前提
如果一不小心把字符转成utf8的格式,但是却产生了乱码。这个时候要么就是寻找其他的转码方式,要么就不想要了,直接过滤吧。
这里说的是直接过滤的办法。
参考链接
https://netvignettes.wordpress.com/2011/07/03/how-to-detect-encoding/
大概的代码解释
其实主要的思路就是对照这个表(不过貌似它也不是严格对照的),比如下面的代码就是对于bytes的数量
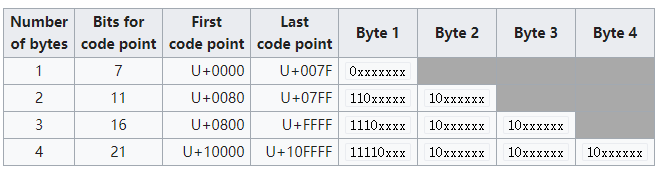
private static bool IsLead4(byte b) { return b >= 0xF0 && b < 0xF8; } private static bool IsLead3(byte b) { return b >= 0xE0 && b < 0xF0; } private static bool IsLead2(byte b) { return b >= 0xC0 && b < 0xE0; } private static bool IsExtendedByte(byte b) { return b > 0x80 && b < 0xC0; }
接下来就是主要一下特殊字符的边界情况
if (length >= 4) { var one = bytes[offset]; var two = bytes[offset + 1]; var three = bytes[offset + 2]; var four = bytes[offset + 3]; if (one == 0x2B && two == 0x2F && three == 0x76 && (four == 0x38 || four == 0x39 || four == 0x2B || four == 0x2F)) { return UTF7; } else if (one == 0xFE && two == 0xFF && three == 0x00 && four == 0x00) { return UTF32; } else if (four == 0xFE && three == 0xFF && two == 0x00 && one == 0x00) { throw new NotSupportedException("The byte order mark specifies UTF-32 in big endian order, which is not supported by .NET."); } } else if (length >= 3) { var one = bytes[offset]; var two = bytes[offset + 1]; var three = bytes[offset + 2]; if (one == 0xFF && two == 0xFE) { return Unicode; } else if (one == 0xFE && two == 0xFF) { return BigEndianUnicode; } else if (one == 0xEF && two == 0xBB && three == 0xBF) { return UTF8; } } if (length > 1) { // Look for a leading < sign: if (bytes[offset] == 0x3C) { if (bytes[offset + 1] == 0x00) { return Unicode; } else { return UTF8; } } else if (bytes[offset] == 0x00 && bytes[offset + 1] == 0x3C) { return BigEndianUnicode; } } if (IsUtf8(bytes)) { return UTF8; }
接下来就是测试
static void Main(string[] args) { string ch = "金"; string Ja = "らなくちゃ"; string Re = "фыввфывфывфв"; //byte[] Rom = {209,132,209,34,90,121,5,34,208}; //byte[] Rom = { 100,200,3,4,5,6,7,8,9,0,0 }; byte[] Rom = { 187, 170, 200,253,194,183,211,201,198,247,95,53,71,51,54,}; //byte[] Rom = {} byte[] byteArrayUTF8 = UTF8.GetBytes(Ja); //byte[] byteArrayDefault = Encoding.Default.GetBytes(Re); string Name = Encoding.UTF8.GetString(Rom,0,(int)Rom.Length); var y = GetTextEncoding(Rom); }
全部代码
using System; using System.Text; using static System.Text.Encoding; namespace ConsoleApp1 { class Program { /// <summary> /// Determines whether the bytes in this buffer at the specified offset represent a UTF-8 multi-byte character. /// </summary> /// <remarks> /// It is not guaranteed that these bytes represent a sensical character - only that the binary pattern matches UTF-8 encoding. /// </remarks> /// <param name="bytes">This buffer.</param> /// <param name="offset">The position in the buffer to check.</param> /// <param name="length">The number of bytes to check, of 4 if not specified.</param> /// <returns>The rank of the UTF</returns> public static MultibyteRank GetUtf8MultibyteRank(byte[] bytes, int offset = 0, int length = 4) { if (bytes == null) { throw new ArgumentNullException("bytes"); } if (offset < 0 || offset > bytes.Length) { throw new ArgumentOutOfRangeException("offset", "Offset is out of range."); } else if (length < 0 || length > 4) { throw new ArgumentOutOfRangeException("length", "Only values 1-4 are valid."); } else if ((offset + length) > bytes.Length) { throw new ArgumentOutOfRangeException("offset", "The specified range is outside of the specified buffer."); } // Possible 4 byte sequence if (length > 3 && IsLead4(bytes[offset])) { if (IsExtendedByte(bytes[offset + 1]) && IsExtendedByte(bytes[offset + 2]) && IsExtendedByte(bytes[offset + 3])) { return MultibyteRank.Four; } } // Possible 3 byte sequence else if (length > 2 && IsLead3(bytes[offset])) { if (IsExtendedByte(bytes[offset + 1]) && IsExtendedByte(bytes[offset + 2])) { return MultibyteRank.Three; } } // Possible 2 byte sequence else if (length > 1 && IsLead2(bytes[offset]) && IsExtendedByte(bytes[offset + 1])) { return MultibyteRank.Two; } if (bytes[offset] < 0x80) { return MultibyteRank.One; } else { return MultibyteRank.None; } } private static bool IsLead4(byte b) { return b >= 0xF0 && b < 0xF8; } private static bool IsLead3(byte b) { return b >= 0xE0 && b < 0xF0; } private static bool IsLead2(byte b) { return b >= 0xC0 && b < 0xE0; } private static bool IsExtendedByte(byte b) { return b > 0x80 && b < 0xC0; } public enum MultibyteRank { None = 0, One = 1, Two = 2, Three = 3, Four = 4 } public static bool IsUtf8(byte[] bytes, int offset = 0, int? length = null) { if (bytes == null) { throw new ArgumentNullException("bytes"); } length = length ?? (bytes.Length - offset); if (offset < 0 || offset > bytes.Length) { throw new ArgumentOutOfRangeException("offset", "Offset is out of range."); } else if (length < 0) { throw new ArgumentOutOfRangeException("length"); } else if ((offset + length) > bytes.Length) { throw new ArgumentOutOfRangeException("offset", "The specified range is outside of the specified buffer."); } var bytesRemaining = length.Value; while (bytesRemaining > 0) { var rank = GetUtf8MultibyteRank(bytes, offset, Math.Min(4, bytesRemaining)); if (rank == MultibyteRank.None) { return false; } else { var charsRead = (int)rank; offset += charsRead; bytesRemaining -= charsRead; } } return true; } /// <summary> /// Uses various discovery techniques to guess the encoding used for a byte buffer presumably containing text characters. /// </summary> /// <remarks> /// Note that this is only a guess and could be incorrect. Be prepared to catch exceptions while using the <see cref="Encoding.Decoder"/> returned by /// the encoding returned by this method. /// </remarks> /// <param name="bytes">The buffer containing the bytes to examine.</param> /// <param name="offset">The offset into the buffer to begin examination, or 0 if not specified.</param> /// <param name="length">The number of bytes to examine.</param> /// <returns>An encoding, or <see langword="null"> if one cannot be determined.</returns> public static Encoding GetTextEncoding(byte[] bytes, int offset = 0, int? length = null) { if (bytes == null) { throw new ArgumentNullException("bytes"); } length = length ?? bytes.Length; if (offset < 0 || offset > bytes.Length) { throw new ArgumentOutOfRangeException("offset", "Offset is out of range."); } if (length < 0 || length > bytes.Length) { throw new ArgumentOutOfRangeException("length", "Length is out of range."); } else if ((offset + length) > bytes.Length) { throw new ArgumentOutOfRangeException("offset", "The specified range is outside of the specified buffer."); } // Look for a byte order mark: if (length >= 4) { var one = bytes[offset]; var two = bytes[offset + 1]; var three = bytes[offset + 2]; var four = bytes[offset + 3]; if (one == 0x2B && two == 0x2F && three == 0x76 && (four == 0x38 || four == 0x39 || four == 0x2B || four == 0x2F)) { return UTF7; } else if (one == 0xFE && two == 0xFF && three == 0x00 && four == 0x00) { return UTF32; } else if (four == 0xFE && three == 0xFF && two == 0x00 && one == 0x00) { throw new NotSupportedException("The byte order mark specifies UTF-32 in big endian order, which is not supported by .NET."); } } else if (length >= 3) { var one = bytes[offset]; var two = bytes[offset + 1]; var three = bytes[offset + 2]; if (one == 0xFF && two == 0xFE) { return Unicode; } else if (one == 0xFE && two == 0xFF) { return BigEndianUnicode; } else if (one == 0xEF && two == 0xBB && three == 0xBF) { return UTF8; } } if (length > 1) { // Look for a leading < sign: if (bytes[offset] == 0x3C) { if (bytes[offset + 1] == 0x00) { return Unicode; } else { return UTF8; } } else if (bytes[offset] == 0x00 && bytes[offset + 1] == 0x3C) { return BigEndianUnicode; } } if (IsUtf8(bytes)) { return UTF8; } else { // Impossible to tell. return null; } } static void Main(string[] args) { string ch = "金"; string Ja = "らなくちゃ"; string Re = "фыввфывфывфв"; //byte[] Rom = {209,132,209,34,90,121,5,34,208}; //byte[] Rom = { 100,200,3,4,5,6,7,8,9,0,0 }; byte[] Rom = { 187, 170, 200,253,194,183,211,201,198,247,95,53,71,51,54,}; //byte[] Rom = {} byte[] byteArrayUTF8 = UTF8.GetBytes(Ja); //byte[] byteArrayDefault = Encoding.Default.GetBytes(Re); string Name = Encoding.UTF8.GetString(Rom,0,(int)Rom.Length); var y = GetTextEncoding(Rom); } } }