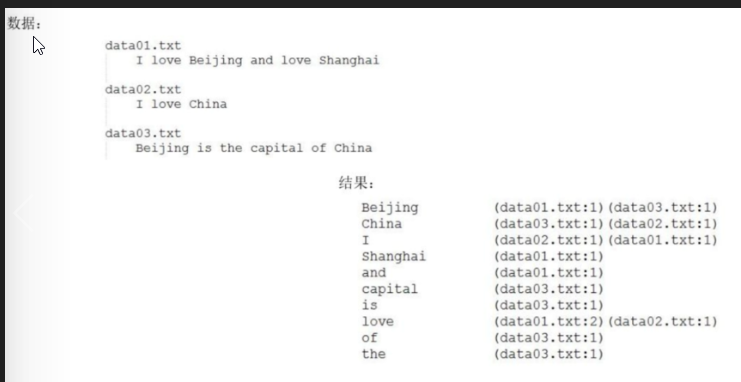
MapReduce倒排索引

代码:
MyMapper.java
1 package dpsy; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.io.LongWritable; 6 import org.apache.hadoop.io.Text; 7 import org.apache.hadoop.mapreduce.Mapper; 8 import org.apache.hadoop.mapreduce.lib.input.FileSplit; 9 10 public class MyMapper extends Mapper<LongWritable, Text, Text, Text> { 11 12 @Override 13 protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context) 14 throws IOException, InterruptedException { 15 // TODO 自动生成的方法存根 16 String thisLine=value.toString(); 17 String words[]=thisLine.split(" "); 18 for (String word : words) { 19 FileSplit fileSplit=(FileSplit)context.getInputSplit(); 20 String file=fileSplit.getPath().getName(); 21 context.write(new Text(word+"&"+file), new Text("1")); 22 } 23 } 24 25 26 27 }
MyCombiner.java
package dpsy; import java.io.IOException; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class MyCombiner extends Reducer<Text, Text, Text, Text> { @Override protected void reduce(Text arg0, Iterable<Text> arg1, Reducer<Text, Text, Text, Text>.Context arg2) throws IOException, InterruptedException { // TODO 自动生成的方法存根 int sum=0; for (Text text : arg1) { sum+=Integer.parseInt(text.toString()); } String s[]=arg0.toString().split("&"); String outKey=s[0]; String outValue="("+s[1]+":"+sum+")"; arg2.write(new Text(outKey), new Text(outValue)); } }
MyReducer.java
package dpsy; import java.io.IOException; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class MyReducer extends Reducer<Text, Text, Text, Text> { @Override protected void reduce(Text arg0, Iterable<Text> arg1, Reducer<Text, Text, Text, Text>.Context arg2) throws IOException, InterruptedException { // TODO 自动生成的方法存根 StringBuffer outValue=new StringBuffer(""); for (Text arg : arg1) { outValue.append(arg.toString()); } arg2.write(arg0, new Text(outValue.toString())); } }
MyJob.java
package dpsy; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; public class MyJob extends Configured implements Tool{ public static void main(String[] args) throws Exception { System.setProperty("hadoop.home.dir", "E:\hadoop"); MyJob myJob=new MyJob(); ToolRunner.run(myJob, null); } public int run(String[] args) throws Exception { // TODO Auto-generated method stub Configuration conf=new Configuration(); conf.set("fs.default.name", "hdfs://192.168.137.11:9000"); Job job=Job.getInstance(conf); job.setJarByClass(MyJob.class); job.setMapperClass(MyMapper.class); job.setCombinerClass(MyCombiner.class); job.setReducerClass(MyReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); FileInputFormat.addInputPath(job, new Path("/hadoop/dpsy")); FileOutputFormat.setOutputPath(job, new Path("/dpsyResult")); job.waitForCompletion(true); return 0; } }
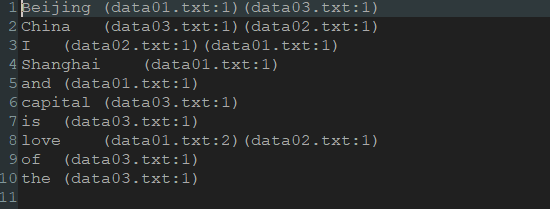
结果: