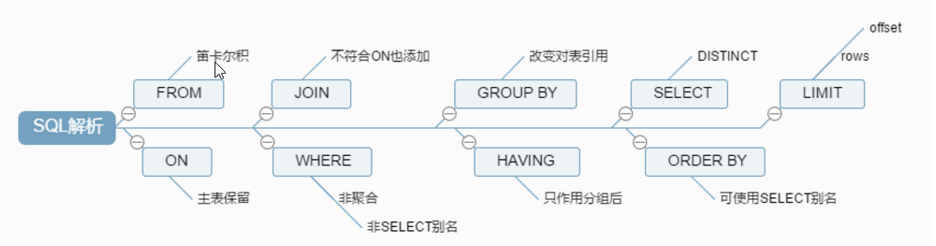
前言:
1.NULL+任何值都为NULL ;不区分大小写; sql执行的时候是一行一行执行的
支持跨库操作:库名.表名
MySQL服务的启动和停止
方式一:计算机——右击管理——服务
方式二:通过管理员身份运行
net start 服务名(启动服务)
net stop 服务名(停止服务)
MySQL服务的登录和退出
方式一:通过mysql自带的客户端
只限于root用户
方式二:通过windows自带的客户端
登录:
mysql 【-h主机名 -P端口号 】-u用户名 -p密码
退出:
exit或ctrl+C
MySQL的常见命令
1.查看当前所有的数据库
show databases;
2.打开指定的库
use 库名
3.查看当前库的所有表
show tables;
4.查看其它库的所有表
show tables from 库名;
5.创建表
create table 表名(
列名 列类型,
列名 列类型,
。。。
);
6.查看表结构
desc 表名;
7.查看服务器的版本
方式一:登录到mysql服务端
select version();
方式二:没有登录到mysql服务端
mysql --version
或
mysql --V
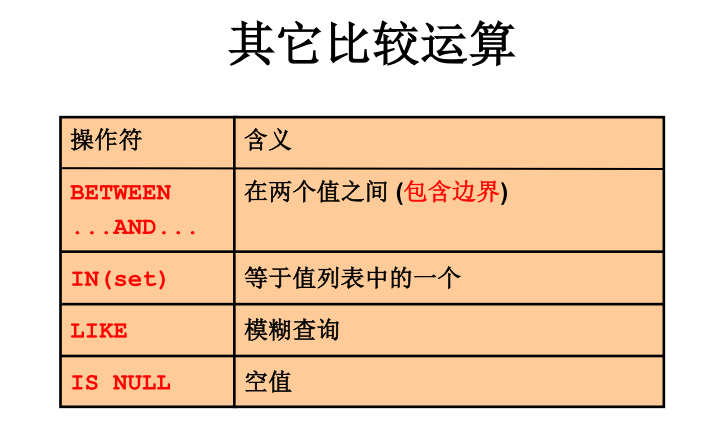
过滤和排序数据


【注】“xxx=null”不能用于判断是不是空值,要用 IS NUll
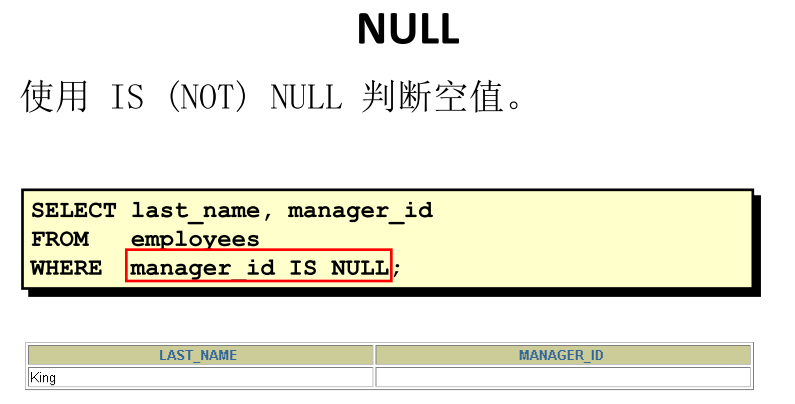
is null VS <=>
| 普通类型的数值 | null值 | 可读性 | |
|---|---|---|---|
| is null | × | √ | √ |
| <=> | √ | √ | × |




七种join理论
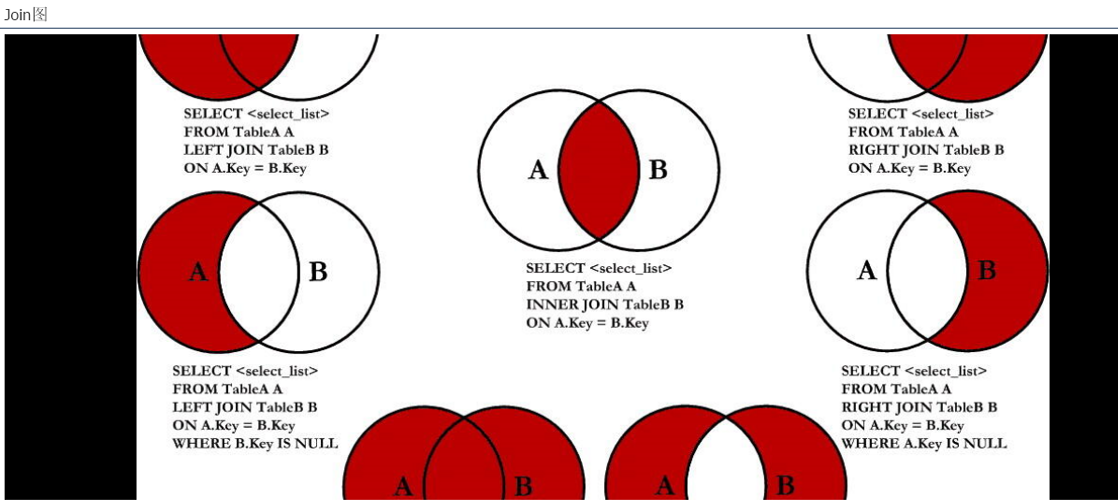
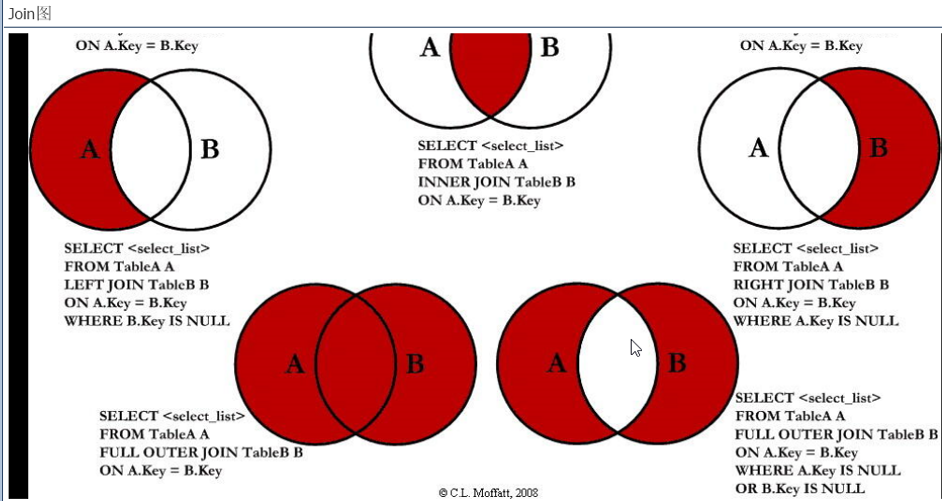
↑
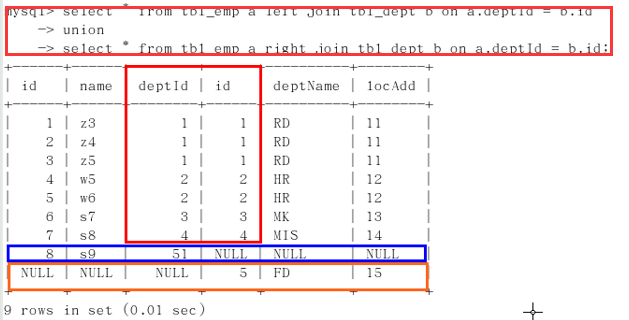
MySQL不支持这种写法,用union(天生去重)
索引(不适合增、删、改频繁的表)


varchar(64) 和 varchar(255) 区别真的很大吗?
大家都知道用 varchar 比用 char 类型更省空间(不过性能略有下降),相对于定长的 char ,varchar 存储分为两部分:varchar字段长度 = 字符串长度值 + 实际数据长度 N。
字符串长度值视实际数据长度,需占用 1 或 2 个字节存储。所以,我们得出:
- 当实际数据长度 <= 255 时,varchar字段长度 = 1 + N;
- 当实际数据长度 > 255 时,varchar字段长度 = 2 + N
因此,在设计数据表时,varchar(64) 和 varchar(255) 在实际应用中占用存储是一样的;varchar(256) 和 varchar(50000) 也是一样的。但是数值越大越占内存
那么问题来了,为什么不在设计时就尽可能把最大长度设置大一些,免得未来长度不够惹麻烦呢?比如,用户名能用 varchar(200) 就不必用 varchar(20),存储稍大一些字符串的字段,能用 varchar(2000) 就不必斤斤计较用 varchar(256)。
这么长的空间,能存储多少汉字呢?如果采用 UTF-8 编码存储,每个汉字占用 3 个字节;如果采用可以放表情的 utf8mb4,每个汉字占用 4字节。
常见函数
- 【网查】MySQL之CONCAT()的用法
mysql CONCAT()函数用于将多个字符串连接成一个字符串,是最重要的mysql函数之一,下面就将为您详细介绍mysql CONCAT()函数,供您参考
- mysql CONCAT(str1,str2,…)
返回结果为连接参数产生的字符串。如有任何一个参数为NULL ,则返回值为 NULL。或许有一个或多个参数。 如果所有参数均为非二进制字符串,则结果为非二进制字符串。 如果自变量中含有任一二进制字符串,则结果为一个二进制字符串。一个数字参数被转化为与之相等的二进制字符串格式;若要避免这种情况,可使用显式类型 cast, 例如: SELECT CONCAT(CAST(int_col AS CHAR), char_col)
mysql> SELECT CONCAT(’My’, ‘S’, ‘QL’);
-> ‘MySQL’
mysql> SELECT CONCAT(’My’, NULL, ‘QL’);
-> NULL
mysql> SELECT CONCAT(14.3);
-> ‘14.3′
- mysql CONCAT_WS(separator,str1,str2,…)
CONCAT_WS() 代表 CONCAT With Separator ,是CONCAT()的特殊形式。 第一个参数是其它参数的分隔符。分隔符的位置放在要连接的两个字符串之间。分隔符可以是一个字符串,也可以是其它参数。如果分隔符为 NULL,则结果为 NULL。函数会忽略任何分隔符参数后的 NULL 值。
mysql> SELECT CONCAT_WS(’,',’First name’,'Second name’,'Last Name’);
-> ‘First name,Second name,Last Name’
mysql> SELECT CONCAT_WS(’,',’First name’,NULL,’Last Name’);
-> ‘First name,Last Name’
#mysql CONCAT_WS()不会忽略任何空字符串。 (然而会忽略所有的 NULL)。
- 字符函数
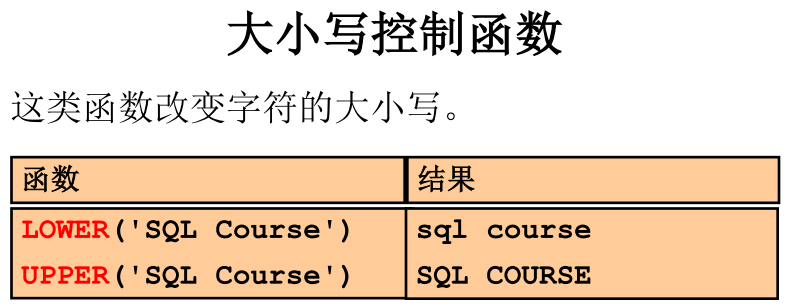
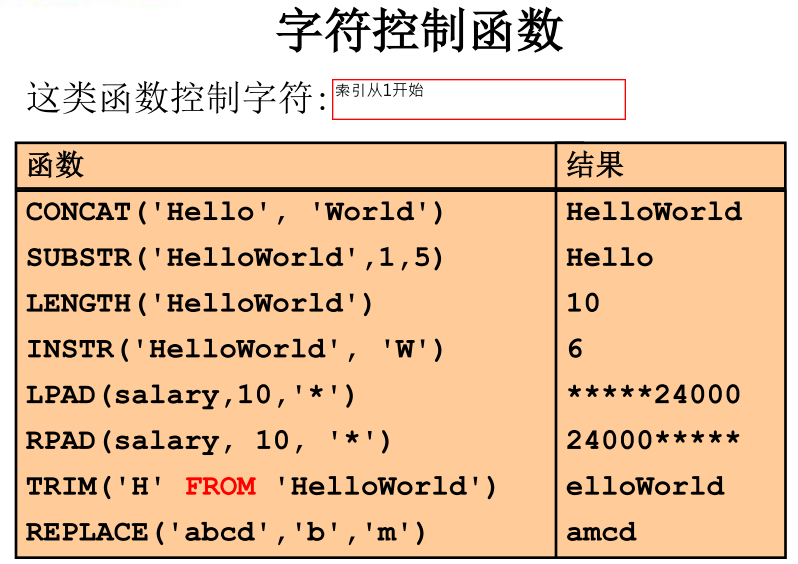
【附】
- 数字函数

【附】
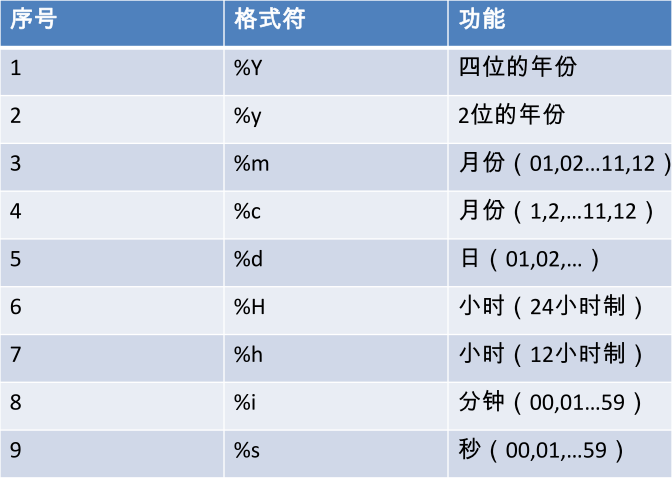
- 日期函数
now:返回当前日期+时间
year:返回年
month:返回月
day:返回日
date_format:将日期转换成字符
curdate:返回当前日期
str_to_date:将字符转换成日期
curtime:返回当前时间
hour:小时
minute:分钟
second:秒
datediff:返回两个日期相差的天数
monthname:以英文形式返回月


- 流程控制函数
①if(条件表达式,表达式1,表达式2):如果条件表达式成立,返回表达式1,否则返回表达式2
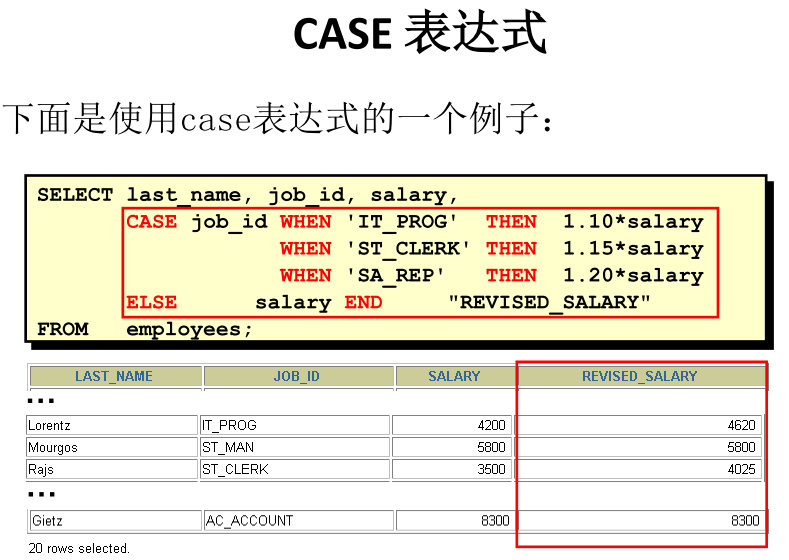
②case情况1
case 变量或表达式或字段
when 常量1 then 值1
when 常量2 then 值2
...
else 值n
end
③case情况2
case
when 条件1 then 值1
when 条件2 then 值2
...
else 值n
end

- 分组函数(忽略null值)




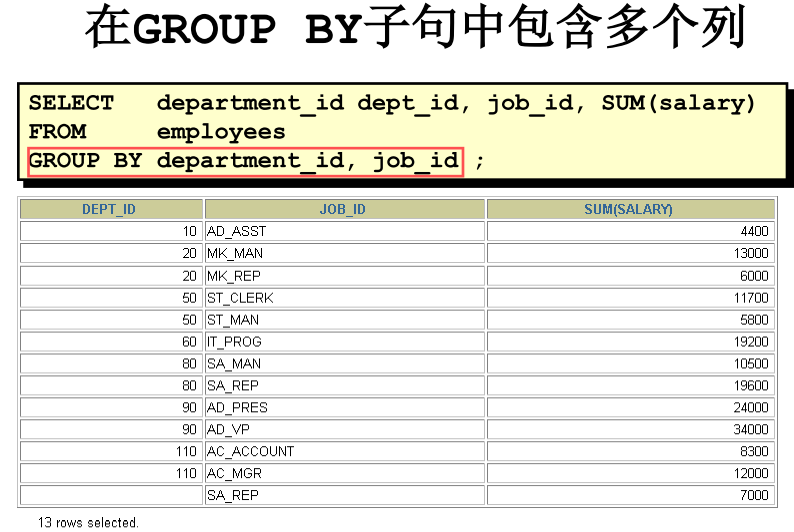
- 分组数据:GROUP BY
- 按字段分组
- 按表达式或函数分组




【注】表中本来就有的字段的Condition,放在where中
分组之后才有的字段的Condition,放在having中
即
使用关键字 筛选的表 位置
分组前筛选 where 原始表 group by的前面
分组后筛选 having 分组后的结果 group by 的后面

- 多表查询
一、传统模式下的连接 :等值连接——非等值连接
1.等值连接的结果 = 多个表的交集
2.n表连接,至少需要n-1个连接条件
3.多个表不分主次,没有顺序要求
4.一般为表起别名,提高阅读性和性能
等值连接:
SELECT `job_title`,COUNT(*)
FROM jobs j,employees e
WHERE e.`job_id`=j.`job_id`
GROUP BY `job_title`
ORDER BY COUNT(*) DESC;
/*
Q:选择city在Toronto工作员工的`last_name`,`job_id`,d.`department_id`,`department_name`
涉及到三个表时,
e.`department_id`=d.`department_id`
d.`location_id`=l.`location_id`,至少需要这两个连接条件,以此类推。
*/
SELECT `last_name`,`job_id`,d.`department_id`,`department_name`
FROM `employees` e,`departments` d,`locations` l
WHERE e.`department_id`=d.`department_id`
AND d.`location_id`=l.`location_id`
AND l.`city`='Toronto';
非等值连接:
SELECT salary,`grade_level`
FROM `employees`,`job_grades` g
WHERE salary BETWEEN g.`lowest_sal` AND g.`highest_sal`
AND g.`grade_level`='A';
- 自连接
- 案例:查询员工名和直接上级的名称
SELECT e.`employee_id`,e.`last_name` 员工,d.`employee_id`,d.`last_name` 领导
FROM `employees` e,`employees` d
WHERE e.`manager_id`=d.`employee_id`
二、【推荐】sql99语法:通过join关键字实现连接
见:七种join理论(Inner可以省略)
含义:1999年推出的sql语法
支持:
等值连接、非等值连接 (内连接)
外连接
交叉连接
语法:
select 字段,...
from 表1
【inner|left outer|right outer|cross】join 表2 on 连接条件
【inner|left outer|right outer|cross】join 表3 on 连接条件
【where 筛选条件】
【group by 分组字段】
【having 分组后的筛选条件】
【order by 排序的字段或表达式】
好处:语句上,连接条件和筛选条件实现了分离,简洁明了!
【案例】:查询员工名和直接上级的名称
SELECT e.last_name,m.last_name
FROM employees e
JOIN employees m ON e.`manager_id`=m.`employee_id`;
-- JOIN ON 可以用多次
SELECT `last_name`,`department_name`,`job_title`
FROM `employees` e
INNER JOIN `departments` d ON e.`department_id`=d.`department_id`
INNER JOIN `jobs` j ON e.`job_id`=j.`job_id`
ORDER BY `department_name` DESC
- 子查询
1、子查询都放在小括号内
2、子查询可以放在from后面、select后面、where后面、having后面,但一般放在条件的右侧
3、子查询优先于主查询执行,主查询使用了子查询的执行结果
4、子查询根据查询结果的行数不同分为以下两类:
① 单行子查询
结果集只有一行
一般搭配单行操作符使用:> < = <> >= <=
非法使用子查询的情况:
a、子查询的结果为一组值
b、子查询的结果为空
② 多行子查询
结果集有多行
一般搭配多行操作符使用:any、all、in、not in
in: 属于子查询结果中的任意一个就行
any和all往往可以用其他查询代替
【例①:单行子查询】
SELECT *
FROM `employees`
WHERE salary>(
SELECT `salary`
FROM `employees`
WHERE `last_name`='Abel'
);
【例②:多行子查询】
【案例一:返回location_id是1400或1700的部门中的所有员工姓名】
SELECT `last_name`
FROM `employees`
WHERE `department_id` IN(
SELECT `department_id`
FROM `departments`
WHERE `location_id`IN (1400,1700)
);
【案例二】
SELECT employee_id, last_name, job_id, salary
FROM employees
WHERE salary < ANY
(
SELECT salary
FROM employees
WHERE job_id = 'IT_PROG'
)
AND job_id <> 'IT_PROG';
---------------------------------- 等价于
SELECT employee_id, last_name, job_id, salary
FROM employees
WHERE salary <
(
SELECT MAX(salary)
FROM employees
WHERE job_id = 'IT_PROG'
)
AND job_id <> 'IT_PROG';
【案例三(select后面):查询每个部门的员工个数】
-- 还可以用这种双select的方式
SELECT d.*,
(
SELECT COUNT(*)
FROM `employees` e
WHERE e.`department_id`=d.`department_id`
) 个数
FROM `departments` d;
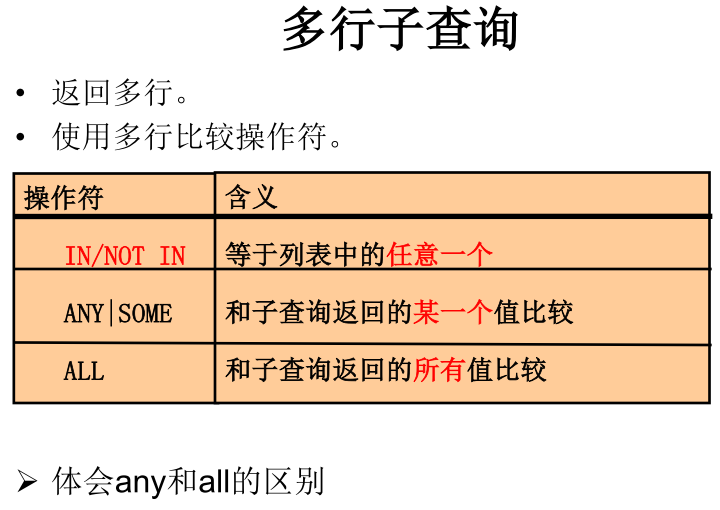
【案例四(from后面):查询每个部门的平均工资的工资等级】
-- 将子查询结果起一个别名(充当一张表)
SELECT avg_dep.*,j.`grade_level`
FROM (
SELECT AVG(salary) ag,`department_id`
FROM `employees` e
GROUP BY `department_id`
) avg_dep
JOIN `job_grades` j
ON avg_dep.ag BETWEEN j.`lowest_sal` AND j.`highest_sal`;
- 分页查询
语法:
select 字段|表达式,...
from 表
【where 条件】
【group by 分组字段】
【having 条件】
【order by 排序的字段】
limit 【起始的条目索引,】条目数;
特点:
1.起始条目索引从0开始
2.limit子句放在查询语句的最后
3.公式:select * from 表 limit (page-1)*sizePerPage,sizePerPage
假如:
每页显示条目数sizePerPage
要显示的页数 page
【案例:各个部门中,最高工资中最低的那个部门的最低工资是多少】
SELECT MAX(salary) sal,`department_id`
FROM `employees`
GROUP BY `department_id`
ORDER BY sal
LIMIT 1;
- 联合查询
语法:
select 字段|常量|表达式|函数 【from 表】 【where 条件】 union 【all】
select 字段|常量|表达式|函数 【from 表】 【where 条件】 union 【all】
select 字段|常量|表达式|函数 【from 表】 【where 条件】 union 【all】
.....
select 字段|常量|表达式|函数 【from 表】 【where 条件】
特点:
1、多条查询语句的查询的列数必须是一致的
2、多条查询语句的查询的列的类型要相同
3、union代表去重,union all代表不去重
DML语言
插入
语法:
insert into 表名(字段名,...)
values(值1,...);
特点:
1、字段类型和值类型一致或兼容,而且一一对应
2、可以为空的字段,可以不用插入值,或用null填充
3、不可以为空的字段,必须插入值
4、字段个数和值的个数必须一致
5、字段可以省略,但默认所有字段,并且顺序和表中的存储顺序一致
【注意:可以一次性插多个】
INSERT INTO admin(username,`password`)
VALUES('john1', '0000'),('lily', '0000'),('rose', '0000'),('jack', '0000'),('tom', '0000');
修改
修改单表语法:
update 表名 set 字段=新值,字段=新值
【where 条件】
修改多表语法:
update 表1 别名1,表2 别名2
set 字段=新值,字段=新值
where 连接条件
and 筛选条件
删除
方式1:delete语句
单表的删除: ★
delete from 表名 【where 筛选条件】
多表的删除:
delete 别名1,别名2
from 表1 别名1,表2 别名2
where 连接条件
and 筛选条件;
方式2:truncate语句
truncate table 表名
两种方式的区别【面试题】
#1.truncate不能加where条件,而delete可以加where条件
#2.truncate的效率高一丢丢
#3.truncate 删除带自增长的列的表后,如果再插入数据,数据从1开始
#delete 删除带自增长列的表后,如果再插入数据,数据从上一次的断点处开始
#4.truncate删除不能回滚,delete删除可以回滚
DDL语句
- 库和表的管理
- 库的管理:
一、创建库
create database 库名
二、删除库
drop database 库名
- 表的管理:
#1.创建表
CREATE TABLE IF NOT EXISTS stuinfo(
stuId INT,
stuName VARCHAR(20),
gender CHAR,
bornDate DATETIME
);
-- 查看该表
DESC studentinfo;
#2.修改表 alter
语法:ALTER TABLE 表名 ADD|MODIFY|DROP|CHANGE COLUMN 字段名 【字段类型】;
#①修改字段名
ALTER TABLE studentinfo CHANGE COLUMN sex gender CHAR;
#②修改表名
ALTER TABLE stuinf RENAME [TO] studentinfo;
#③修改字段类型和列级约束
ALTER TABLE studentinfo MODIFY COLUMN borndate DATE ;
最终结论:change用来字段重命名,不能修改字段类型和约束;
modify不用来字段重命名,只能修改字段类型和约束;
#④添加字段
ALTER TABLE studentinfo ADD COLUMN email VARCHAR(20) first;
#⑤删除字段
ALTER TABLE studentinfo DROP COLUMN email;
#3.删除表
DROP TABLE [IF EXISTS] studentinfo;
#四、复制表
1、复制表的结构
create table 表名 like 旧表;
2、复制表的结构+数据
create table 表名
select 查询列表 from 旧表【where 筛选】;
3、仅仅复制某些字段
create table 表名
select 查询列表 from 旧表【where 0】;
- 数据类型


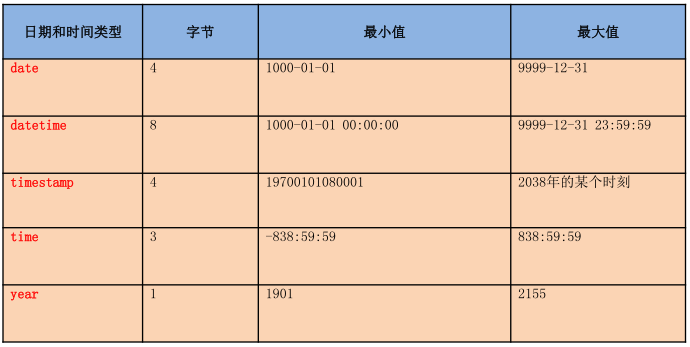
-
datetime和timestamp的区别
#显示当前时区
SHOW VARIABLES LIKE 'time_zone';
#设置当前时区
SET time_zone='+9:00';

数据库事务

含义
通过一组逻辑操作单元(一组DML——sql语句),将数据从一种状态切换到另外一种状态
特点
(ACID)
原子性:要么都执行,要么都回滚
一致性:保证数据的状态操作前和操作后保持一致
隔离性:多个事务同时操作相同数据库的同一个数据时,一个事务的执行不受另外一个事务的干扰
持久性:一个事务一旦提交,则数据将持久化到本地,除非其他事务对其进行修改
隐式(自动)事务:没有明显的开启和结束,本身就是一条事务可以自动提交,比如insert、update、delete
显式事务:具有明显的开启和结束
使用显式事务:
①开启事务
set autocommit=0;
start transaction;#可以省略
②编写一组逻辑sql语句
注意:sql语句支持的是insert、update、delete
设置回滚点:
savepoint 回滚点名;
③结束事务
提交:commit;
回滚:rollback;
回滚到指定的地方:rollback to 回滚点名;


-
隔离级别
脏读 不可重复读 幻读 read uncommitted:读未提交 × × × read committed:读已提交 √ × × repeatable read:可重复读 √ √ × serializable:串行化 √ √ √  在 MySql 中设置隔离级别?
在 MySql 中设置隔离级别? -
每启动一个 mysql 程序, 就会获得一个单独的数据库连接. 每
个数据库连接都有一个全局变量@@tx_isolation, 表示当前的
事务隔离级别. -
查看当前的隔离级别:
SELECT @@tx_isolation; -
设置当前 mySQL 连接的隔离级别:
set transaction isolation level read committed; -
设置数据库系统的全局的隔离级别:
set global transaction isolation level read committed;
视图
含义:理解成一张虚拟的表
视图和表的区别:
使用方式 占用物理空间
视图 完全相同 不占用,仅仅保存的是sql逻辑
表 完全相同 占用
视图的好处:
1、sql语句提高重用性,效率高
2、和表实现了分离,提高了安全性
视图的创建
语法:
CREATE VIEW 视图名
AS
查询语句;
视图的增删改查
1、查看视图的数据 ★
SELECT * FROM my_v4;
SELECT * FROM my_v1 WHERE last_name='Partners';
2、插入视图的数据,原始表对应的字段也会插入
INSERT INTO my_v4(last_name,department_id) VALUES('虚竹',90);
3、修改视图的数据,原始表对应的字段也会修改
UPDATE my_v4 SET last_name ='梦姑' WHERE last_name='虚竹';
4、删除视图的数据
DELETE FROM my_v4;
某些视图不能更新
包含以下关键字的sql语句:分组函数、distinct、group by、having、union或者union all
常量视图
Select中包含子查询
join
from一个不能更新的视图
where子句的子查询引用了from子句中的表
视图逻辑的更新
#方式一:
CREATE OR REPLACE VIEW test_v7
AS
SELECT last_name FROM employees
WHERE employee_id>100;
#方式二:
ALTER VIEW test_v7
AS
SELECT employee_id FROM employees;
SELECT * FROM test_v7;
视图的删除
DROP VIEW test_v1,test_v2,test_v3;
视图结构的查看
DESC test_v7;
SHOW CREATE VIEW test_v7;
约束

-- 示例
USE students;
CREATE TABLE stuinfo(
id INT PRIMARY KEY COMMENT '主键',
stu_name VARCHAR(20) NOT NULL ,
gender CHAR(1) CHECK(gender='男' OR gender='女'),
seat INT UNIQUE,
age INT DEFAULT 18,
major_id INT ,
CONSTRAINT fk_stuinfo_major FOREIGN KEY (major_id) REFERENCES major(id)
);
CREATE TABLE major(
id INT PRIMARY KEY,
major_name VARCHAR(20)
);
-
主键和唯一
1、区别:
①、一个表至多有一个主键,但可以有多个唯一
②、主键不允许为空,唯一可以为空
2、相同点
都具有唯一性
都支持组合键,但不推荐



流程控制结构
系统变量
一、全局变量
作用域:针对于所有会话(连接)有效,但不能跨重启
查看所有全局变量
SHOW GLOBAL VARIABLES;
查看满足条件的部分系统变量
SHOW GLOBAL VARIABLES LIKE '%char%';
查看指定的系统变量的值
SELECT @@global.autocommit;
为某个系统变量赋值
SET @@global.autocommit=0;
SET GLOBAL autocommit=0;
二、会话变量
作用域:针对于当前会话(连接)有效
查看所有会话变量
SHOW SESSION VARIABLES;
查看满足条件的部分会话变量
SHOW SESSION VARIABLES LIKE '%char%';
查看指定的会话变量的值
SELECT @@autocommit;
SELECT @@session.tx_isolation;
为某个会话变量赋值
SET @@session.tx_isolation='read-uncommitted';
SET SESSION tx_isolation='read-committed';
自定义变量
一、用户变量,作用域:针对当前会话有效
声明并初始化:
SET @变量名=值;
SET @变量名:=值;
SELECT @变量名:=值;
赋值:
方式一:一般用于赋简单的值
SET 变量名=值;
SET 变量名:=值;
SELECT 变量名:=值;
方式二:一般用于赋表 中的字段值
SELECT 字段名或表达式 INTO 变量
FROM 表;
使用:
select @变量名;
二、局部变量
声明:
declare 变量名 类型 【default 值】;
赋值:
方式一:一般用于赋简单的值
SET 变量名=值;
SET 变量名:=值;
SELECT 变量名:=值;
方式二:一般用于赋表 中的字段值
SELECT 字段名或表达式 INTO 变量
FROM 表;
使用:
select 变量名
二者的区别:
作用域 定义位置 语法
用户变量 当前会话 会话的任何地方 加@符号,不用指定类型
局部变量 定义它的BEGIN END中 BEGIN END的第一句话 一般不用加@,需要指定类型
存储过程
含义:一组经过预先编译的sql语句的集合
好处:
1、提高了sql语句的重用性,减少了开发程序员的压力
2、提高了效率
3、减少了传输次数
分类:
1、无返回无参
2、仅仅带in类型,无返回有参
3、仅仅带out类型,有返回无参
4、既带in又带out,有返回有参
5、带inout,有返回有参
注意:in、out、inout都可以在一个存储过程中带多个
- 创建存储过程
语法:
create procedure 存储过程名(in|out|inout 参数名 参数类型,...)
begin
存储过程体
end
类似于方法:
修饰符 返回类型 方法名(参数类型 参数名,...){
方法体;
}
-- 示例一
CREATE PROCEDURE myp1()
BEGIN
INSERT INTO admin(username,`password`)
VALUES('john1', '0000'),('lily', '0000'),('rose', '0000'),('jack', '0000'),('tom', '0000');
END;
CALL myp1();
SELECT * FROM admin
-- 示例二
CREATE PROCEDURE myp3(IN username VARCHAR(20),IN `password`VARCHAR(20) )
BEGIN
DECLARE result int DEFAULT 0;#声明并初始化
SELECT COUNT(*) INTO result#赋值
FROM admin
WHERE admin.username=username #相当于java中的this
AND admin.`password`=`password`;
SELECT IF(result>0,'成功','失败') result ;#使用
END;
CALL myp3('张飞','8888');#失败
-- 示例三 OUT是写出来了,以后直接SELECT @bName;就行了
delimiter $
CREATE PROCEDURE myp4(IN beautyName VARCHAR(20),OUT boyName VARCHAR(20))
BEGIN
SELECT bo.boyName INTO boyName
FROM boys bo
INNER JOIN beauty b ON bo.id=b.boyfriend_id
WHERE b.`name`=beautyName;
END $
CALL myp4('小昭',@bName)
SELECT @bName;
-- 示例四
delimiter $
CREATE PROCEDURE myp5(IN beautyName VARCHAR(20),OUT boyName VARCHAR(20),OUT userCP INT)
BEGIN
SELECT bo.boyName,bo.userCP INTO boyName,userCP
FROM boys bo
INNER JOIN beauty b ON bo.id=b.boyfriend_id
WHERE b.`name`=beautyName;
END $
CALL myp5('热巴',@bName,@userCP)
SELECT @bName ,@userCP;
-- 示例五
CREATE PROCEDURE myp6(INOUT a INT,INOUT b INT)
BEGIN
SET a=a*2;
SET b=b*2;
END;
SET @m=10;
SET @n=20;
call myp6(@m,@n);
SELECT @m,@n;# @m:20,@n:40
注意
1、需要设置新的结束标记
delimiter 新的结束标记
示例:
delimiter $
CREATE PROCEDURE 存储过程名(IN|OUT|INOUT 参数名 参数类型,...)
BEGIN
sql语句1;
sql语句2;
END $
2、存储过程体中可以有多条sql语句,如果仅仅一条sql语句,则可以省略begin end
3、参数前面的符号的意思
in:该参数只能作为输入 (该参数不能做返回值)
out:该参数只能作为输出(该参数只能做返回值)
inout:既能做输入又能做输出
- 调用存储过程
call 存储过程名(实参列表)
函数
- 创建函数
学过的函数:LENGTH、SUBSTR、CONCAT等
语法:
CREATE FUNCTION 函数名(参数名 参数类型,...) RETURNS 返回类型
BEGIN
函数体
END
--案例一:无参有返回,返回公司员工个数
CREATE FUNCTION myf1() RETURNS INT
BEGIN
DECLARE c INT DEFAULT 0;#定义变量
SELECT COUNT(*) INTO c#赋值
FROM employees;
RETURN c;
END;
SELECT myf1();
-- 案例二:有参有返回,根据员工名,返回他的工资
CREATE FUNCTION myf2(empName VARCHAR(20)) RETURNS DOUBLE
BEGIN
SET @sal=0;#定义用户变量
SELECT salary INTO @sal
FROM employees
WHERE last_name=empName;
RETURN @sal;
END;
SELECT myf2('Kochhar');
-- 案例三
CREATE FUNCTION myf3(deptName VARCHAR(20)) RETURNS DOUBLE
BEGIN
DECLARE sal DOUBLE;
SELECT AVG(salary) INTO sal
FROM employees e
JOIN departments d ON e.department_id=d.department_id
WHERE d.department_name=deptName;
RETURN sal;
END;
SELECT myf3('IT');
- 调用函数
SELECT 函数名(实参列表)
- 函数和存储过程的区别
| 关键字 | 调用语法 | 返回值 | 应用场景 | |
|---|---|---|---|---|
| 函数 | FUNCTION | SELECT 函数() | 只能是一个 | 一般用于查询结果为一个值并返回时,当有返回值而且仅仅一个 |
| 存储过程 | PROCEDURE | CALL 存储过程() | 可以有0个或多个 | 一般用于更新 |
分支
一、if函数
语法:if(条件,值1,值2)
特点:可以用在任何位置
二、case语句
语法:
情况一:类似于switch
case 表达式
when 值1 then 结果1或语句1(如果是语句,需要加分号)
when 值2 then 结果2或语句2(如果是语句,需要加分号)
...
else 结果n或语句n(如果是语句,需要加分号)
end 【case】(如果是放在begin end中需要加上case,如果放在select后面不需要)
情况二:类似于多重if
case
when 条件1 then 结果1或语句1(如果是语句,需要加分号)
when 条件2 then 结果2或语句2(如果是语句,需要加分号)
...
else 结果n或语句n(如果是语句,需要加分号)
end 【case】(如果是放在begin end中需要加上case,如果放在select后面不需要)
特点:
可以用在任何位置
三、if elseif语句
语法:
if 情况1 then 语句1;
elseif 情况2 then 语句2;
...
else 语句n;
end if;
特点:
只能用在begin end中!!!!!!!!!!!!!!!
三者比较:
应用场合
if函数 简单双分支
case结构 等值判断 的多分支
if结构 区间判断 的多分支
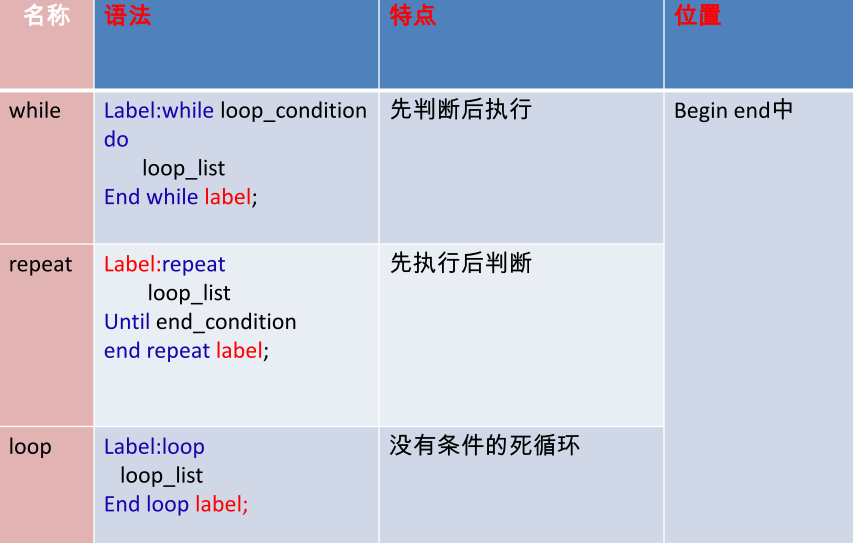
循环
语法:
【标签:】WHILE 循环条件 DO
循环体
END WHILE 【标签】;
特点:
只能放在BEGIN END里面
如果要搭配leave跳转语句,需要使用标签,否则可以不用标签
leave类似于java中的break语句,跳出所在循环!!!
- case结构——作为表达式

- case结构——作为独立的语句

-- 案例一
TRUNCATE TABLE admin;
CREATE PROCEDURE test_while1(IN insertCount INT)
BEGIN
DECLARE i INT DEFAULT 1;
a:WHILE i<=insertCount DO
INSERT INTO admin (username,`password`)VALUES (CONCAT('xiaohua',i),'0000');
IF i>=20 THEN LEAVE a;
END IF;
SET i=i+1;
END WHILE a;
END;
CALL test_while1(100);
SELECT * FROM admin;