最近有不少在微博上谈论BOM头问题,BOM头会造成页面展示的乱码,xml分析出现问题。而我恰巧遇到一种情况,在wml页面中如果加上BOM头,PC浏览器(IE,火狐)和手机浏览器(UC)都很正常,而如果去除BOM头,则手机端正常,PC端不正常。为此,对BOM头和编码做些简单的研究。
1、什么是BOM头
对于使用windows的记事本编辑文本,在采用UTF-8编码保存的时候,会给文本加上三个看不见的字节 0xEF 0xBB 0xBF,有些文章把这三个字节称为三个字符 是不对的,实际上这三个字节如果按照UTF-8解码,表示的是一个字符,这个字符表示没有显示,又不同于空格,我们先把这三个字节做一下转换
| 编码 | UTF8编码16进制 | unicode编码16进制 | unicode编码10进制 |
| 值 | EFBBBF | FEFF | 65279 |
通过网上根据编码查看汉字的工具查看确认一下(http://www.mytju.com/classcode/tools/encode_utf8.asp)
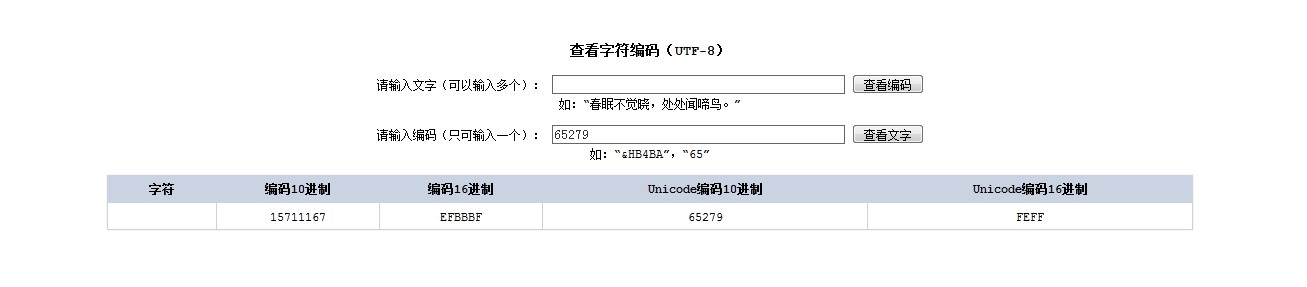
可以看出来,这是一个没有任何显示的字符,那么这样一个字符的用处是什么呢?实际上这个字符被windows的文本编辑器用来作为字符编码区分的标记,在windows系统下,一旦发现文本的前三个字节是EFBBBF,则确认整个文本是按照utf-8做的编码。
2、BOM头的一般处理过程
a、linux下查看文件是否有BOM头的办法
一般的linux服务器带有一个xxd命令,可以以16进制的形式打开查看。
b、查看项目下面哪些文件拥有bom头
方法很多,网上一般提供grep -r -I -l $'^xEFxBBxBF' ./ 也就是在一个项目下,循环项目里面的文件,不区分大小写,查看是否已十六进制下的EFBBBF开头的文件,输出文件名信息
c、去除bom头
单个文件去除bom头可以用Vi打开文件,set nobomb后保存一下就可以去除,同理如果想加bom头,set bomb即可, 而如果去除某个项目下所有存在bom头的文件,一般需要写脚本来实现,在php下面
a1、循环读取每一个文件
b1、利用substr()查看文件的前三个字节,将字节转成十进制查看
"EF" => 239
"BB" => 187
"BF" => 191
c1、如果查看到前三个字节是BOM头,则用substr()截取之后的文字写入