zookeeper概述
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.zookeeper概述
1>.什么是zookeeper
zookeeper是一个开源的分布式的,为分布式应用提供微服务的Apache项目,它是由之前雅虎公司开源的。
zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架。
zookeeper负责存储和管理大家都关心的数据,然后接收观察者的注册,一旦这些数据的状态发生变化,zookeeper将负责通知已经在zookeeper上注册的那些观察者做出相应的反应。
综上所述,我们可以说:zookeeper = 文件系统 + 通知机制。
2>.zookeeper的特点
zookeeper是一个领导者(Leader)和多个跟随者(Follower)组成的集群,集群中只要有半数以上节点存活,zookeeper集群就能正常服务。
全局数据一致:
每个Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的。
更新请求顺序进行:
来自一个Client的更新请求按其发送顺序依次运行。
数据更新原子性:
一次数据更新要么成功,要么失败。
实时性:
在一定时间范围内,Client能读到最新数据。
3>.zookeeper数据模型
zookeeper的数据模型的结构与unix文件系统很类似,整体上可以看作是一棵树,每个节点称作一个Znode。
每一个Znode默认能够存储1MB(1M的数据已经很大的,因为它仅存放配置信息)的数据,每个ZNode都可以通过其路径唯一标识。
温馨提示:
zookeeper和Linux系统目录结构在逻辑上有一个很大的区别在于Linux是有目录和文件的区分,而zookeeper并不区分文件和目录,只有znode。
zookeeper每一个Znode既可以存储数据也可以有子znode。
4>.应用场景
统一命名服务: 在分布式环境下,经常需要对应用/服务进行统一命名,便于标识。例如:IP地址不容易记住,而域名容易记住。 统一配置管理; 1>.在分布式环境下,配置文件同步非常常见: (a)一般要求一个集群中,所有节点的配置信息是一致的,比如kafka集群; (b)对配置文件修改后,希望能够快速同步到各个节点上; 2>.配置管理可交由zookeeper实现 (a)可将配置信息写入zookeeper上的一个ZNode; (b)各个客户端服务器监听这个ZNode; (c)一旦Znode中的数据被修改,zookeeper将通知已经在其注册的各个客户端服务器; 主备选举: 大数据集群大多数都是分布式集群,以HDFS,YARN集群的主备选举都可以基于zookeeper来实现。 统一集群管理: 1>.分布式环境中,实时掌握每个节点的状态是必要的,可根据节点实时状态做出一些调整; 2>.zookeeper可以实现实时监控节点状态变化 (a)可将节点信息写入zookeeper上的一个Znode; (b)监听这个Znode可获得它的实时状态变化; 服务器节点动态上下线; 客户端服务器能实时洞察到服务器上下线的变化。 软负载均衡: 在zookeeper中记录每台服务器的访问数,让访问数量最少的服务器去处理新的客户端请求。
5>.下载zookeeper
官方地址: https://zookeeper.apache.org/ 下载地址: https://zookeeper.apache.org/releases.html 官方文档: https://zookeeper.apache.org/doc/current/index.html
二.zookeeper的znode类型
持久(Persistent)化znode:
客户端与zookeeper断开连接后,该节点依旧存在。即只要你不手动删除,它就会一直存在。默认创建的就是持久的znode。
持久化顺序编号znode:
客户端与zookeeper断开连接后,该节点依旧存在,只是zookeeper给该znode名称进行顺序编号。
临时(Ephemeral)znode:
客户端与zookeeper断开连接后,该节点被删除。
临时顺序编号znode:
客户端与zookeeper断开连接后,该znode被删除,只是zookeeper给该znode名称末尾进行顺序编号。
温馨提示:
创建znode时设置顺序标识,znode名称会附加一个值(顺序号),该值是一个单调递增的计数器,由父节点维护。
在分布式系统中,顺序号可以被用于所有的时间进行全局排序,这样客户端可以通过顺序号推断时间的顺序。
三.znode状态信息
[zk: hadoop102.yinzhengjie.org.cn(CONNECTED) 9] stat /yinzhengjie cZxid = 0x10000000c ctime = Tue May 12 07:17:12 CST 2020 mZxid = 0x10000001a mtime = Tue May 12 07:41:00 CST 2020 pZxid = 0x10000001e cversion = 4 dataVersion = 2 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 8 numChildren = 4 [zk: hadoop102.yinzhengjie.org.cn(CONNECTED) 10] [zk: hadoop102.yinzhengjie.org.cn(CONNECTED) 10] ls /yinzhengjie [test1, test2, test30000000002, test40000000003] [zk: hadoop102.yinzhengjie.org.cn(CONNECTED) 11] 以上是stat命令的输出结果,以下对每个键值对的概要说明: cZxid: 创建节点的事务zxid.每次修改ZooKeeper状态都会收到一个zxid形式的时间戳,也就是ZooKeeper事务ID。 事务ID是ZooKeeper中所有修改总的次序。每个修改都有唯一的zxid,如果zxid1小于zxid2,那么zxid1在zxid2之前发生。 cZxid是由64bits(8个字节)组成,我们以"0x10000000c"为例,这是一个十六进制数字,从左到右第一个数字1表示的是在zookeeper第几次启动的,后面的"0000000c"表示在第13次创建的该节点,换句话说,在zookeeper的第一次启动的第13次操作时创建的/yinzhengjie这个znode。 尽管我们修改了该znode的数据也不会修改该值。 ctime: 表示znode被创建的毫秒数(从1970年开始) mzxid: 表示znode最后更新的事务zxid mtime: znode最后修改的毫秒数(从1970年开始) pZxid: znode最后更新的子节点zxid cversion: znode子节点变化号,znode子节点修改次数 dataversion: znode数据变化号 aclVersion: znode访问控制列表的变化号,0表示没有配置ACL。 ephemeralOwner: 如果是临时znode,这个是znode拥有者的session id。如果不是临时节点则是0。 dataLength: znode的数据长度 numChildren: znode子节点数量
四.监听器原理
(1)在main线程中创建Zookeeper客户端(new ZooKeeper),这时会创建两个线程,一个是负责网络连接通信(sendThread),一个负责监听(eventThread);
(2)通过客户端sendThread线程将注册的监听事件发送给服务端zookeeper集群;
(3)在服务端zookeeper集群的注册监听列表中将注册的监听事件添加到列表中;
(4)服务端zookeeper监听到有数据或路径变化,就会将这个消息发送给客户端的eventThread线程;
(5)客户端的eventThread线程内部调用了process()方法;
五.ZAB协议
1>. paxos算法
Paxos算法是Lamport宗师提出的一种基于消息传递的分布式一致性算法,使其获得2013年图灵奖。 Paxos由Lamport于1998年在《The Part-Time Parliament》论文中首次公开,最初的描述使用希腊的一个小岛Paxos作为比喻,描述了Paxos小岛中通过决议的流程,并以此命名这个算法,但是这个描述理解起来比较有挑战性。后来在2001年,Lamport觉得同行不能理解他的幽默感,于是重新发表了朴实的算法描述版本《Paxos Made Simple》。 自Paxos问世以来就持续垄断了分布式一致性算法,Paxos这个名词几乎等同于分布式一致性。Google的很多大型分布式系统都采用了Paxos算法来解决分布式一致性问题,如Chubby、Megastore以及Spanner等。开源的ZooKeeper,以及MySQL 5.7推出的用来取代传统的主从复制的MySQL Group Replication等纷纷采用Paxos算法解决分布式一致性问题。 然而,Paxos的最大特点就是难,不仅难以理解,更难以实现。 博主推荐阅读: https://zhuanlan.zhihu.com/p/31780743
2>.zab协议
Zab协议的全称是 Zookeeper Atomic Broadcast (Zookeeper原子广播)。Zookeeper是通过Zab协议来保证分布式事务的最终一致性。 Zab协议是为分布式协调服务Zookeeper专门设计的一种 支持崩溃恢复 的 原子广播协议 ,是Zookeeper保证数据一致性的核心算法。Zab借鉴了Paxos算法,但又不像Paxos那样,是一种通用的分布式一致性算法。它是特别为Zookeeper设计的支持崩溃恢复的原子广播协议。 在Zookeeper中主要依赖Zab协议来实现数据一致性,基于该协议,zk实现了一种主备模型(即Leader和Follower模型)的系统架构来保证集群中各个副本之间数据的一致性。
这里的主备系统架构模型,就是指只有一台客户端(Leader)负责处理外部的写事务请求,然后Leader客户端将数据同步到其他Follower节点。 Zookeeper客户端会随机的链接到 zookeeper 集群中的一个节点,如果是读请求,就直接从当前节点中读取数据;如果是写请求,那么节点就会向 Leader 提交事务,Leader 接收到事务提交,会广播该事务,只要超过半数节点写入成功,该事务就会被提交。 Zab协议的特性: Zab 协议需要确保那些已经在 Leader 服务器上提交(Commit)的事务最终被所有的服务器提交。 Zab 协议需要确保丢弃那些只在 Leader 上被提出而没有被提交的事务。 博主推荐阅读: https://www.jianshu.com/p/2bceacd60b8a
3>.博主推荐阅读
分布式协调服务Zookeeper扫盲篇: https://www.cnblogs.com/yinzhengjie/p/10742994.html
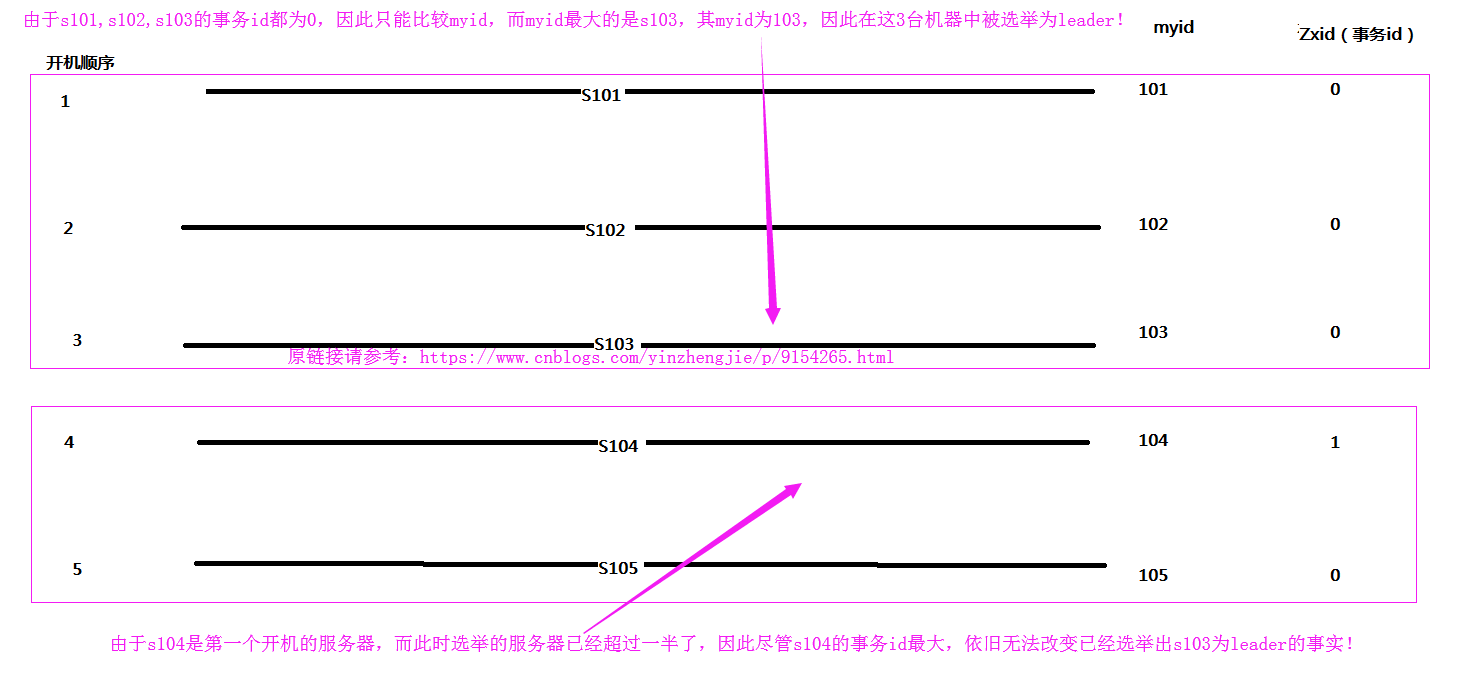
六.选举机制
在选举leader节点时,首先会比较事务id,其次比较myid,如果集群中已经有一半机器参加选举,那么此leader就是整个集群中的leader。
为了方便理解,我画了两幅图,便于理解上面的一句话,当事物id一致时推选leader如下:
当事物id不一致时推选leader如下:

七.写数据流程
(1)Client向zookeeper的Server上写数据,就会发送一个写请求;
(2)如果server不是Leader角色,那么该server会把接受到的请求进一步转发给Leader,因为zookeeper集群的每台Server里面都记录着Lader节点,这个Leader会将写请求发广播给各个Server,比如s101和s102,各个Server会将该写请求加入待写队列吗,并向Leader发送成功消息;
(3)当Leader收到半数以上Server的成功信息,说明该写操作可以执行。Leader回想各个Server发送提交消息,各个Server收到信息后会落实队列里的写请求,此时写成功;
(4)Sever会进步通知Client数据写成功了,这时九任务整个写操作成功。