我们今天大致的聊一下,从socket一致引伸到Django,具体的知识点这一章里不细讲,只是串一下是怎么回事的。
我们在前面学习了如何利用socket建立连接来实现数据的交互,那么我们最常用的Web服务,其实也是通过socket来实现数据的收发。回顾一下socket的使用,我们写一个最简单的socket服务器然后用浏览器访问一下


import socket sk=socket.socket() sk.bind(('127.0.0.1',8000)) #绑定IP和端口 sk.listen() #开始监听 while True: conn,_=sk.accept() data=conn.recv(9216) print(data) conn.send(b'HelloWorld!') conn.close() sk.close()
但是我们用浏览器访问一下这个网址发现是报错的
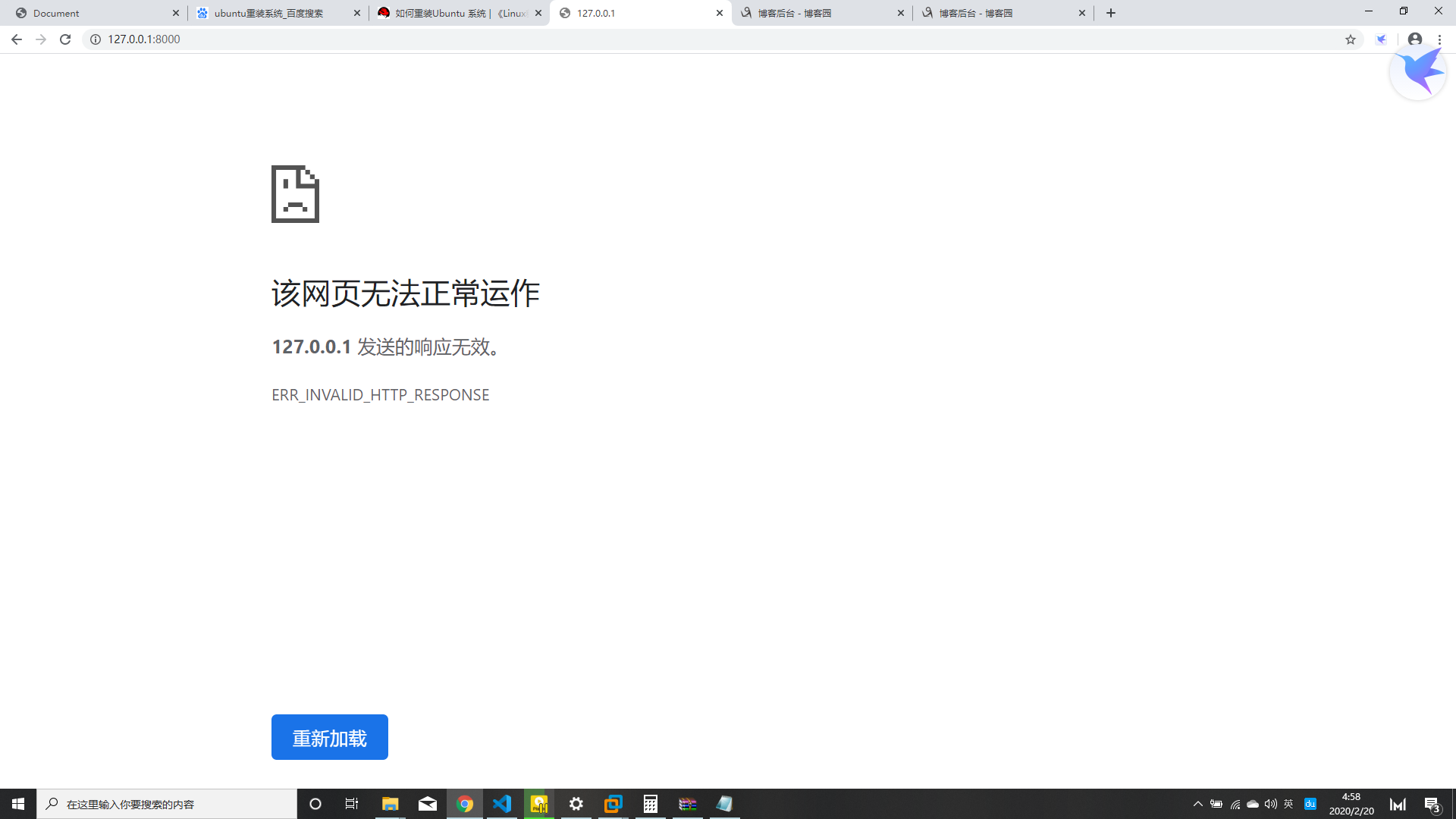
为什么呢?在以前我们写的socket的案例中,服务端和客户端都是我们自己写的,服务端能识别客户端的意图,客户端也可以识别服务端的指令。但是,浏览器是不会明白我们写的这个服务端的内容的,我们在程序中要求服务端打印浏览器发送的请求,可以看一下
b'GET / HTTP/1.1 Host: 127.0.0.1:8000 Connection: keep-alive Cache-Control: max-age=0 Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36 Sec-Fetch-Dest: document Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9 Sec-Fetch-Site: none Sec-Fetch-Mode: navigate Sec-Fetch-User: ?1 Accept-Encoding: gzip, deflate, br Accept-Language: zh-CN,zh;q=0.9 '
看看第一段( )前,指明了浏览器的请求行为和所用的协议,这就引出了http协议。
http协议的具体我们这里不讲了,但是为了后面的内容,我们要知道两点——请求和相应的格式
http请求格式

请求
请求的方法,常用的也就几种,GET,HEAD,POST,PUT,DELETE,TRACE,OPTIONS,CONNECT
一般服务器接收到请求以后也会相应的返回相应
URL
超文本传输协议(HTTP)的统一资源定位符将从因特网获取信息的五个基本元素包括在一个简单的地址中:
- 传送协议。
- 层级URL标记符号(为[//],固定不变)
- 访问资源需要的凭证信息(可省略)
- 服务器。(通常为域名,有时为IP地址)
- 端口号。(以数字方式表示,若为HTTP的默认值“:80”可省略)
- 路径。(以“/”字符区别路径中的每一个目录名称)
- 查询。(GET模式的窗体参数,以“?”字符为起点,每个参数以“&”隔开,再以“=”分开参数名称与数据,通常以UTF8的URL编码,避开字符冲突的问题)
- 片段。以“#”字符为起点
http响应格式
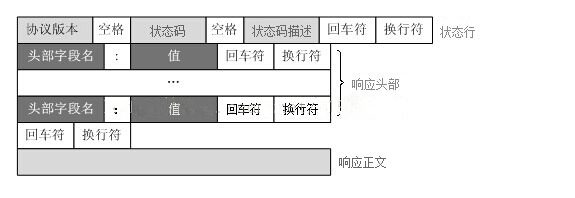
状态码
状态码就是我们在网上看到的、服务器根据请求给出的具体状态响应,状态码的第一个数字代表了当前响应的类型
- 1xx消息——请求已被服务器接收,继续处理
- 2xx成功——请求已成功被服务器接收、理解、并接受
- 3xx重定向——需要后续操作才能完成这一请求
- 4xx请求错误——请求含有词法错误或者无法被执行
- 5xx服务器错误——服务器在处理某个正确请求时发生错误
因为我们从服务端给浏览器发送的数据里没有按照http的响应的格式发送,所以浏览器获得数据以后是不会理解服务端的要求的,这时候,我们就要按照HTTP的响应格式加上
直接访问地址/端口
看看前面要求的响应格式,我们应该在发送数据前发送下面的一段字符串
conn.send(b'http/1.1 200 OK content-type: text/html; charset=utf-8 ')
那么浏览器在获得数据时候就知道下面一段字符串是通过http协议发送的,服务器响应正常,文本类型是文本或html文档,字符集是utf8,那么浏览器就会做出相应的渲染显示出来。这就是我们改进版的socket服务端
import socket sk=socket.socket() sk.bind(('127.0.0.1',8000)) sk.listen() while True: conn,_=sk.accept() data=conn.recv(1024) print(data) conn.send(b'http/1.1 200 OK content-type: text/html; charset=utf-8 ') conn.send(b'<h1>Hello World</h1>') conn.close() sk.close()
运行服务端,打开浏览器重新访问:

注意我们的代码里的字符串是html文件的格式,说明浏览器是把我们发送的响应正文按照html的格式进行渲染再心啊是的。
带路径返回的socket服务
在前面的例子中,我们已经实现了浏览器和socket的连接,但是在日常使用中是不会有直接访问一个地址加端口号的,看看请求的格式,一般的get请求都会带一个URL,那么带URL的socket又是怎么实现的呢?
正如我们前面的请求的格式里讲的,我们用/.../来表示具体的地址。
import socket sk=socket.socket() sk.bind(('127.0.0.1',8000)) sk.listen() while True: conn,_=sk.accept() data=conn.recv(9216) data = str(data,encoding='utf-8') # print(data) request = data.split(' ')[0] # print('request',request) #切割字符串,获取 url= request.split()[1] print(url) conn.send(b'http/1.1 200 OK content-type: text/html; charset=utf-8 ') if url == '/firstpage/': conn.send(b'the first page') elif url == '/secondpage/': conn.send(b'the second page') else: conn.send(b'404 Not Found') print(url) conn.close() sk.close()
我们在获取请求后对请求的head部分进行解析可以获取到URL,在进行判定后就可以返回相对应的值。

开了两个页面分别访问了两个地址,都可以正常显示。
上面这段代码是比较低级的,正常的话我们都是把相对应的功能放到一个函数中,所以上面的代码也可以简化成下面的方案:
import socket sk=socket.socket() sk.bind(('127.0.0.1',8000)) sk.listen() def resp(url): #定义函数,参数为URL在函数中可以做相应的动作 ret = 'Hello {}'.format(url) return bytes(ret,encoding='utf-8') def f404(url): ret='404 Not Found' return bytes(ret,encoding='utf-8') #定义了函数列表,注意元组第二项为函数名,可以直接作为变量使用,如果URL需要多个函数可以每个URL对应一个函数,后面的用法有些类似闭包 url_fun_list= [('/firstpage/',resp), ('/secondpage/',resp)] while True: conn,_=sk.accept() data=conn.recv(8096) data = str(data,encoding='utf-8') request = data.split(' ')[0] url= request.split()[1] #切割字符串,获取URL conn.send(b'http/1.1 200 OK content-type: text/html; charset=utf-8 ') func=f404 #先赋值404,如果没有对应URL直接报404错误 for i in url_fun_list: if i[0]==url: func=i[1] break response = func(url) conn.send(response) conn.close() sk.close()
在这个方法里,我们把函数名resp作为一个变量放在url对应的列表里,然后通过赋值给func做成了闭包的使用方式。
在获的请求里的URL以后去和列表比较,如果有则调用对应的函数,否则返回404。
返回html文件
下面就要返回html文件了,因为正常的Web服务都是通过浏览器打开对应的网页所以我们可以创建两个html文件来试一下
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>Document</title> </head> <body> <div> <p><label for=''>姓名</label><input type="text"></p> <p><label for=''>密码</label><input type="text"></p> </div> <div><button>登录</button></div> </body> </html>
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=p, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>Document</title> </head> <body> <p><h1>这里是第二页的内容</h1></p> <a href="http://www.baidu.com" target="blank">度娘,啥都知道</a> </body> </html>
在py文件的父级目录下保存上面两个html文件,然后我们把socket服务端的代码稍微修改一下
import socket
sk=socket.socket()
sk.bind(('127.0.0.1',8000))
sk.listen()
def resp(url):
url=url[1:-1]+'.html'
print(url)
with open(url,'rb') as f:
ret=f.read()
return ret
def f404(url):
ret='404 Not Found'
return bytes(ret,encoding='utf-8')
url_fun_list= [('/firstpage/',resp),('/secondpage/',resp)]
while True:
conn,_=sk.accept()
data=conn.recv(9216)
data=str(data,encoding='utf-8')
request = data.split('
')[0]
url = request.split()[1]
conn.send(b'http/1.1 200 OK
content-type: text/html; charset=utf-8
')
func=f404
for i in url_fun_list:
if i[0]==url:
func=i[1]
break
response = func(url)
conn.send(response)
sk.close()
这样就完成了最简单的Web服务端了框架了。但是这只是个框架的示意,稳定性什么的要比正规的框架要差的多,可能运行一会就bug了。
动态页面的实现
这里的动态并不是指在页面上实现数据的动态显示,想想淘宝的主页面,每个人打开的页面是不一样的。首页推荐的内容是和平时搜索的内容索引出来相关的。那么复杂的效果我们还实现不了,就显示一下时间戳,每次刷新的时候能显示不同的时间。
把firstpage.html修改一下,随便加一个字符串。下面是修改过的firstpage.html文件
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>Document</title> </head> <body> <div> <p><label for=''>姓名</label><input type="text"></p> <p><label for=''>密码</label><input type="text"></p> </div> <div><button>登录</button></div> <div>时间:@@@</div> <!--在Python中用字符串替换@@@--> </body> </html>
然后在Python代码中把指定的字符串@@@用时间替换注意替换的方法:str.replace并不是把原字符串内指定字符替换,而是生成一个新的对象。运行一下,我们每次刷新页面,时间都会重新显示。
所以,动态的页面本质上就是实现了Html框架上对指定字符串的替换。注意字符串的替换是在服务端实现的,实在服务端,服务端。
Web框架的本质
前面我们实现了通过浏览器请求服务端响应的过程,那么我么总结下Web框架的本质:就是通过socket实现了服务端和浏览器之间的通讯。
Web框架功能性划分
Web框架按照功能可以划分为下面几点
- 负责与浏览器收发消息(socket)
- 根据用户访问的不同路径执行不同的函数
- 从HTML文件读取内容,并且完成字符串的替换。
Python中框架的分类
按照上面的三个功能来划分:
- 自带三个功能,例如tornado。
- 自带后两个功能,使用第三方的功能1,例如Django。
- 框架自带2,使用第三方的1和3,例如Flask。
而根据另外的一个维度来分:
- Django,大而全的框架,做一个网站所能需要的都能提供
- 其他非Django框架,例如轻量级的Flask
回顾一下前面的几个案例,我们下面分别从各个功能上利用框架来实现一下。
wsgiref模块
首先是实现第一个功能的wsgiref模块,通过这个模块,我们能实现比较稳定的socket连接。下面看看如何通过wsgiref模块实现一个简单的socket server
from wsgiref.simple_server import make_server
def resp(url):
url=url[1:-1]+'.html'
print(url)
with open(url,'rb') as f:
ret=f.read()
return ret
url_list = [('/firstpage/',resp),
('/secondpage/',resp)]
def run_server(environ,start_response):
start_response('200 OK',[('Content-Type','text/html;charset=utf8'),])#设置http响应头信息
url=environ['PATH_INFO']#获取用户输入的URL
func = None
for i in url_list:
if i[0] == url: #循环比较url是否在url_list内
func = i[1]
break
if func:
response = func(url)
else:
response = b'404 Not Found!'
return [response,]
if __name__ =='__main__':
httpd = make_server('127.0.0.1',8000,run_server)
httpd.serve_forever()
wsgiref模块是遵循了WSGI协议。
因为框架的三个功能基本上不是由一个人开发的,那么负责写功能1模块的开发人员为了要和后面的开发人员能顺利的对接,二者都要遵循一个叫WSGI的Web服务器网关接口(Python Web Server Gateway Interface,缩写为WSGI)的协议。
Jinja2模块
Jinja2模块主要实现的是第三个功能,实现功能3的模块有很多,这里讲Jinja2主要是因为Flask框架就是使用他来实现第三个功能的。并且Jinja2的语法和Django大致相同。
Jinja2的范例我们用的稍微复杂一些,涉及到了数据库——html和Web,要实现的功能是从通过Pymysql连接MySQL,数据库里读取数据经过Web服务显示在浏览器中。假设数据库文件是个用户列表,大概是这样的,database=test2
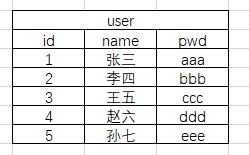
from jinja2 import Template from wsgiref.simple_server import make_server import pymysql #连接数据库 def read_db(): conn_db = pymysql.connect( host = '127.0.0.1', port = 3306, user = 'root', password = '', database = 'test2', charset = 'utf8') cursor = conn_db.cursor(cursor=pymysql.cursors.DictCursor) cursor.execute('select * from user;') user_list = cursor.fetchall() return user_list def resp(url): with open('Jinja2版html.html','r',encoding='utf-8') as f: data=f.read() user_list = read_db() template = Template(data) #生成模板文件 # ret = template.render({'user_list':user_list}) #把数据填充到模板中 ret = template.render({"user_list": user_list}) return [bytes(ret, encoding="utf8"), ] url_list=[('/user/',resp)] def run_server(environ,start_response): start_response('200 OK',[('Content-Type','text/html;charset=utf8'),]) url = environ['PATH_INFO'] func = None for i in url_list: if i[0] == url: func = i[1] break if func: response = func(url)[0] #注意,resp函数返回值是个list,这里需要的只是list内第一项。 else: response = b'404 Not Found!' print(response) return [response,] if __name__ == '__main__': httpd = make_server('127.0.0.1',8000,run_server) httpd.serve_forever()
还有对应的html模板,注意文件名
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>Document</title> </head> <body> <table border='1'> <thead> <th>ID</th> <th>用户名</th> <th>密码</th> </thead> <tbody> <!-- 用循环来实现数据的替换 --> {% for user in user_list %} <tr> <td>{{user.id}}</td> <td>{{user.name}}</td> <td>{{user.pwd}}</td> </tr> {% endfor %} </tbody> </table> </body> </html>
打开浏览器访问指定的界面:
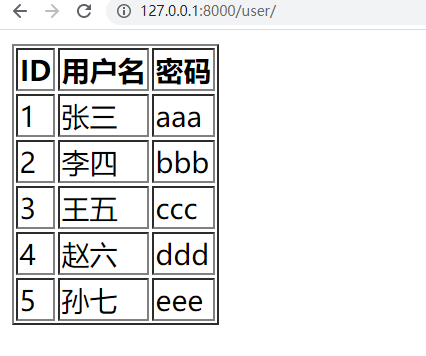
上面就用到了几乎所有前面所学的知识点了。
为了能搞好的实现上面的功能,下面就引出接下来一段时间的学习对象——Django
请看下集——第一个Django项目!