Hadoop基础-MapReduce的Partitioner用法案例
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.Partitioner关键代码剖析
1>.返回的分区号

2>.partitioner默认是通过hash方法实现的
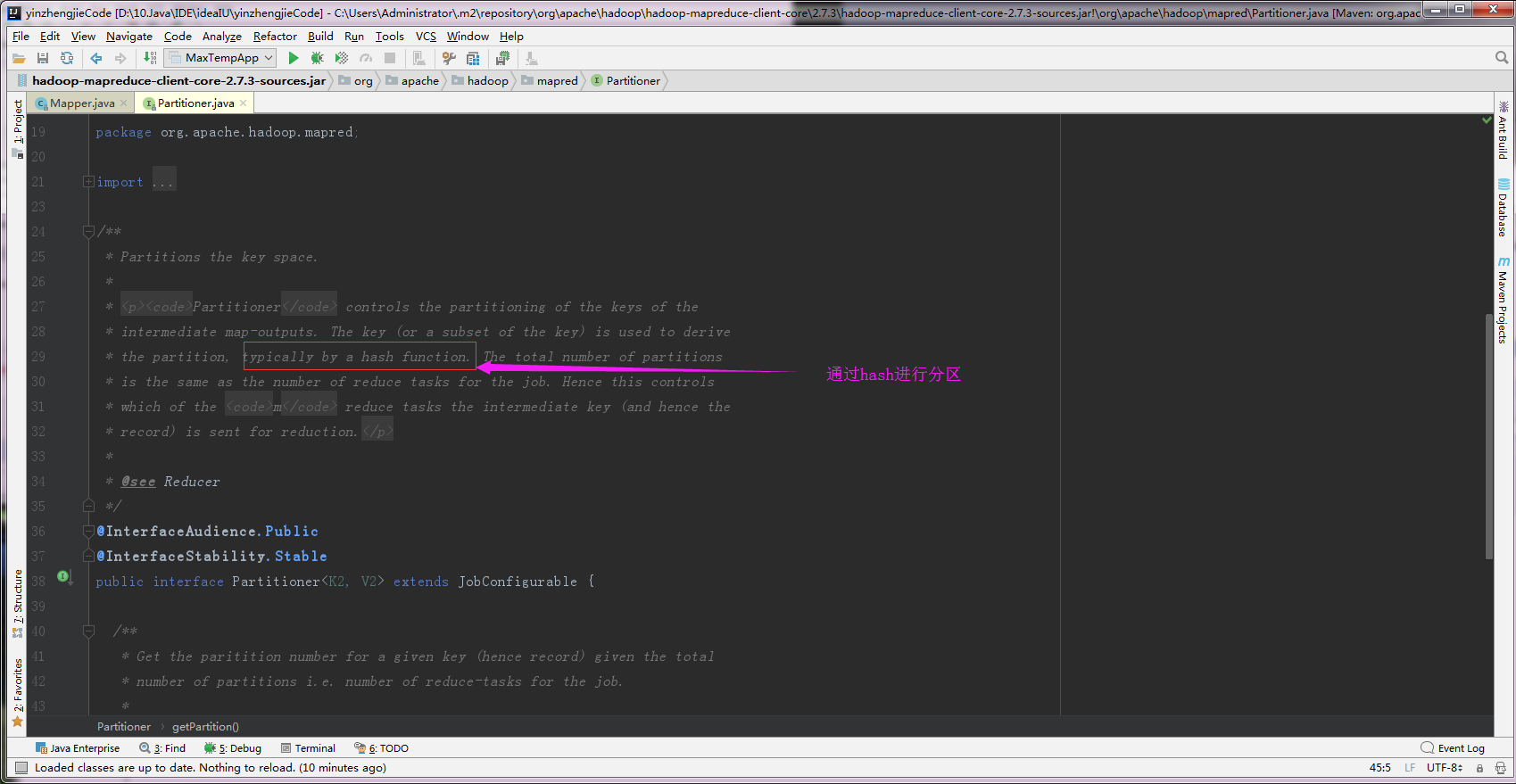
返回的是一个int类型的数组:

3>.HashPartitioner

接下来咱们就看看Partition在MapReduce的作用是什么吧。
二.Partitioner在MapReduce的位置
1>.什么是Partitioner
通过查看Partitioner的源码估计你也发现了Partitioner跟hash有关系,那么它到底是什么呢?能帮我们做什么事情呢?说白了它就是帮我们实现分发Key和value的一个过程,它负责将同一个key发给同一个Reduce。还记得我们之前说的Combiner吗?Combiner相当于Map端的Reduce,用于减少网络间分发。说直白点就是将key进行折叠的一个操作,将一个key的初始值为1方给Reduce端100万次,和将key进行折叠后形成key的初始值为100万,在发送给Reduce可以街上带宽资源,还可以减少网络带宽。而这个分发过程就是Partitioner程序完成的,当然我们是不定义Partitioner也不会报错。
2>.Partitioner在MapReduce的位置
接下来我们大致看一下Partitioner在MapReduce的大致位置,如下:
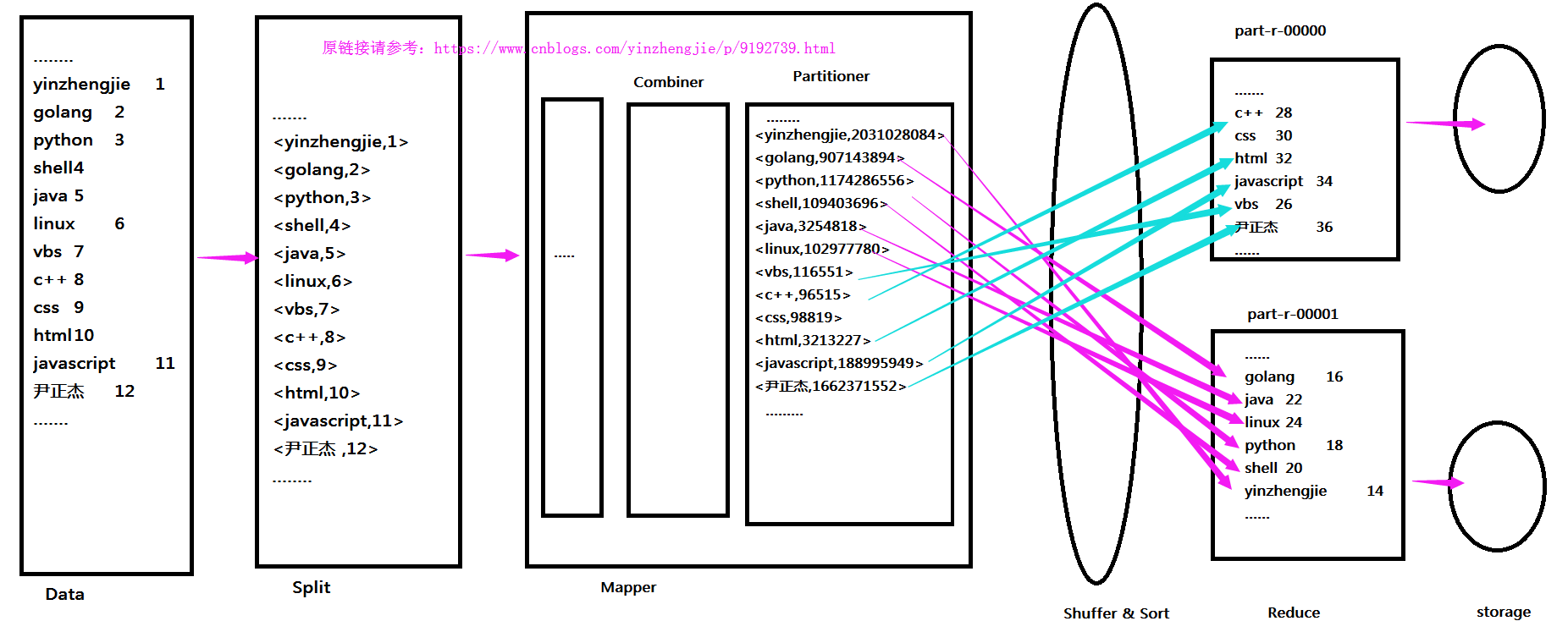
接下来我们就一起体验一下设置Partitioner和不设置Partitioner的明显区别。
三.未定义Partitioner的情况
1>.测试数据文件内容(partitioner.txt)
yinzhengjie 1 golang 2 python 3 shell 4 java 5 linux 6 vbs 7 c++ 8 css 9 html 10 javascript 11 尹正杰 12 yinzhengjie 13 golang 14 python 15 shell 16 java 17 linux 18 vbs 19 c++ 20 css 21 html 22 javascript 23 尹正杰 24
2>.KVMapper.java 文件内容
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.mapreduce.partition; 7 8 import org.apache.hadoop.io.IntWritable; 9 import org.apache.hadoop.io.Text; 10 import org.apache.hadoop.mapreduce.Mapper; 11 12 import java.io.IOException; 13 14 public class KVMapper extends Mapper<Text,Text,Text,IntWritable> { 15 @Override 16 protected void map(Text key, Text value, Context context) throws IOException, InterruptedException { 17 //将value转换成int类型 18 int val = Integer.parseInt(value.toString()); 19 context.write(key,new IntWritable(val)); 20 } 21 }
3>.KVReduce.java 文件内容
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.mapreduce.partition; 7 8 import org.apache.hadoop.io.IntWritable; 9 import org.apache.hadoop.io.Text; 10 import org.apache.hadoop.mapreduce.Reducer; 11 12 import java.io.IOException; 13 14 public class KVReduce extends Reducer<Text,IntWritable,Text,IntWritable> { 15 @Override 16 protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { 17 int count = 0; 18 for (IntWritable value : values) { 19 count += value.get(); 20 } 21 context.write(key,new IntWritable(count)); 22 } 23 }
4>.KVApp.java 文件内容
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.mapreduce.partition; 7 8 import org.apache.hadoop.conf.Configuration; 9 import org.apache.hadoop.fs.FileSystem; 10 import org.apache.hadoop.fs.Path; 11 import org.apache.hadoop.io.IntWritable; 12 import org.apache.hadoop.io.Text; 13 import org.apache.hadoop.mapreduce.Job; 14 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 15 import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat; 16 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 17 18 public class KVApp { 19 public static void main(String[] args) throws Exception { 20 //实例化一个Configuration,它会自动去加载本地的core-site.xml配置文件的fs.defaultFS属性。(该文件放在项目的resources目录即可。) 21 Configuration conf = new Configuration(); 22 //将hdfs写入的路径定义在本地,需要修改默认为文件系统,这样就可以覆盖到之前在core-site.xml配置文件读取到的数据。 23 conf.set("fs.defaultFS","file:///"); 24 //创建一个任务对象job,别忘记把conf穿进去哟! 25 Job job = Job.getInstance(conf); 26 //给任务起个名字 27 job.setJobName("WordCount"); 28 //设置输入格式以K-V的类型传入,这样K的类型就是Mapper输入端的key,而V的类型就是Mapper输入端的value 29 job.setInputFormatClass(KeyValueTextInputFormat.class); 30 //指定main函数所在的类,也就是当前所在的类名 31 job.setJarByClass(KVApp.class); 32 //指定map的类名,这里指定咱们自定义的map程序即可 33 job.setMapperClass(KVMapper.class); 34 //指定reduce的类名,这里指定咱们自定义的reduce程序即可 35 job.setReducerClass(KVReduce.class); 36 //设置输出key的数据类型 37 job.setOutputKeyClass(Text.class); 38 //设置输出value的数据类型 39 job.setOutputValueClass(IntWritable.class); 40 //设置输入路径,需要传递两个参数,即任务对象(job)以及输入路径 41 FileInputFormat.addInputPath(job,new Path("D:\10.Java\IDE\yhinzhengjieData\MyHadoop\Partitioner\partitioner.txt")); 42 //初始化HDFS文件系统,此时我们需要把读取到的fs.defaultFS属性传给fs对象。我的目的是调用该对象的delete方法,删除已经存在的文件夹 43 FileSystem fs = FileSystem.get(conf); 44 //通过fs的delete方法可以删除文件,第一个参数指的是删除文件对象,第二参数是指递归删除,一般用作删除目录 45 Path outPath = new Path("D:\10.Java\IDE\yhinzhengjieData\MyHadoop\Partitioner\out"); 46 if (fs.exists(outPath)){ 47 fs.delete(outPath,true); 48 } 49 //设置输出路径,需要传递两个参数,即任务对象(job)以及输出路径 50 FileOutputFormat.setOutputPath(job,outPath); 51 //Reduce的个数,咱们是可以自己设置的 52 job.setNumReduceTasks(2); 53 //等待任务执行结束,将里面的值设置为true。 54 job.waitForCompletion(true); 55 } 56 }


WARNING: An illegal reflective access operation has occurred WARNING: Illegal reflective access by org.apache.hadoop.security.authentication.util.KerberosUtil (file:/C:/Users/Administrator/.m2/repository/org/apache/hadoop/hadoop-auth/2.7.3/hadoop-auth-2.7.3.jar) to method sun.security.krb5.Config.getInstance() WARNING: Please consider reporting this to the maintainers of org.apache.hadoop.security.authentication.util.KerberosUtil WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations WARNING: All illegal access operations will be denied in a future release 18/06/18 08:51:19 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id 18/06/18 08:51:19 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId= 18/06/18 08:51:19 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 18/06/18 08:51:19 WARN mapreduce.JobResourceUploader: No job jar file set. User classes may not be found. See Job or Job#setJar(String). 18/06/18 08:51:19 INFO input.FileInputFormat: Total input paths to process : 1 18/06/18 08:51:19 INFO mapreduce.JobSubmitter: number of splits:1 18/06/18 08:51:19 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local1080098995_0001 18/06/18 08:51:19 INFO mapreduce.Job: The url to track the job: http://localhost:8080/ 18/06/18 08:51:19 INFO mapreduce.Job: Running job: job_local1080098995_0001 18/06/18 08:51:19 INFO mapred.LocalJobRunner: OutputCommitter set in config null 18/06/18 08:51:19 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1 18/06/18 08:51:19 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter 18/06/18 08:51:19 INFO mapred.LocalJobRunner: Waiting for map tasks 18/06/18 08:51:19 INFO mapred.LocalJobRunner: Starting task: attempt_local1080098995_0001_m_000000_0 18/06/18 08:51:19 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1 18/06/18 08:51:19 INFO util.ProcfsBasedProcessTree: ProcfsBasedProcessTree currently is supported only on Linux. 18/06/18 08:51:19 INFO mapred.Task: Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@59eafdde 18/06/18 08:51:19 INFO mapred.MapTask: Processing split: file:/D:/10.Java/IDE/yhinzhengjieData/MyHadoop/Partitioner/partitioner.txt:0+241 18/06/18 08:51:19 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584) 18/06/18 08:51:19 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100 18/06/18 08:51:19 INFO mapred.MapTask: soft limit at 83886080 18/06/18 08:51:19 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600 18/06/18 08:51:19 INFO mapred.MapTask: kvstart = 26214396; length = 6553600 18/06/18 08:51:19 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer 18/06/18 08:51:19 INFO mapred.LocalJobRunner: 18/06/18 08:51:19 INFO mapred.MapTask: Starting flush of map output 18/06/18 08:51:19 INFO mapred.MapTask: Spilling map output 18/06/18 08:51:19 INFO mapred.MapTask: bufstart = 0; bufend = 252; bufvoid = 104857600 18/06/18 08:51:19 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 26214304(104857216); length = 93/6553600 18/06/18 08:51:19 INFO mapred.MapTask: Finished spill 0 18/06/18 08:51:19 INFO mapred.Task: Task:attempt_local1080098995_0001_m_000000_0 is done. And is in the process of committing 18/06/18 08:51:19 INFO mapred.LocalJobRunner: file:/D:/10.Java/IDE/yhinzhengjieData/MyHadoop/Partitioner/partitioner.txt:0+241 18/06/18 08:51:19 INFO mapred.Task: Task 'attempt_local1080098995_0001_m_000000_0' done. 18/06/18 08:51:19 INFO mapred.LocalJobRunner: Finishing task: attempt_local1080098995_0001_m_000000_0 18/06/18 08:51:19 INFO mapred.LocalJobRunner: map task executor complete. 18/06/18 08:51:19 INFO mapred.LocalJobRunner: Waiting for reduce tasks 18/06/18 08:51:19 INFO mapred.LocalJobRunner: Starting task: attempt_local1080098995_0001_r_000000_0 18/06/18 08:51:19 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1 18/06/18 08:51:19 INFO util.ProcfsBasedProcessTree: ProcfsBasedProcessTree currently is supported only on Linux. 18/06/18 08:51:19 INFO mapred.Task: Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@5d916cac 18/06/18 08:51:19 INFO mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@6ef6c4ad 18/06/18 08:51:19 INFO reduce.MergeManagerImpl: MergerManager: memoryLimit=2996200960, maxSingleShuffleLimit=749050240, mergeThreshold=1977492736, ioSortFactor=10, memToMemMergeOutputsThreshold=10 18/06/18 08:51:19 INFO reduce.EventFetcher: attempt_local1080098995_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events 18/06/18 08:51:19 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local1080098995_0001_m_000000_0 decomp: 144 len: 148 to MEMORY 18/06/18 08:51:19 INFO reduce.InMemoryMapOutput: Read 144 bytes from map-output for attempt_local1080098995_0001_m_000000_0 18/06/18 08:51:19 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 144, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->144 18/06/18 08:51:19 INFO reduce.EventFetcher: EventFetcher is interrupted.. Returning 18/06/18 08:51:19 INFO mapred.LocalJobRunner: 1 / 1 copied. 18/06/18 08:51:19 INFO reduce.MergeManagerImpl: finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs 18/06/18 08:51:19 INFO mapred.Merger: Merging 1 sorted segments 18/06/18 08:51:19 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 138 bytes 18/06/18 08:51:19 INFO reduce.MergeManagerImpl: Merged 1 segments, 144 bytes to disk to satisfy reduce memory limit 18/06/18 08:51:19 INFO reduce.MergeManagerImpl: Merging 1 files, 148 bytes from disk 18/06/18 08:51:19 INFO reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memory into reduce 18/06/18 08:51:19 INFO mapred.Merger: Merging 1 sorted segments 18/06/18 08:51:19 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 138 bytes 18/06/18 08:51:19 INFO mapred.LocalJobRunner: 1 / 1 copied. 18/06/18 08:51:19 INFO Configuration.deprecation: mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords 18/06/18 08:51:19 INFO mapred.Task: Task:attempt_local1080098995_0001_r_000000_0 is done. And is in the process of committing 18/06/18 08:51:19 INFO mapred.LocalJobRunner: 1 / 1 copied. 18/06/18 08:51:19 INFO mapred.Task: Task attempt_local1080098995_0001_r_000000_0 is allowed to commit now 18/06/18 08:51:19 INFO output.FileOutputCommitter: Saved output of task 'attempt_local1080098995_0001_r_000000_0' to file:/D:/10.Java/IDE/yhinzhengjieData/MyHadoop/Partitioner/out/_temporary/0/task_local1080098995_0001_r_000000 18/06/18 08:51:19 INFO mapred.LocalJobRunner: reduce > reduce 18/06/18 08:51:19 INFO mapred.Task: Task 'attempt_local1080098995_0001_r_000000_0' done. 18/06/18 08:51:19 INFO mapred.LocalJobRunner: Finishing task: attempt_local1080098995_0001_r_000000_0 18/06/18 08:51:19 INFO mapred.LocalJobRunner: Starting task: attempt_local1080098995_0001_r_000001_0 18/06/18 08:51:19 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1 18/06/18 08:51:19 INFO util.ProcfsBasedProcessTree: ProcfsBasedProcessTree currently is supported only on Linux. 18/06/18 08:51:19 INFO mapred.Task: Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@378ab11d 18/06/18 08:51:19 INFO mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@10246d23 18/06/18 08:51:19 INFO reduce.MergeManagerImpl: MergerManager: memoryLimit=2996200960, maxSingleShuffleLimit=749050240, mergeThreshold=1977492736, ioSortFactor=10, memToMemMergeOutputsThreshold=10 18/06/18 08:51:19 INFO reduce.EventFetcher: attempt_local1080098995_0001_r_000001_0 Thread started: EventFetcher for fetching Map Completion Events 18/06/18 08:51:19 INFO reduce.LocalFetcher: localfetcher#2 about to shuffle output of map attempt_local1080098995_0001_m_000000_0 decomp: 160 len: 164 to MEMORY 18/06/18 08:51:19 INFO reduce.InMemoryMapOutput: Read 160 bytes from map-output for attempt_local1080098995_0001_m_000000_0 18/06/18 08:51:19 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 160, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->160 18/06/18 08:51:19 INFO reduce.EventFetcher: EventFetcher is interrupted.. Returning 18/06/18 08:51:19 INFO mapred.LocalJobRunner: 1 / 1 copied. 18/06/18 08:51:19 INFO reduce.MergeManagerImpl: finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs 18/06/18 08:51:19 INFO mapred.Merger: Merging 1 sorted segments 18/06/18 08:51:19 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 151 bytes 18/06/18 08:51:19 INFO reduce.MergeManagerImpl: Merged 1 segments, 160 bytes to disk to satisfy reduce memory limit 18/06/18 08:51:19 INFO reduce.MergeManagerImpl: Merging 1 files, 164 bytes from disk 18/06/18 08:51:19 INFO reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memory into reduce 18/06/18 08:51:19 INFO mapred.Merger: Merging 1 sorted segments 18/06/18 08:51:19 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 151 bytes 18/06/18 08:51:19 INFO mapred.LocalJobRunner: 1 / 1 copied. 18/06/18 08:51:19 INFO mapred.Task: Task:attempt_local1080098995_0001_r_000001_0 is done. And is in the process of committing 18/06/18 08:51:19 INFO mapred.LocalJobRunner: 1 / 1 copied. 18/06/18 08:51:19 INFO mapred.Task: Task attempt_local1080098995_0001_r_000001_0 is allowed to commit now 18/06/18 08:51:19 INFO output.FileOutputCommitter: Saved output of task 'attempt_local1080098995_0001_r_000001_0' to file:/D:/10.Java/IDE/yhinzhengjieData/MyHadoop/Partitioner/out/_temporary/0/task_local1080098995_0001_r_000001 18/06/18 08:51:19 INFO mapred.LocalJobRunner: reduce > reduce 18/06/18 08:51:19 INFO mapred.Task: Task 'attempt_local1080098995_0001_r_000001_0' done. 18/06/18 08:51:19 INFO mapred.LocalJobRunner: Finishing task: attempt_local1080098995_0001_r_000001_0 18/06/18 08:51:19 INFO mapred.LocalJobRunner: reduce task executor complete. 18/06/18 08:51:20 INFO mapreduce.Job: Job job_local1080098995_0001 running in uber mode : false 18/06/18 08:51:20 INFO mapreduce.Job: map 100% reduce 100% 18/06/18 08:51:20 INFO mapreduce.Job: Job job_local1080098995_0001 completed successfully 18/06/18 08:51:20 INFO mapreduce.Job: Counters: 30 File System Counters FILE: Number of bytes read=2721 FILE: Number of bytes written=886698 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 Map-Reduce Framework Map input records=24 Map output records=24 Map output bytes=252 Map output materialized bytes=312 Input split bytes=139 Combine input records=0 Combine output records=0 Reduce input groups=12 Reduce shuffle bytes=312 Reduce input records=24 Reduce output records=12 Spilled Records=48 Shuffled Maps =2 Failed Shuffles=0 Merged Map outputs=2 GC time elapsed (ms)=0 Total committed heap usage (bytes)=805306368 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=241 File Output Format Counters Bytes Written=138
5>.查看生成的文件内容
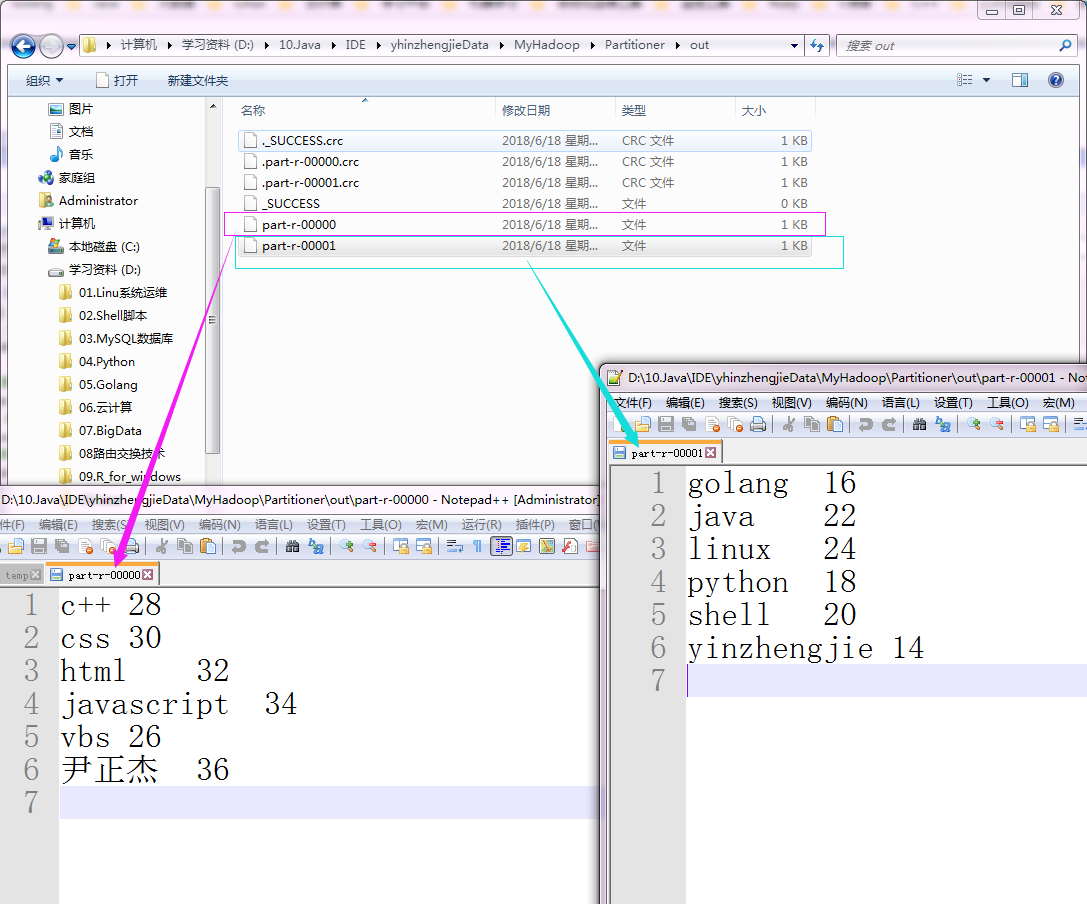
四.定义Partitioner的情况
1>.Mapper和Reduce端代码不变
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.mapreduce.partition; 7 8 import org.apache.hadoop.io.IntWritable; 9 import org.apache.hadoop.io.Text; 10 import org.apache.hadoop.mapreduce.Mapper; 11 12 import java.io.IOException; 13 14 public class KVMapper extends Mapper<Text,Text,Text,IntWritable> { 15 @Override 16 protected void map(Text key, Text value, Context context) throws IOException, InterruptedException { 17 //将value转换成int类型 18 int val = Integer.parseInt(value.toString()); 19 context.write(key,new IntWritable(val)); 20 } 21 }
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.mapreduce.partition; 7 8 import org.apache.hadoop.io.IntWritable; 9 import org.apache.hadoop.io.Text; 10 import org.apache.hadoop.mapreduce.Reducer; 11 12 import java.io.IOException; 13 14 public class KVReduce extends Reducer<Text,IntWritable,Text,IntWritable> { 15 @Override 16 protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { 17 int count = 0; 18 for (IntWritable value : values) { 19 count += value.get(); 20 } 21 context.write(key,new IntWritable(count)); 22 } 23 }
2>.Partitioner端代码
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.mapreduce.partition; 7 8 import org.apache.hadoop.io.IntWritable; 9 import org.apache.hadoop.io.Text; 10 import org.apache.hadoop.mapreduce.Partitioner; 11 12 public class Partition extends Partitioner<Text,IntWritable> { 13 @Override 14 public int getPartition(Text text, IntWritable intWritable, int numPartitions) { 15 //此处使用了一个取巧的方式,如果字符串不能转换成数字,说明该字符串是数字类型,就会被分到0号分区,反之就会分到1号分区。 16 try { 17 Integer.parseInt(text.toString()); 18 return 0; 19 } catch (Exception e) { 20 return 1; 21 } 22 } 23 }
3>.KVApp.java 端代码
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.mapreduce.partition; 7 8 import org.apache.hadoop.conf.Configuration; 9 import org.apache.hadoop.fs.FileSystem; 10 import org.apache.hadoop.fs.Path; 11 import org.apache.hadoop.io.IntWritable; 12 import org.apache.hadoop.io.Text; 13 import org.apache.hadoop.mapreduce.Job; 14 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 15 import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat; 16 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 17 18 public class KVApp { 19 public static void main(String[] args) throws Exception { 20 //实例化一个Configuration,它会自动去加载本地的core-site.xml配置文件的fs.defaultFS属性。(该文件放在项目的resources目录即可。) 21 Configuration conf = new Configuration(); 22 //将hdfs写入的路径定义在本地,需要修改默认为文件系统,这样就可以覆盖到之前在core-site.xml配置文件读取到的数据。 23 conf.set("fs.defaultFS","file:///"); 24 //创建一个任务对象job,别忘记把conf穿进去哟! 25 Job job = Job.getInstance(conf); 26 //给任务起个名字 27 job.setJobName("WordCount"); 28 //设置输入格式以K-V的类型传入,这样K的类型就是Mapper输入端的key,而V的类型就是Mapper输入端的value 29 job.setInputFormatClass(KeyValueTextInputFormat.class); 30 //指定main函数所在的类,也就是当前所在的类名 31 job.setJarByClass(KVApp.class); 32 //指定map的类名,这里指定咱们自定义的map程序即可 33 job.setMapperClass(KVMapper.class); 34 //指定reduce的类名,这里指定咱们自定义的reduce程序即可 35 job.setReducerClass(KVReduce.class); 36 //指定Partitioner的类名,这里指定咱们自定义的Partition程序即可 37 job.setPartitionerClass(Partition.class); 38 //设置输出key的数据类型 39 job.setOutputKeyClass(Text.class); 40 //设置输出value的数据类型 41 job.setOutputValueClass(IntWritable.class); 42 //设置输入路径,需要传递两个参数,即任务对象(job)以及输入路径 43 FileInputFormat.addInputPath(job,new Path("D:\10.Java\IDE\yhinzhengjieData\MyHadoop\Partitioner\partitioner.txt")); 44 //初始化HDFS文件系统,此时我们需要把读取到的fs.defaultFS属性传给fs对象。我的目的是调用该对象的delete方法,删除已经存在的文件夹 45 FileSystem fs = FileSystem.get(conf); 46 //通过fs的delete方法可以删除文件,第一个参数指的是删除文件对象,第二参数是指递归删除,一般用作删除目录 47 Path outPath = new Path("D:\10.Java\IDE\yhinzhengjieData\MyHadoop\Partitioner\out"); 48 if (fs.exists(outPath)){ 49 fs.delete(outPath,true); 50 } 51 //设置输出路径,需要传递两个参数,即任务对象(job)以及输出路径 52 FileOutputFormat.setOutputPath(job,outPath); 53 //Reduce的个数,咱们是可以自己设置的 54 job.setNumReduceTasks(2); 55 //等待任务执行结束,将里面的值设置为true。 56 job.waitForCompletion(true); 57 } 58 }
4>.测试结果如下:
