Java基础-二进制以及字符编码简介
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
想必计算机毕业的小伙伴或是从事IT的技术人员都知道数据存储都是以二进制的数字存储到硬盘的。从事开发的兄弟们对二进制估计也再熟悉不过了。但是现实生活中我们都是知其然不知其所以然。这也是我在学习大数据之前对二进制的迷茫,就说Java中关于byte和int两种不同的数据类型吧,byte是字节类型,一个字节等于八个比特位,int是整数型,它占用了四个字节,共计32个比特位。那么你对二进制确定了解的很透彻吗?比如“-1”是如何通过二进制表示的,为什么一个字节的取值范围是“-128~127”,为什么在二进制中“0”是正数?“-128”是如何表示的呢?如果你对这些还没有了解透彻,我们可以一起来探讨一下。
一.计算机只能识别“0”和“1”
在计算机中,所有的数据都是以“0”和“1”的形式存在的,比如CPU,内存,硬盘中的数据都是“0”和“1”。话句话说,计算机只能识别“0”和“1”,因为计算机是由数字逻辑电路设计成的,电路只有通电和断电两种稳定的状态,就用“0”和“1”来表示这两种状态。
在计算机中存储一个“0”或“1”,需要使用一个比特位(bit),一个字节(byte)字节表示8个二进制位。做大数据的小伙伴,电脑的标配内存建议是32G,你们32Gbyte是多少字节呢?(32GByte = 32*1024Mbyte = 32*1024*1024Kbyte = 32*1024*1024*1024Byte)。
二.简介二进制
1>.什么是二进制
二进制是计算技术中广泛采用的一种数制。二进制数据是用0和1两个数码来表示的数。它的基数为2,进位规则是“逢二进一”,借位规则是“借一当二”,由18世纪德国数理哲学大师莱布尼兹发现。当前的计算机系统使用的基本上是二进制系统,数据在计算机中主要是以补码的形式存储的。计算机中的二进制则是一个非常微小的开关,用“开”来表示1,“关”来表示0。
2>.如何用二进制表示数字“8”

综上图:我们可以看出数字“8”用二进制表示为:“00001000”。
3>.如何用二进制表示数字“-8”
Java的负数采用补码方式存储,即:取反+1。我们知道正数“8”用二进制表示应为:“00001000”,如果对其取反则为:“10000111”,我们如果在对他进行加“1”操作后的数字应为:“10001000”,所以我们说“-8”用二进制表示则为:"10001000",那么问题来了,“8”和“-8”的相加的和应该是多少呢?相信大家都是心知肚明的,那么我们看看计算机是如何用二进制表示的吧。

如上图所示:数字“8”和“-8”的相加的和为:“100000000”,很显然,一个字节只能存储8位,所以,我们要把最前面的那个“1”丢弃掉,这样就得到了“00000000”,即8个“0”,因此,“8”+“-8”的值为“0”。现在想想发明二进制算法的人真是牛逼啊!连这样的空隙都想出来了!!
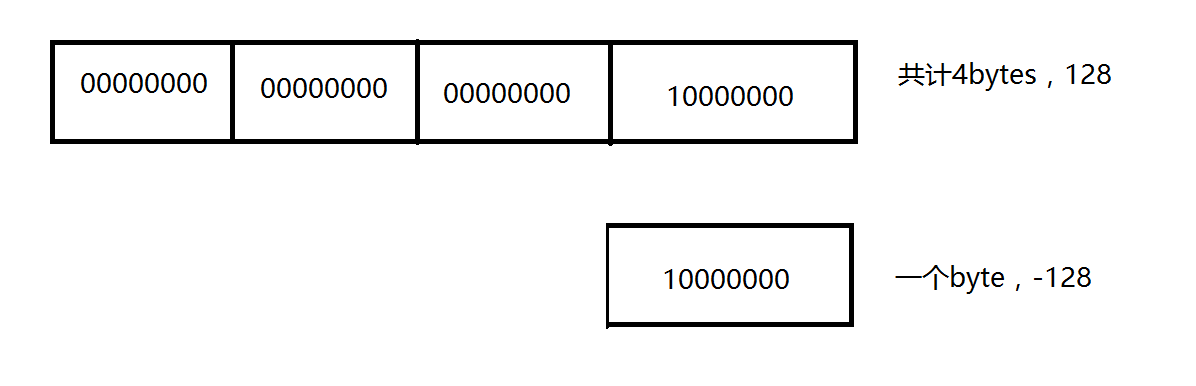
4>.小试牛刀-int和byte类型强制转换

其实原理很简单,byte类型只有8个bits,最大的值为“-128~127”,其结果如下:
三.字符编码
字符编码可以把我们输入的汉字等字符转换为对应的“01”序列,还可以把“01”序列转换为对应的字符。
1>.编码
把字符转换成对应的码值。
2>.解码
把一个整数转换为对应的字符。
3>.常用的字符编码
a>.ASCII 编码,美国的标准的信息转换码,仅使用一个字节存储;
b>.ISO-9959-1 编码,西欧编码,Tomcat服务器默认的编码格式;
c>.GBK(一个汉字对应2个字节)/GB2312编码,简体中文编码,每个汉字都对应两个字节的“01”序列;
d>.BIG5(一个汉字对应2个字节),繁体中文编码;
e>.Unicode 编码,为全世界所有的语言都提供了唯一的编码,有utf-8(一个汉字对应3个字节),utf-16等常用的编码格式。
f>.UTF-8编码,国际化统一编码,可以表示任何文字。
注意:任何字符集都是ASCII编码的超集。
4>.乱码
编码时使用的编码格式与解码时使用的解码格式不一致就会出现乱码。如"尹正杰"三个汉字使用utf-8编码,生成“01”序列为9个字节,如果是用GB2312进行解码,把两个字节的“01”序列翻译为一个汉字,最终解码出来的数据肯定是不正常的。现在你应该明白为什么你下载了一个晚上的小电影,最后用播放器打开的时候提示无法渲染该文件内容,这就是因为播放器不支持你所下载的视频格式。
5>.小试牛刀
a>.打印出Java中char可以表示的类型
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Java%E5%9F%BA%E7%A1%80/ 4 EMAIL:y1053419035@qq.com 5 */ 6 7 package cn.org.yinzhengjie.java; 8 9 import org.junit.Test; 10 11 public class CharacterCoding { 12 //打印出Java中char可以表示的类型 13 @Test 14 public void testChar(){ 15 int count = 0; 16 for (int i = 0x0000;i <= 0xffff;i++){ 17 char res = (char)i; 18 if (count == 20){ 19 count = 0; 20 System.out.println(); 21 } 22 System.out.print(i + ":" + res + " "); 23 count++; 24 } 25 } 26 }
b>.对“尹正杰”这个字符串进程编码和解码操作
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Java%E5%9F%BA%E7%A1%80/ 4 EMAIL:y1053419035@qq.com 5 */ 6 7 package cn.org.yinzhengjie.java; 8 9 import org.junit.Test; 10 import java.nio.charset.Charset; 11 12 public class CharacterCoding { 13 @Test 14 public void testCharset() throws Exception { 15 String str = "尹正杰" ; 16 //编码 17 System.out.println(Charset.defaultCharset().name()); //查看当前操作平台默认的编码格式 18 byte[] bytes = str.getBytes("unicode") ; //编码的格式以Unicode进行编码 19 20 //解码 21 String str2 = new String(bytes, "unicode") ; //解码的格式以Unicode的方式进行解码 22 System.out.println(str2); 23 } 24 }
c>.找出“尹正杰”这个字符串在Unicode存储的编号
/* @author :yinzhengjie Blog:http://www.cnblogs.com/yinzhengjie/tag/Java%E5%9F%BA%E7%A1%80/ EMAIL:y1053419035@qq.com */ package cn.org.yinzhengjie.java; import org.junit.Test; public class CharacterCoding { //找出“尹正杰”对应的unicode编号,不推荐使用!效率低! @Test public void searchName(){ for(int i = 0x0000;i<0xffff;i++){ char res = (char)i; if (res == '尹' || res == '正' || res == '杰'){ System.out.print(i + ":" + res + " "); } } } //找出“尹正杰”对应的unicode编号,推荐使用! @Test public void searchName2(){ int yin = '尹'; int zheng = '正'; int jie = '杰'; System.out.println(yin); System.out.println(zheng); System.out.println(jie); } }
d>.定义函数,取出整数内存中的存储形态对应的16进制字符串。
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Java%E5%9F%BA%E7%A1%80/ 4 EMAIL:y1053419035@qq.com 5 */ 6 7 package cn.org.yinzhengjie.java; 8 9 public class CharacterCoding { 10 /** 11 * 定义函数,取出整数内存中的存储形态对应的16进制字符串。 12 */ 13 public static String int2hexStr(int j){ 14 StringBuffer buffer = new StringBuffer(); 15 char[] chars = {'0','1','2','3','4','5','6','7','8','9','A','B','C','D','E','F',}; 16 for (int i = 0;i<8;i++){ 17 //每次移动不同的位数,然后和0x0f进行“&”运算,目的是为了把前28位的数字都变成0,只截移位后的最后4位,而这最后4位的取值范围恰巧在chars数组中! 18 char c = chars[j>>(i * 4) & 0x0f]; 19 //每次取值后,将该数据插入到首位 20 buffer.insert(0,c); 21 } 22 return buffer.toString(); 23 } 24 25 public static void main(String[] args) { 26 int year = 2018; 27 String res = int2hexStr(year); 28 System.out.println(res); 29 } 30 } 31 32 /* 33 以上代码执行结果如下: 34 000007E2 35 */
e>.定义函数,取出整数内存中的存储形态对应的2进制字符串。
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Java%E5%9F%BA%E7%A1%80/ 4 EMAIL:y1053419035@qq.com 5 */ 6 7 package cn.org.yinzhengjie.java; 8 9 public class CharacterCoding { 10 /** 11 * 定义函数,取出整数内存中的存储形态对应的2进制字符串。 12 */ 13 public static String int2BinaryStr(int j){ 14 StringBuffer buffer = new StringBuffer(); 15 char[] chars = {'0','1'}; 16 for (int i = 0;i<32;i++){ 17 char c = chars[j>>(i * 1) & 0x01]; 18 //每次取值后,将该数据插入到首位 19 buffer.insert(0,c); 20 } 21 return buffer.toString(); 22 } 23 24 public static void main(String[] args) { 25 int year = 2018; 26 String res = int2BinaryStr(year); 27 System.out.println(res); 28 } 29 } 30 31 32 /* 33 以上代码输出结果如下: 34 00000000000000000000011111100010 35 */