Spark解析及运用
一、Spark(大规模数据处理引擎)的特点
0、Spark的优点是什么?spark框架的数据结构是什么?针对于不同的情况,spark怎么更改数据结构?spark数据流的传递是怎么?spark的数据的安全性怎么保证?
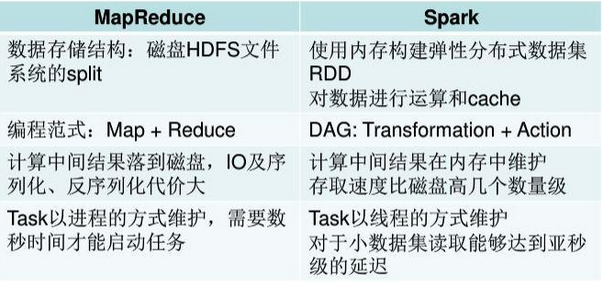
1、speed:Spark应用程序的中间数据是存储在内存中的,Spark比Hadoop的MapReduce快100多倍,存储在磁盘中的数据要快10多倍
2、Easy of Use:Spark应用程序可以使用Java、Scala、Python、R等多种编程语言
3、Generality:Spark提供了SparkSQL、Streaming、MLlib、GraphX功能模块,功能强大
图-1 Spark生态系统
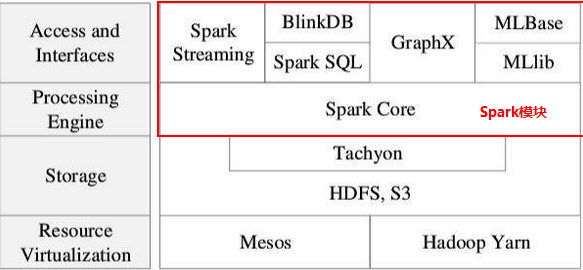
4、Runs Everywhere:运行在Hadoop的Yarn上、Mesos和自身的standalone上,处理的文件系统包括HDFS、Cassandra、HBase、S3、Hive等多种数据源。
注:以上部分摘自官网: http://spark.apache.org/
二、Spark 的设计与实现原理
1、Spark的基本数据类型:RDD(resilientdistributed dataset)、DataFrame、Dataset
1.1、Spark的基本数据类型的核心RDD:一个RDD就是一个可分区的分布式对象集合。RDD的不同分区可以被保存到集群中不同的节点上,可以在集群中不同节点上进行并行计算。NarrowDependency在一个集群节点上以流水线的方式(pipeline)计算所有父分区。
1.2、RDD:一、高效的容错性,二、中间结果持久化到内存,三、存放的数据可以是Java对象,避免了不必要的对象序列化和反序列化
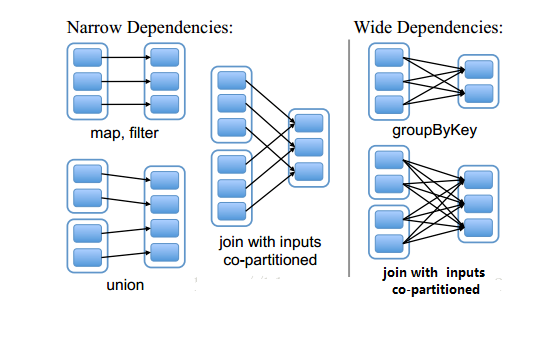
1.3、RDD的依赖关系:窄依赖(NarrowDependency),子RDD的每个分区依赖于常数个父分区(即与数据规模无关)(map、filter、union、join);宽依赖(ShuffleDependency),子RDD的每个分区依赖于所有父RDD分区(groupBy;join)
2、Stage的划分
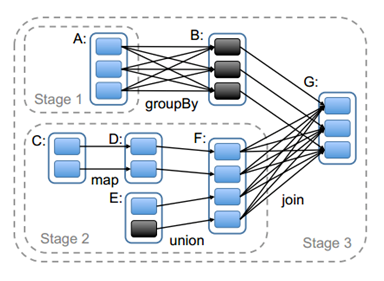
2.1、stage的划分原则:一、RDD的依赖关系:遇到宽依赖就断开;遇到窄依赖就把当前的RDD加入到Stage中,将窄依赖尽量划分到同一个Stage。二、将依赖链断开,每个stage内部可以并行运行。
2.2、一个Job由多个Stage构成,一个Job按照Stage顺序依次执行,最终完成整个Job。
2.3、DAG((Directed Acyclic Graph))Scheduler的Stage划分算法:会从触发action操作的那个RDD开始反向解析,首先会为最后一个RDD创建一个stage,反向解析的时候,遇到窄依赖就把当前的RDD加入到Stage,遇到宽依赖就断开,将宽依赖的那个RDD创建一个新的stage,那个RDD就是这个新stage最后一个RDD。依此类推,遍历所有RDD。
图-2 Stage划分示例
3、Spark的计算模型也属于MapReduce,但是不局限于Map和Reduce操作,还可以提供了多种数据集操作类型,编程模型比Hadoop MapReduce更灵活。
图-2 MapReduce vs Spark
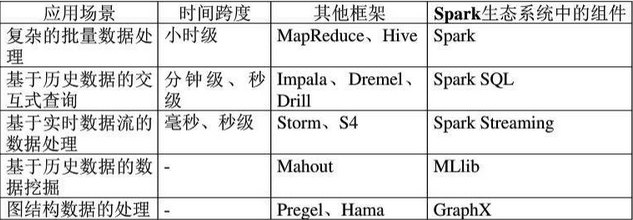
4、Spark生态各组件的应用情况:
图-3 应用场景
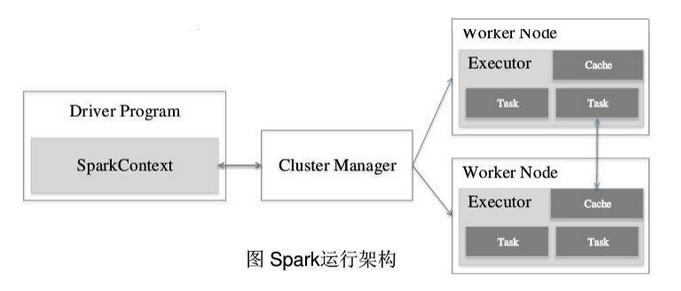
5、Spark运行框架
一、基本概念:
4.1、RDD(弹性分布式数据集):是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型。
4.2、DAG(有向无环图):反映RDD之间的依赖关系,任务调度执行机制
4.3、Executor(是运行在工作节点的一个进程):,负责运行Task
4.4、Application:用户编写Spark应用程序,一个Application由一个Driver(DriverApplication)和若干个Job构成
4.5、Task:运行在Executor上的工作单元,Task分为ShuffleMapTask和ResultTask两种,Task是运行Application的基本单位。Task的调度和管理等是由TaskScheduler负责。
4.6、Job:一个application里面每遇到一个action的操作就会生成一个job,一个Job由多个Stage构成,一个job包含多个Rdd及作用于相应RDD上的各种操作,。
4.7、Stage:是Job的基本调度单位,一个Job会分为多组Task,每组Task被称为Stage,或者被称为TaskSet,代表了一组关联的、相互之间没有Shuffle依赖关系(宽依赖)任务组成的任务集。
二、Spark 运行框架的组成
1、Spark 运行框架的组成:集群资源管理器(Cluster Manager) + 任务控制节点(Driver) + 工作节点(Worker Node) + 执行进行(Executor)
2、集群资源管理器(Cluster Manager):主要负责资源的分配与管理。集群管理器分配的资源属于一级分配,它将各个Worker Node上的内存、CPU等资源分配给应用程序,但是并不负责对Execoutor的资源分配。
3、Driver Program:运行Application的main()函数,用于将任务程序转换为RDD和DAG,并与Cluster Manager进行通信与调度
4、Worker Node:控制计算节点,创建并启动Executor,将资源和任务进一步分配给Executor,同步资源信息给Cluster Manager
5、Executor:某个Appliation运行在Worker node上的一个进程。主要负责任务的执行以及与Worker、Driver App的信息同步
6、Executor的优点:1、采用多线程来执行具体的任务,减少任务的启动开销;2、BlockManager存储模块将内存和磁盘共同作为存储设备,有效减少IO开销
图-4 Spark运行框架
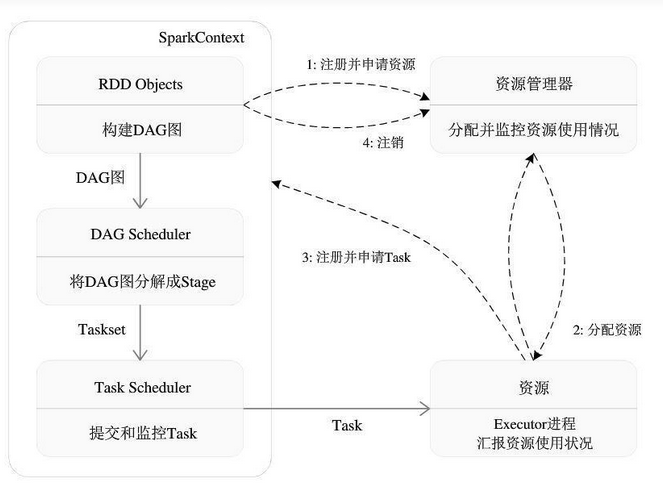
三、Spark 运行框架的运行
1、概述:当执行一个Application时,Driver会向集群管理器申请资源,启动Executor,并向Executor发送应用程序代码和文件,然后在Executor上执行Task,运行结束后,执行结果会返回给Driver,或者写到HDFS(分布式文件系统)或者其他数据库。
2、具体的执行步骤:
2.1、Driver会向集群管理器申请资源任务发分配和监控:Driver创建一个SparkContext
2.2、资源管理器为Executor分配资源,并启动Executor进程:
2.3、SparkContext根据RDD的依赖关系构建DAG图(有向无环图),DAG图提交给DAGScheduler解析成Stage(TaskSet)
2.4、TaskSet提交给底层调度器Taskscheduler处理
2.5、Executor向SparkContext申请Task发给Executor运行,并提供应用程序代码
2.6、Task在Executor上运行,把执行结果反馈给TaskScheduler,然后反馈给DAGScheduler
三、Spark编译和源码解析
1、Maven 是一个项目管理工具,可以对 Java 项目进行构建、依赖管理。
四、Spark编程模型
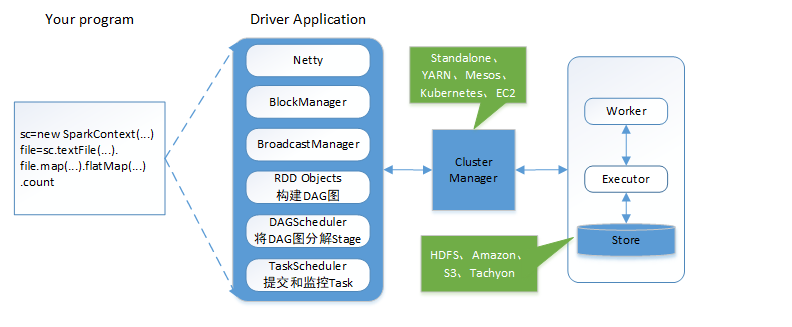
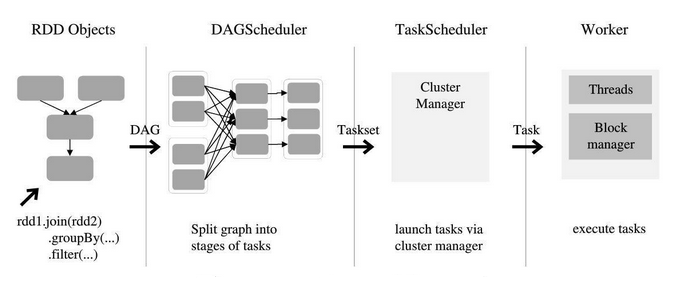
Spark应用程序从编写到提交、执行、输出的整个过程:
1、用户使用SparkContext提供的API(常用的有textFile、sequenceFile、runJob、stop等)编写Driver application程序。此外SQLContext、HiveContext及StreamingContext对SparkContext进行封装,并提供了SQL、Hive及流式计算相关的 API
2、使用SparkContext提交的用户应用程序,首先会使用BlockManager和BroadcaseManager将任务的Hadoop配置进行广播。然后由DAGScheduler将任务转换为RDD并组织成DAG,DAG还将被划分为不同的Stage,一个Stage会由多个Task组成,多个Task将会被存放在TaskSet集合里,TaskSet即为Stage。最后由TaskScheduler将Task借助Netty通信框架将任务提交给集群管理器(Cluster Manager)
3、集群管理器(Cluster Manager)给任务分配资源,即将具体任务分配到Worker上,Worker创建Executor来处理任务的运行。Standalone、YARN、Mesos、Kubernetes、EC2等都可以作为Spark的集群管理器
图-5 Spark编程模型