高并发高可用架构演进 :
数据库、应用于一体➡数据库与应用分离➡数据库根据业务将表分到不同的库中➡同一张表进行读写分离➡表中数据根据需求分表
其中Mycat数据库中间件起到了读写分离,分库,分表的作用
1.解决的问题
读写分离 (Mysql主从复制)/分库分表 ➡ 多数据源 ➡ Java程序需要进行多个数据源的切换 / Java程序与MySQL紧耦合 —— Java程序与数据库解耦
高可用 ➡ 集群与容错机制 高并发 ➡ 分库+分表 —— 解决高并发高可用对数据库的压力
2.怎样解决
Mycat通过配置文件搭建一个逻辑数据库,向外暴露一个Mycat的访问接口[解耦] ,而底层通过多个数据节点DataNode(一个DataNode对应一个DataHost,而一个DataHost保证其高可用搭建读写分离集群writeHost,readHost(一主一从/双主双从)) [高可用],通过<table dataHost="">节点将不同业务的表分发到不同的库中,分散数据库压力,而相同表中数据量大时会遇到瓶颈,所以此时将表中数据根据<table rule="">根据分片规则分发到多个表中(不同库的不同的表),提高查询等的效率[高并发]
而所有这些操作都在Mycat内部解决,对于Java程序来说完全透明,和平常一样进行SQL的传输即可,Mycat接到SQL语句,对其进行拦截,后根据配置的一系列分库分表规则等进行解析SQL,分析SQL(分片分析,缓存分析,路由分析......),分发到后台的物理数据库,得到结果对结果进行整合后传回
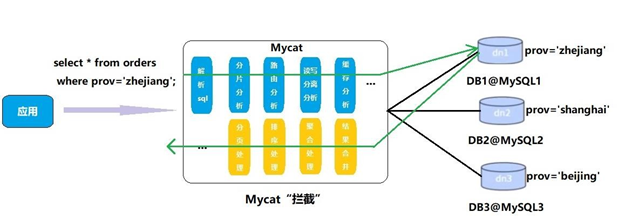
3.如何使用
开发步骤 : 分析业务制定出分片规则等后配置好配置文件 --> 启动对应的物理数据库 -->使用Mycat执行建表操作
- 读写分离 ➡同一个DataHost的主从复制

<dataNode name="dn1" dataHost="host1" database="testdb" /> <dataHost name="host1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100" > <heartbeat>select user()</heartbeat> <!-- can have multi write hosts --> <writeHost host="hostM1" url="192.168.140.128:3306" user="root" password="123123"> <!-- can have multi read hosts --> <readHost host="hostS1" url="192.168.140.127:3306" user="root" password="123123" />
</writeHost>
<writeHost host="hostM2" url="192.168.140.126:3306" user="root" password="123123"> <!-- can have multi read hosts --> <readHost host="hostS2" url="192.168.140.125:3306" user="root" password="123123" /> </writeHost> </dataHost> …
负载均衡类型,目前的取值有4 种:
(1) balance="0", 不开启读写分离机制,所有读操作都发送到当前可用的 writeHost 上。
(2) balance="1",全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且 M1 与 M2 互为主备),正常情况下,M2,S1,S2 都参与 select 语句的负载均衡。
(3) balance="2",所有读操作都随机的在 writeHost、readhost 上分发。
(4) balance="3",所有读请求随机的分发到 readhost 执行,writerHost 不负担读压力
#writeType="0": 所有写操作发送到配置的第一个writeHost,第一个挂了切到还生存的第二个#writeType="1",所有写操作都随机的发送到配置的 writeHost,1.5 以后废弃不推荐#writeHost,重新启动后以切换后的为准,切换记录在配置文件中:dnindex.properties 。
#switchType="1": 1 默认值,自动切换。
# -1 表示不自动切换
# 2 基于 MySQL 主从同步的状态决定是否切换。
- 分库 ➡ 表分到不同的库中
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"> <!--制定规则,customer表分到dataNode2库中-->
<table name="customer" dataNode="dn2" ></table> </schema>
<dataNode name="dn1" dataHost="host1" database="orders" /> <dataNode name="dn2" dataHost="host2" database="orders" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <!-- can have multi write hosts --> <writeHost host="hostM1" url="192.168.140.128:3306" user="root" password="123123">
</writeHost> </dataHost> <dataHost name="host2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <!-- can have multi write hosts --> <writeHost host="hostM2" url="192.168.140.127:3306" user="root" password="123123"> </writeHost> </dataHost>
- 分表 ➡ 数据分到不同的表中(不同的表又在不同的库中) ➡分表基于分库,但多张表是同一种表
schema.xml
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"> <!--制定规则,customer表分到dn1,dn2两个库中,并且其中的数据根据mode_rule规则分配--> <table name="customer" dataNode="dn1,dn2" rule="mod_rule"></table> </schema>
rule.xml #在 rule 配置文件里新增分片规则 mod_rule,并指定规则适用字段为 customer_id, #还有选择分片算法mod-long(对字段求模运算),customer_id 对两个节点求模,根据结果分片 #配置算法 mod-long 参数 count 为 2,两个节点 <tableRule name="mod_rule"> <rule> <columns>customer_id</columns> <algorithm>mod-long</algorithm> </rule> </tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod"> <!-- how many data nodes --> <property name="count">2</property> </function>
-
- E-R表 : 主表进行了分片,其子表也需要根据关联字段进行分片
<table name="orders" dataNode="dn1,dn2" rule="mod_rule" > <childTable name="orders_detail" primaryKey="id" joinKey="order_id" parentKey="id" /> </table>
-
- 全局表 : 全局表数据量少,变动不频繁,且很多表都需要其 ➡ 通过数据冗余实现其可以与任意一张表进行关联 ➡ 多个分库中都创建一个全局表,且数据变动一致
<table name="orders" dataNode="dn1,dn2" rule="mod_rule" > <childTable name="orders_detail" primaryKey="id" joinKey="order_id" parentKey="id" /> </table> <table name="dict_order_type" dataNode="dn1,dn2" type="global" ></table>
-
- 分片规则
- 取模 根据物理数据库数量进行取模轮询分配
- 分片枚举 适用于根据固定数量固定值进行分配
- 范围约定(值/日期)
- 分片规则
-
- 全局序列
表中数据ID自增带来的问题 : 进行了分表,每个表中ID进行自增,会导致出现重复ID,所以,此时自增ID不可取,MyCat对这种情况做了几种解决方案
1) 本地文件
MyCat本地保存一个文件,其中记录ID值,每次新增数据时从此文件中取
优 : 本地文件读取效率高
缺 : 当此台Mycat宕机后,启用另一台Mycat时无法获取之前那个本地文件中的ID值,也就无法决定接下来的ID值
2) 数据库方式
在一个数据库中维护一个ID表,每次新增时查此表,但每次新增都查表,会很浪费IO效率极低,所以Mycat会预加载一部分到内存中,这样大部分序列都是在内存年中完成的。这样用完之后再向数据库请求一段,当此台MyCat宕机后,另一台MyCat重新请求一段序列,而之前的序列不管用完或者没用完都不会再管,这样就不会产生冲突
优 : 将ID值放到了数据库中,与MyCat状态无关 , 避免了MyCat宕机带来的问题
以一段序列加载进内存的策略来进行ID值分配,提高了效率,减少了IO
3) 时间戳方式
时间戳避免了ID冲突问题,但此ID值过长,浪费空间
4)自定义ID序列
Java程序中新增时根据业务指定ID
利用Redis单线程原子性incr来生成序列
缺 : 这些自定义ID都需要在Java代码中指定ID实现,又增加了耦合度,所以不推荐