合并(Combiner)
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.Combiner概述
Combiner是Mapper和Reducer之外的一种可选组件; Combiner组件的父类就是Reducer; Combiner和Reducer的区别在于运行的位置,Combiner是在每一个MapTask所在的节点运行,Reducer是接收全局所有Mapper的输出结果; Combiner的意义就是对每一个MapTask的输出进行局部汇总,以减小网络传输量; Combiner能够应用的前提是不能影响最终的业务逻辑,而且Combiner的输出K,V类型应该和Reducer输入的KV类型要对应起来。 Combiner自定义步骤大致如下所示: (1)自定义一个Combiner继承Reducer,重写Reduce方法; (2)在Job驱动类中设置: job.setCombinerClass(WordcountCombiner.class);
二.未使用Combiner测试
1>.测试代码


package cn.org.yinzhengjie.mapreduce; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /* 用户自定义的Mapper要继承自己的父类。 接下来我们就要对"Mapper<LongWritable,Text,Text,IntWritable>"解释如下: 前两个参数表示定义输出的KV类型 LongWritable: 用于定义行首之间的偏移量,用于定义某一行的位置。 Text: 我们知道LongWritable可以定位某一行的偏移量,那Text自然是该行的内容。 后两个参数表示定义输出的KV类型: Text: 用于定义输出的Key类型 IntWritable: 用于定义输出的Value类型 */ public class WordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable> { //注意哈,我们这里仅创建了2个对象,即word和one。 private Text word = new Text(); private IntWritable one = new IntWritable(1); /* Mapper中的业务逻辑写在map()方法中; 接下来我们就要对"map(LongWritable key, Text value, Context context)"中个参数解释如下: key: 依旧是某一行的偏移量 value: 对应上述偏移量的行内容 context: 整个任务的上下文环境,我们写完Mapper或者Reducer都需要交给context框架去执行。 */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //拿到行数据 String line = value.toString(); //将行数据按照逗号进行切分 String[] words = line.split(","); //遍历数组,把单词变成(word,1)的形式交给context框架 for (String word:words){ /* 我们将输出KV发送给context框架,框架所需要的KV类型正式我们定义在继承Mapper时指定的输出KV类型,即Text和IntWritable类型。 为什么不能写"context.write(new Text(word),new IntWritable(1));"? 上述写法并不会占用过多的内存,因为JVM有回收机制; 但是上述写法的确会大量生成对象,这回导致回收垃圾的时间占比越来越长,从而让程序变慢。 因此,生产环境中并不推荐大家这样写。 推荐大家参考apache hadoop mapreduce官方程序的写法,提前创建2个对象(即上面提到的word和one),然后利用这两个对象来传递数据。 */ this.word.set(word); context.write(this.word,this.one); } } }
package cn.org.yinzhengjie.mapreduce; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /* 用户自定义Reducer要继承自己的父类; 根据Hadoop MapReduce的运行原理,再写自定义的Reducer类时,估计你已经猜到了Reducer<Text,IntWritable,Text,IntWritable>的泛型。 前两个输入参数就是咱们自定义Mapper的输出泛型的类型,即: Text: 自定义Mapper输出的Key类型。 IntWritable: 自定义Mapper输出的Value类型 后两个参数表示定义输出的KV类型: Text: 用于定义输出的Key类型 IntWritable: 用于定义输出的Value类型 */ public class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable> { //定义一个私有的对象,避免下面创建多个对象 private IntWritable total = new IntWritable(); /* Reducer的业务逻辑在reduce()方法中; 接下来我们就要对"reduce(Text key, Iterable<IntWritable> values, Context context)"中个参数解释如下: key: 还记得咱们自定义写的"context.write(this.word,this.one);"吗? 这里的key指的是同一个单词(word),即相同的单词都被发送到同一个reduce函数进行处理啦。 values: 同理,这里的values指的是很多个数字1组成,每一个数字代表同一个key出现的次数。 context: 整个任务的上下文环境,我们写完Mapper或者Reducer都需要交给context框架去执行。 */ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { //定义一个计数器 int sum = 0; //对同一个单词做累加操作,计算该单词出现的频率。 for (IntWritable value:values){ sum += value.get(); } //包装结果 total.set(sum); //将计算的结果交给context框架 context.write(key,total); } }
package cn.org.yinzhengjie.mapreduce; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class WordCountDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //获取一个Job实例 Job job = Job.getInstance(new Configuration()); //设置我们的当前Driver类路径(classpath) job.setJarByClass(WordCountDriver.class); //设置自定义的Mapper类路径(classpath) job.setMapperClass(WordCountMapper.class); //设置自定义的Reducer类路径(classpath) job.setReducerClass(WordCountReducer.class); //设置自定义的Mapper程序的输出类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //设置自定义的Reducer程序的输出类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //设置输入数据 FileInputFormat.setInputPaths(job,new Path(args[0])); //设置输出数据 FileOutputFormat.setOutputPath(job,new Path(args[1])); //提交我们的Job,返回结果是一个布尔值 boolean result = job.waitForCompletion(true); //如果程序运行成功就打印"Task executed successfully!!!" if(result){ System.out.println("Task executed successfully!!!"); }else { System.out.println("Task execution failed..."); } //如果程序是正常运行就返回0,否则就返回1 System.exit(result ? 0 : 1); } }
java python java c++ zabbix hdfs python spark yarn hive mapreduce kafka java fink spark java golang zabbix zabbix HDFS
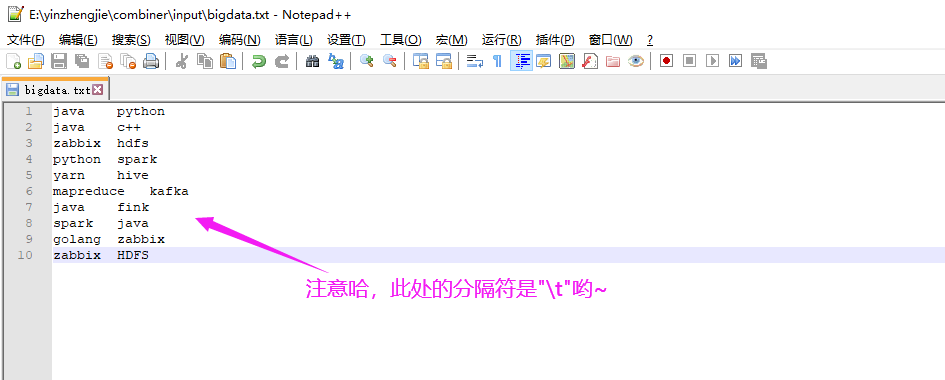
2>.测试结果

三.使用Combiner测试
1>.仅需修改WordCountDriver.java的部分代码
package cn.org.yinzhengjie.combiner; import cn.org.yinzhengjie.mapreduce.WordCountMapper; import cn.org.yinzhengjie.mapreduce.WordCountReducer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class WordCountDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //获取一个Job实例 Job job = Job.getInstance(new Configuration()); //设置我们的当前Driver类路径(classpath) job.setJarByClass(cn.org.yinzhengjie.mapreduce.WordCountDriver.class); //设置自定义的Mapper类路径(classpath) job.setMapperClass(WordCountMapper.class); //设置自定义的Reducer类路径(classpath) job.setReducerClass(WordCountReducer.class); //设置自定义的Mapper程序的输出类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //设置自定义的Reducer程序的输出类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //设置Combiner job.setCombinerClass(WordCountReducer.class); //设置输入数据 FileInputFormat.setInputPaths(job,new Path(args[0])); //设置输出数据 FileOutputFormat.setOutputPath(job,new Path(args[1])); //提交我们的Job,返回结果是一个布尔值 boolean result = job.waitForCompletion(true); //如果程序运行成功就打印"Task executed successfully!!!" if(result){ System.out.println("Task executed successfully!!!"); }else { System.out.println("Task execution failed..."); } //如果程序是正常运行就返回0,否则就返回1 System.exit(result ? 0 : 1); } }
2>.再次查看代码测试结果
