分布式结构化存储系统-HBase应用案例
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
为了让读者更进一步了解HBase在实际生成环境中的应用方法,在董西成的书里介绍两个经典的HBase实际应用案例,分别是社交关系数据存储和时间序列数据库OpenTSDB。我这里手抄记录一下。
一.社交关系数据存储
互联网领域很大一类应用是社交关系数据,国内的新浪微博和微信,国外的Twitter和Facebook等,均是典型的代表。社交关系数据主要维护了Follower-folowed用户关系,即用户关注和被关注信息,目前有专门的图数据库非常适合存储这些数据,但通过介绍HBase的方案,可以帮助读者更深入理解HBase数据建模方法和应用技巧。
对于社交关系数据的存储,通常有以下几个功能需求:
(1)读数据要求
1)查看用户A关注来哪些用户;
2)查看哪些用户关注了用户A;
3)查看用户A是否关注了用户B;
(2)写数据要求
1)用户A增加了一个新的关注者;
2)用户A取消了对用户B的关注;
为了实现上述功能,对照HBase的数据模型,很容易向导如下图所示的数据模型(我们暂时称为模型A)
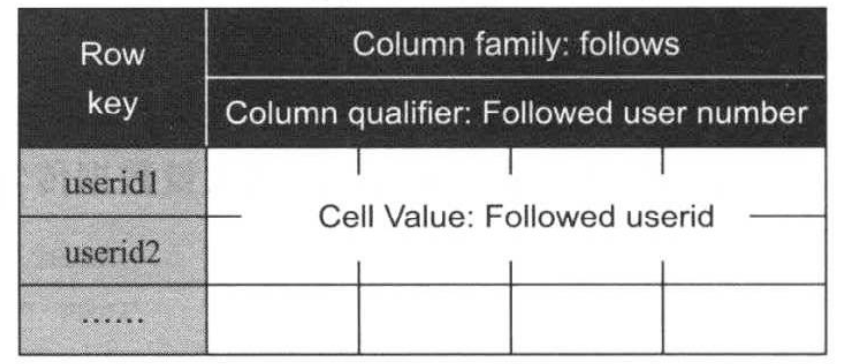
在该数据模型中,rowkey被设置为userid以方便查找和定位,column family为follows,其内部的每一列保存了一个关注着信息,如下图所示:
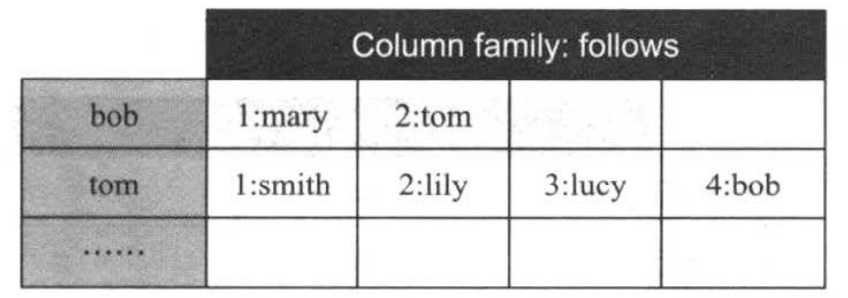
模型A能够很好地解决读数据要求中的第一条和第三条,但第二条非常低效,需要遍历整张表查找哪些用户关注了某个特定哟哦那个户,另外,为特定用户增加一个新的关注者也非常困难;难以高效地确定应为新关注者赋予什么编号,一种解决思路是新增一例counter,记录最小可用编号值,但这将引入事务问题:counter值的更新无法保证原子性,用户需在应用层解决这一问题。
为了解决模型A存在的问题,我们该用如下图所示的模型B,与模型A不同的是,用户ID被用作列名,每列对应的cell值为任意数值。该模型能够很高解决大多数需求,唯独第二个读要求:“查看哪些用户关注了用户A”,这是由于HBase仅提供了基于rowkey的索引,因此,为了查找哪些用户关注了用户A,需要遍历整个表。

为了进一步优化模型B,可考虑以下两种方案: (1)构造第二张表,保存逆序关系,即用户X以及关注X的用户列表。 (2)在同一张表中保存用户X关注的用户列表以及关注X的用户列表。
以方案2为例,可以得到如下图所示的模型C。

在该模型中,column family名称被改为“f”以减少数据存储空间和网络传输数据量,同时将前面的“宽表”改为“窄表”,即表中的rowkey由用户ID被关注用户ID组合而成,column family中只有一列。
如下图所示,给出了一个模型C的实例。

为了划整化rowkey,避免rowkey长度导致每次请求返回的数据量不一(造成调试困难),可将用户ID映射成等长的hash值,组装成rowkey,比如“md5(userID1)+md5(userID2)”。
二.时间序列数据库OpenTSDB
OpenTSDB是基于HBase构建的分布式,可伸缩的时间序列数据库(Time Series Database),它是一个典型应用场景是实时采集,存储和展示各类监控指标(metric)信息(比如集群中的网络设备,操作系统,应用程序的监控信息),具有扩展性好,能够永久存储所有监控指标等优点。
1>.OpenTSDB数据模型
为了规范化指标数据,OpenTSDB对指标进行了规范化,在OpenTSDB中,一条指标数据由以下几个属性构成:
(1)metric
metric名称,比如CPU利用率。
(2)tags
用来描述metric的标签,由tagk和tagv组成,即tagk=tagv。
(3)value
metric实际的值。
(4)timestamp
时间戳,描述value对应的时间点。
在实际应用中,一条MySQL数据库相关的metric数据格式如下(表示某个时刻作用在某个表上的慢查询的数目):
metric : mysql.slow_queries
timestamp : 1454557429
value : 100
tags : schema=userdb
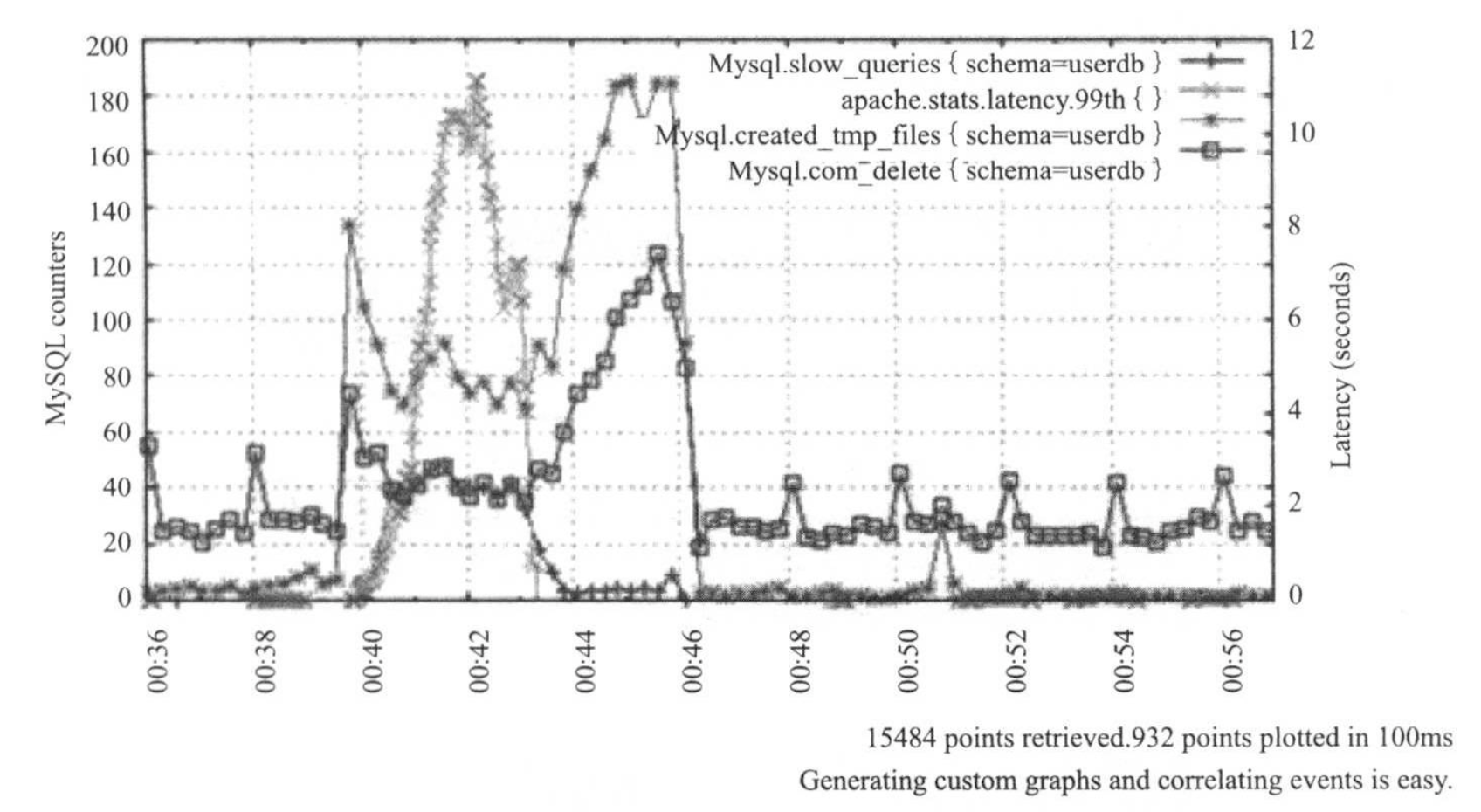
监控系统最主要读需求是,将一段时间内的metric数据取出,并通过曲线图形化展示出来,如下图所示:
2>.OpenTSDB存储方式
OpenTSDB采用HBase存储metric数据,如果仅考虑metric,timestamp和value三个属性,一种可行的存储方案(记为方案A)如下:把HBase当作一个简单的key/value存储系统,其中key是由timestamp和metric组合而成,如下图所示。

方案A能够满足读写需求,通过一个简单的HBase scan操作即获取某一时间段内的特定metric数值,但由于该方案直接以字符串的方式保存metric名称,会造成大量存储空间的浪费。为了对其进行优化,可对metric进行数值编码,直接将编码后的数字保存到rowkey中,进而产生如下图所示的方案B。
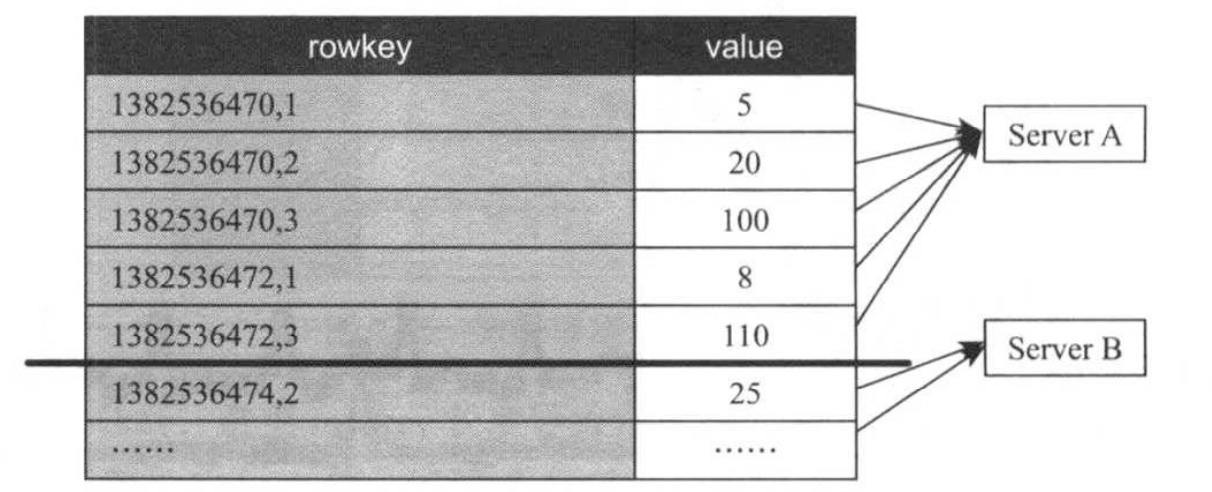
在实际应用中,方案B仍存在性能问题:HBase自动按照rowkey排序,这使得最近的metric数据被紧挨着存储在同一个RegionServer上,考虑到数据局部性特点(最新的数据访问频率最高),这将导致某个RegionServer读请求负载过重。为了解决该问题,一种可行的优化方式是将rowkey中timestamp和metric两个字段位置互换一下,进而出现了如下所所示的方案C。
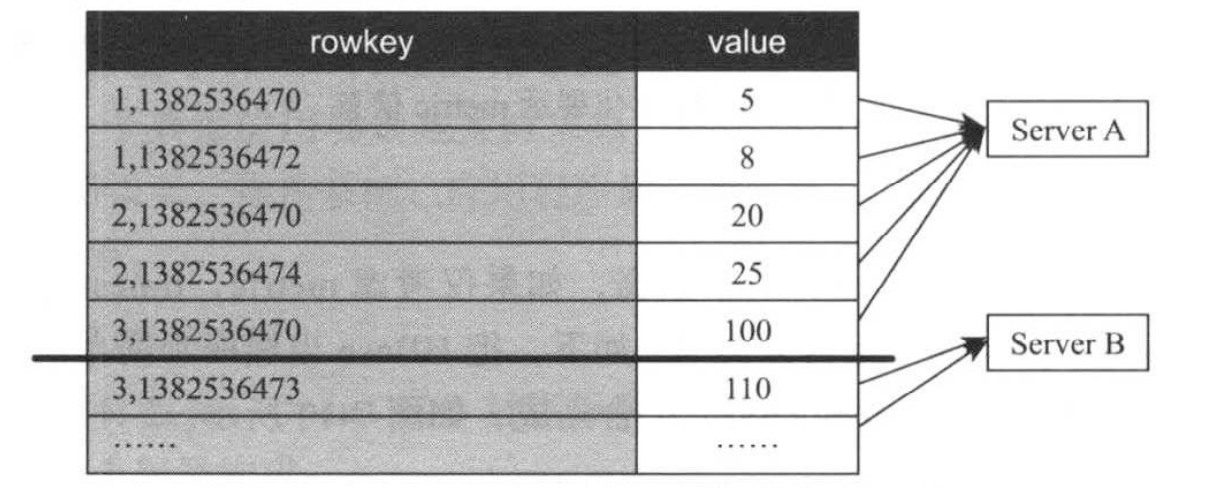
方案C能够很好均衡各个RegionServer的读负载,可提高读性能,但每次读取一个时间区间的metric数值时,需要扫描多行数据,这明显要慢于只读一行或者若干行的情况,为了进一步提高性能,可将多行数据压缩存储到一行中(极为方案D),如下图所示。
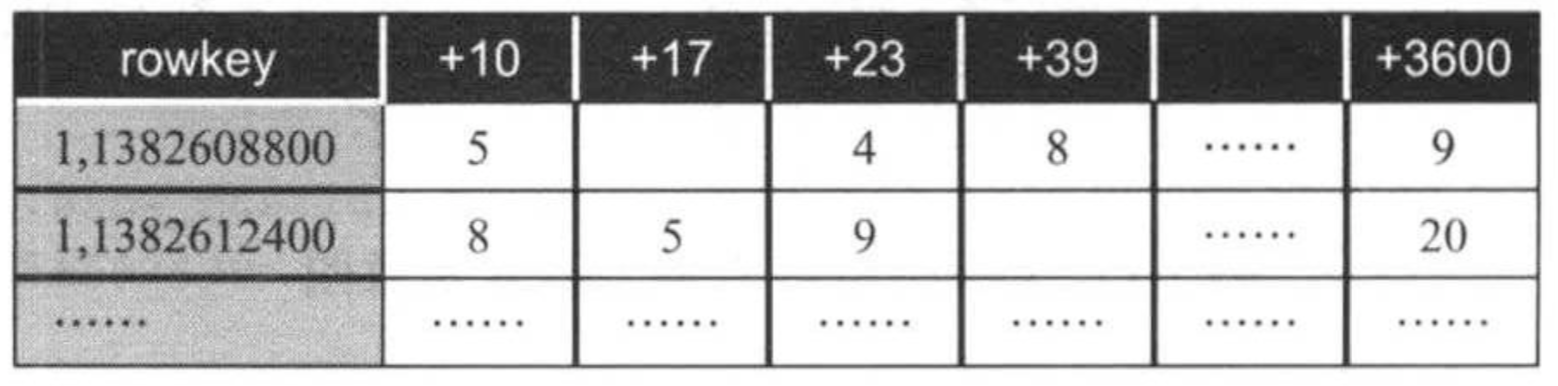
在方案D中,每行数据保存了特定metric在一小时内的数值,其中rowkey中的timestamp为整点时间戳,而各列名则为相对于该整点时刻的偏移量,通过这种方式,在节省存储空间(时间偏移量占用空间要小于时间戳)的同时,可加快数据读性能(主要读请求为区间扫描)。在方案D基础上,将tags编码后,保存到rowkey尾部,则形成了OpenTSDB完整的数据存储方式。
3>.OpenTSDB基本架构

OpenSTDB架构如上图所示,各个模块功能如下:
(1)Server
OpenTSDB的代理,通过Collector收集数据,推送数据。
(2)TSD
是对外通信的无状态服务器,对数据进行汇总和存取。
(3)HBase
TSD收到数据后,通过异步客户端将数据写入到HBase。