内容来自本人以前在github搭建的博客写的:MySQL高级之视图事务函数触发器
pymysql安装
pymysql是python用于连接并操作数据库的一个原生模块
linux下:
pip3 install pymysql
sql注入
1.简单模拟登录
先来看一个简单例子,代码如下:
import pymysql user = input("username:") pwd = input("password:") # 与数据库建立连接 conn = pymysql.connect(host="localhost", user="root", password="root", database="test") # 设置游标 cursor = conn.cursor() # 将要执行的sql语句 sql = "select * from userinfo where username = '%s' and password = '%s'" % (user, pwd) # 执行语句 cursor.execute(sql) # 用fetchone获取查询结果 result = cursor.fetchone() # 关闭连接 cursor.close() conn.close() if result: print("登录成功") else: print("用户名或密码错误")
2.sql注入漏洞
注意,上面的代码虽然可正确执行,但是是存在漏洞的。
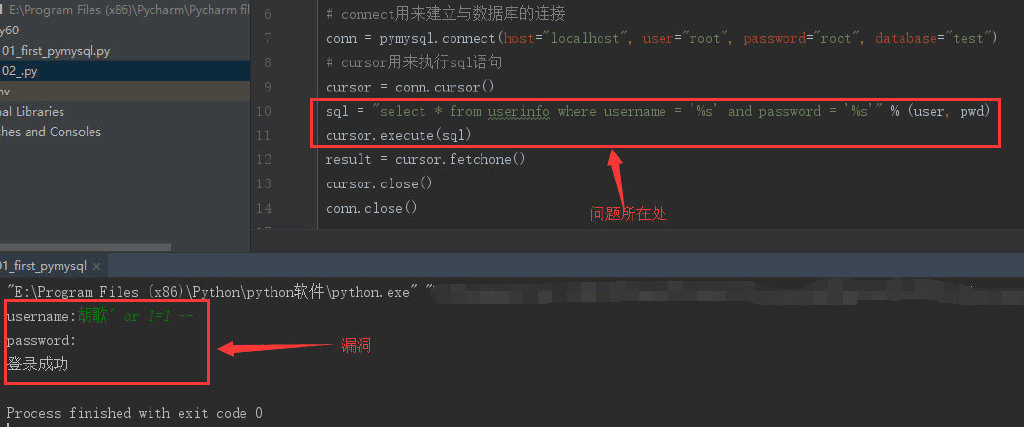
如图,漏洞为即使你随便输入一个账户,按照”xxx’ or 1=1 – “的格式,不输入密码也能登录进去,这种漏洞我们称呼为”sql注入”;问题主要存在于sql语句的写法。
3.sql注入原理
如图

4.避免sql注入
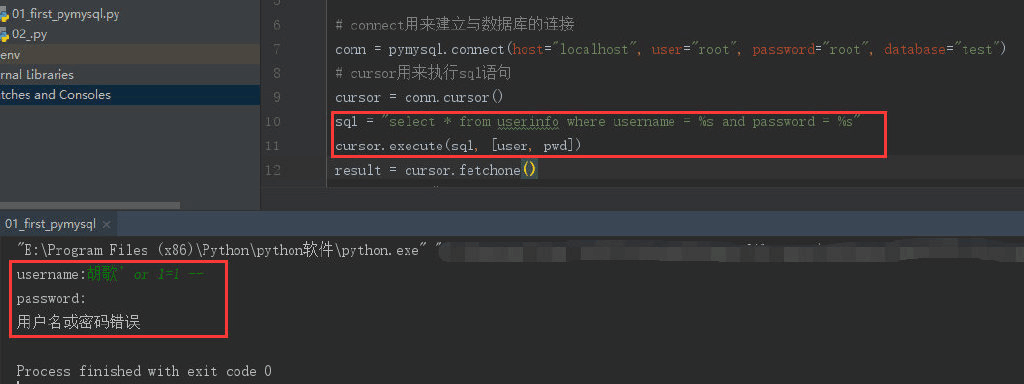
为了避免sql注入,我们不要自己做拼接,用pymysql自带的execute后面传参数的方式,有如下三种方法:
sql = "select * from userinfo where username = %s and password = %s" cursor.execute(sql, (user, pwd))
或者:
sql = "select * from userinfo where username = %s and password = %s" cursor.execute(sql, [user, pwd])
或者:
sql = "select * from userinfo where username = %(u)s and password = %(p)s" cursor.execute(sql, {'u': user, 'p': pwd})
顺利解决sql注入问题,如图
5.模拟登陆代码
import pymysql name = input("username:") pwd = input("password:") conn = pymysql.connect(host='localhost', user='root', password='root', database='test') cursor = conn.cursor() sql = "select * from userinfo where name=%s and password=%s" r = cursor.execute(sql, (name, pwd)) # 方法二 # sql = "select * from userinfo where name=%s and password=%s" # r = cursor.execute(sql, [name, pwd]) # 方法三 # sql = "select * from userinfo where name=%(u)s and password=%(p)s" # r = cursor.execute(sql, {'u': name, 'p': pwd}) result = cursor.fetchone() cursor.close() conn.close() if result: print("登陆成功") else: print("账户名或密码错误")
pymysql操作数据库
1.pymysql增
1.1.插入一行数据
代码如下:
import pymysql conn = pymysql.connect(host="localhost", user="root", password="root", database="test") cursor = conn.cursor() sql = "insert into userinfo(username,password) values('那英','naying')" cursor.execute(sql) conn.commit() cursor.close() conn.close()
值得注意的是,在增删改时我们用的是commit进行提交,在查时用的是fetchone进行查找。
当然,我们也可以自定义插入,如下:
sql = "insert into userinfo(username,password) values(%s,%s)" cursor.execute(sql, [user, pwd]) conn.commit()
1.2.插入多行数据
在插入当行数据是,应注意此时我们用的是executemany,而不是execute。
sql = "insert into userinfo(username,password) values(%s,%s)" r = cursor.executemany(sql, [('张学友', 'zhangxueyou'), ('林俊杰', 'linjunjie')]) conn.commit()
1.3.execute的返回值r
execute和executemany都有返回值,用来记录受影响的行数,如下:
sql = "insert into userinfo(username,password) values(%s,%s)" r = cursor.executemany(sql, [('张学友', 'zhangxueyou'), ('林俊杰', 'linjunjie')]) print(r) conn.commit()
结果为2;
不仅仅是增删改会有受影响的行数,查询时也会有。
同时,executemany只适用于插入数据,删和改用execute即可。
2.pymysql查
2.1.fetchone
代码如下:
result = cursor.fetchone() print(result) result = cursor.fetchone() print(result) result = cursor.fetchone() print(result)
结果:
(1, '刘德华', 'liudehua') (3, '郭德纲', 'guodegang') (4, '胡歌', 'huge')
fetchone可以单次查询,也可以连续单次查询,连续单次查询时,会有类似于指针一样的东西,当你查询一次后,指针自动跳往下一行数据。
2.2.fetchall
fetchall在未指定limit时,默认查询所有数据
代码如下:
sql = "select * from userinfo" cursor.execute(sql) result = cursor.fetchall() print(result)
结果:
((1, ‘刘德华’, ‘liudehua’), (3, ‘郭德纲’, ‘guodegang’), (4, ‘胡歌’, ‘huge’), (5, ‘周杰伦’, ‘zhoujielun’), (7, ‘那英’, ‘naying’), (8, ‘王菲’, ‘wangfei’), (11, ‘张学友’, ‘zhangxueyou’), (14, ‘林俊杰’, ‘linjunjie’))
2.3.fetchmany
fetchmany(n)查询指定前n条数据
代码如下:
sql = "select * from userinfo" cursor.execute(sql) result = cursor.fetchmany(3) print(result)
结果:
((1, ‘刘德华’, ‘liudehua’), (3, ‘郭德纲’, ‘guodegang’), (4, ‘胡歌’, ‘huge’))
2.4.fetch小结
- 1.fetchone查询单次数据,fetchall查询所有数据,fetchmany(n)查询指定n词数据。
- 2.如果想要实现分页的话,要先在查询语句中limit 10数据,再用fetchall查询指定的10条数据;而不能先fetchall所有数据,再一部分一部分的显示。
- 3.相对来说,用的最多的是fetchone和fetchall
注:在fetch数据时按照顺序进行,可以使用cursor.scroll(num,mode)来移动游标位置,如:
- cursor.scroll(1,mode=’relative’) # 相对当前位置移动
- cursor.scroll(2,mode=’absolute’) # 相对绝对位置移动
2.5.查询数据字典形式显示
为了方便查看,我们会将数据以字典格式显示key和value
代码如下:
import pymysql conn = pymysql.connect(host='localhost', user='root', password='root', database='test') cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) sql = "select * from userinfo" cursor.execute(sql) result = cursor.fetchmany(3) print(result)
结果:
[{‘id’: 1, ‘username’: ‘刘德华’, ‘password’: ‘liudehua’}, {‘id’: 3, ‘username’: ‘郭德纲’, ‘password’: ‘guodegang’}, {‘id’: 4, ‘username’: ‘胡歌’, ‘password’: ‘huge’}]
2.6.新增数据的自增id
获取新增数据的自增id:cursor.lastrowid,直接用
如果插入的为多行数据,则显示的为最后一个自增的id
print(cursor.lastrowid)
3.pymysql删改
增和查的注意点可能多一点,而pymysql删与改的操作重点在于sql语句,其他只需要连接,执行,关闭连接即可。
3.1.改
代码如下:
import pymysql conn = pymysql.connect(host='localhost', user='root', password='root', database='test') cursor = conn.cursor() sql = "update userinfo set name='李玉刚' where id=1" cursor.execute(sql) conn.commit() cursor.close() conn.close()
4.pymysql删
4.1.删
代码如下:
import pymysql conn = pymysql.connect(host='localhost', user='root', password='root', database='test') cursor = conn.cursor() sql = "delete from userinfo where id=1" cursor.execute(sql) conn.commit() cursor.close()
视图
为某个查询语句设置别名,方便使用,即为视图;
1.创建视图
创建语句:
create view viewname as SQL
示例:
CREATE view v1 as SELECT * FROM userinfo WHERE id>5; CREATE view v1 as SELECT id,name FROM userinfo WHERE id>5;
2.修改视图
修改语句:alter view viewname as SQL
eg:
alter view v1 as SELECT id,NAME from userinfo WHERE id >5;
3.删除视图
删除语句:drop view viewname;
eg:
drop view v1;
4.查看视图
查看语句:select from viewname;
eg:
select from v1; select id,name from v1;
5.视图小结
给一个临时表设置别名的过程就叫做创建视图,别名就是视图的名称;实际存在的表比如userinfo就是物理表,而一个视图就是虚拟表,虚拟表动态的从物理表中取数据,所以在物理表中插入数据后虚拟表也可能会随之改变,但不能向虚拟表中插入数据;创建,修改,删除视图。
触发器
对某个表进行【增/删/改】操作的前后触发一些操作即为触发器,如果希望触发增删改的行为之前或之后做操作时,可以使用触发器,触发器用于自定义用户对表的行进行【增/删/改】前后的行为。
1.创建触发器
delimiter // # 修改终止符 CREATE TRIGGER tri_before_insert_userinfo BEFORE INSERT on userinfo for EACH ROW BEGIN insert into userinfolog(type,newname) VALUES('insert','姓名'); END// delimiter ; # 结束后将终止符修改回来
2.多次触动触发器
insert into userinfo(name,password) values('石超','shichao'),('林殊','linshu');
因为each row的存在,在一次SQL中插入两行数据,会触发两次触发器,即向userinfo插入数据前,会分别两次向user插入数据。
3.自定义触发器新插入数据
在前面我们写的触发器里,只能插入固定的数据,那么我们可不可以在user中插入即将插入userinfo的数据呢?答案是可以的,如下:
delimiter // create trigger tri_after_delete_userinfo after delete on userinfo for each row begin insert into userinfolog(type,oldname) values(‘delete’,OLD.name); end // delimiter ; delimiter // create trigger tri_after_update_userinfo after update on userinfo for each row begin insert into userinfolog(type,oldname,newname) values('update',OLD.name,NEW.name); end // delimiter ;
注意:触发器无法被修改,如果想要修改的话,可以先drop,再重新创建
delimiter // create trigger tri_after_update_userinfo after insert on userinfo for each row begin if NEW.operate = 'insert' then insert into userinfolog(type,newname) values('INSERT',NEW.name); elseif NEW.operate = 'delete' then insert into userinfolog(type,newname) values('delete',OLD.name); else insert into userinfolog(type,oldname,newname) values('update',OLD.name); end if; end // delimiter ;
函数
1、内置函数
MySQL中提供了许多内置函数,例如:
CURDATE(),可以查看当前时间;
使用:
select CURDATE()
2、自定义函数
delimiter \ create function f1( i1 int, i2 int) returns int BEGIN declare num int; set num = i1 + i2; return(num); END \ delimiter ;
3、删除函数
drop function func_name();
4、执行函数
# 获取返回值 set @i1=1; set @i2=2; select f1(@i1,@i2) into @j; SELECT @j; select f1(11,nid) ,name from tb2; # 在查询中使用,对列的值函数计算后返回。
5、查看函数
show function status;
6、查看函数构建语句
show create function func_nameG
存储过程
存储过程是一个SQL语句集合,当主动去调用存储过程时,其中内部的SQL语句会按照逻辑执行。
1、创建存储过程
无参数存储过程
– 创建存储过程
delimiter // #修改结束符号,为// create procedure p1() BEGIN select * from t1; END// delimiter ;
– 执行存储过程
call p1()
对于存储过程,可以接收参数,其参数有三类:
- in 仅用于传入参数用
- out 仅用于返回值用
- inout 既可以传入又可以当作返回值
关于变量设置,对于调用存储过程或者函数时,外部传入参数或者获取参数,需加符号@,例如set @t=1;在本次会话内这些带@的变量都可以被获取到。断开连接后变量失效。
有参数存储过程
– 创建存储过程
delimiter \ create procedure p1( in i1 int, in i2 int, inout i3 int, out r1 int ) BEGIN DECLARE temp1 int; DECLARE temp2 int default 0; set temp1 = 1; set r1 = i1 + i2 + temp1 + temp2; set i3 = i3 + 100; end\ delimiter ;
– 执行存储过程
SET @t2=3; CALL p1 (1, 2 ,@t1, @t2); SELECT @t1,@t2; delimiter // 将结束符号;修改为// DECLARE 声明变量。如果没有DEFAULT子句,初始值为NULL。用于内部变量申明。 SET 变量赋值。用于内部变量赋值,和传参数时参数赋值。
2、删除存储过程
drop procedure proc_name;
3、执行存储过程
– 无参数
call proc_name();
– 有参数,全in
call proc_name(1,2);
– 有参数,有in,out,inout
set @t1=3; call proc_name(1,2,@t1,@t2); import pymysql conn = pymysql.connect(host='127.0.0.1',user='root', password='root', db='t1') cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) cursor.callproc('p1', args=(1, 22, 3, 4)) # 执行存储过程 cursor.execute("select @_p1_0,@_p1_1,@_p1_2,@_p1_3") # 获取执行完存储的参数 result = cursor.fetchall() conn.commit() cursor.close() conn.close() print(result)
4、查看存储过程
列出所有的存储过程
SHOW PROCEDURE STATUS;
5、查看存储过程生成语句
查看存储过程
SHOW CREATE PROCEDURE 存储过程名G
事务
事务用于将某些操作的多个SQL作为原子性操作,一旦有某一个出现错误,即可回滚到原来的状态,从而保证数据库数据完整性。
定义存储过程:
delimiter \ drop PROCEDURE if EXISTS p1; create PROCEDURE p1( OUT p_return_code tinyint ) BEGIN DECLARE exit handler for sqlexception -- 定义错误处理 BEGIN -- ERROR set p_return_code = 1; rollback; -- 回滚 END; DECLARE exit handler for sqlwarning -- 定义告警处理 BEGIN -- WARNING set p_return_code = 2; rollback; END; START TRANSACTION; -- 开始事务,使下面的多条SQL语句操作变成原子性操作 UPDATE tb7 set licnese=(licnese-5) WHERE nid=21; UPDATE tb7 set licnese=(licnese+5) WHERE nid=22; COMMIT; -- SUCCESS set p_return_code = 0; END\ delimiter ;
执行存储过程:
call p1(@p); SELECT @p;
SQL防注入之动态SQL
在高级语言的DB API不提供防注入的参数化查询功能时,可以使用这种方法来防止SQL注入。在pymysql中的调用点这里。
定义存储过程:
delimiter \ DROP PROCEDURE IF EXISTS proc_sql \ CREATE PROCEDURE proc_sql ( in nid1 INT, in nid2 INT, in callsql VARCHAR(255) ) BEGIN set @nid1 = nid1; set @nid2 = nid2; set @callsql = callsql; PREPARE myprod FROM @callsql; -- PREPARE prod FROM 'select * from tb2 where nid>? and nid<?'; 传入的值为字符串,?为占位符 -- 用@nid1,和@nid2填充占位符 EXECUTE myprod USING @nid1,@nid2; DEALLOCATE prepare myprod; END\ delimiter ;
调用存储过程
set @nid1=12; set @nid2=15; set @callsql = 'select * from tb7 where nid>? and nid<?'; CALL proc_sql(@nid1,@nid2,@callsql)