底层:链表和字典
链表
redis中的list类型有时会采用链表的形式存储。
链表的每一个节点定义如下:
typedef struct listNode{
//前置节点
struct listNode *prev;
//后置节点
struct listNode *next;
//节点的值
void *value;
} listNode;
链表的整体定义如下:
typedef struct list{
//表头节点
listNode *head;
//表尾节点
listNode *tail;
//链表所包含的节点数量
unsigned long len;
//三个函数:分别是节点值复制函数、节点值释放函数、节点值对比函数
void *(*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr,void *key);
} list;
一个链表例子如下:
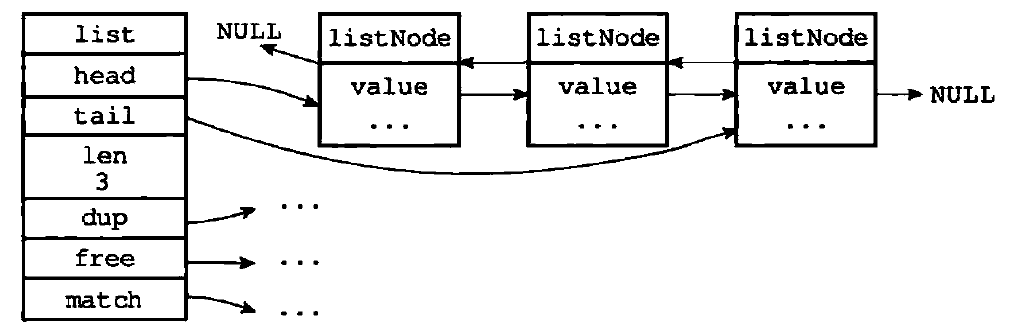
redis中的链表是一个双端无环链表,带有长度计数器,用void类型来保存节点值使链表可以保存多种不同类型的值。
字典
在redis中,整个数据库就是一个巨大的字典,所有的数据都有键来对应。hash类型有时也会采取字典来表示,字典中每一个键都是独一无二的。
定义
哈希表节点定义如下:
typedef struct dictEntry{
//键值对中的键
void *key;
//键值对中的值,可以是一个指针,或者uint64_t整数,或int64_t整数
union{
void *val;
uint64_t u64;
int64_t s64;
} v;
//指向下一个哈希表节点的指针,它的存在是为了应对哈希冲突的
struct dicEntry *next;
} dictEntry;
哈希表定义:
typedef struct dictht{
//哈希表节点数组
dicEntry **table;
//哈希表的大小
unsigned long size;
//哈希表大小掩码,用于计算索引值,总是等于size-1
unsigned long sizemask;
//哈希表已有的节点数量
unsigned long used;
} dictht;
下图表示一个两个相同键连接在一起的哈希表:
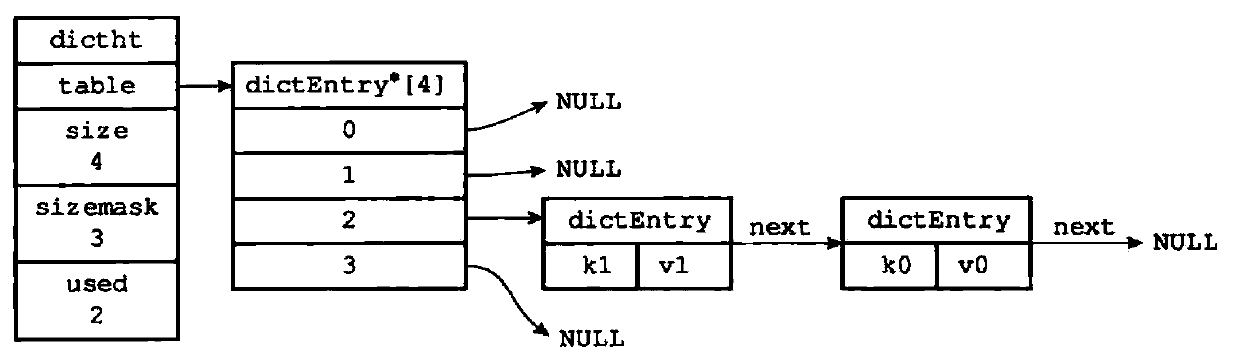
字典定义:
typedef struct dict{
//这两个字段都是为了多态设置的,对应处理不同类型的函数和参数
dictType *type;
void *privdata;
//两个哈希表,一个是正在使用的,一个是为了rehash而用的
dicht ht[2];
//rehash索引,不进行rehash时值为-1
int rehashidx;
}
下图表示一个没有进行rehash的字典:
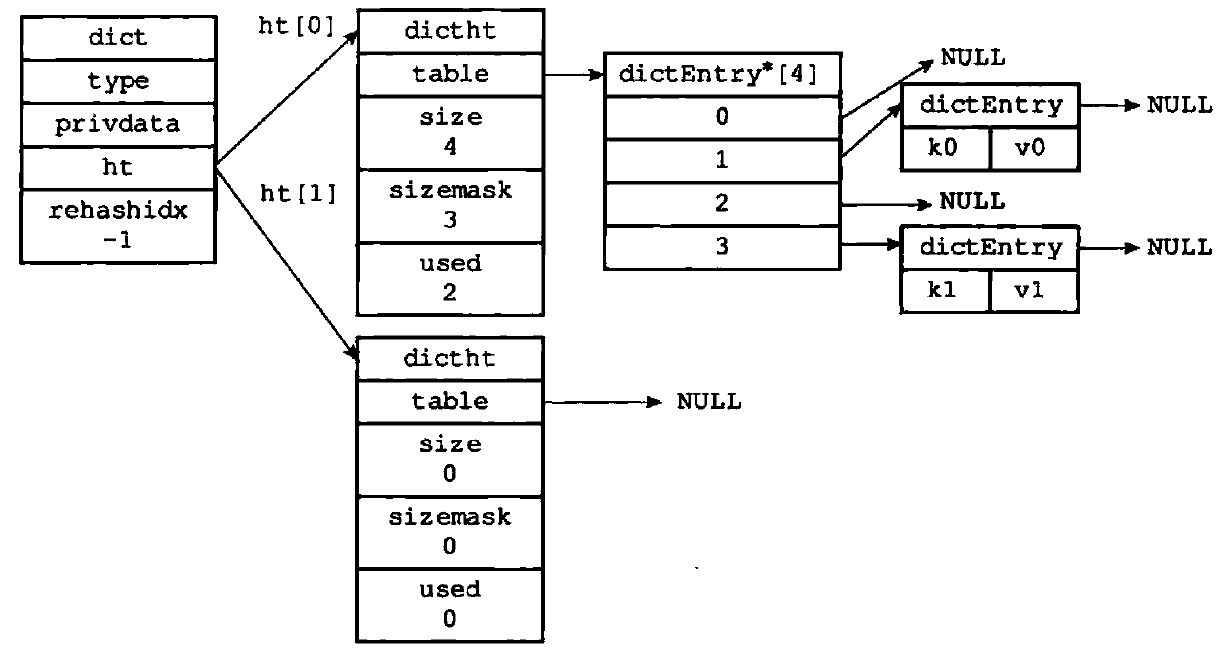
哈希算法
当一个新的键值要添加到字典中时,需要首先调用type中的函数来计算hash值:
hash = dict->type->hashFunction(key);
计算hash值的算法是MurmurHash2算法,它的特点在于即使输入有规律的键也会给出很好的随机分布性,且计算速度非常快。
然后hash值与掩码(size-1)相与,得到索引值:
index = hash & dict->ht[x].sizemask;
如果有两个或以上的键被分配到了哈希表数组的同一个索引上就会触发hash冲突,redis使用链地址法来解决hash冲突,将多个哈希节点连接在哈希节点数组的一个位置,为了速度考虑,redis总是将新节点添加到链表的表头位置,旧节点连接在后面。
rehash算法
随着操作的不断执行,哈希表的负载因子可能会很高或者很低,为了保证它维持在合理的范围内,需要对哈希表的大小进行相应的扩展和收缩。这些扩展和收缩都可以通过执行rehash来完成,执行rehash的步骤如下:
1、为字典的ht[1]哈希表分配空间,如果是扩展操作,那么新哈希表大小为第一个大于等于ht[0].used*2(旧哈希表已经使用的部分乘2)的2的n次幂;如果是收缩操作,那么新哈希表大小为第一个大于等于ht[0].used的2的n次幂。(如原哈希表大小为4,现在要扩大,则扩大到8,因为8是大于等于4*2的第一个2的n次幂)
2、将保存在ht[0]中的所有键值对都重新计算hash值和索引值,放入ht[1]中。
3、释放ht[0]的空间,将ht[1]设置为ht[0],并在ht[1]处创建一个空白哈希表,为下一次rehash做准备。
rehash的时机
当下列条件中的任何一个被满足时,程序会自动开始执行扩展:
1、服务器目前没有执行bgsave命令或bgrewriteaof命令,且哈希表的负载因子大于等于1.
2、服务器目前正在执行bgsave命令或者bgrewriteaof命令,且哈希表的负载因子大于等于5.
当执行bgsave命令或者bgrewriteaof命令时,redis需要创建当前服务器进程的子进程,尽可能避免在这个时候进行哈希表扩展操作。
当哈希表的负载因子小于0.1时,程序就会自动对哈希表执行收缩操作。
渐进式rehash
进行rehash时,从ht[0]中的数据移动到ht[1]中这个过程不是一次性完成的,而是分多次,渐进式完成的。
当哈希表中的数据量很大的时候,一次性进行rehash可能会造成服务器在一段时间内停止服务,所以redis采用渐进式rehash。
渐进式rehash的步骤如下:
1、rehash未开始时,字典的rehashidx字段值为-1,开始rehash后,该值被设置为0.
2、每次对字典执行增删改查操作时,程序除了执行指定的操作外,还会将ht[0][rehashidx]位置的所有键值对都转移到ht[1]中,转移完成后rehashidx++。
3、随着操作的不断执行,最终所有的键值对都rehash完成,此时将rehashidx设置为-1,rehash结束。
由此可见,渐进式rehash把一次性的操作分散到每次增删改查,避免了卡顿。
在渐进式rehash期间,删除和更新的操作都同时在两个哈希表中进行,如果是查找操作会先在旧字典ht[0]中查找,找不到再去ht[1]中查找。如果是新增数据则会直接新增在ht[1]中。