]# vim ${HADOOP_HOME}/etc/hadoop/hdfs-site.xml ...... <property> <name>dfs.client.read.shortcircuit</name> <value>true</value> <description>此配置参数打开短路本地读取。默认值为"false"</description> </property> <property> <name>dfs.domain.socket.path</name> <value>/yinzhengjie/data/hadoop/fully-mode/hdfs/dn_socket</value> <description>这是UNIX域套接字的路径,该套接字将用于DataNode和本地HDFS客户端之间的通信。如果此路径中存在字符串“ _PORT”,它将被DataNode的TCP端口替换。</description> </property> ...... [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# manage-hdfs.sh restart #修改上述配置后,需要重启集群 hadoop101.yinzhengjie.com | CHANGED | rc=0 >> stopping namenode hadoop105.yinzhengjie.com | CHANGED | rc=0 >> stopping secondarynamenode hadoop104.yinzhengjie.com | CHANGED | rc=0 >> stopping datanode hadoop102.yinzhengjie.com | CHANGED | rc=0 >> stopping datanode hadoop103.yinzhengjie.com | CHANGED | rc=0 >> stopping datanode Stoping HDFS: [ OK ] hadoop101.yinzhengjie.com | CHANGED | rc=0 >> starting namenode, logging to /yinzhengjie/softwares/hadoop-2.10.0-fully-mode/logs/hadoop-root-namenode-hadoop101.yinzhengjie.com.out hadoop105.yinzhengjie.com | CHANGED | rc=0 >> starting secondarynamenode, logging to /yinzhengjie/softwares/hadoop/logs/hadoop-root-secondarynamenode-hadoop105.yinzhengjie.com.out hadoop103.yinzhengjie.com | CHANGED | rc=0 >> starting datanode, logging to /yinzhengjie/softwares/hadoop/logs/hadoop-root-datanode-hadoop103.yinzhengjie.com.out hadoop102.yinzhengjie.com | CHANGED | rc=0 >> starting datanode, logging to /yinzhengjie/softwares/hadoop/logs/hadoop-root-datanode-hadoop102.yinzhengjie.com.out hadoop104.yinzhengjie.com | CHANGED | rc=0 >> starting datanode, logging to /yinzhengjie/softwares/hadoop/logs/hadoop-root-datanode-hadoop104.yinzhengjie.com.out Starting HDFS: [ OK ] [root@hadoop101.yinzhengjie.com ~]#