对于所有的Web应用,其实本质上都是一个socket服务端,用户的浏览器就是一个socket的client,我们看看下面这段代码
import socket def handle_request(client): buf = client.recv(1024) client.send(bytes("HTTP/1.1 200 OK ",encoding = 'utf-8')) client.send(bytes("Hello, Seven",encoding = 'utf-8')) def main(): sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sock.bind(('localhost',8000)) sock.listen(5) while True: connection, address = sock.accept() handle_request(connection) connection.close() if __name__ == '__main__': main()
运行一下,然后在浏览器里访问一下下面的地址
http://localhost:8000/
看看是不是接受到了服务器发送的字符串!这个过程就是通过socket实现了web应用的本质。而对于真实开发的Python Web来说,一般都会分为两部分:服务器程序和应用程序。服务器程序负责对socket服务器进行封装,并在请求到来的时候,对请求的各种数据进行整理。应用程序则负责具体的逻辑处理。为了方便应用程序的开发,已经出现了很多种Web框架:Django,Flask、web.py等等。这里就不再说明,以后再讲。
话说回来,上面的代码就是我们需要维护的服务器,我们访问的页面是很简单的一个页面,只有一个字符串。但是基本所有的 页面访问的都是有着各种效果的。这时候我们修改一下发送的字符串
client.send(bytes("<h1 style = 'background-color:red;'>Hello, Seven<h1>",encoding = 'utf-8'))
我们用了一段代码把发送的字符串包裹起来,在访问一下该页面,就会发现不同的效果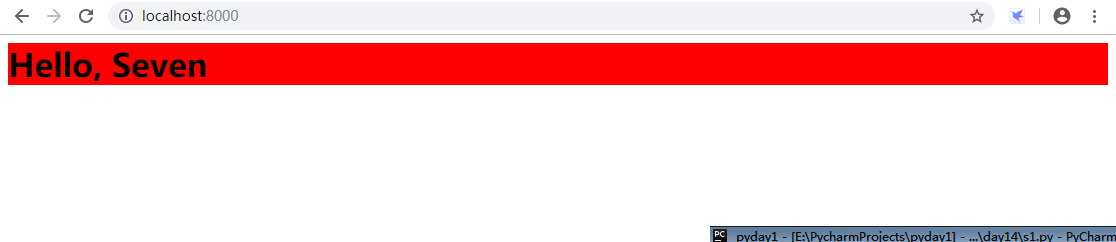
是不是背景颜色和字体大小都有了效果。也就是说我们发回来的字符串包含了一个标签,这个标签可以被浏览器识别,然后浏览器就把这个标签按照一定的规则进行包装。而这套规则,就是HTML协议。我们在修改一下这段代码
import socket def handle_request(client): buf = client.recv(1024) client.send(bytes("HTTP/1.1 200 OK ",encoding = 'utf-8')) with open(r'D:python前端index.txt','rb') as f: data = f.read() client.send(data) def main(): sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sock.bind(('localhost',8000)) sock.listen(5) while True: connection, address = sock.accept() handle_request(connection) connection.close() if __name__ == '__main__': main()
我们把要发送的字符串和把这段字符串包装的标签放在index.txt这个文件下,运行的效果是一样的。那这个index文件就是html文件(一般为了规范就不用txt作为后缀名,而用html)。我们现在要做的,就是学习html规则。
再引伸一下,把刚才的index文件中间的字符串修改一下
<h1 style = 'background-color:red;'>Hello,@@@@@<h1> <table border='1'> <tr> <td>1</td> <td>2</td> <td>3</td> </tr> </table>
然后再读取数据的时候,把@@@@@替换一下
def handle_request(client): buf = client.recv(1024) client.send(bytes("HTTP/1.1 200 OK ",encoding = 'utf-8')) with open(r'D:python前端index.txt','r') as f: data = f.read() import time now_time = str(time.time()) data=data.replace('@@@@@',now_time) client.send(bytes(data,encoding='utf-8'))
所以这个html文件就成了一个模板,我们只需要写好这个模板,然后从数据库里获得数据,然后替换到html文件的指定位置就实现了最low的后台程序。所以下面就是开发者要做的事情:
一.学习Html规则
二.写Html文件(模板)
三.获取数据,然后替换到html文件的指定位置(Web框架可以实现,以后会讲到)。
下面就是今天要做的——学习Html规则,更具体一点就是如何使用这些标签来构建我们的html文件。
基础架构
如果我们用Pycharm新建一个html文件,是会生成一个这样的结构的
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> </body> </html>
这个文件就是一个最基础的模板,下面就看一看每一个部分所代表的含义
第一行
<!DOCTYPE html>
就是声明了我们这个文件所用的协议类型——html
第二行
<html lang='en'>
lang='en'写在了标签的内部,就叫做标签内部的属性。这里的语言属性主要是声明了网页的语言是英文。作用是在有些浏览器(类似于chrome打开以后会提示是否翻译)
而在html里面包含了一个head和一个body,就构成了html文件的最基础的结构
<!DOCTYPE html> <html lang="utf-8"> <head></head> <body></body> </html>
下面我们就看一看具体的部分是怎么使用
html的head内标签
其实这里的head更好的理解应该是大脑而不是头,因为head内标签几乎所有的效果都是不可见的(注意是几乎,不是所有)。我们就看看下面几个标签的含义
1.meta(metadata information)
该标签提供了有关页面的元信息,包括页面编码、刷新、跳转、针对搜索引擎和更新频度的描述和关键词,下面看看具体的用法
1.1页面编码
<meta http-equiv="content-type" content="text/heml;charset=utf-8">
1.2刷新
<meta http-equiv="refresh "content='3'>
后面的内容就刷新的时间间隔,单位为秒。
1.3跳转
<meta http-equiv="refresh"content='3,url=http://www.baidu.com'>
跳转的用法和刷新差不多,就是在跳转的间隔后加上要跳转的页面地址。这种用法不太常用,因为实际使用中的页面跳转都是动态的(类似于显示还有多少秒跳转)。但是可以在救急的时候用一下。
1.4关键词
<meta name='keywords' content="关键词1,关键词2">
这个关键字的描述就是给搜索引擎的爬虫提供了个关键字。然后通过这个关键字可以搜索到这个页面(现在这个时代好像也没什么用了,毕竟竞价排名~)
1.5描述
<meta name='description' content='对于这个页面的描述'>
这个描述是和上面的关键词一起用的,看看百度出来知乎的描述
再看看知乎首页的源代码里的这一行
<meta name="description" property='og:description' content='有问题,上知乎。知乎,可信赖的问答社区,以让每个人高效获得可信赖的解答为使命。知乎凭借认真、专业和友善的社区氛围,结构化、易获得的优质内容,基于问答的内容生产方式和独特的社区机制,吸引、聚集了各行各业中大量的亲历者、内行人、领域专家、领域爱好者,将高质量的内容透过人的节点来成规模地生产和分享。用户通过问答等交流方式建立信任和连接,打造和提升个人影响力,并发现、获得新机会。'>
是不是就知道啥意思了!
1.6X-UA-Compatible,用来声明对那种浏览器支持
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
并且这个语法早期可以定义IE8以后的版本的浏览器是否以兼容模式来访问该页面。但是随着IE6的消亡貌似也不这么用了。
2.title标签
title标签貌似是head里唯一可以看到的了,按照下面的代码
<title>好像只有这个title是可见的</title>
出来的效果
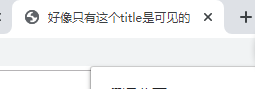
也就是改了页面的标题栏里显示的文本字符。
3.link标签
固定格式,可以改上面图里标题栏里的图表,具体用法我们在后面讲
4.style标签
后面再讲
5Script标签
后面再讲
html里的body内标签
所有的标签分为块级标签,和内联标签(也叫行内标签),块级标签作用于为整行,而内连表情值作用域当下。
1.各种符号
在html中,很多字符是预留的,我们不能使用(比方说大于号小于号,会和标签冲突,还有引号等等。)所以我们就需要用字符实体(character entities)。类似下面的用法
body内的各种符号是有固定的标签的,比如我们要用一个大于号或者小于号,是不是可能会和标签里的<>冲突!那就要用对应的标签了,下面就是常用的符号标签。
| 空格 | |   | |
| < | 小于号 | < | < |
| > | 大于号 | > | > |
| & | 和号 | & | & |
| " | 引号 | " | " |
| ' | 撇号 | ' (IE不支持) | ' |
| ¢ | 分(cent) | ¢ | ¢ |
| £ | 镑(pound) | £ | £ |
| ¥ | 元(yen) | ¥ | ¥ |
| € | 欧元(euro) | € | € |
| § | 小节 | § | § |
| © | 版权(copyright) | © | © |
| ® | 注册商标 | ® | ® |
| ™ | 商标 | ™ | ™ |
| × | 乘号 | × | × |
| ÷ | 除号 | ÷ | ÷ |
其实这里的字符集有非常多个,最早使用的是ASCII。后来有各种的标准字符集,我们在用的时候可以直接在网上搜,这里就不列出来了。
2.P标签和b标签
P标签和BR标签,P标签用于声明段落,而BR是用于声明换行。有些类似字符串里的转义字符。从br标签的作用可以看出来,他是个自闭和的标签。
<p></p> <br>
3.h标签
h标签用来指定标签内部的字号,只有h1——h6。
4.span标签
span标签(块级)就是一个白板(行内标签)。可以通过css来修饰。
5.div标签
div是个非常牛逼的标签(自闭和),也是相当于一个白板,但是不同于span的是他是个块级标签。现在大部分做页面的都是div+css的模式(其实用span+css也是可以的,效果相同)。我们随便看一个页面的代码都是用div来组建的。并且通过标签之间的嵌套和一些js操作、css操作其中内容。
上面是一些入门的标签,我们将会在后续章节中讲剩下的一些功能性比较强的标签的用法。