正则表达式与字符处理
正则表达式
正则表达式和通配符的区别是,正则表达式的作用是在文件中搜索符合条件的字符串(常用命令有grep、awk、sed),而通配符用来匹配符合条件的文件名(ls、find、cp这些命令只能用通配符,不能用正则表达式)。且通配符是完全匹配,而正则表达式是包含匹配,如当用grep命令查找时,只要包含该字符串的行就会显示。
正则表达式:
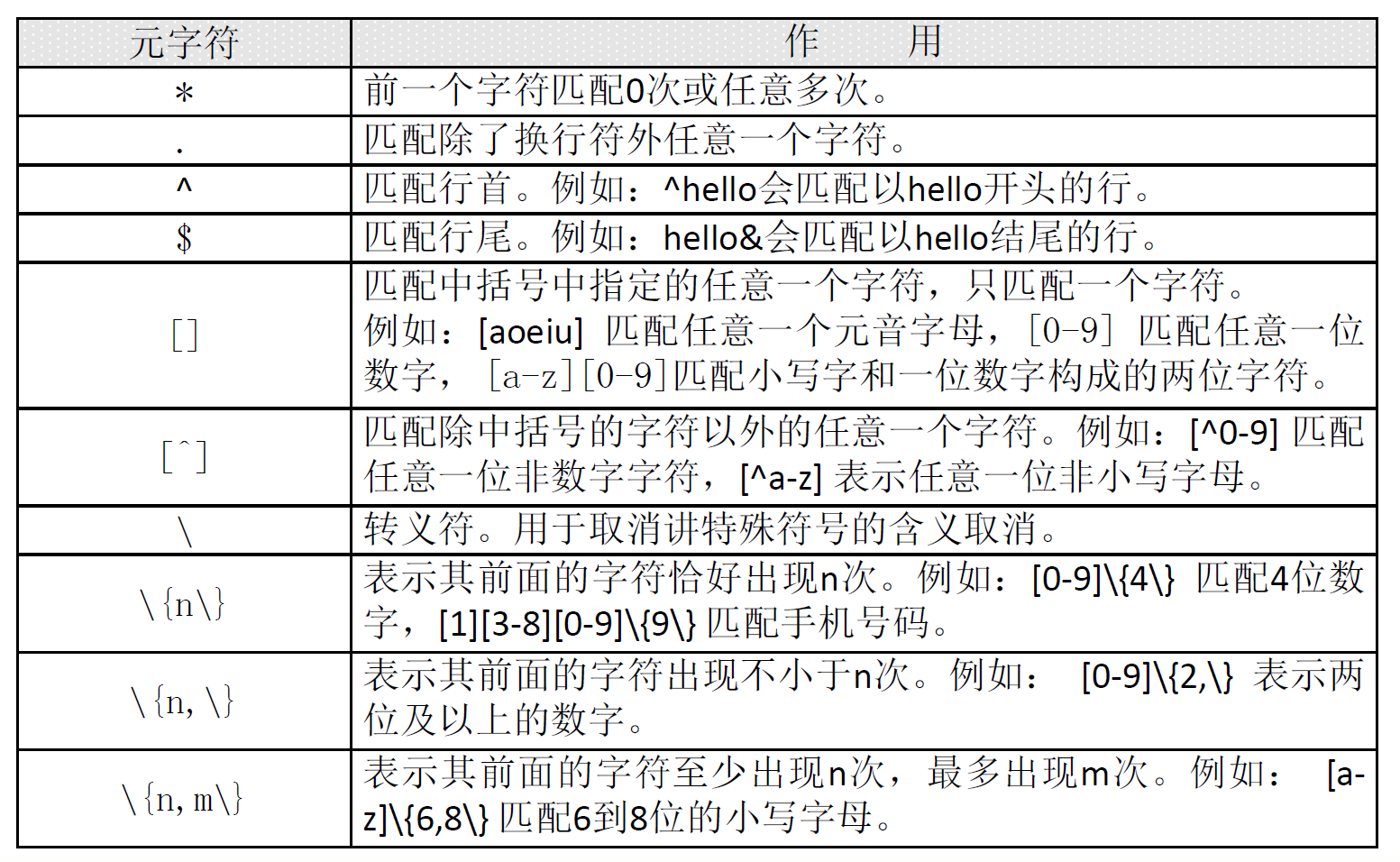
通配符:

*表示前一个字符匹配0次或任意多次(和通配符中的*不同),故grep "a*" test_rule.txt表示匹配所有内容,包括空白行,而grep "aa*" test_rule.txt表示匹配至少包含有一个a的行。
.表示匹配除了换行符外的任意一个字符,grep "s.*d" test_rule.txt表示匹配在s和d字母之间有任意字符的行,grep ".*" test_rule.txt 表示匹配所有内容。
和$表示能匹配行首和行尾,M表示行首是M,d$表示行尾是d,而grep -n "^$" test_rule.txt 表示会匹配空白行。
常见的匹配:
grep "^[^a-z]" test_rule.txt 表示匹配不用小写字母开头的行
grep "^[^a-zA-Z]" test_rule.txt 表示匹配不用字母开头的行
grep ".$" test_rule.txt 表示匹配使用“.”结尾的行
字符截取命令
截取命令有grep、cut、awk和sed四个。
cut命令
grep是将符合条件的行提取出来,而cut是提取列。
使用的基本格式:cut [选项] 文件名-f后跟列号代表提取第几列,-d后跟分隔符表示设置提取时的分隔符。对于文件(每行中的分隔符是tab)
ID Name gender Mark
1 Liming M 86
2 Sc M 90
3 Gao M 83
执行cut -f 2,3 student.txt结果就是提取第2、3列(中间分隔符还保留):
Name gender
Liming M
Sc M
Gao M
cut命令会一行一行进行切分,取返回结果中每行第12个字符以后的所有字符串:export | cut -c 12
cut命令常和grep命令配合使用,如对/etc/passwd,该文件中每一行代表一个用户,如果想提取这个文件中的普通用户名,应该执行:
cat /etc/passwd | grep /bin/bash | grep -v root | cut -d ":" -f 1
就会将普通用户名提取出来。这里第一部分代表用cat命令查看该文件,然后选取行内带/bin/bash的行(相当于除掉系统用户),然后去除root用户(-v代表过滤掉某个结果),最后用cut命令提取第一列,分割符是冒号(不设置的话默认分隔符是制表符),中间用管道符连接。
但如果要读取的文件分隔符是多个空格,则cut无法正确提取内容,cut的分隔符只支持一个字符,awk命令可以解决这个问题。
printf命令
printf的基本用法是printf '输出格式' 输出内容
输出格式主要有三种,%ns表示输出字符串,n代表输出字符的个数;%ni代表输出整数,n指输出数字的个数;%m.nf表示输出小数,m指输出数字的个数,n值其中小数的位数。
输出格式中有一些特殊字符,常用的有 换行, 回车, 制表符。
printf %s 1 2 3 4 5 6会输出123456
printf %s %s %s 1 2 3 4 5 6会输出%s%s123456
必须将输出格式用单引号括起来:printf '%s %s %s' 1 2 3 4 5 6会输出1 2 34 5 6
printf '%s %s %s
' 1 2 3 4 5 6会输出1 2 3换行4 5 6
也就是说当后面内容多于输出格式时,会反复使用输出格式。
想要按照一定的格式输出文件时,要这样处理:printf '%s' $(cat student.txt),注意这里不能用管道符,这样会将文件所有内容在一行输出,如果想按照文件格式输出必须按照文件的格式来写输出命令:printf '%s %s %s %s %s %s
' $(cat student.txt)这样就能完整的输出文件了student.txt:
ID Name PHP Linux MySQL Average
1 Liming 82 95 86 87.66
2 Sc 74 96 87 85.66
3 Gao 99 83 93 91.66
printf '%10s %5i %8.2f
' $(cat file),输出格式依次是长度为10的字符串、长度为5的数字、长度为8其中可以留两位小数点。
print和printf的区别在于print命令会自动加换行,linux中默认没有print命令,但在awk中可以使用print命令。
awk命令
awk使用格式:awk ‘条件1{动作1} 条件2{动作2}…’ 文件名条件通常是关系表达式,当使用awk处理文件时,文件是按行读取的,然后判断条件,确定是否执行动作。
整个awk的处理流程是:
1、读取第一行,然后初始化$0/$1/$2...。
2、根据条件值判断是否进行后面的动作。
3、执行所有的条件和动作,如果后面还有后续的行则重复上述步骤,直到所有行都读完。
对student.txt来说,awk '{printf $2 " " $6 "
"}' student.txt能将第2列和第6列提取出来,这里的printf不是系统命令,可以用$n代表第几列,$0代表整行,printf中的特殊字符要用双引号括起来,因为外层已经使用了单引号,所以这里用双引号,特殊字符控制的都是输出格式。
awk默认的字段分隔符是空格或tab,所以对于用多个空格作为分隔符的文件或输出,awk也能处理,如df -h | awk '{print $1 " " $3}'这里用的是print命令,和printf手动加换行符效果相同。
如果想提取df -h中的百分数,如下图:

此时应该执行df -h | grep root | awk '{printf $5}' | cut -d "%" -f 1这条语句就是用grep命令提取对应行,然后用awk来提取对应列,最后用cut命令来以%为分隔符切割,相当于去掉%,最后得到数字。
BEGIN是一种条件,表示读取前优先处理。awk 'BEGIN{printf "This is a transcript
" } {printf $2 " " $6 "
"}' student.txt此时打印内容第一行就是This is a transcript,第二行开始读取文件。
设置分隔符awk 'BEGIN {FS=":"} {printf $1 " " $3 "
"}'FS就代表设置分隔符为冒号,这里前面必须加BEGIN ,如果不加那么文件第一行会原封不动打印,因为在读取第一个大括号时就已经读取第一行了,如果不加BEGIN程序会直接读取第二行然后开始处理。
END也是一种条件,表示最后执行。awk 'END{printf "The End
" } {printf $2 " " $6 "
"}' student.txt此时就会最后打印一行The End。
awk的强大之处在于可以插入逻辑表达式,cat student.txt | grep -v Name | awk '$6 >= 87 {printf $2 "
" }',同样是对student文件,如果想输出平均分大于87分的Name就可以执行这条命令,首先读取该文件,然后除掉第一行,如果第六列的元素大于等于87就打印第二列。
awk有几个内建变量:NF(每一行拥有的字段总数)、NR(目前处理的是第几行的数据)、FS(分隔符默认为空格),这些变量都可以直接放在大括号里打印出来,或者放在括号外作为条件判断都可以,不需要加$。
sed命令
sed命令是一种轻量级流编辑器,主要是用来将数据选取、替换、删除和新增。vim也可以修改文件,但是vim难以修改命令输出内容,只能将输出内容写入文件然后修改,而sed在这方面优于vim。
sed命令的执行格式是sed [选项] ‘[动作]’ 文件名
提取文件第2行并输出:sed -n '2p' student.txt,动作中p代表输出指定的行,而-n代表仅输出sed处理过的行,如果不加-n那么会输出全部文件内容,第二行会输出两次。sed不仅可以用在文件中,还能用在命令输出的内容中:df -h | sed -n '2p'
删除第2行到第4行的数据(相当于输出其他行,它不会修改文件本身):sed '2,4d' student.txt
在第二行后插入一行(不修改文件本身):sed '2a hello' student.txt,a代表某行后插入。
在第二行前插入两行(不修改文件本身):sed '2i hello world' student.txt,反斜杠代表输入第二行,插入时除了最后一行,当想插入多行时必须在行末处加反斜杠,i代表某行前插入。
将第二行替换(不修改文件本身):sed '2c No such person‘ student.txt
数据替换可以精确到字符串,格式是sed ‘s/旧字串/新字串/g’ 文件名
把第三行中的74换成99:sed '3s/74/99/g' student.txt
同时把“Liming”和“Gao”替换为空:sed -e 's/Liming//g ; s/Gao//g' student.txt,注意当有多个动作时用分号隔开,-e代表允许多条编辑,当s前没有数字时代表针对所有行。
总结:sed命令的常用选项有三个,-n、-e和-i‘;常用动作有6种,a、c、i、d、p、s。
字符处理命令
1、排序命令sort,使用方法:sort [选项] 文件名选项有几种:
-f: 忽略大小写
-n: 以数值型进行排序,默认使用字符串型排序
-r: 反向排序
-t: 指定分隔符,默认是分隔符是制表符
-k n[,m]: 按照指定的字段范围排序。从第n字段开始, m字段结束(默认到行尾)
排序用户信息文件:sort /etc/passwd此时会输出按照文件每行首字母排序的结果:

如果想按照每行第三个字段排序,必须先指定冒号为分隔符:sort -t ":" -k 3,3 /etc/passwd
-k 3,3的意思是从第三个字段开始到第三个字段结束,也就是按照第3个字段排序。但是排序结果会把10排在3前,这是因为默认只识别第一个字符,如果想按数字排序应该加上-n选项:
sort -n -t ":" -k 3,3 /etc/passwd。
2、去重命令uniq:经常结合排序使用,仅取出账号栏,然后排序后去重:
last | cut -d ' ' -f 1 | sort | uniq
3、统计命令wc:wc [选项] 文件名。选项有以下几种:-l: 只统计行数、-w: 只统计单词数、-m: 只统计字符数。如果不加选项那么上述三种都会输出。
字符转换命令
1、tr命令可以用来删除一段讯息中的文字或进行替换
将last输出信息中的所有小写字母换成大写的:last | tr '[a-z]' '[A-Z]'
将输出信息中的冒号全部删除:cat /etc/passwd | tr -d ':'
2、col命令可以将tab转成对等的空格键,命令是col -x
3、join命令用来通过两个文件数据相同的部分,来把两个文件的数据整合到一起,如/etc/passwd和/etc/shadow两个文件每行的第一个字段都是相同的账号名:

此时就可以用join方法:
join -t ':' /etc/passwd /etc/shadow
这样整合后,两个文件的数据都会整合到一起,查看上面输出的内容:

可以发现最后每一行输出的内容就是文件1+文件2没有连接字段的那部分。join的字段也可以不采用首个字段。
join常常在sort之后,防止出现对应行不匹配的现象。
4、paste命令用来将两行粘在一起,中间用tab键分开:paste 文件1 文件2,如果加-d后面跟分隔符的话就可以重新设置分隔符。
5、expand和unexpand分别是将tab转成空格,和把空格转成tab,expand后跟文件名会自动将文件内的tab转成8个空格,也可以用-t加数字来自定义转换数字。
6、分区命令split,它可以将一个大文件分成多个小文件,以便于复制。
切割成300k一个的小文件:split -b 300k 文件名,此时原文件会被删除,假设原文件名为1,那么结果就会多出1aa、1ab、1ac文件,将这三个文件合并:cat 1* >> 1,这样就可以复原。
将ls输出信息每十行记录一个文件:ls -al / | split -l 10 - lsroot,这里新生成的文件名开头就是lsroot,-的意思是输入流,但是为空所以就用-来表示。
7、xargs命令可以创造标准输入,令不支持用管道符的命令能够接受其他命令的返回结果并执行。