Scala进阶之路-高级数据类型之集合的使用
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
Scala 的集合有三大类:序列 Seq、集 Set、映射 Map,所有的集合都扩展自 Iterable 特质在 Scala 中集合有可变(“scala.collection.mutable” 包下存放)和不可变(“scala.collection.immutable” 包下存放)两种类型,immutable 类型的集合初始化后就不能改变了(注意与 val 修饰的变量进行区别)。
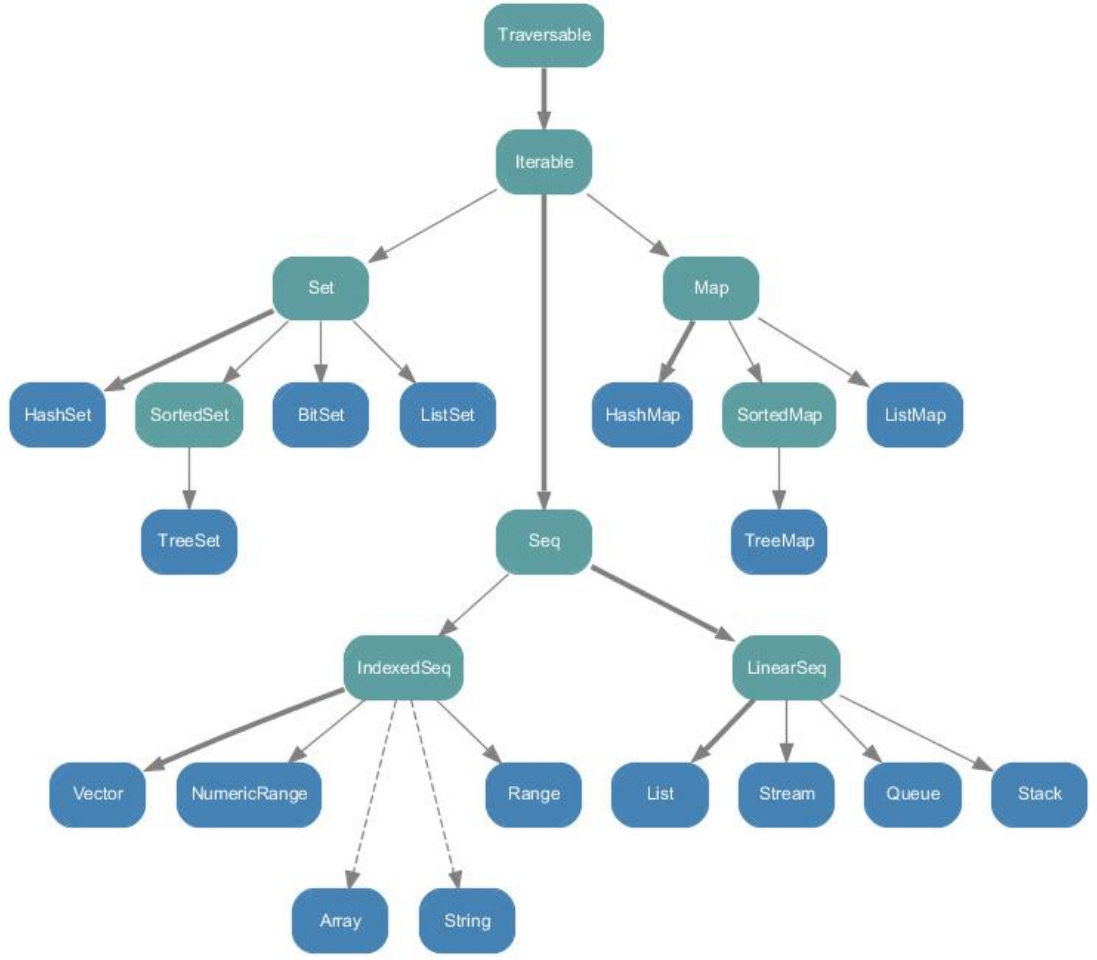
一.Seq 序列
1>.不可变的序列 import scala.collection.immutable._
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Scala%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.function 7 8 object SetOperation { 9 def main(args: Array[String]): Unit = { 10 //定义一个list 11 var list = List("yinzhengjie","Python","Golang","Java","Scala") 12 //查看list的头 13 print(s"list.head=====> ${list.head} ") 14 //查看list的尾,尾就是出了头部的数据 15 print(s"list.tail=====> ${list.tail} ") 16 //Nil表示为空,此时的list为空 17 list = Nil 18 print(s"list=====> ${list} ") 19 /** 20 * "::" 操作符是将给定的头和尾创建一个新的列表。 21 * 注意,"::" 操作符是右结合的,如 100::200::300::Nil 相当于 100::(200::(300::Nil)) 22 */ 23 var list2 = 100::200::300::list 24 println("list2=====>"+list2) 25 //“+”是拼接操作 26 var list3 = list2 + ("666666") 27 print(s"list3=====> ${list3} ") 28 //“++”是将两个集合进行拼接操作,最终会返回一个新的list对象,将右边的集合的每一个元素追加在左边集合的尾部 29 var list4 = list2 ++ List("J","Q","K") 30 print(s"list4=====> ${list4} ") 31 //“++:”是将右边的集合的每一个元素元素放置在左边集合的头部哟 32 var list5 = list2.++:(List("J","Q","K")) 33 print(s"list5=====> ${list5} ") 34 //“+:”是将右边的集合的放置在左边集合的头部,并非是将右边的集合的每个元素放进去! 35 var list6 = list2.+:(List("J","Q","K")) 36 print(s"list6=====> ${list6} ") 37 //“:+”是将右边的集合的放置在左边集合的尾部部,并非是将右边的集合的每个元素放进去! 38 var list7 = list2.:+(List("J","Q","K")) 39 print(s"list7=====> ${list7} ") 40 //“::”方法是将右边集合的每个元素和左边的集合合并为一个新的集合 41 var list8 = list2::(List("J","Q","K")) 42 print(s"list8=====> ${list8} ") 43 //判断list9集合中存在偶数的个数 44 val list9 = List(9,2,3,6,8,7,1,4,5) 45 val res1 = list9.count(x => x % 2 == 0) 46 print(s"res1=====> ${res1} ") 47 //判断list9集合中偶数的值 48 val res2 = list9.filter(x => x % 2 == 0) 49 print(s"res2=====> ${res2} ") 50 //对list9进行升序排序 51 val res3 = list9.sorted 52 print(s"res3=====> ${res3} ") 53 //list9进行降序排序,如果我们不用负号("-"),那么默认是以升序排序 54 val res4 = list9.sortBy(x => -x) 55 print(s"res4=====> ${res4} ") 56 //根据wordCount中的Int类型进行排序 57 val wordCount = List(("yinzhengjie",100),("Scala",80)) 58 val res5 = wordCount.sortWith((x,y) => x._2 > y._2) 59 print(s"res5=====> ${res5} ") 60 //指定每个分组允许的最大个数 61 val lis10 = List("yinzhengjie","Shell","Python","VBS","HTML","CSS","JavaScript","Golang","Java","Scala") 62 val res6 = lis10.grouped(3) 63 res6.foreach(x => print(x + " ")) 64 print(s"res6=====> ${res6} ") 65 /** 66 * 注意fold(定义初始值)(叠加的函数) 67 * 分析:val res7 = list11.fold(0)(_+_) 68 * fold(0)中的初始值为 : 0 69 * (_+_)是叠加的函数,左边的下划线是初始值,右边的下划线是list11中的每一个元素 70 * 综上所述: 71 * list11.fold(0)(_+_)会进行三次运算,因为list11的长度为3. 72 * 第一次运算,计算结果为: (0+9) 73 * 第二次运算的初始值是第一次计算的结果,计算结果为: (9+2) 74 * 第三次运算的初始值是上一次计算的结果,计算结果为: (11+3) 75 * 因此,我们可以得到最终的结果应该为: 14 76 */ 77 val list11= List(9,2,3) 78 val res7 = list11.fold(0)(_+_) //其实我们也可以这样写:val res7 = list11.fold(0)((x,y) => x + y) 79 print(s"res7=====> ${res7} ") 80 /** 81 * 相信你理解了上面的fold的方法,那么下面的fold的方法你估计也再熟悉不过了,因为fold底层调用的就是foldLeft方法。 82 */ 83 var res8 = list11.foldLeft(0)(_+_) 84 var res9 = list11.foldLeft(0)(_-_) 85 print(s"res8=====> ${res8} ") 86 print(s"res9=====> ${res9} ") 87 /** 88 * 在你理解foldLeft的工作原理后,相信foldRight对你来说更是小菜一碟啦,因为foldLeft和fold都是从左往右计算 89 * 第一次运算,计算结果为: (9-0) 90 * 第二次运算的初始值是上一次计算的结果,计算结果为: (2-9) 91 * 第三次运算的初始值是上一次计算的结果,计算结果为: (3-(2-9)) 92 * 因此,我们可以得到最终的结果应该为: 10 93 */ 94 var res10 = list11.foldRight(0)(_-_) 95 print(s"res10=====> ${res10} ") 96 //反转list的值,使用reverse方法 97 var list12 = List("yinzhengjie","Shell","Python","Scala") 98 list12 = list12.reverse 99 print(s"list12=====> ${list12} ") 100 //将列表进行聚合操作,如果列表中有字符串就直接拼接,如果全部是int类型就累加操作 101 val res11 = list12.reduce((x,y) => x + y) 102 print(s"res11=====> ${res11} ") 103 //aggregate(在Spark已经把它封装为reduceByKey)可以模拟并行化集合,可以把集合打散,在非并行化底层还是调用的foldLeft 104 var res12 = list11.aggregate(0)(_ + _,_+_) 105 print(s"res12=====> ${res12} ") 106 //计算出两个集合中的并集,就可以调用union方法 107 var list13 = List(1,3,5,7,9,0,8) 108 var list14 = List(8,0,7,2,4,6) 109 var res13 = list13.union(list14) 110 print(s"res13=====> ${res13} ") 111 //计算交集,调用intersect方法即可 112 var res14 = list13.intersect(list14) 113 print(s"res14=====> ${res14} ") 114 //计算两个集合的差集,即可以理解为不同元素 115 var res15 = list13.diff(list14) 116 print(s"res15=====> ${res15} ") 117 //拉链函数,可以把两个元素集合的没有索引进行咬合,新城一个新的元组。如果一个集合中比另一个集合元素要少,那么会以较少元素个数的集合进行匹配。 118 var res16 = list13.zip(list14) 119 print(s"res16=====> ${res16} ") 120 //格式化字符串操作,比如以“|”将list13中的每个元素隔开,并将结果以字符串的形式返回 121 var res17 = list13.mkString("|") 122 print(s"res17=====> ${res17} ") 123 //计算集合的大小或者是长度 124 var res18 = list13.size 125 var res19 = list13.length 126 print(s"res18=====> ${res18} ") 127 print(s"res19=====> ${res19} ") 128 //对应list取切片操作,和Python语法有点像,同样也是挂前不顾后! 129 var list15 =List("yinzhengjie","Hadoop","Nginx","MySQL","TomCat","Httpd") 130 var res20 = list15.slice(1,3) 131 print(s"res20=====> ${res20} ") 132 //对一个Int类型的结合进行求和运算 133 var list16 = List(1,2,3,4,5,6,7,8,9,10) 134 var res21 = list16.sum 135 print(s"res21=====> ${res21} ") 136 } 137 } 138 139 140 /* 141 以上代码执行结果如下: 142 list.head=====> yinzhengjie 143 list.tail=====> List(Python, Golang, Java, Scala) 144 list=====> List() 145 list2=====>List(100, 200, 300) 146 list3=====> List(100, 200, 300)666666 147 list4=====> List(100, 200, 300, J, Q, K) 148 list5=====> List(J, Q, K, 100, 200, 300) 149 list6=====> List(List(J, Q, K), 100, 200, 300) 150 list7=====> List(100, 200, 300, List(J, Q, K)) 151 list8=====> List(List(100, 200, 300), J, Q, K) 152 res1=====> 4 153 res2=====> List(2, 6, 8, 4) 154 res3=====> List(1, 2, 3, 4, 5, 6, 7, 8, 9) 155 res4=====> List(9, 8, 7, 6, 5, 4, 3, 2, 1) 156 res5=====> List((yinzhengjie,100), (Scala,80)) 157 List(yinzhengjie, Shell, Python) List(VBS, HTML, CSS) List(JavaScript, Golang, Java) List(Scala) res6=====> empty iterator 158 res7=====> 14 159 res8=====> 14 160 res9=====> -14 161 res10=====> 10 162 list12=====> List(Scala, Python, Shell, yinzhengjie) 163 res11=====> ScalaPythonShellyinzhengjie 164 res12=====> 14 165 res13=====> List(1, 3, 5, 7, 9, 0, 8, 8, 0, 7, 2, 4, 6) 166 res14=====> List(7, 0, 8) 167 res15=====> List(1, 3, 5, 9) 168 res16=====> List((1,8), (3,0), (5,7), (7,2), (9,4), (0,6)) 169 res17=====> 1|3|5|7|9|0|8 170 res18=====> 7 171 res19=====> 7 172 res20=====> List(Hadoop, Nginx) 173 res21=====> 55 174 */
2>.可变的序列 import scala.collection.mutable._
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Scala%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 7 package cn.org.yinzhengjie.function 8 9 import scala.collection.mutable.ListBuffer 10 11 object ListOperationDemo { 12 13 def main(args: Array[String]): Unit = { 14 //构建一个可变列表,初始有 3 个元素 1,2,3 15 val res = ListBuffer[Int](1,2,3) 16 print(s"res=====> ${res} ") 17 18 //创建一个空的可变列表 19 val res2 = new ListBuffer[Int] 20 print(s"res2=====> ${res2} ") 21 22 //向 res2 中追加元素,注意:没有生成新的集合 23 res2+= 4 24 res2.append(5) 25 print(s"res2=====> ${res2} ") 26 27 //将 res2 中的元素追加到 res 中, 注意:没有生成新的集合 28 res ++= res2 29 print(s"res=====> ${res} ") 30 31 //将 res 和 res2 合并成一个新的 ListBuffer 注意:生成了一个集合 32 val res3 = res ++ res2 33 print(s"res3=====> ${res3} ") 34 35 //将元素追加到 res 的后面生成一个新的集合 36 val res4 = res :+ 10 37 print(s"res4=====> ${res4} ") 38 } 39 } 40 41 42 43 44 /* 45 以上代码执行结果如下 : 46 res=====> ListBuffer(1, 2, 3) 47 res2=====> ListBuffer() 48 res2=====> ListBuffer(4, 5) 49 res=====> ListBuffer(1, 2, 3, 4, 5) 50 res3=====> ListBuffer(1, 2, 3, 4, 5, 4, 5) 51 res4=====> ListBuffer(1, 2, 3, 4, 5, 10) 52 */
二.Set集合
1>.不可变的 Set
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Scala%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.function 7 8 9 object setOperationDemo { 10 def main(args: Array[String]): Unit = { 11 var s1 =Set(1,2,3,5) 12 var s2 =Set(2,3,4) 13 //计算交集 14 val res1 = s1.intersect(s2) 15 val res2 = s1 & s2 16 println(s"res1 ======> ${res1}") 17 println(s"res2 ======> ${res2}") 18 //计算并集 19 val res3 = s1.union(s2) 20 val res4 = s1 | s2 21 println(s"res3 ======> ${res3}") 22 println(s"res4 ======> ${res4}") 23 //计算差集 24 val res5 = s1.diff(s2) 25 val res6 = s1 &~ s2 26 println(s"res5 ======> ${res5}") 27 println(s"res6 ======> ${res6}") 28 29 /** 30 * 查看当前使用的是哪个类 31 */ 32 println(s1.getClass) 33 } 34 } 35 36 37 38 /* 39 以上代码执行结果如下 : 40 res1 ======> Set(2, 3) 41 res2 ======> Set(2, 3) 42 res3 ======> Set(5, 1, 2, 3, 4) 43 res4 ======> Set(5, 1, 2, 3, 4) 44 res5 ======> Set(1, 5) 45 res6 ======> Set(1, 5) 46 class scala.collection.immutable.Set$Set4 47 */
2>.可变的 Set
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Scala%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.function 7 8 import scala.collection.mutable 9 10 object setOperationDemo { 11 def main(args: Array[String]): Unit = { 12 /** 13 * 创建一个可变的 HashSet 14 */ 15 val set1 = new mutable.HashSet[Int]() 16 print(s"set1=====> ${set1} ") 17 /** 18 * 向“HashSet ”中添加元素 : 19 * 1>.由于set的顺序是无序的,因此插入过程中可能不存在 ; 20 * 2>.add一般用于追加一个元素 ; 21 * 3>.如果想要一次性追加多个元素可以用".+="的方式添加,也可以使用“++=”操作符 ; 22 */ 23 set1.add(4) 24 set1 += (100,500) 25 set1.+=(300,200) 26 set1 ++= Set (1,3,5) 27 print(s"set1=====> ${set1} ") 28 29 /** 30 * 向“HashSet”中删除元素 : 31 * 1>.删除一个元素一般用"remove"方法 ; 32 * 2>.如果要删除多个元素 33 */ 34 set1 -= (100,200) 35 set1.-=(3,4) 36 set1.remove(5) 37 print(s"set1=====> ${set1} ") 38 39 /** 40 * 查看当前使用的是那个类 41 */ 42 println (set1.getClass) 43 } 44 } 45 46 47 48 /* 49 以上代码执行结果如下 : 50 set1=====> Set() 51 set1=====> Set(1, 300, 100, 5, 3, 500, 4, 200) 52 set1=====> Set(1, 300, 500) 53 class scala.collection.mutable.HashSet 54 */
三.Map映射
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Scala%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.basicGrammar 7 8 import scala.collection.mutable 9 10 object MapDemo { 11 def main(args: Array[String]): Unit = { 12 //定义不可变的map 13 val map = Map[String,Int]("尹正杰" -> 18) 14 print(s"map=====> ${map} ") 15 16 //定义一个可变的map 17 val changeableMap = mutable.HashMap[String,Int]() 18 print(s"changeableMap=====> ${changeableMap} ") 19 20 //往可变map中添加元素,这种添加方式和Java如出一辙 21 changeableMap.put("尹正杰", 26 ) 22 changeableMap += "yinzhengjie" -> 18 //当然Scala也可以使用“+=”添加元素哟 23 changeableMap +=(("JDK",8),("Scala",2),("Hadoop",2)) //如果想要一次性添加多个元素,每个元素有逗号分隔即可 24 print(s"changeableMap=====> ${changeableMap} ") 25 26 //删除map中元素 27 changeableMap.remove("Scala") 28 print(s"changeableMap=====> ${changeableMap} ") 29 changeableMap.-=("Hadoop") //当然Scala也可以使用“-=”删除元素哟 30 print(s"changeableMap=====> ${changeableMap} ") 31 32 //获取Map中的元素 33 val res1 = map.get("尹正杰").get 34 print(s"res1=====> ${res1} ") 35 val res2 = changeableMap.get("尹正杰").get 36 print(s"res2=====> ${res2} ") 37 38 //getOrElse方法是判断Map中是否有某个key,如果有就返回具体的值,若没有则返回我们提前设定的值 39 val res3 = changeableMap.getOrElse("Python",100) 40 val res4 = changeableMap.getOrElse("JDK",200) 41 print(s"res3=====> ${res3} ") 42 print(s"res4=====> ${res4} ") 43 44 /** 45 * 扩充知识点: 46 * 在Scala 中Option 类型样例类用来表示可能存在或也可能不存在的值(Option 的子类有Some 47 * 和None)。Some 包装了某个值,None 表示没有值。 48 * Option 是Some 和None 的父类 49 * Some 代表有(多例),样例类 50 * None 代表没有(单例),样例对象 51 */ 52 var res5:Option[Any] = Some("yinzhengjie","python","shell","vbs") 53 print(s"res5=====> ${res5} ") 54 //取出Option的值 55 val res6 = res5.get 56 print(s"res6=====> ${res6} ") 57 //判断Option是否为空 58 val res7 = res5.isEmpty 59 print(s"res7=====> ${res7} ") 60 61 /** 62 * Option 的get方法返回的为Option, 也就意味着res6可能取到也有可能没取到,如果res5=None 时, 63 * 会出现异常情况: NoSuchElementException: None.get 64 */ 65 res5=None 66 val res8 = res5.isEmpty 67 print(s"res8=====> ${res8} ") 68 // val res9 = res5.get 69 // print(s"res9=====> ${res9} ") 70 } 71 } 72 73 74 75 /* 76 以上代码执行结果如下 : 77 map=====> Map(尹正杰 -> 18) 78 changeableMap=====> Map() 79 changeableMap=====> Map(yinzhengjie -> 18, Hadoop -> 2, 尹正杰 -> 26, Scala -> 2, JDK -> 8) 80 changeableMap=====> Map(yinzhengjie -> 18, Hadoop -> 2, 尹正杰 -> 26, JDK -> 8) 81 changeableMap=====> Map(yinzhengjie -> 18, 尹正杰 -> 26, JDK -> 8) 82 res1=====> 18 83 res2=====> 26 84 res3=====> 100 85 res4=====> 8 86 res5=====> Some((yinzhengjie,python,shell,vbs)) 87 res6=====> (yinzhengjie,python,shell,vbs) 88 res7=====> false 89 res8=====> true 90 */
四.元组(Tuple)
Scala 元组将固定数量的项目组合在一起,以便它们可以作为一个整体传递。与数组或列表不同,元组可以容纳不同类型的对象,但它们也是不可变的。元组是类型Tuple1,Tuple2,Tuple3 等等。目前在Scala 中只能有22 个上限,如果您需要更多个元素,那么可以使用集合而不是元组。
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Scala%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.basicGrammar 7 8 object TupleDemo { 9 10 def main(args: Array[String]): Unit = { 11 12 //定义一个元组 13 val tuple = ("yinzhengjie",2018,true,Unit) 14 15 //访问元素中的第一个元素,根据下标访问即可,默认是从1开始计数的 16 val res1 = tuple._1 17 print(s"res1=====> ${res1} ") 18 19 /** 20 * productIterator: 21 * 可以将一个元组转换成一个数组 22 * foreach: 23 * 可以遍历迭代器中的每一个元素 24 */ 25 tuple.productIterator.foreach(x => print(x + " ")) 26 println() 27 28 /** 29 * 对偶元组: 30 * 顾名思义。对偶元组指的是元组中元素的个数只有2个。 31 */ 32 val tuple1 = ("yinzhengjie",2018) 33 print(s"tuple1=====> ${tuple1} ") 34 val res2 = tuple1.swap 35 print(s"res2=====> ${res2} ") 36 37 } 38 39 } 40 41 42 43 /* 44 以上代码执行结果如下: 45 res1=====> yinzhengjie 46 yinzhengjie 2018 true object scala.Unit 47 tuple1=====> (yinzhengjie,2018) 48 res2=====> (2018,yinzhengjie) 49 */
五.Scala中的并行化集合
Scala结合Hadoop中的MapReduce思想,可以模拟分布式计算,使用par方法即可。
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Scala%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.function 7 8 object MyListPar { 9 def main(args: Array[String]): Unit = { 10 var list = (1 to 10).toList 11 println(list) 12 13 /** 14 * 在没有开启并行化时,我们会看到执行map任务时都在主线程执行 15 */ 16 list.map(e => { 17 //获取当前线程名称 18 val name = Thread.currentThread().getName() 19 println(name + " : " + e) 20 //将listl列表中的数据乘以2 21 println(e * 2) 22 }) 23 24 println(" ==============我是分割线============= ") 25 26 /** 27 * Scala结合Hadoop中的MapReduce思想,可以模拟分布式计算,使用par方法即可。 28 * 使用par方法将list对象转成并行化集合,我们会看到执行map任务时开启了多个线程执行,缺点是执行顺序不一致啦! 29 */ 30 list.par.map(e => { 31 //获取当前线程名称 32 val name = Thread.currentThread().getName() 33 println(name + " : " + e) 34 //将listl列表中的数据乘以2 35 println(e * 2) 36 }) 37 } 38 } 39 40 41 42 /* 43 以上代码执行结果如下 : 44 List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) 45 main : 1 46 2 47 main : 2 48 4 49 main : 3 50 6 51 main : 4 52 8 53 main : 5 54 10 55 main : 6 56 12 57 main : 7 58 14 59 main : 8 60 16 61 main : 9 62 18 63 main : 10 64 20 65 66 ==============我是分割线============= 67 68 scala-execution-context-global-11 : 1 69 2 70 scala-execution-context-global-11 : 2 71 4 72 scala-execution-context-global-14 : 8 73 scala-execution-context-global-12 : 6 74 12 75 scala-execution-context-global-12 : 7 76 14 77 scala-execution-context-global-13 : 3 78 6 79 scala-execution-context-global-13 : 4 80 8 81 scala-execution-context-global-13 : 5 82 10 83 16 84 scala-execution-context-global-14 : 9 85 18 86 scala-execution-context-global-14 : 10 87 20 88 89 */
六.小试牛刀
1>.对数组的字符串进行单词统计
不知道你是否感觉到了,大数据统计不管是MapReduce还是Spark他们最终的计算都类似于之中WordCount,因此想要学习大数据,练习写WordCount是你必经之路,我们可以对一个数组的数据进行单词统计,以及排序等操作,只需要一行就可以搞定,而且速度那是相当的快呀!下面我介绍4中单词统计的方式,其实万变不离其宗。具体代码如下:
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Scala%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.basicGrammar 7 8 object WordCount { 9 10 def main(args: Array[String]): Unit = { 11 //定义需要统计的单词 12 val words = Array("hello Scala","hello Spark","hello Java","Java Scala") 13 14 // 实现方式一 15 val res1 = words .flatMap(_.split(" ")) // 对数组中的每个元素进行切分, 并进行扁平化操作 16 .map((_, 1)) // 将数组的每个元素转换成一个对偶元组, 元组的第二个元素为1 17 .groupBy(_._1) // 对集合中的所有元素进行按单词分组, 相同单词的元组分到一组 18 .mapValues(_.length) // 对每个key 的value 集合进行求长度操作 19 .toList // 将map 转换成List 20 .sortBy(t => - t._2) // 实现降序排列,默认是升序排列 21 22 // 实现方式二 23 val res2 = words .flatMap(_.split(" ")).groupBy(x => x).map(t => (t._1,t._2.length)).toList.sortBy(t => t._2) 24 25 //实现方式三 26 val res3 = words.flatMap(_.split(" ")).map(x =>(x,1)).groupBy(x=>x._1).mapValues(t=>t.foldLeft(0)(_+_._2)) 27 28 //实现方式四 29 val res4 = words.flatMap(_.split(" ")).map(x =>(x,1)).groupBy(x =>x._1).mapValues(t=>t.foldRight(0)(_._2 + _)).toList.sortBy(t => - t._2) 30 31 print(s"res1=====> ${res1} ") 32 print(s"res2=====> ${res2} ") 33 print(s"res3=====> ${res3} ") 34 print(s"res4=====> ${res4} ") 35 36 } 37 } 38 39 40 41 /* 42 以上代码执行结果如下: 43 res1=====> List((hello,3), (Scala,2), (Java,2), (Spark,1)) 44 res2=====> List((Spark,1), (Scala,2), (Java,2), (hello,3)) 45 res3=====> Map(Spark -> 1, Scala -> 2, Java -> 2, hello -> 3) 46 res4=====> List((hello,3), (Scala,2), (Java,2), (Spark,1)) 47 */
2>.