SparkSQL数据源-Hive数据库
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.Hive应用
1>.内嵌Hive应用
Apache Hive是Hadoop上的SQL引擎,Spark SQL编译时可以包含Hive支持,也可以不包含。包含Hive支持的Spark SQL可以支持Hive表访问、UDF(用户自定义函数)以及 Hive 查询语言(HiveQL/HQL)等。
需要强调的一点是,如果要在Spark SQL中包含Hive的库,并不需要事先安装Hive。一般来说,最好还是在编译Spark SQL时引入Hive支持,这样就可以使用这些特性了。如果你下载的是二进制版本的 Spark,它应该已经在编译时添加了 Hive 支持。
若要把Spark SQL连接到一个部署好的Hive上,你必须把hive-site.xml复制到 Spark的配置文件目录中($SPARK_HOME/conf)。即使没有部署好Hive,Spark SQL也可以运行。
需要注意的是,如果你没有部署好Hive,Spark SQL会在当前的工作目录中创建出自己的Hive 元数据仓库,叫作 metastore_db。
此外,如果你尝试使用HiveQL中的 CREATE TABLE (并非 CREATE EXTERNAL TABLE)语句来创建表,这些表会被放在你默认的文件系统中的 /user/hive/warehouse 目录中(如果你的classpath中有配好的hdfs-site.xml,默认的文件系统就是HDFS,否则就是本地文件系统)。 如果要使用内嵌的Hive,什么都不用做,直接用就可以了。 当然可以通过添加参数初次指定数据仓库地址:--conf spark.sql.warehouse.dir=hdfs://hadoop101.yinzhengjie.org.cn:9000/spark-wearhouse 温馨提示: 如果你使用的是内部的Hive,在Spark2.0之后,spark.sql.warehouse.dir用于指定数据仓库的地址,如果你需要是用HDFS作为路径,那么需要将core-site.xml和hdfs-site.xml 加入到Spark conf目录,否则只会创建master节点上的warehouse目录,查询时会出现文件找不到的问题,这是需要使用HDFS,则需要将metastore删除,重启集群。


[root@hadoop105.yinzhengjie.org.cn ~]# vim /tmp/id.txt [root@hadoop105.yinzhengjie.org.cn ~]# [root@hadoop105.yinzhengjie.org.cn ~]# cat /tmp/id.txt 100 200 3 400 500 [root@hadoop105.yinzhengjie.org.cn ~]#
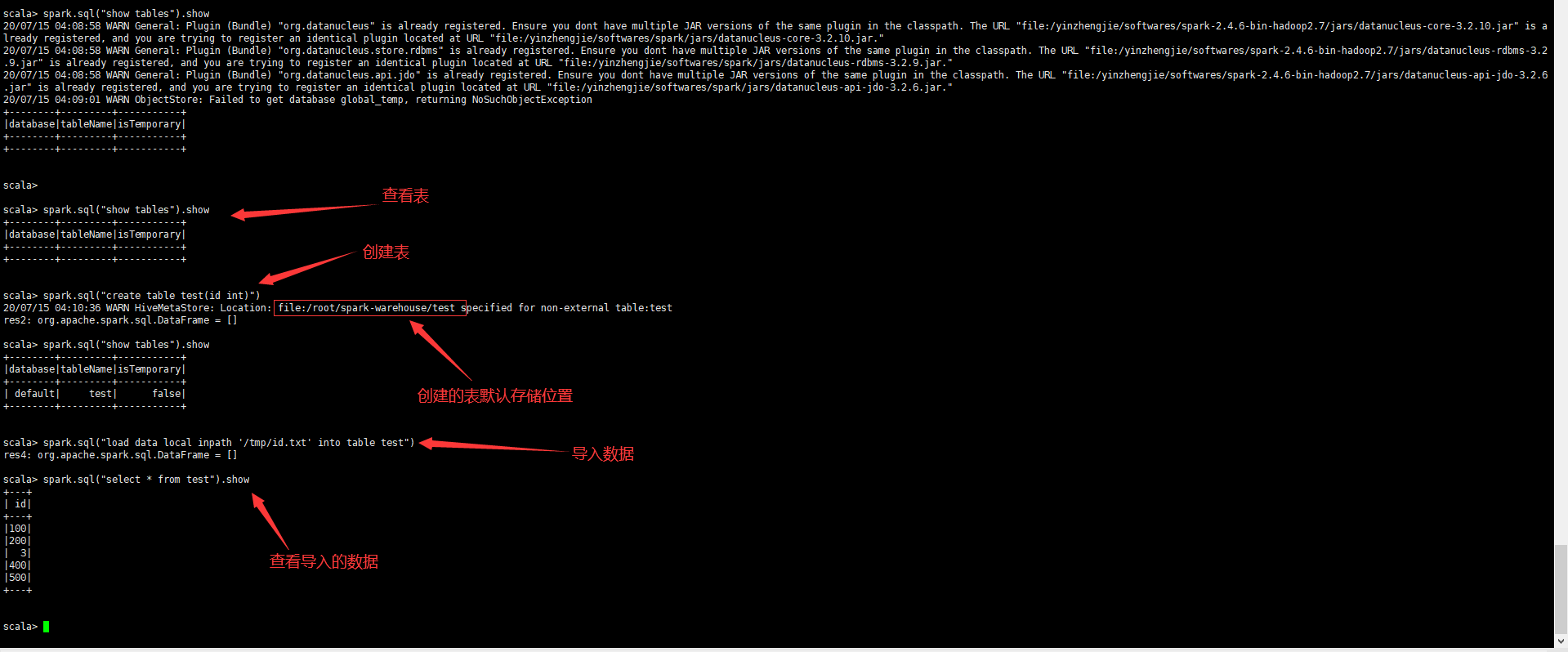
scala> spark.sql("show tables").show +--------+---------+-----------+ |database|tableName|isTemporary| +--------+---------+-----------+ +--------+---------+-----------+ scala> spark.sql("create table test(id int)") 20/07/15 04:10:36 WARN HiveMetaStore: Location: file:/root/spark-warehouse/test specified for non-external table:test res2: org.apache.spark.sql.DataFrame = [] scala> spark.sql("show tables").show +--------+---------+-----------+ |database|tableName|isTemporary| +--------+---------+-----------+ | default| test| false| +--------+---------+-----------+ scala> spark.sql("load data local inpath '/tmp/id.txt' into table test") res4: org.apache.spark.sql.DataFrame = [] scala> spark.sql("select * from test").show +---+ | id| +---+ |100| |200| | 3| |400| |500| +---+ scala>
2>.外部Hive应用
如果想连接外部已经部署好的Hive,需要通过以下几个步骤。 (1)将Hive中的hive-site.xml拷贝或者软连接到Spark安装目录下的conf目录下。 (2)打开spark shell,注意带上访问Hive元数据库的JDBC客户端,如下所示(如果你将对应的Hive的元数据库驱动已经放在spark的安装目录下的jars目录下则可以不加"--jars"选项哟~)。 [root@hadoop105.yinzhengjie.org.cn ~]# spark-shell --jars mysql-connector-java-5.1.36-bin.jar
二.运行Spark SQL CLI
Spark SQL CLI可以很方便的在本地运行Hive元数据服务以及从命令行执行查询任务。其效果等效于你在spark-shell中执行的spark.sql("...")中执行的SQL语句。
[root@hadoop105.yinzhengjie.org.cn ~]# spark-sql 20/07/15 04:28:33 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable log4j:WARN No appenders could be found for logger (org.apache.hadoop.conf.Configuration). log4j:WARN Please initialize the log4j system properly. log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info. Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties 20/07/15 04:28:35 INFO SparkContext: Running Spark version 2.4.6 20/07/15 04:28:35 INFO SparkContext: Submitted application: SparkSQL::172.200.4.105 20/07/15 04:28:35 INFO SecurityManager: Changing view acls to: root 20/07/15 04:28:35 INFO SecurityManager: Changing modify acls to: root 20/07/15 04:28:35 INFO SecurityManager: Changing view acls groups to: 20/07/15 04:28:35 INFO SecurityManager: Changing modify acls groups to: 20/07/15 04:28:35 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set() 20/07/15 04:28:35 INFO Utils: Successfully started service 'sparkDriver' on port 33260. 20/07/15 04:28:35 INFO SparkEnv: Registering MapOutputTracker 20/07/15 04:28:35 INFO SparkEnv: Registering BlockManagerMaster 20/07/15 04:28:35 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information 20/07/15 04:28:35 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up 20/07/15 04:28:35 INFO DiskBlockManager: Created local directory at /tmp/blockmgr-ae5de0c5-5282-4cc6-8ce6-d1dbe34e82e9 20/07/15 04:28:35 INFO MemoryStore: MemoryStore started with capacity 366.3 MB 20/07/15 04:28:35 INFO SparkEnv: Registering OutputCommitCoordinator 20/07/15 04:28:36 INFO Utils: Successfully started service 'SparkUI' on port 4040. 20/07/15 04:28:36 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://hadoop105.yinzhengjie.org.cn:4040 20/07/15 04:28:36 INFO Executor: Starting executor ID driver on host localhost 20/07/15 04:28:36 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 29320. 20/07/15 04:28:36 INFO NettyBlockTransferService: Server created on hadoop105.yinzhengjie.org.cn:29320 20/07/15 04:28:36 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy 20/07/15 04:28:36 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, hadoop105.yinzhengjie.org.cn, 29320, None) 20/07/15 04:28:36 INFO BlockManagerMasterEndpoint: Registering block manager hadoop105.yinzhengjie.org.cn:29320 with 366.3 MB RAM, BlockManagerId(driver, hadoop105.yinzhengjie.org.cn, 29320, None) 20/07/15 04:28:36 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, hadoop105.yinzhengjie.org.cn, 29320, None) 20/07/15 04:28:36 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, hadoop105.yinzhengjie.org.cn, 29320, None) 20/07/15 04:28:36 INFO EventLoggingListener: Logging events to hdfs://hadoop101.yinzhengjie.org.cn:9000/yinzhengjie/spark/jobhistory/local-1594758516077 20/07/15 04:28:36 INFO SharedState: Setting hive.metastore.warehouse.dir ('null') to the value of spark.sql.warehouse.dir ('file:/root/spark-warehouse/'). 20/07/15 04:28:36 INFO SharedState: Warehouse path is 'file:/root/spark-warehouse/'. 20/07/15 04:28:37 INFO StateStoreCoordinatorRef: Registered StateStoreCoordinator endpoint 20/07/15 04:28:37 INFO HiveUtils: Initializing HiveMetastoreConnection version 1.2.1 using Spark classes. 20/07/15 04:28:37 INFO HiveClientImpl: Warehouse location for Hive client (version 1.2.2) is file:/root/spark-warehouse/ 20/07/15 04:28:37 INFO metastore: Mestastore configuration hive.metastore.warehouse.dir changed from /user/hive/warehouse to file:/root/spark-warehouse/ 20/07/15 04:28:37 INFO HiveMetaStore: 0: Shutting down the object store... 20/07/15 04:28:37 INFO audit: ugi=root ip=unknown-ip-addr cmd=Shutting down the object store... 20/07/15 04:28:37 INFO HiveMetaStore: 0: Metastore shutdown complete. 20/07/15 04:28:37 INFO audit: ugi=root ip=unknown-ip-addr cmd=Metastore shutdown complete. 20/07/15 04:28:37 INFO HiveMetaStore: 0: get_database: default 20/07/15 04:28:37 INFO audit: ugi=root ip=unknown-ip-addr cmd=get_database: default 20/07/15 04:28:37 INFO HiveMetaStore: 0: Opening raw store with implemenation class:org.apache.hadoop.hive.metastore.ObjectStore 20/07/15 04:28:37 INFO ObjectStore: ObjectStore, initialize called 20/07/15 04:28:37 INFO Query: Reading in results for query "org.datanucleus.store.rdbms.query.SQLQuery@0" since the connection used is closing 20/07/15 04:28:37 INFO MetaStoreDirectSql: Using direct SQL, underlying DB is DERBY 20/07/15 04:28:37 INFO ObjectStore: Initialized ObjectStore Spark master: local[*], Application Id: local-1594758516077 20/07/15 04:28:37 INFO SparkSQLCLIDriver: Spark master: local[*], Application Id: local-1594758516077 spark-sql> show tables; #查看现在已有的表 20/07/15 04:29:19 INFO HiveMetaStore: 0: get_database: global_temp 20/07/15 04:29:19 INFO audit: ugi=root ip=unknown-ip-addr cmd=get_database: global_temp 20/07/15 04:29:19 WARN ObjectStore: Failed to get database global_temp, returning NoSuchObjectException 20/07/15 04:29:19 INFO HiveMetaStore: 0: get_database: default 20/07/15 04:29:19 INFO audit: ugi=root ip=unknown-ip-addr cmd=get_database: default 20/07/15 04:29:19 INFO HiveMetaStore: 0: get_database: default 20/07/15 04:29:19 INFO audit: ugi=root ip=unknown-ip-addr cmd=get_database: default 20/07/15 04:29:19 INFO HiveMetaStore: 0: get_tables: db=default pat=* 20/07/15 04:29:19 INFO audit: ugi=root ip=unknown-ip-addr cmd=get_tables: db=default pat=* 20/07/15 04:29:19 INFO CodeGenerator: Code generated in 184.459346 ms default test false #很明显,目前咱们就一张表哟~ Time taken: 1.518 seconds, Fetched 1 row(s) 20/07/15 04:29:19 INFO SparkSQLCLIDriver: Time taken: 1.518 seconds, Fetched 1 row(s) spark-sql>
三.代码中使用Hive
1>.添加依赖
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-hive --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_2.11</artifactId> <version>2.1.1</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hive/hive-exec --> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec</artifactId> <version>1.2.1</version> </dependency>
2>.创建SparkSession时需要添加hive支持
val warehouseLocation: String = new File("spark-warehouse").getAbsolutePath /** * 若使用的是外部Hive,则需要将hive-site.xml添加到ClassPath下。 */ val spark = SparkSession .builder() .appName("Spark Hive Example") .config("spark.sql.warehouse.dir", warehouseLocation) //使用内置Hive需要指定一个Hive仓库地址。若使用外部的hive则无需指定 .enableHiveSupport() //启用hive的支持 .getOrCreate()