Spark核心 RDD(上)
一、预备知识:
x:RDD(Resilient Distributed Dataset / 弹性分布式数据集)、分区、流水线操作、Stage...
0、RDD在迭代计算方面比Hadoop快20多倍,计算数据分析类报表的性能提高了40多倍,同时还可以在5-7秒内交互式地查询1TB数据集。RDD适用于具有批量转换需求的应用,并且相同的操作作用于数据集的每一个元素上。
1、RDD持久化:一、persist()内部调用了persist(StorageLevel.MEMORY_ONLY);二、cache()调用了persist( )。说明:RDD持久化方法被调用时不会立即缓存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供后面重用。
2、RDD可序列化:每个partition仅仅是一个字节数组而已,大大减少了对象数量,并降低了内存占用
3、Spark Core 生产中只选择MEMORY_ONLY(未序列化的Java对象格式)和MEMORY_ONLY_SER(将RDD中的数据进行序列化)这两种存储级别,Cpu的计算速度远远大于从内存中读取数据的速度更大于从磁盘中读取数据的速度,有时重新计算数据比读取缓存的数据速度更快,故不需要将数据存多份或者存储磁盘,故spark core生产只选择上述两种存储类型
4、序列化使得占用的内存更少,但是序列化以及反序列化是需要耗时的,同时耗费CPU,故具体要根据资源以及业务去选择使用缓存,最好养成结束释放缓存的良好规范
5、数据流系统(非循环模型)在迭代式算法和交互式数据挖掘工具两种情况下处理并不高效。这两种情况的特点是在多个并行操作之间重用工作数据集。迭代式算法每一步对数据执行相似的函数,而且机器学习算法需要将这次迭代权值调优后的结果数据集作为下次迭代的输入,MapReduce计算框架经过一次Reduce操作后输出数据结果写回磁盘,速度大大的降低了,RDD将数据保存在内存中能够极大地提高性能。
6、 Transformation实际上是一种链式的逻辑Action,记录了RDD演变的过程。Action则是实质触发Transformation开始计算的动作,由于在每个Transformation的过程中都有记录,所以每个RDD是知道上一个RDD是怎样转变为当前状态的,所以如果出错就可以很容易的重新演绎计算过程。
7、基于数据集的hadoop的MapReduce和基于工作集的的Spark的RDD共同点:位置感知调度(MapReduce:partition、Reducer;Spark:partition、Stage)--最优化调度,提高系统性能,自动容错--高效容错,节省容错成本,负载均衡等
9、RDD还允许用户根据关键字(key)指定分区顺序(细粒度操作),这是一个可选的功能。目前支持哈希分区和范围分区,如:应用程序请求将两个RDD按照同样的哈希分区方式进行分区(将同一机器上具有相同关键字的记录放在一个分区,以加速它们之间的join操作。有些操作会自动产生一个哈希或范围分区的RDD,像groupByKey,reduceByKey和sort等。分区置换策略优化!
10、JVM的OOM内存溢出:
11、MapReduce等数据流模型的容错特性:;RDD容错特性:RDD提供了一种高度受限的共享内存,即RDD是只读的,并且只能通过其他RDD执行确定的转换操作(如map、join和group by)来创建。
二、RDD的弹性:
1、弹性之一:自动的进行内存和磁盘数据存储的切换;
2、弹性之二:基于Lineage的高效容错(第n个节点出错,会从第n-1个节点恢复,血统容错); RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列转换(如map、join和group by)记录下来(即Lineage)。如果Lineage链很长,可以将Lineage链存到物理存储中,再定期对RDD执行检查点操作。
3、弹性之三:Task如果失败会自动进行特定次数的重试(默认4次);
4、弹性之四:Stage如果失败会自动进行特定次数的重试(可以只运行计算失败的阶段);只计算失败的数据分片;
5、checkpoint和persist:checkpoint:每次对RDD操作都会产生新的RDD,如果链条比较长,计算比较笨重,就把数据放在硬盘中;persist:内存或磁盘中对数据进行复用
6、数据调度的弹性:DAG TASK 和资源 管理无关
7、数据分片的高度弹性(人工自由设置分片函数),repartition
三、RDD的Transformation和Actions:
- map(func) :返回一个新的分布式数据集,由每个原元素经过func函数转换后组成
- filter(func) : 返回一个新的数据集,由经过func函数后返回值为true的原元素组成
*flatMap(func) : 类似于map,但是每一个输入元素,会被映射为0到多个输出元素(因此,func函数的返回值是一个Seq,而不是单一元素) - flatMap(func) : 类似于map,但是每一个输入元素,会被映射为0到多个输出元素(因此,func函数的返回值是一个Seq,而不是单一元素)
- sample(withReplacement, frac, seed) :
根据给定的随机种子seed,随机抽样出数量为frac的数据 - union(otherDataset) : 返回一个新的数据集,由原数据集和参数联合而成
- groupByKey([numTasks]) :
在一个由(K,V)对组成的数据集上调用,返回一个(K,Seq[V])对的数据集。注意:默认情况下,使用8个并行任务进行分组,你可以传入numTask可选参数,根据数据量设置不同数目的Task - reduceByKey(func, [numTasks]) : 在一个(K,V)对的数据集上使用,返回一个(K,V)对的数据集,key相同的值,都被使用指定的reduce函数聚合到一起。和groupbykey类似,任务的个数是可以通过第二个可选参数来配置的。
- join(otherDataset, [numTasks]) :
在类型为(K,V)和(K,W)类型的数据集上调用,返回一个(K,(V,W))对,每个key中的所有元素都在一起的数据集 - groupWith(otherDataset, [numTasks]) : 在类型为(K,V)和(K,W)类型的数据集上调用,返回一个数据集,组成元素为(K, Seq[V], Seq[W]) Tuples。这个操作在其它框架,称为CoGroup
- cartesian(otherDataset) : 笛卡尔积。但在数据集T和U上调用时,返回一个(T,U)对的数据集,所有元素交互进行笛卡尔积。
- flatMap(func) :
类似于map,但是每一个输入元素,会被映射为0到多个输出元素(因此,func函数的返回值是一个Seq,而不是单一元素)
- reduce(func) : 通过函数func聚集数据集中的所有元素。Func函数接受2个参数,返回一个值。这个函数必须是关联性的,确保可以被正确的并发执行
- collect() : 在Driver的程序中,以数组的形式,返回数据集的所有元素。这通常会在使用filter或者其它操作后,返回一个足够小的数据子集再使用,直接将整个RDD集Collect返回,很可能会让Driver程序OOM,批量读操作,即扫描整个数据集,分配到距离数据最近的节点
- count() : 返回数据集的元素个数,批量读操作,即扫描整个数据集,分配到距离数据最近的节点
- take(n) : 返回一个数组,由数据集的前n个元素组成。注意,这个操作目前并非在多个节点上,并行执行,而是Driver程序所在机器,单机计算所有的元素(Gateway的内存压力会增大,需要谨慎使用)
- first() : 返回数据集的第一个元素(类似于take(1))
- saveAsTextFile(path) : 将数据集的元素,以textfile的形式,保存到本地文件系统,hdfs或者任何其它Hadoop支持的文件系统。Spark将会调用每个元素的toString方法,并将它转换为文件中的一行文本
- saveAsSequenceFile(path) : 将数据集的元素,以sequencefile的格式,保存到指定的目录下,本地系统,hdfs或者任何其它hadoop支持的文件系统。RDD的元素必须由key-value对组成,并都实现了Hadoop的Writable接口,或隐式可以转换为Writable(Spark包括了基本类型的转换,例如Int,Double,String等等)
- foreach(func) : 在数据集的每一个元素上,运行函数func。这通常用于更新一个累加器变量,或者和外部存储系统做交互
图-1 RDD空间
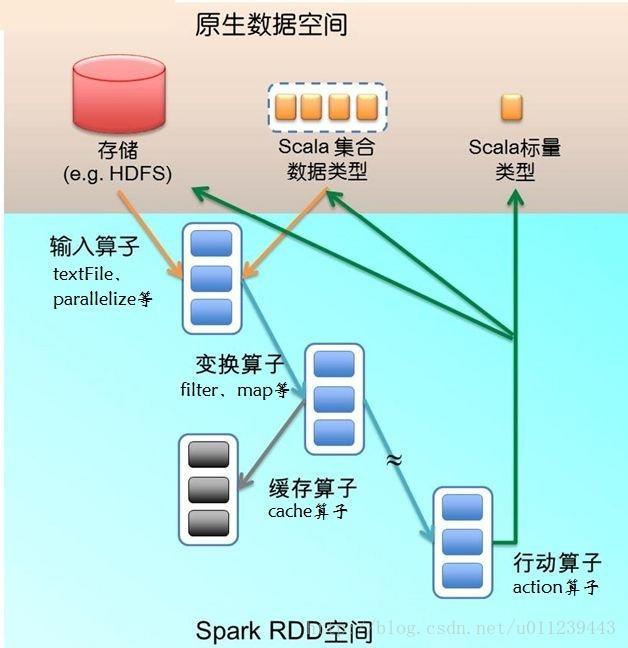
四、RDD来源
1、使用程序中的集合创建RDD(用于小量测试)
package com.imf.spark.rdd
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by lujinyong168 on 2016/2/2.
* DT大数据梦工厂-IMF
* 使用程序中的集合创建RDD(用于小量测试)
*/
object RDDCreateByCollections {
def main(args: Array[String]) {
val conf = new SparkConf()//创建SparkConf对象
conf.setAppName("RDDCreateByCollections")//设置应用名称
conf.setMaster("local")
val sc = new SparkContext(conf)//创建SparkContext对象
//创建一个Scala集合
val numbers = 1 to 100
val rdd = sc.parallelize(numbers)
// val rdd = sc.parallelize(numbers,10)//设置并行度为10
val sum = rdd.reduce(_+_)
println("1+2+3+...+99+100="+sum)
}
}
2、使用本地文件系统创建RDD(测试大数据)
package com.imf.spark.rdd
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by lujinyong168 on 2016/2/2.
* DT大数据梦工厂-IMF
* 使用本地文件系统创建RDD(测试大量数据)
* 统计文本中的字符个数
*/
object RDDCreateByLocal {
def main(args: Array[String]) {
val conf = new SparkConf()//创建SparkConf对象
conf.setAppName("RDDCreateByLocal")//设置应用名称
conf.setMaster("local")
val sc = new SparkContext(conf)//创建SparkContext对象
val rdd = sc.textFile("D://testspark//WordCount.txt")
val linesLen = rdd.map(line=>line.length)
val sum = linesLen.reduce(_+_)
println("The total characters of the file is : "+sum)
}
}
3、使用HDFS创建RDD(生产环境最常用的RDD创建方式)
package com.imf.spark.rdd
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by lujinyong168 on 2016/2/2.
* DT大数据梦工厂-IMF
* 使用HDFS创建RDD(生产环境最常用的RDD创建方式)
*/
object RDDCreateByHDFS {
def main(args: Array[String]) {
val conf = new SparkConf()//创建SparkConf对象
conf.setAppName("RDDCreateByHDFS")//设置应用名称
conf.setMaster("local")
val sc = new SparkContext(conf)//创建SparkContext对象
val rdd = sc.textFile("/library/")
val linesLen = rdd.map(line=>line.length)
val sum = linesLen.reduce(_+_)
println("The total characters of the file is : "+sum)
}
4、基于DB创建RDD
5、基于NoSQL,例如HBase
6、基于S3创建RDD
7、基于数据流创建RDD
五、RDD示例,检查Hadoop文件系统(HDFS)中的日志文件(TB级大小)来找出大型网站出错原因
lines = spark.textFile("hdfs://...")
errors = lines.filter(_.startsWith("ERROR"))
errors.cache()
注:第1行从HDFS文件定义了一个RDD(即一个文本行集合),第2行获得一个过滤后的RDD,第3行请求将errors缓存(cache)起来,最初的RDD lines不会被缓存。因为错误信息可能只占原数据集的很小一部分(小到足以放入内存)。
errors.count()
注:集群还没有开始执行任何任务。但是,用户已经可以在这个RDD上执行对应的动作action
// Count errors mentioning MySQL:
errors.filter(_.contains("MySQL")).count()
// Return the time fields of errors mentioning
// HDFS as an array (assuming time is field
// number 3 in a tab-separated format):
errors.filter(_.contains("HDFS"))
.map(_.split(' ')(3))
.collect()
注:在RDD上执行更多的转换操作transformation
六、RDD与分布式共享内存
1、分布式共享内存(Distributed Shared Memory/DSM):不仅指传统的共享内存系统,还包括那些通过分布式哈希表或分布式文件系统进行数据共享的系统
2、RDD与分布式共享内存(DMS)的对比:
第一点:DMS、应用可以向全局地址空间的任意位置进行读写操作。RDD、不仅可以对任意内存位置读写,还可以通过批量转换创建(即“写”)RDD。
第二点:DSM则难以实现备份任务,因为任务及其副本都需要读写同一个内存位置。通过备份任务的拷贝,RDD还可以处理落后任务(即运行很慢的节点)
第三点:与DSM相比,RDD模型有两个好处。第一,对于RDD中的批量操作,运行时将根据数据存放的位置来调度任务,从而提高性能。第二,对于基于扫描的操作,如果内存 不足以缓存整个RDD,就进行部分缓存。把内存放不下的分区存储到磁盘上,此时性能与现有的数据流系统差不多。
表-1 RDD与分布式共享内存对比
| 对比项目 | RDD | 分布式共享内存(DSM) |
|---|---|---|
| 读 | 批量或细粒度操作 | 细粒度操作 |
| 写 | 批量转换操作 | 细粒度操作 |
| 一致性 | 不重要(RDD是不可更改的) | 取决于应用程序或运行时 |
| 容错性 | 细粒度,低开销(使用Lineage) | 需要检查点操作和程序回滚 |
| 落后任务的处理 | 任务备份 | 很难处理 |
| 任务安排 | 基于数据存放的位置自动实现 | 取决于应用程序(通过运行时实现透明性) |
| 如果内存不够 | 与已有的数据流系统类似 | 性能较差 |