通过日志聚合将作业日志存储在HDFS中
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.启用日志聚合功能
在默认情况下,Hadoop将所有日志存储在运行作业任务的节点上。在特定时间段后应用程序日志会被自动删除。可以配置日志聚合功能,将日志存储在HDFS中来长久保留日志信息。 日志聚合意味着一旦作业完成,Hadoop会自动聚合运行作业任务的所有节点的作业日志,并将它们移动到HDFS。日志记录是一个与YARN相关的特性。 在默认情况下禁用日志聚合功能,但可以通过在"${HADOOP_HOME}/etc/hadoop/yarn-site.xml"文件中设置yarn.log-aggregation-enable参数来启用: <property> <name>yarn.log-aggregation-enable</name> <value>true</value> <description> 每个DataNode上的NodeManager使用此属性来聚合应用程序日志。默认值为"false",启用日志聚合时,Hadoop收集作为应用程序一部分的每个容器的日志,并在应用完成后将这些文件移动到HDFS。 可以使用"yarn.nodemanager.remote-app-log-dir"和"yarn.nodemanager.remote-app-log-dir-suffix"属性来指定在HDFS中聚合日志的位置。 </description> </property> 由于在默认情况下禁用日志聚合功能,因此yarn.log-aggregation-enable参数的默认值为"false"。一旦启用日志聚合,还需要关注其他的事情,以确保日志聚合工作正常。
温馨提示:
日志聚合提供了许多有用的功能,但这需要配置,因为默认是禁用日志聚合功能的。
用户和管理员通常需要对作业日志进行历史Fenix,而不是尝试设置自定义的日志收集过程,只需启用日志聚合,以便自动在HDFS中存储作业日志,存储的时间长短也可以设置。
二.Hadoop存储聚合日志的位置
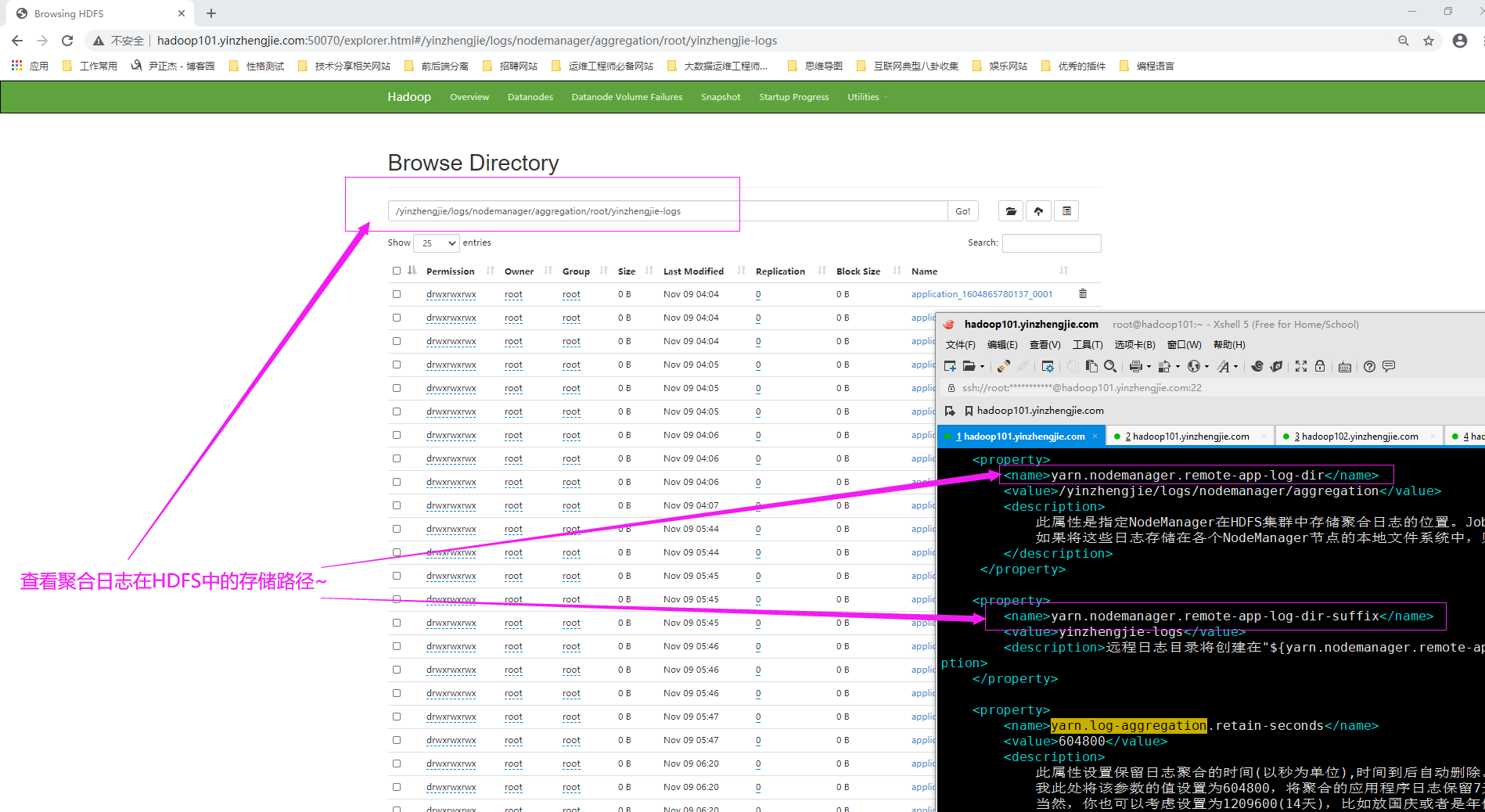
1>.指定NodeManager在HDFS集群中存储聚合日志的位置
启用日志聚合后,NodeManager会将所有容器日志连接到一个文件中并将它保存在HDFS中。它也会在间隔"${yarn.nodemanager.delete.debug-delay-sec}"秒后从本地目录(由"${yarn.nodemanager.log-dirs}"属性指定)中删除本地日志。 可以使用"${yarn.nodemanager.remote-app-log-dir}"属性配置Hadoop在HDFS的哪里存储聚合的日志,如下所示: <property> <name>yarn.nodemanager.remote-app-log-dir</name> <value>/yinzhengjie/logs/nodemanager/aggregation</value> <description> 此属性是指定NodeManager在HDFS集群中存储聚合日志的位置。JobHistoryServer将应用日志存储在HDFS中的此目录中。默认值为"/tmp/logs" 如果将这些日志存储在各个NodeManager节点的本地文件系统中,则JobHistoryServer和其他Hadoop守护进程将无法访问并使用这些日志,这是将它们存储在HDFS中的原因。 </description> </property> 温馨提示: yarn.nodemanager.remote-app-log-dir属性用来设置存储聚合日志文件的根HDFS目录的位置,实际的日志文件会存储在执行作业的用户命名的子目录下。 每个用户将其聚合日志存储在HDFS中的"${yarn.nodemanager.remote-app-log-dir}/${user.name}/"文件夹中, 如下图所示。
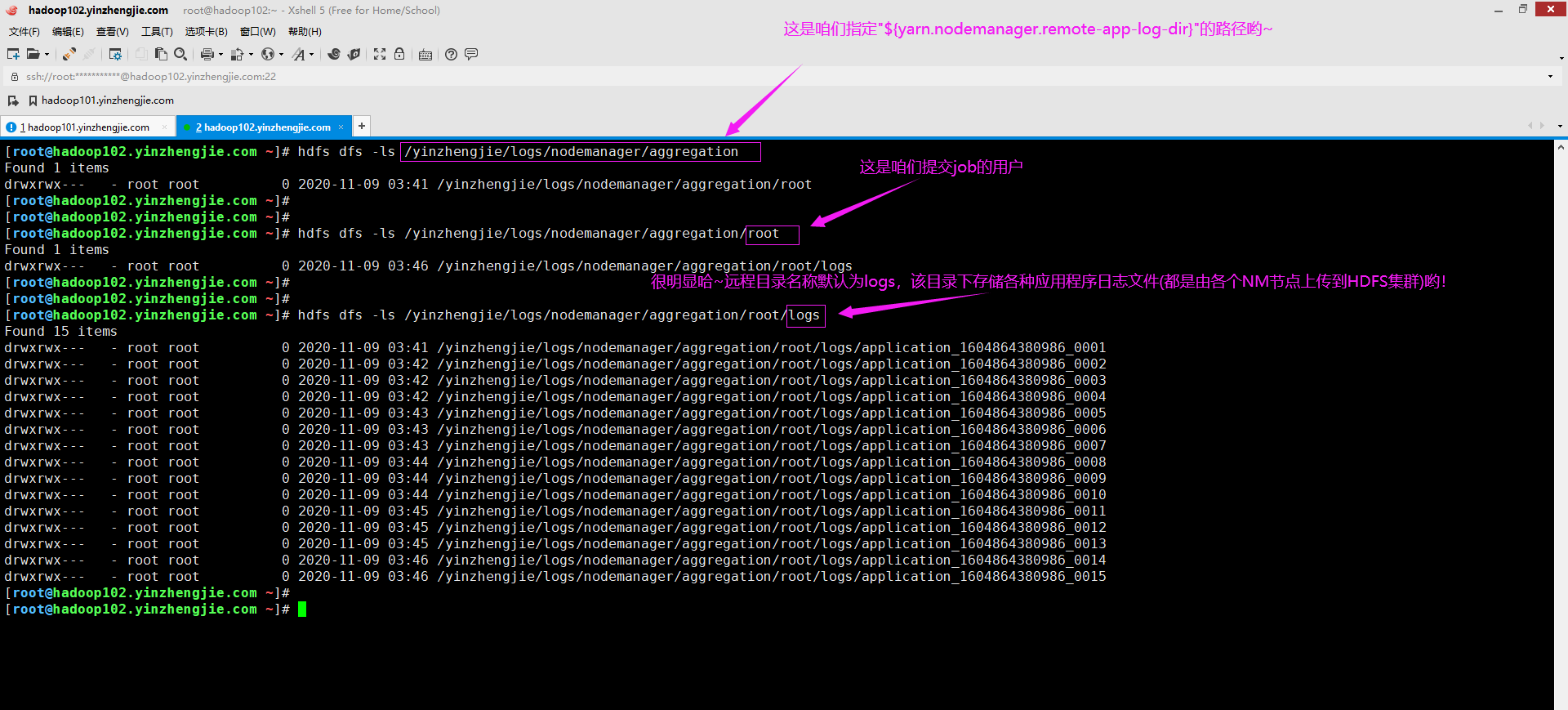
2>.设置HDFS远程日志目录的名称
可以使用"yarn.nodemanager.remote-app-log-dir-suffix"属性设置HDFS中远程目录的名称,若不指定该参数属性,默认值为"logs",如上图所示。 我们可以自定义"yarn.nodemanager.remote-app-log-dir-suffix"的属性值,远程目录日志将创建在"${yarn.nodemanager.remote-app-log-dir}/${user.name}/${yarn.nodemanager.remote-app-log-dir-suffix}",如下所示。 <property> <name>yarn.nodemanager.remote-app-log-dir-suffix</name> <value>yinzhengjie-logs</value> <description>远程日志目录将创建在"${yarn.nodemanager.remote-app-log-dir}/${user.name}/${yarn.nodemanager.remote-app-log-dir-suffix}",该属性默认值为"logs"。</description> </property> 温馨提示:
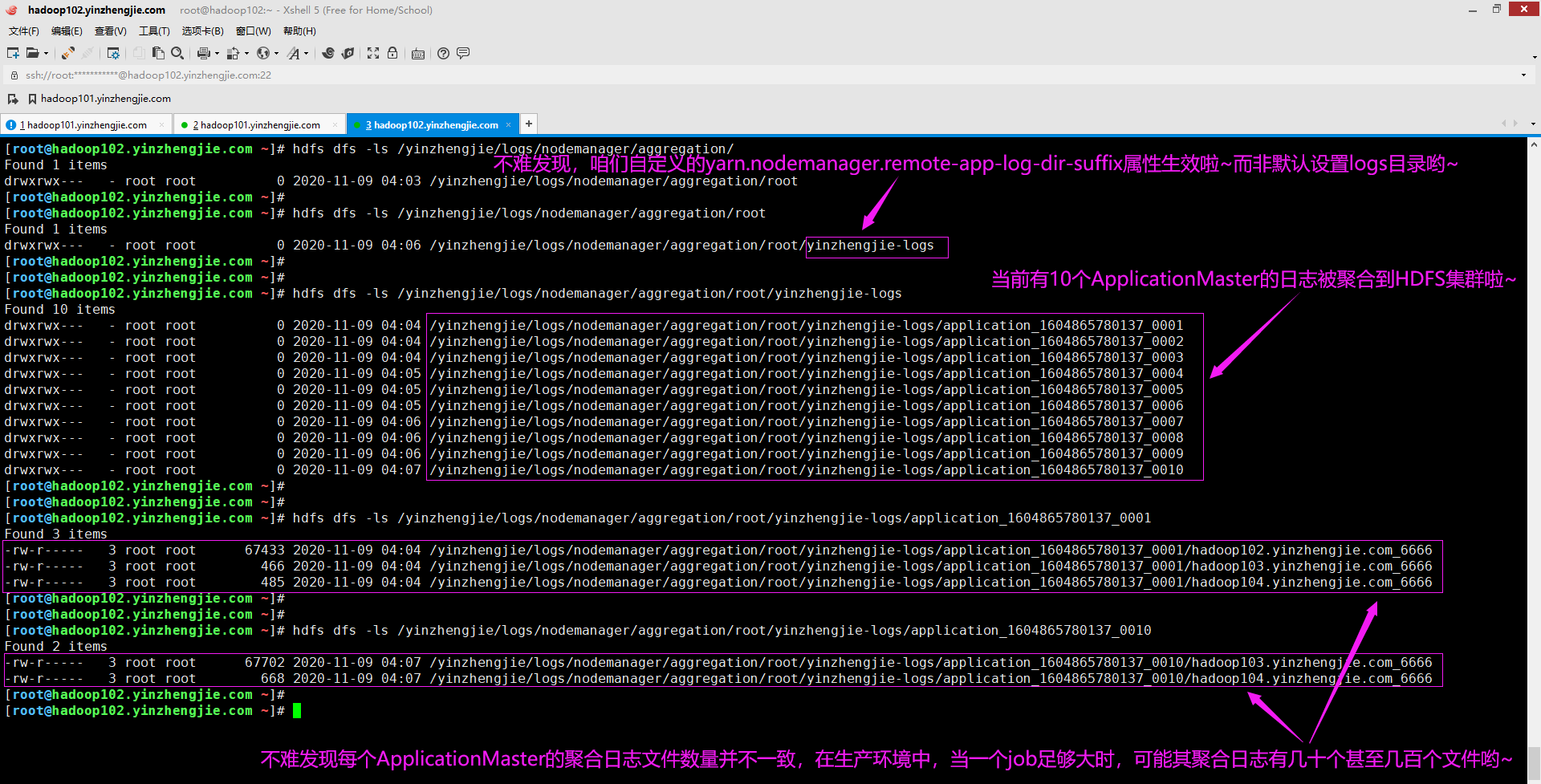
一个特定的应用程序的实际HDFS位置是"${yarn.nodemanager.remote-app-log-dir}/${user.name}/${yarn.nodemanager.remote-app-log-dir-suffix}/<application ID>",如下图所示。
三.配置日志保留时间
我们需要在"${HADOOP_HOME}/etc/hadoop/yarn-site.xml"配置文件中定义日志保留时间。下面几个参数需要我们重点关心一下哟~ 在禁用日志聚合功能是,以下两个参数指定日志保留的时间和日志删除行为: yarn.nodemanager.log.retain-seconds: 指定日志保留的时间周期,以秒为单位,默认10800,即3小时。 yarn.nodemanager.log.deletion-threads-count: 指定日志用于清理日志的线程数,默认值为4。 在启用日志聚合功能后,上述两个参数全部时效,以下是日志保留配置参数将生效: yarn.log-aggregation.retain-seconds: 日志删除HDFS日志聚合的时间,若将此参数设置为一个负数(例如默认值为-1),则永久不删除日志,这意味着应用程序的日志聚合所占的空间会不断的增长,从而造成HDFS集群的资源过度使用。 yarn.log.server.url: 指定应用程序(例如:MRAppMaster,SparkAppMaster等等)运行完成后可以访问聚合日志的URL,若不指定,默认值为空。 温馨提示: 如果作业历史记录文件比你用"mapreduce.jobhistory.max-age-ms"属性配置的作业历史文件还要大,则其会被删除。此属性的默认值为"604800000毫秒"(即1周)。
1>.yarn.nodemanager.log.retain-seconds
<property> <name>yarn.nodemanager.log.retain-seconds</name> <value>10800</value> <description> 指定在单节点上保留用户日志的时间(以秒为单位)。需要注意的是,仅在禁用日志聚合的情况下此属性值才生效,默认值为:10800s(即3小时)。 启用日志聚合功能后,用户运行完作业时,日志将移动到HDFS集群"${yarn.nodemanager.remote-app-log-dir}/${user.name}/${yarn.nodemanager.remote-app-log-dir-suffix}/"目录下。 当达到"${yarn.nodemanager.delete.debug-delay-sec}"指定阈值后,立即删除存储在本地目录的日志文件。 </description> </property>
2>.yarn.nodemanager.log.deletion-threads-count
<property> <name>yarn.nodemanager.log.deletion-threads-count</name> <value>8</value> <description>指定NodeManager用于清理日志的线程数,需要注意的是,仅在禁用日志聚合的情况下此属性值才生效,默认值为:4,通常设置为当前操作系统的cores即可。</description> </property>
3>.yarn.log-aggregation.retain-seconds
<property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> <description> 此属性设置保留日志聚合的时间(以秒为单位),时间到后自动删除。设置为一个负数(如默认值-1)会禁止删除日志。 我此处将该参数的值设置为604800,将聚合的应用程序日志保留7天。如果设置非常长的保留时间,日志会占用大量昂贵的HDFS存储空间(尤其是在公有云上,是按容量收费的)。 当然,你也可以考虑设置为1209600(14天),比如放国庆或者是年假,有可能等你回公司想要查询你休假期间某个日志的运行情况,可以考虑设置的更长哟,不过通常情况下,7天很合适。 </description> </property>
4>.yarn.log.server.url
<property> <name>yarn.log.server.url</name> <value>http://hadoop105.yinzhengjie.com:19888/yinzhengjie/history_logs/aggregation</value> <description> 指定应用程序(例如:MRAppMaster,SparkAppMaster等等)运行完成后可以访问聚合日志的URL。NameNodes将WebUI用户重定向到此URL,并且指向MapReduce作业历史记录。若不指定,默认值为空。 需要注意的是,若配置该参数,通常需要我们启用History服务哟~ </description> </property>
5>.mapreduce.jobhistory.max-age-ms
温馨提示: 如果你想将"yarn.log-aggregation.retain-seconds"的属性值设置大于7天的话,请记得修改如下图所示的属性。该属性用于运行历史清理程序时,将删除早于此毫秒的作业历史文件。 注意哈,该属性在"${HADOOP_HOME}/etc/hadoop/mapred-site.xml"文件中来修改哟~

四.访问存储在HDFS中的日志文件
1>.访问特定应用程序日志
经过上面的配置,重启YARN集群和HistoryServer服务后立即生效。现在就可以访问HDFS中实际日志文件了,可以访问特定节点的聚合日志并下载到本地,如下图所示。
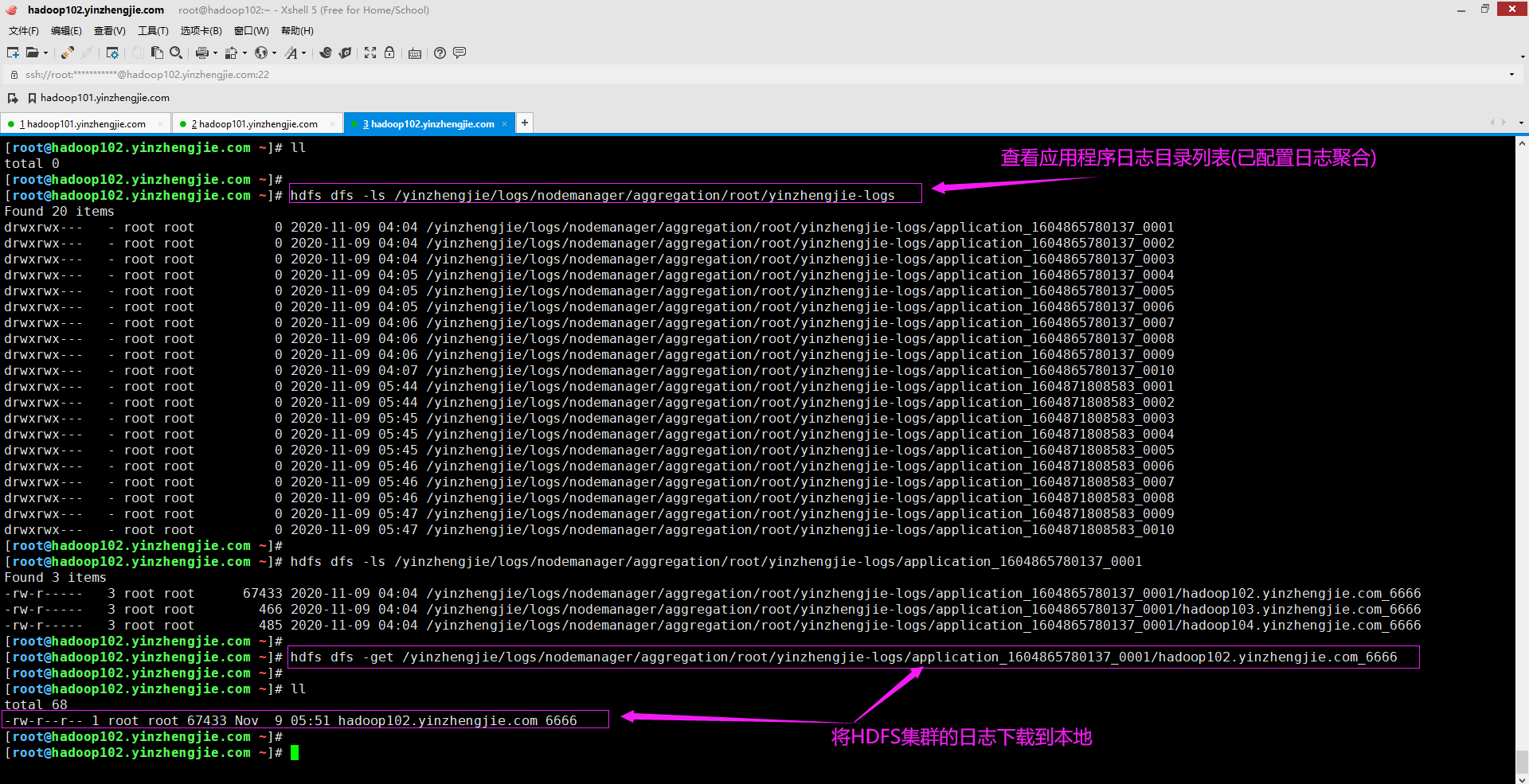
2>.查看下载到本地的日志文件

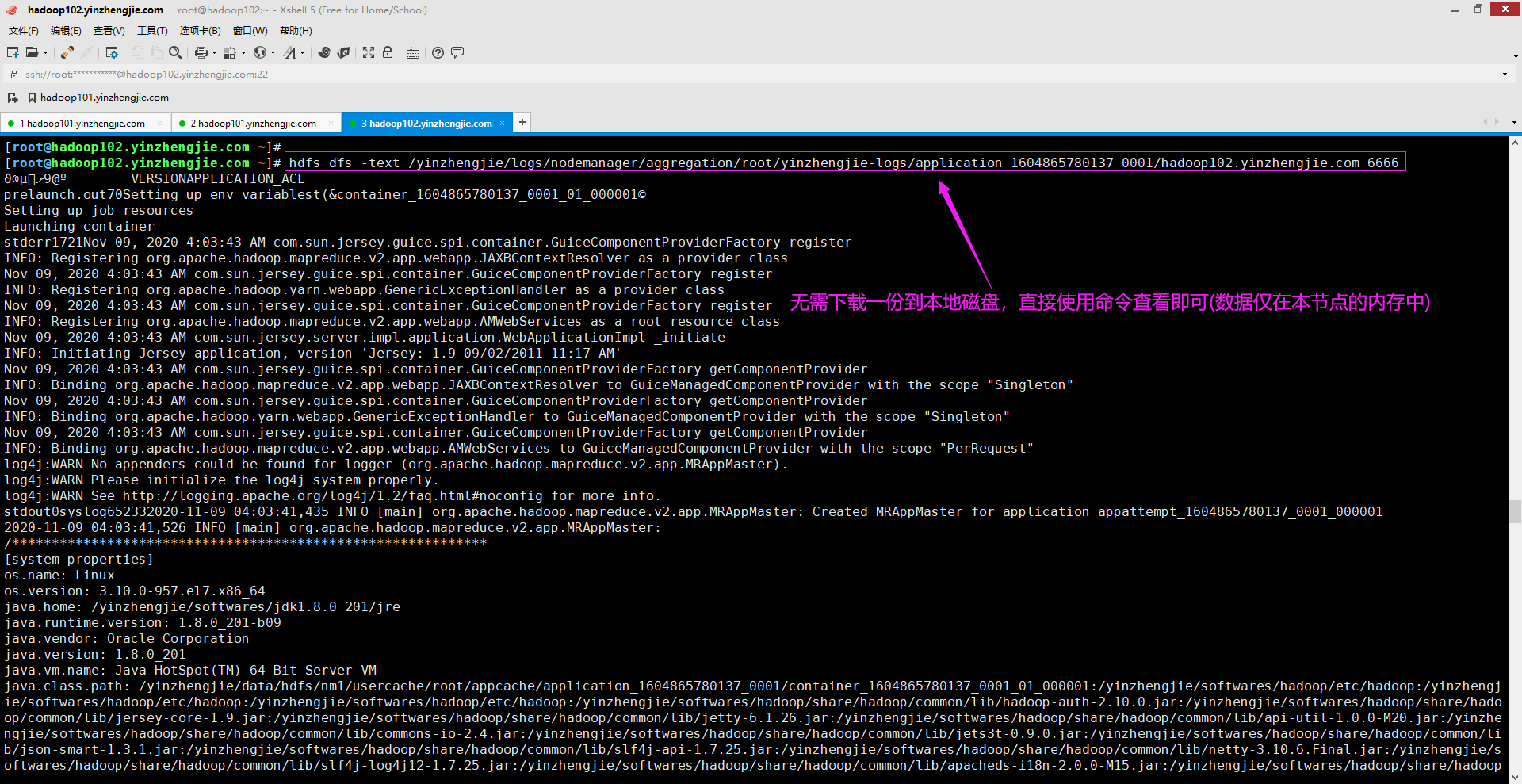
3>.直接在HDFS集群上查看数据无需下载到本地
以下是某个作业的特定节点上典型日志聚合文件示例。
五.通过多种方式查看应用程序日志
1>.使用yarn logs命令获取应用日志案例


[root@hadoop102.yinzhengjie.com ~]# hdfs dfs -ls /yinzhengjie/logs/nodemanager/aggregation/root/yinzhengjie-logs Found 20 items drwxrwx--- - root root 0 2020-11-09 04:04 /yinzhengjie/logs/nodemanager/aggregation/root/yinzhengjie-logs/application_1604865780137_0001 drwxrwx--- - root root 0 2020-11-09 04:04 /yinzhengjie/logs/nodemanager/aggregation/root/yinzhengjie-logs/application_1604865780137_0002 drwxrwx--- - root root 0 2020-11-09 04:04 /yinzhengjie/logs/nodemanager/aggregation/root/yinzhengjie-logs/application_1604865780137_0003 drwxrwx--- - root root 0 2020-11-09 04:05 /yinzhengjie/logs/nodemanager/aggregation/root/yinzhengjie-logs/application_1604865780137_0004 drwxrwx--- - root root 0 2020-11-09 04:05 /yinzhengjie/logs/nodemanager/aggregation/root/yinzhengjie-logs/application_1604865780137_0005 drwxrwx--- - root root 0 2020-11-09 04:05 /yinzhengjie/logs/nodemanager/aggregation/root/yinzhengjie-logs/application_1604865780137_0006 drwxrwx--- - root root 0 2020-11-09 04:06 /yinzhengjie/logs/nodemanager/aggregation/root/yinzhengjie-logs/application_1604865780137_0007 drwxrwx--- - root root 0 2020-11-09 04:06 /yinzhengjie/logs/nodemanager/aggregation/root/yinzhengjie-logs/application_1604865780137_0008 drwxrwx--- - root root 0 2020-11-09 04:06 /yinzhengjie/logs/nodemanager/aggregation/root/yinzhengjie-logs/application_1604865780137_0009 drwxrwx--- - root root 0 2020-11-09 04:07 /yinzhengjie/logs/nodemanager/aggregation/root/yinzhengjie-logs/application_1604865780137_0010 drwxrwx--- - root root 0 2020-11-09 05:44 /yinzhengjie/logs/nodemanager/aggregation/root/yinzhengjie-logs/application_1604871808583_0001 drwxrwx--- - root root 0 2020-11-09 05:44 /yinzhengjie/logs/nodemanager/aggregation/root/yinzhengjie-logs/application_1604871808583_0002 drwxrwx--- - root root 0 2020-11-09 05:45 /yinzhengjie/logs/nodemanager/aggregation/root/yinzhengjie-logs/application_1604871808583_0003 drwxrwx--- - root root 0 2020-11-09 05:45 /yinzhengjie/logs/nodemanager/aggregation/root/yinzhengjie-logs/application_1604871808583_0004 drwxrwx--- - root root 0 2020-11-09 05:45 /yinzhengjie/logs/nodemanager/aggregation/root/yinzhengjie-logs/application_1604871808583_0005 drwxrwx--- - root root 0 2020-11-09 05:46 /yinzhengjie/logs/nodemanager/aggregation/root/yinzhengjie-logs/application_1604871808583_0006 drwxrwx--- - root root 0 2020-11-09 05:46 /yinzhengjie/logs/nodemanager/aggregation/root/yinzhengjie-logs/application_1604871808583_0007 drwxrwx--- - root root 0 2020-11-09 05:46 /yinzhengjie/logs/nodemanager/aggregation/root/yinzhengjie-logs/application_1604871808583_0008 drwxrwx--- - root root 0 2020-11-09 05:47 /yinzhengjie/logs/nodemanager/aggregation/root/yinzhengjie-logs/application_1604871808583_0009 drwxrwx--- - root root 0 2020-11-09 05:47 /yinzhengjie/logs/nodemanager/aggregation/root/yinzhengjie-logs/application_1604871808583_0010 [root@hadoop102.yinzhengjie.com ~]# [root@hadoop102.yinzhengjie.com ~]# [root@hadoop102.yinzhengjie.com ~]# ll total 0 [root@hadoop102.yinzhengjie.com ~]# [root@hadoop102.yinzhengjie.com ~]# yarn logs -applicationId application_1604865780137_0010 > application_1604865780137_0010.log 20/11/09 06:11:16 INFO client.RMProxy: Connecting to ResourceManager at hadoop101.yinzhengjie.com/172.200.6.101:8032 Unable to get ApplicationState. Attempting to fetch logs directly from the filesystem. [root@hadoop102.yinzhengjie.com ~]# [root@hadoop102.yinzhengjie.com ~]# ll total 72 -rw-r--r-- 1 root root 70550 Nov 9 06:11 application_1604865780137_0010.log [root@hadoop102.yinzhengjie.com ~]# [root@hadoop102.yinzhengjie.com ~]#

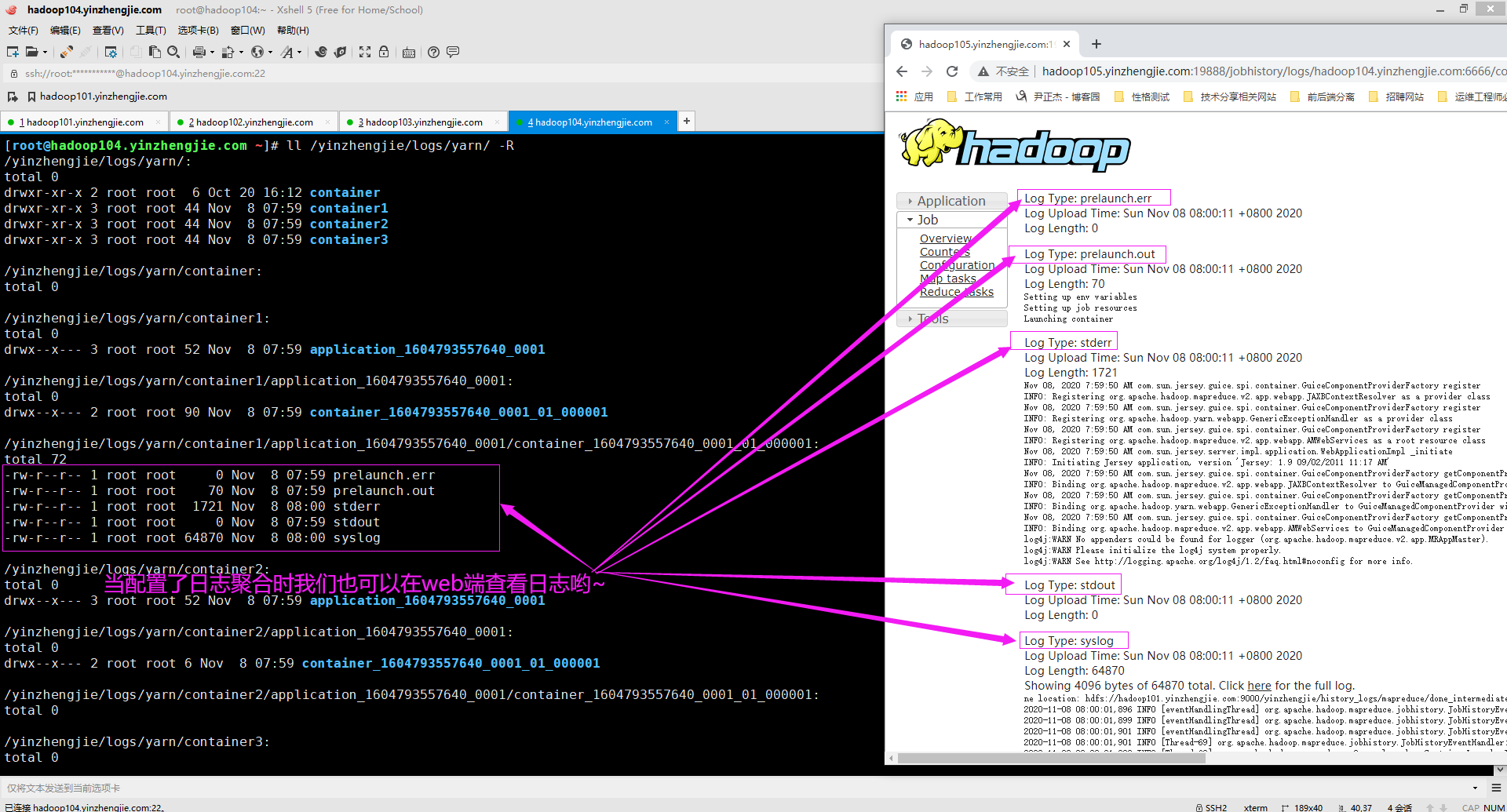
2>.作业完成后,在JobHistoryServer UI查看
如下图所示,当作业运行完成后,我们可以登录到节点上去通过命令行查看应用程序日志信息,也可以通过JoubHistory的Web UI查看日志信息(比如:http://hadoop105.yinzhengjie.com:19888/jobhistory)。
温馨提示:
通常情况下,我们只需要访问ResourceManager Web UI,找到对应的应用程序,而后根据相应的链接就可以访问应用程序的日志哟~
3>.通过NameNode的WebUI查看应用程序日志
关于命令行如何查看HDFS的应用程序日志,包括文件下载之类的,我已经在之前的笔记分享过,这里就不多做赘述啦~ 博主推荐阅读: https://www.cnblogs.com/yinzhengjie2020/p/12459595.html