Spark进阶之路-Spark HA配置
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
集群部署完了,但是有一个很大的问题,那就是Master节点存在单点故障,要解决此问题,就要借助zookeeper,并且启动至少两个Master节点来实现高可靠,配置方式比较简单。本篇博客的搭建环境是基于Standalone模式进行的(https://www.cnblogs.com/yinzhengjie/p/9458161.html)
1>.编辑spark-env.sh文件,去掉之前的master主机,并指定zookeeper集群的主机
[yinzhengjie@s101 ~]$ grep -v ^# /soft/spark/conf/spark-env.sh | grep -v ^$ export JAVA_HOME=/soft/jdk SPARK_MASTER_PORT=7077 export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://s105:8020/yinzhengjie/logs" export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=s102:2181,s103:2181,s103:2181 -Dspark.deploy.zookeeper.dir=/spark" #指定zookeeper的集群地址以及spark在spark存放的路径。 [yinzhengjie@s101 ~]$
2>.分发配置


[yinzhengjie@s101 ~]$ more `which xrsync.sh` #!/bin/bash #@author :yinzhengjie #blog:http://www.cnblogs.com/yinzhengjie #EMAIL:y1053419035@qq.com #判断用户是否传参 if [ $# -lt 1 ];then echo "请输入参数"; exit fi #获取文件路径 file=$@ #获取子路径 filename=`basename $file` #获取父路径 dirpath=`dirname $file` #获取完整路径 cd $dirpath fullpath=`pwd -P` #同步文件到DataNode for (( i=102;i<=105;i++ )) do #使终端变绿色 tput setaf 2 echo =========== s$i %file =========== #使终端变回原来的颜色,即白灰色 tput setaf 7 #远程执行命令 rsync -lr $filename `whoami`@s$i:$fullpath #判断命令是否执行成功 if [ $? == 0 ];then echo "命令执行成功" fi done [yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ xrsync.sh /soft/spark =========== s102 %file =========== 命令执行成功 =========== s103 %file =========== 命令执行成功 =========== s104 %file =========== 命令执行成功 =========== s105 %file =========== 命令执行成功 [yinzhengjie@s101 ~]$ xrsync.sh /soft/spark-2.1.1-bin-hadoop2.7/ =========== s102 %file =========== 命令执行成功 =========== s103 %file =========== 命令执行成功 =========== s104 %file =========== 命令执行成功 =========== s105 %file =========== 命令执行成功 [yinzhengjie@s101 ~]$
3>.s101启动master集群
[yinzhengjie@s101 ~]$ /soft/spark/sbin/start-all.sh starting org.apache.spark.deploy.master.Master, logging to /soft/spark/logs/spark-yinzhengjie-org.apache.spark.deploy.master.Master-1-s101.out s103: starting org.apache.spark.deploy.worker.Worker, logging to /soft/spark/logs/spark-yinzhengjie-org.apache.spark.deploy.worker.Worker-1-s103.out s104: starting org.apache.spark.deploy.worker.Worker, logging to /soft/spark/logs/spark-yinzhengjie-org.apache.spark.deploy.worker.Worker-1-s104.out s102: starting org.apache.spark.deploy.worker.Worker, logging to /soft/spark/logs/spark-yinzhengjie-org.apache.spark.deploy.worker.Worker-1-s102.out [yinzhengjie@s101 ~]$ [yinzhengjie@s101 ~]$ xcall.sh jps ============= s101 jps ============ 18546 DFSZKFailoverController 20565 Jps 20472 Master 18234 NameNode 19389 HistoryServer 命令执行成功 ============= s102 jps ============ 12980 QuorumPeerMain 13061 DataNode 13925 Jps 13147 JournalNode 13870 Worker 命令执行成功 ============= s103 jps ============ 12836 JournalNode 13573 Worker 12663 QuorumPeerMain 13628 Jps 12750 DataNode 命令执行成功 ============= s104 jps ============ 13360 Worker 12455 QuorumPeerMain 13415 Jps 12537 DataNode 12623 JournalNode 命令执行成功 ============= s105 jps ============ 12151 DFSZKFailoverController 12043 NameNode 13052 Jps 命令执行成功 [yinzhengjie@s101 ~]$
4>.s105手动启动另外一个master
[yinzhengjie@s105 ~]$ /soft/spark/sbin/start-master.sh starting org.apache.spark.deploy.master.Master, logging to /soft/spark/logs/spark-yinzhengjie-org.apache.spark.deploy.master.Master-1-s105.out [yinzhengjie@s105 ~]$ jps 13109 Master 13221 Jps 12151 DFSZKFailoverController 12043 NameNode [yinzhengjie@s105 ~]$
5>.连接spark集群
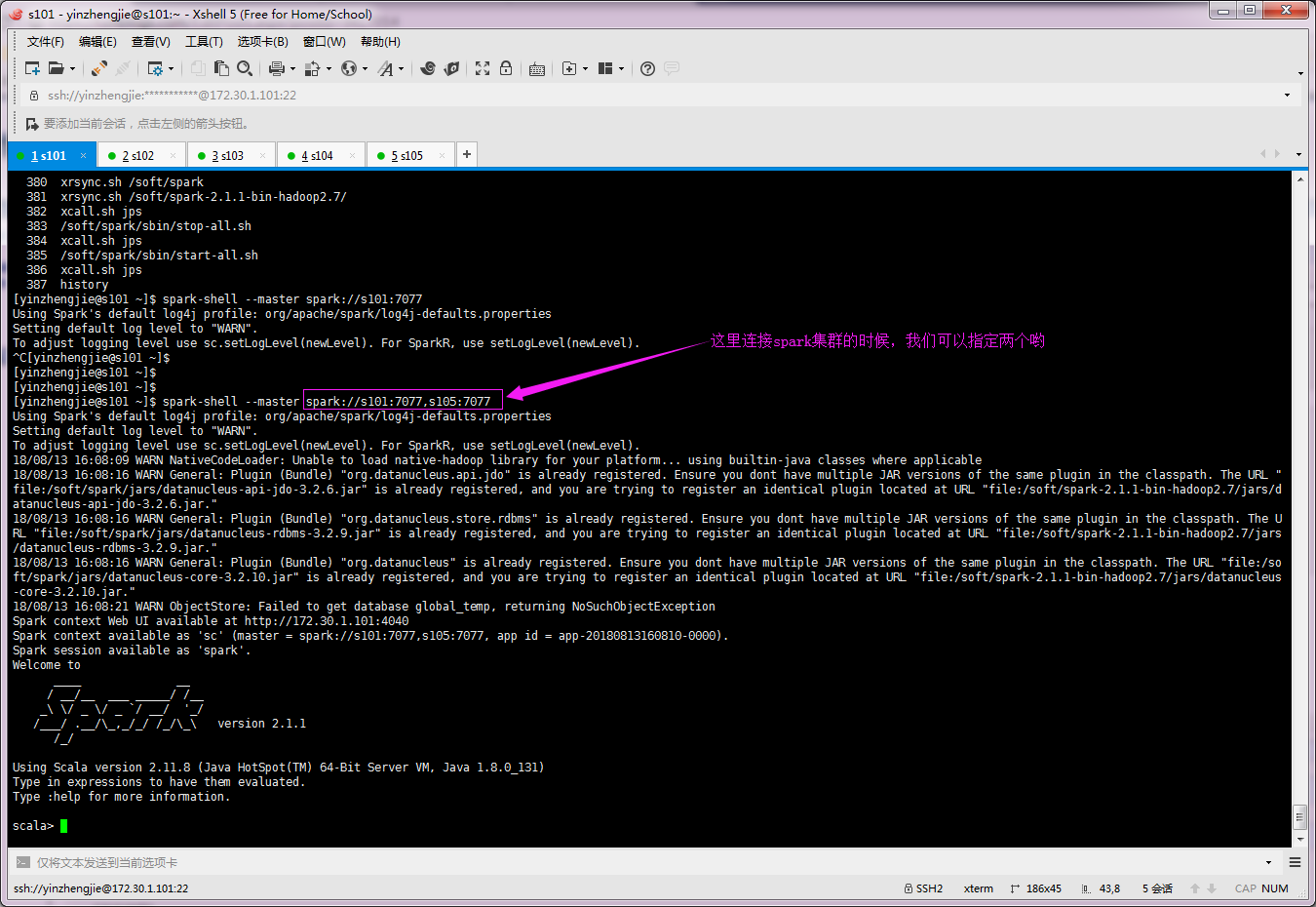
6>.查看master节点的webUI信息
s105的master信息如下:(此时s105啥也没有,worker没有正确到,正在运行的任务也没有争取到)
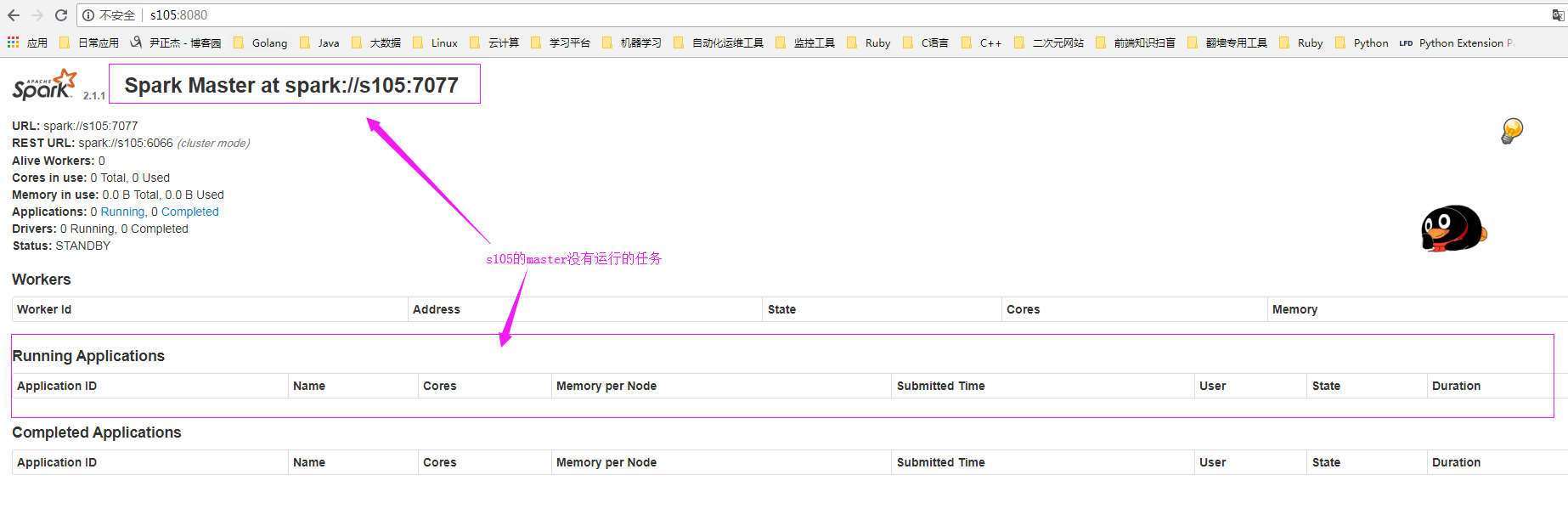
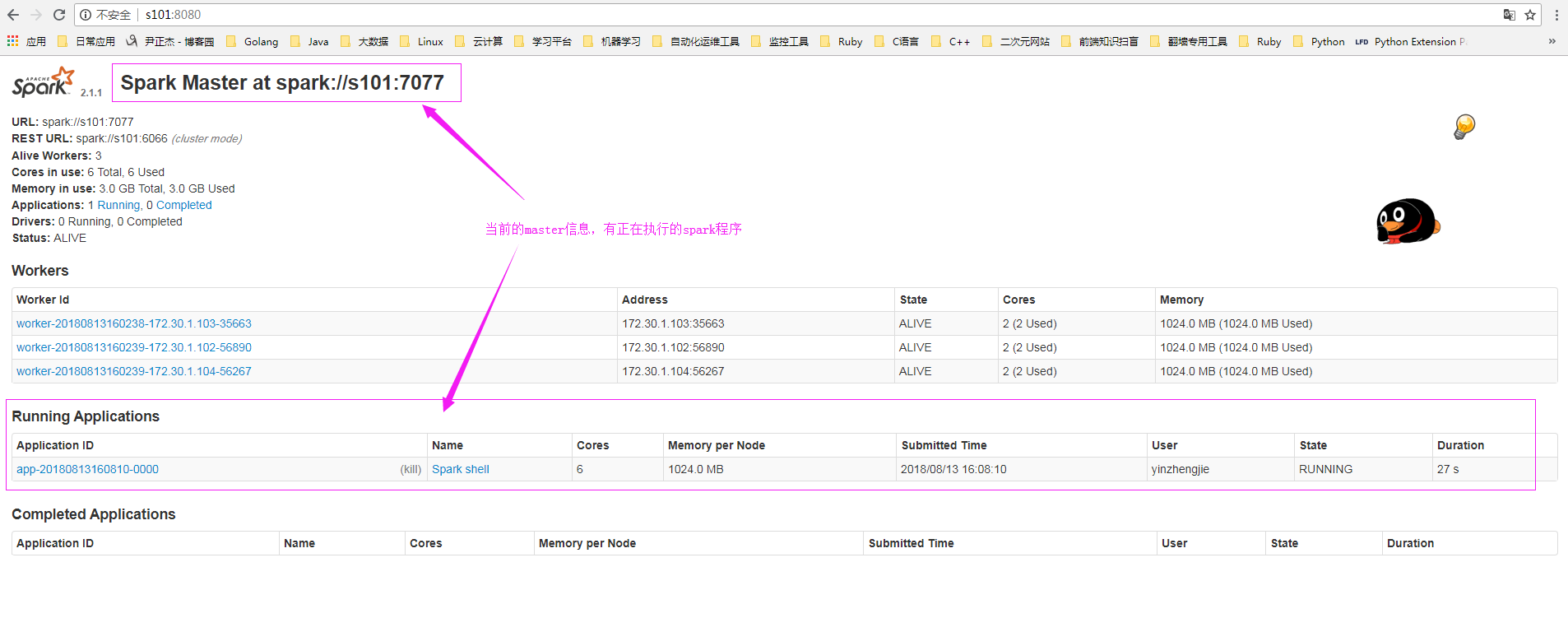
s101的master信息如下:(你会发现目前的正在工作的master是s101)
7>.手动杀死s101的master进程
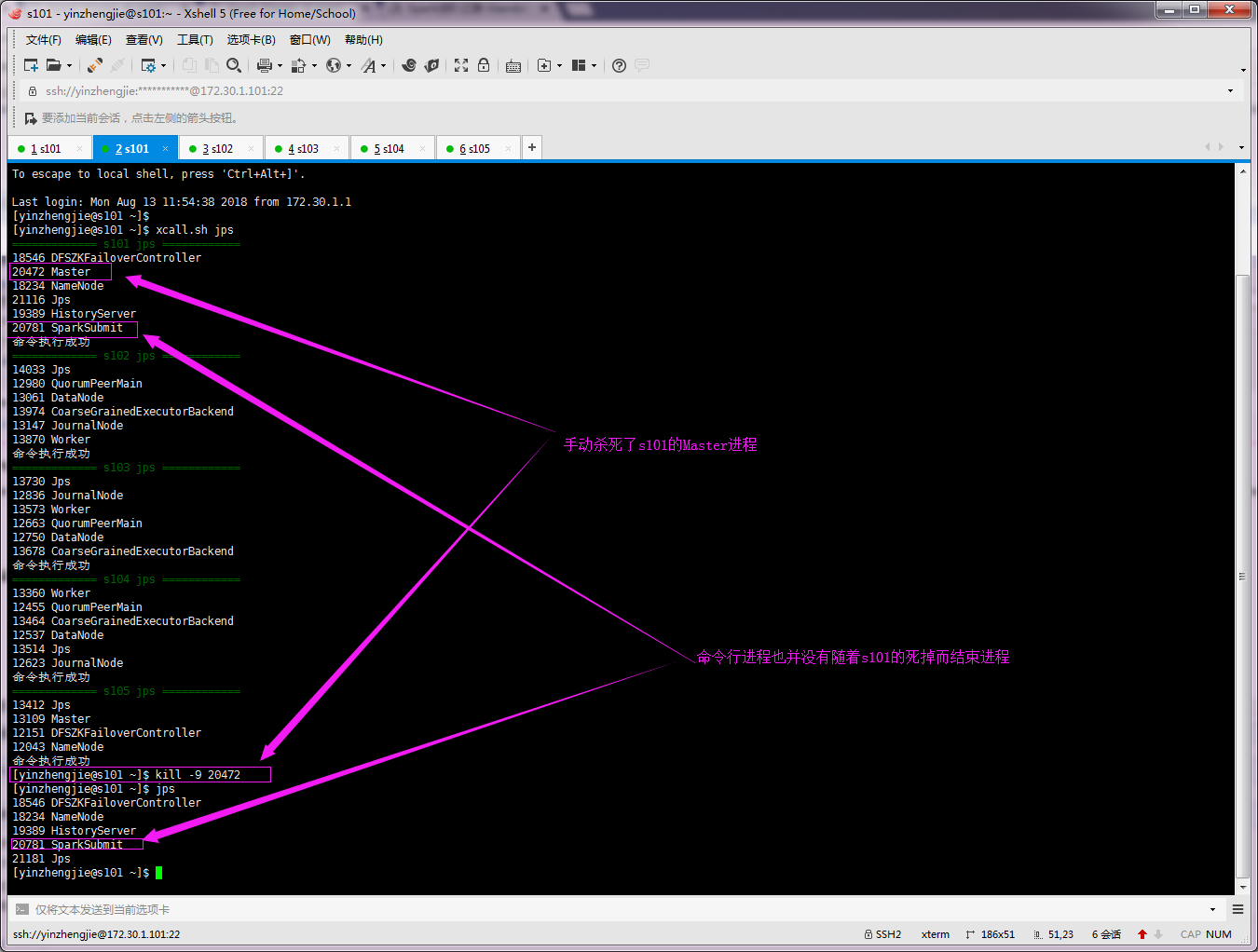
8>.查看spark-shell命令行是否可以正常工作
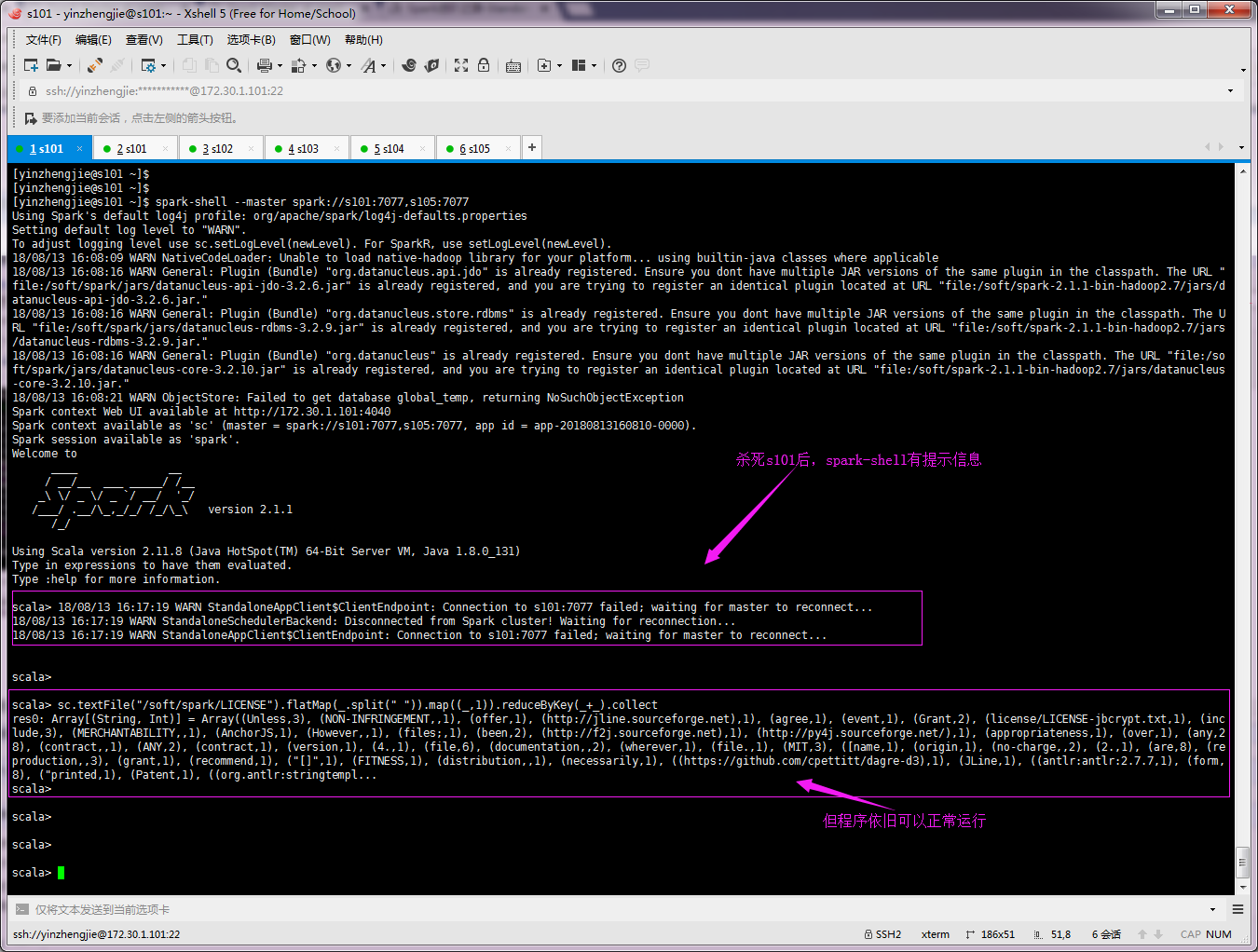
9>.检查集群中是否还有正常的master存活(很显然,此时一定是s105接管了任务)
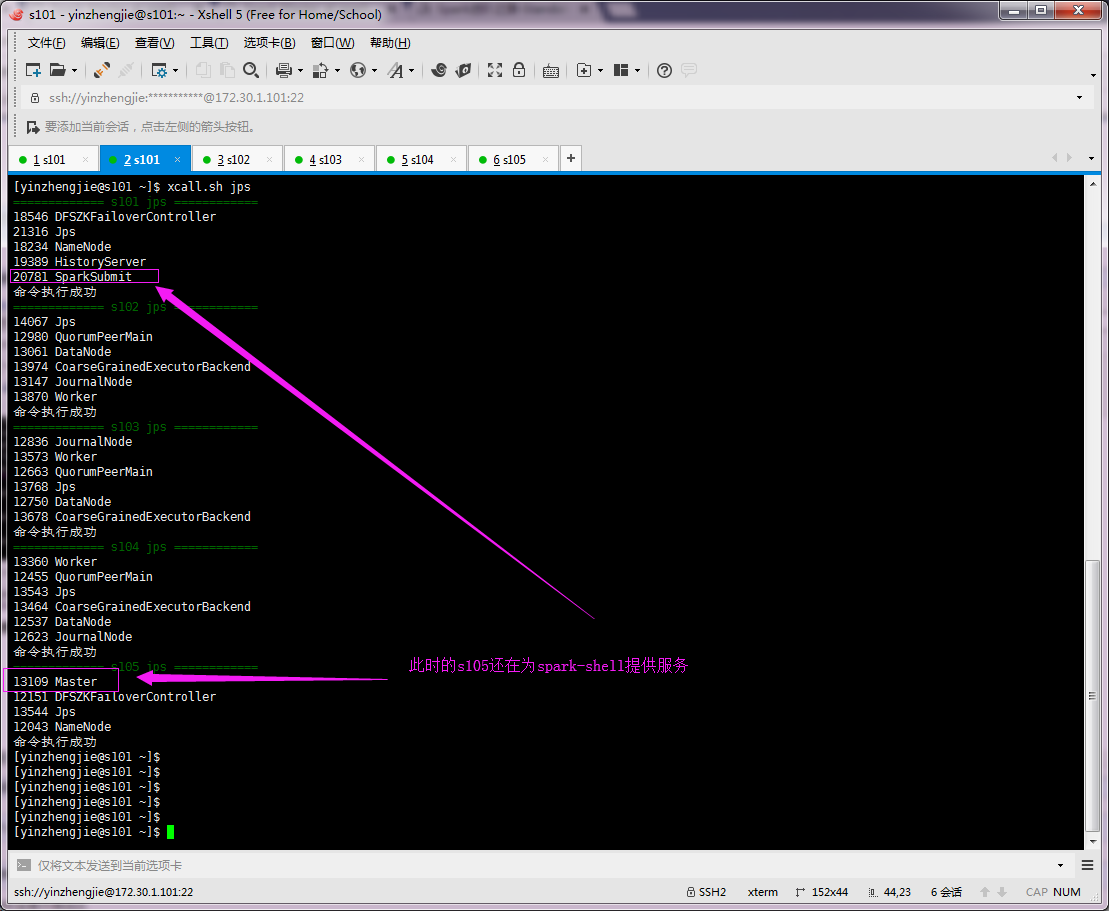
10>.再次查看s105的webUI界面
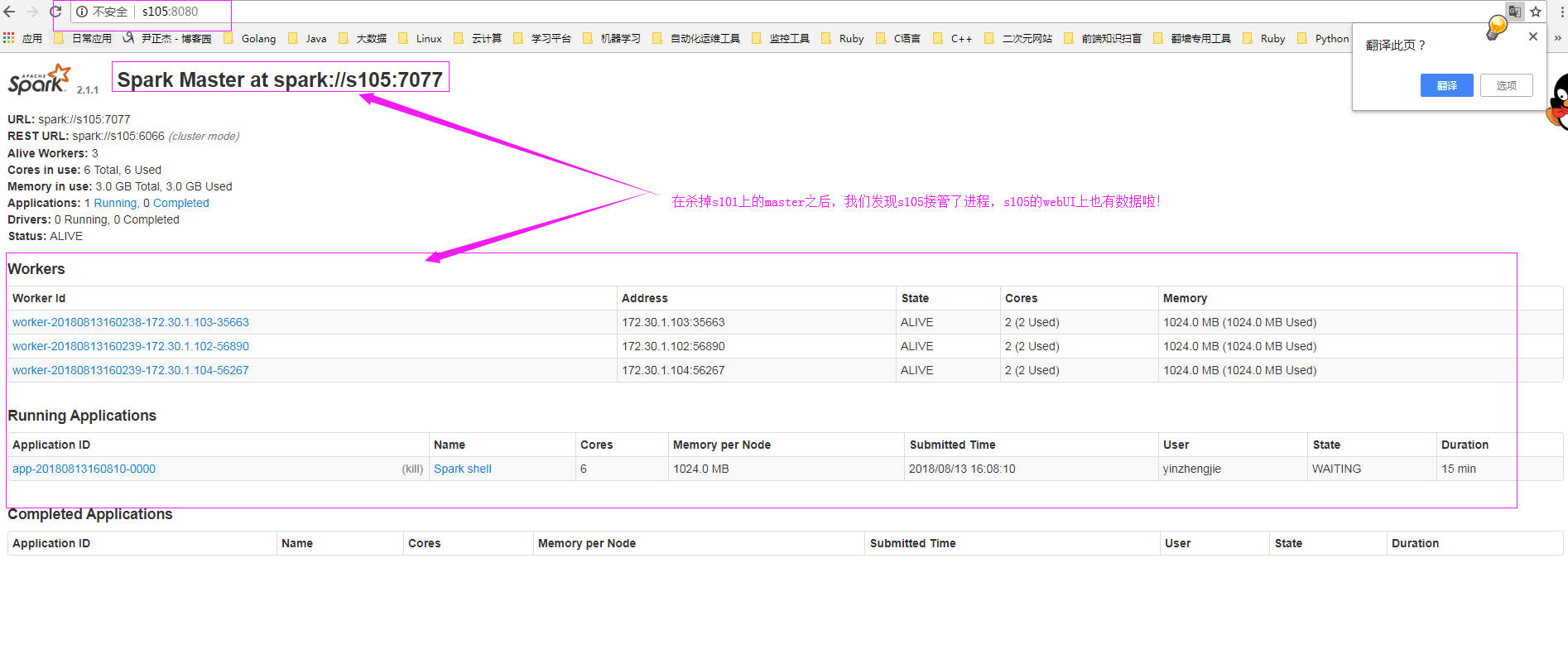
由于s101的master进程已经被我们手动杀死了,因此我们无法通过webUI的形式访问它了: