线程
Threading用于提供线程相关的操作,线程是应用程序中工作的最小单元。
1 #!/usr/bin/env python 2 #coding=utf-8 3 __author__ = 'yinjia' 4 5 6 import threading,time 7 8 def show(arg): 9 time.sleep(2) 10 print('线程: ' + str(arg)) 11 12 for i in range(5): 13 t = threading.Thread(target=show,args=(i,)) 14 t.start()
如上述代码创建了5个线程,target指向函数,arges参数传递数值。
- 其它方法:
- start 线程准备就绪,等待CPU调度
- setName 为线程设置名称
- getName 获取线程名称
- setDaemon 设置为后台线程或前台线程(默认)。如果是后台线程,主线程执行过程中,后台线程也在进行,主线程执行完毕后,后台线程不论成功与否,均停止;如果是前台线程,主线程执行过程中,前台线程也在进行,主线程执行完毕后,等待前台线程也执行完成后,程序停止
- join 逐个执行每个线程,执行完毕后继续往下执行,该方法使得多线程变得无意义
- run 线程被cpu调度后自动执行线程对象的run方法
- setNamegetName使用方法
1 #!/usr/bin/env python 2 #coding=utf-8 3 __author__ = 'yinjia' 4 5 6 import threading,time 7 8 def test(i): 9 print("线程:%s" %str(i)) 10 time.sleep(2) 11 12 for i in range(2): 13 t = threading.Thread(target=test,args=(i,)) 14 t.start() 15 t.setName("我的线程: {0}".format(str(i))) 16 print(t.getName()) 17 18 运行结果: 19 线程:0 20 我的线程: 0 21 线程:1 22 我的线程: 1


1 #!/usr/bin/env python 2 #coding=utf-8 3 __author__ = 'yinjia' 4 5 6 import threading,time 7 8 class MyThread(threading.Thread): 9 def __init__(self,num): 10 threading.Thread.__init__(self) 11 self.num = num 12 13 def run(self): 14 print("running thread:%s" % self.num) 15 time.sleep(2) 16 17 if __name__ == '__main__': 18 for i in range(2): 19 t1 = MyThread(i) 20 t1.start() 21 t1.setName("我的线程: {0}".format(str(i))) 22 print(t1.getName()) 23 24 运行结果: 25 running thread:0 26 我的线程: 0 27 running thread:1 28 我的线程: 1
- setDaemon方法使用
1 #!/usr/bin/env python 2 #coding=utf-8 3 __author__ = 'yinjia' 4 5 6 import threading,time 7 8 def run(num): 9 print("running thread %s" % str(num)) 10 time.sleep(2) 11 print("OK! %s" % str(num)) 12 13 for i in range(2): 14 t = threading.Thread(target=run,args=(i,)) 15 #未使用setDaemon时默认是前台线程 16 #t.setDaemon(True) 17 t.start() 18 t.setName("MyThread_{0}".format(str(i))) 19 print(t.getName()) 20 21 运行结果: 22 running thread 0 23 MyThread_0 24 running thread 1 25 MyThread_1 26 OK! 1 27 OK! 0
后台线程:
1 #!/usr/bin/env python 2 #coding=utf-8 3 __author__ = 'yinjia' 4 5 6 import threading,time 7 8 def run(num): 9 print("running thread %s" % str(num)) 10 time.sleep(2)
#主线程执行结束后,不会执行以下语句 11 print("OK! %s" % str(num)) 12 13 for i in range(2): 14 t = threading.Thread(target=run,args=(i,)) 15 #使用setDaemon时是后台线程 16 t.setDaemon(True) 17 t.start() 18 t.setName("MyThread_{0}".format(str(i))) 19 print(t.getName()) 20 21 22 运行结果: 23 running thread 0 24 MyThread_0 25 running thread 1 26 MyThread_1
- join用法理解
当未使用join方法时候,先执行完主线程再根据超时决定等待子线程执行完才能程序结束;如果使用join方法,先执行子线程执行完后,才开始执行下一步主线程,此方法没有达到并行效果。
1 #!/usr/bin/env python 2 # _*_ coding:utf-8 _*_ 3 __author__ = 'yinjia' 4 5 import time,threading 6 7 def do_thread(num): 8 time.sleep(3) 9 print("this is thread %s" % str(num)) 10 11 for i in range(2): 12 t = threading.Thread(target=do_thread, args=(i,)) 13 t.start() 14 t.setName("Mythread_{0}".format(str(i))) 15 print("print in main thread: thread name:", t.getName()) 16 17 运行效果:【#先同时执行两个主线程,等待3秒后再执行两个子线程】 18 print in main thread: thread name: Mythread_0 #主线程 19 print in main thread: thread name: Mythread_1 #主线程 20 this is thread 0 #子线程 21 this is thread 1 #子线程
使用join效果如下:
1 #!/usr/bin/env python 2 # _*_ coding:utf-8 _*_ 3 __author__ ='yinjia' 4 5 import time,threading 6 7 def do_thread(num): 8 time.sleep(3) 9 print("this is thread %s" % str(num)) 10 11 for i in range(2): 12 t = threading.Thread(target=do_thread, args=(i,)) 13 t.start() 14 t.join() #增加join 15 t.setName("Mythread_{0}".format(str(i))) 16 print("print in main thread: thread name:", t.getName()) 17 18 19 运行结果:【先执行子线程,然后再执行主线程,单一逐步执行】 20 this is thread 0 21 print in main thread: thread name: Mythread_0 22 this is thread 1 23 print in main thread: thread name: Mythread_1
- 线程锁(Lock、RLock)
线程是共享内存,当多个线程对一个公共变量修改数据,会导致线程争抢问题,为了解决此问题,采用线程锁。
1 #!/usr/bin/env python 2 # _*_ coding:utf-8 _*_ 3 __author__ = 'Administrator' 4 5 import time,threading 6 7 gl_num = 0 8 lock = threading.RLock() 9 10 def Func(): 11 global gl_num 12 #加锁 13 lock.acquire() 14 gl_num += 1 15 time.sleep(1) 16 print(gl_num) 17 #解锁 18 lock.release() 19 20 for i in range(10): 21 t = threading.Thread(target=Func) 22 t.start()
- 信号量(Semaphore)
信号量同时允许一定数量的线程更改数据 ,比如厕所有3个坑,那最多只允许3个人上厕所,后面的人只能等里面有人出来了才能再进去。
1 #!/usr/bin/env python 2 # _*_ coding:utf-8 _*_ 3 __author__ = 'yinjia' 4 5 import time,threading 6 7 def run(n): 8 semaphore.acquire() 9 time.sleep(1) 10 print("run the thread: %s" % n) 11 semaphore.release() 12 13 if __name__ == '__main__': 14 num = 0 15 semaphore = threading.BoundedSemaphore(5) # 最多允许5个线程同时运行 16 for i in range(20): 17 t = threading.Thread(target=run, args=(i,)) 18 t.start()
- 事件(event)
事件用于主线程控制其他线程的执行,事件主要提供了三个方法 set、wait、clear。
1 #!/usr/bin/env python 2 # _*_ coding:utf-8 _*_ 3 __author__ = 'Administrator' 4 5 import time,threading 6 7 def run(event): 8 print("start") 9 event.wait() 10 print('END.....') 11 12 event_obj = threading.Event() 13 for i in range(2): 14 t = threading.Thread(target=run,args=(event_obj,)) 15 t.start() 16 17 event_obj.clear() 18 inp = input("input: ") 19 if inp == 'true': 20 event_obj.set() 21 22 #运行结果: 23 start 24 start 25 input: true 26 END..... 27 END.....
- 条件(Condition)
满足条件,才能释放N个线程。
1 #!/usr/bin/env python 2 # _*_ coding:utf-8 _*_ 3 __author__ = 'Administrator' 4 5 import time,threading 6 7 def condition_func(): 8 ret = False 9 inp = input('>>>') 10 if inp == '1': 11 ret = True 12 return ret 13 14 def run(n): 15 con.acquire() 16 con.wait_for(condition_func) 17 print("run the thread: %s" %n) 18 con.release() 19 20 if __name__ == '__main__': 21 22 con = threading.Condition() 23 for i in range(10): 24 t = threading.Thread(target=run, args=(i,)) 25 t.start() 26 27 #运行结果: 28 >>>1 29 run the thread: 0 30 >>>1 31 run the thread: 1 32 >>>1 33 run the thread: 2
- 定时器
1 #!/usr/bin/env python 2 # _*_ coding:utf-8 _*_ 3 __author__ = 'Administrator' 4 5 from threading import Timer 6 7 def hello(): 8 print("hello, world") 9 10 t = Timer(1, hello) 11 t.start()
进程
- 进程数据共享
方法一:Array
1 #!/usr/bin/env python 2 #coding=utf-8 3 __author__ = 'yinjia' 4 5 6 from multiprocessing import Process, Array, RLock 7 8 def Foo(lock,temp,i): 9 """ 10 将第0个数加100 11 """ 12 lock.acquire() 13 temp[0] = 100+i 14 for item in temp: 15 print(i,'----->',item) 16 lock.release() 17 18 lock = RLock() 19 temp = Array('i', [11, 22, 33, 44]) 20 21 for i in range(20): 22 p = Process(target=Foo,args=(lock,temp,i,)) 23 p.start()
方法二:manage.dict()共享数据
1 #!/usr/bin/env python 2 #coding=utf-8 3 __author__ = 'yinjia' 4 5 from multiprocessing import Process, Manager 6 7 manage = Manager() 8 dic = manage.dict() 9 10 11 def Foo(i): 12 dic[i] = 100 + i 13 print(dic) 14 print(dic.values()) 15 16 17 for i in range(2): 18 p = Process(target=Foo, args=(i,)) 19 p.start() 20 p.join()
- 进程池
进程池方法:
apply(func[, args[, kwds]]): 阻塞的执行,比如创建一个有3个线程的线程池,当执行时是创建完一个 执行完函数再创建另一个,变成一个线性的执行
apply_async(func[, args[, kwds[, callback]]]) : 它是非阻塞执行,同时创建3个线程的线程池,同时执行,只要有一个执行完立刻放回池子待下一个执行,并行的执行
close(): 关闭pool,使其不在接受新的任务。
terminate() : 结束工作进程,不在处理未完成的任务。
join() 主进程阻塞,等待子进程的退出, join方法要在close或terminate之后使用。
1 #!/usr/bin/env python 2 #coding=utf-8 3 __author__ = 'yinjia' 4 5 from multiprocessing import Pool 6 import time 7 8 def myFun(i): 9 time.sleep(2) 10 return i+100 11 12 def end_call(arg): 13 print("end_call",arg) 14 15 p = Pool(5) 16 #print(p.apply(myFun,(1,))) 17 #print(p.apply_async(func =myFun, args=(1,)).get()) 18 19 print(p.map(myFun,range(10))) 20 21 for i in range(10): 22 p.apply_async(func=myFun,args=(i,),callback=end_call) 23 24 print("end") 25 p.close() 26 p.join()
- 生产者&消费型
产生数据的模块,就形象地称为生产者;而处理数据的模块,就称为消费者。在生产者与消费者之间在加个缓冲区,我们形象的称之为仓库,生产者负责往仓库了进商 品,而消费者负责从仓库里拿商品,这就构成了生产者消费者模型。
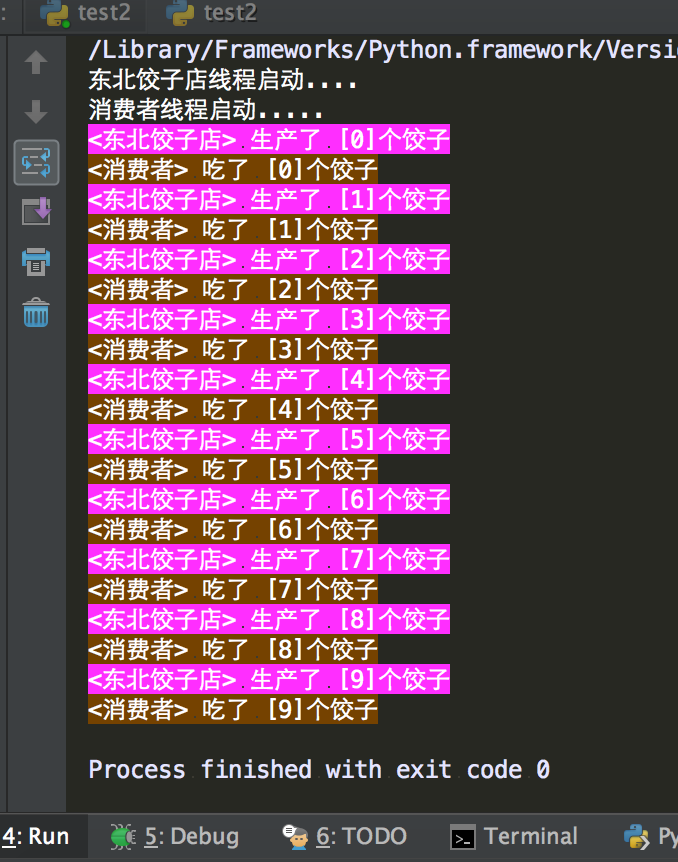
1 #!/usr/bin/env python 2 #coding=utf-8 3 __author__ = 'yinjia' 4 5 6 import queue 7 import threading,time 8 9 10 message = queue.Queue(10) 11 12 13 def producer(): 14 name = threading.current_thread().getName() 15 print(name + "线程启动....") 16 for i in range(10): 17 time.sleep(1) 18 print('�33[45m<%s> 生产了 [%s]个饺子�33[0m' % (name, i)) 19 message.put(name) 20 21 22 def consumer(): 23 name = threading.current_thread().getName() 24 print(name + "线程启动.....") 25 for i in range(10): 26 message.get() 27 print('�33[43m<%s> 吃了 [%s]个饺子�33[0m' % (name, i)) 28 29 30 if __name__ == '__main__': 31 32 p = threading.Thread(target=producer, name='东北饺子店') 33 c = threading.Thread(target=consumer, name='消费者') 34 p.start() 35 c.start()
运行结果:
协程
协程存在的意义:对于多线程应用,CPU通过切片的方式来切换线程间的执行,线程切换时需要耗时(保存状态,下次继续)。协程,则只使用一个线程,在一个线程中规定某个代码块执行顺序。
协程的适用场景:当程序中存在大量不需要CPU的操作时(IO),适用于协程;
- gevent
1 #!/usr/bin/env python 2 # _*_ coding:utf-8 _*_ 3 __author__ = 'Administrator' 4 5 import gevent 6 7 def foo(): 8 print('Running in foo') 9 gevent.sleep(0) 10 print('Explicit context switch to foo again') 11 12 def bar(): 13 print('Explicit context to bar') 14 gevent.sleep(0) 15 print('Implicit context switch back to bar') 16 17 gevent.joinall([ 18 gevent.spawn(foo), 19 gevent.spawn(bar), 20 ]) 21 22 #运行结果: 23 Running in foo 24 Explicit context to bar 25 Explicit context switch to foo again 26 Implicit context switch back to bar
- 遇到IO操作自动切换
1 #!/usr/bin/env python 2 # _*_ coding:utf-8 _*_ 3 4 from gevent import monkey; monkey.patch_all() 5 import gevent 6 import urllib.request 7 8 def f(url): 9 print('GET: %s' % url) 10 resp = urllib.request.urlopen(url) 11 data = resp.read() 12 print('%d bytes received from %s.' % (len(data), url)) 13 14 gevent.joinall([ 15 gevent.spawn(f, 'https://www.python.org/'), 16 gevent.spawn(f, 'https://www.baidu.com/'), 17 gevent.spawn(f, 'https://github.com/'), 18 ]) 19 20 #运行结果: 21 GET: https://www.python.org/ 22 GET: https://www.baidu.com/ 23 GET: https://github.com/ 24 227 bytes received from https://www.baidu.com/. 25 49273 bytes received from https://www.python.org/. 26 53756 bytes received from https://github.com/.
上下文管理
1 #!/usr/bin/env python 2 # _*_ coding:utf-8 _*_ 3 __author__ = 'Administrator' 4 5 import contextlib 6 7 @contextlib.contextmanager 8 def tag(name): 9 print("<%s>" % name) 10 yield 11 print("</%s>" % name) 12 13 with tag("h1"): 14 print("foo") 15 16 #运行结果: 17 <h1> 18 foo 19 </h1>
1 #!/usr/bin/env python 2 # _*_ coding:utf-8 _*_ 3 __author__ = 'Administrator' 4 5 import contextlib 6 7 @contextlib.contextmanager 8 def myopen(file_path,mode): 9 f = open(file_path,mode,encoding='utf-8') 10 try: 11 yield f 12 finally: 13 f.close() 14 with myopen('index.html','r') as file_obj: 15 for i in file_obj: 16 print(i)