目录
- ELMo简介
- ELMo模型概述
- ELMo模型解析
- ELMo步骤
- 总结
一句话简介:2018年发掘的自回归模型,采用预训练和下游微调方式处理NLP任务;解决动态语义问题,word embedding 送入双向LSTM,损失函数基于两个LSTM判断的loss求和,最后通过softmax求解。
一、ELMo简介
1.1 背景
word embedding 是现在自然语言处理中最常用的 word representation 的方法,常用的word embedding 有word2vec的方法,然而word2vec本质上是一个静态模型,所谓静态指的是训练好之后每个单词的表达就固定住了,以后使用的时候,不论新句子上下文单词是什么,这个单词的 Word Embedding 不会跟着上下文场景的变化而改变,所以对于比如 Bank 这个词,它事先学好的 Word Embedding 中混合了几种语义,在应用中来了个新句子,即使从上下文中(比如句子包含 money 等词)明显可以看出它代表的是「银行」的含义,但是对应的 Word Embedding 内容也不会变,它还是混合了多种语义。这是为何说它是静态的,这也是问题所在。
1.2 介绍
ELMo的提出就是为了解决这种语境问题,动态的去更新词的word embedding。ELMo的本质思想是:事先用语言模型在一个大的语料库上学习好词的word embedding,但此时的多义词仍然无法区分,不过没关系,我们接着用我们的训练数据(去除标签)来fine-tuning 预训练好的ELMO 模型。作者将这种称为domain transfer。这样利用我们训练数据的上下文信息就可以获得词在当前语境下的word embedding。作者给出了ELMO 和Glove的对比。
1.3 效果对比
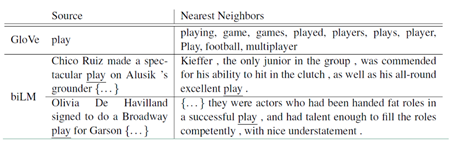
对于Glove训练出来的word embedding来说,多义词play,根据他的embedding 找出的最接近的其他单词大多数几种在体育领域,这主要是因为训练数据中包含play的句子大多数来源于体育领域,之后在其他语境下,play的embedding依然是和体育相关的。
而使用ELMO,根据上下文动态调整后的embedding不仅能够找出对应的"表演"相同的句子,还能保证找出的句子中的play对应的词性也是相同的。接下来看看ELMO是怎么实现这样的结果的。
二、ELMO模型概述

ELMO 采用了典型的两阶段过程:
第一个阶段是利用语言模型进行预训练;
第二个阶段是在做下游任务时,从预训练网络中提取对应单词的网络各层的 Word Embedding 作为新特征补充到下游任务中。
上图展示的是其预训练过程,它的网络结构采用了双层双向 LSTM,目前语言模型训练的任务目标是根据单词的上下文去正确预测单词,输入的是从左到右顺序的除了预测单词外的上文 Context-before;右端的逆向双层 LSTM 代表反方向编码器,输入的是从右到左的逆序的句子下文 Context-after;每个编码器的深度都是两层 LSTM 叠加。这个网络结构其实在 NLP 中是很常用的。
使用这个网络结构利用大量语料做语言模型任务就能预先训练好这个网络,如果训练好这个网络后,输入一个新句子Snew,句子中每个单词都能得到对应的三个Embedding:最底层是单词的 Word Embedding,往上走是第一层双向LSTM中对应单词位置的 Embedding,这层编码单词的句法信息更多一些;再往上走是第二层LSTM中对应单词位置的 Embedding,这层编码单词的语义信息更多一些。也就是说,ELMO 的预训练过程不仅仅学会单词的 Word Embedding,还学会了一个双层双向的LSTM网络结构,而这两者后面都有用。
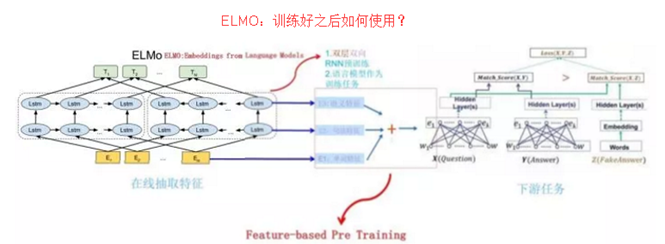
上面介绍的是 ELMO 的第一阶段:预训练阶段。那么预训练好网络结构后,如何给下游任务使用呢?上图展示了下游任务的使用过程,比如我们的下游任务仍然是 QA 问题,此时对于问句 X,我们可以先将句子 X 作为预训练好的 ELMO 网络的输入,这样句子 X 中每个单词在 ELMO 网络中都能获得对应的三个 Embedding(文中3个1024维的向量表示),之后给予这三个 Embedding 中的每一个 Embedding 一个权重 a,这个权重可以学习得来,根据各自权重累加求和,将三个 Embedding 整合成一个。然后将整合后的这个 Embedding 作为 X 句在自己任务的那个网络结构中对应单词的输入,以此作为补充的新特征给下游任务使用。对于上图所示下游任务 QA 中的回答句子 Y 来说也是如此处理。因为 ELMO给下游提供的是每个单词的特征形式,所以这一类预训练的方法被称为"Feature-based Pre-Training"。
三、ELMO模型解析
3.1 模型结构
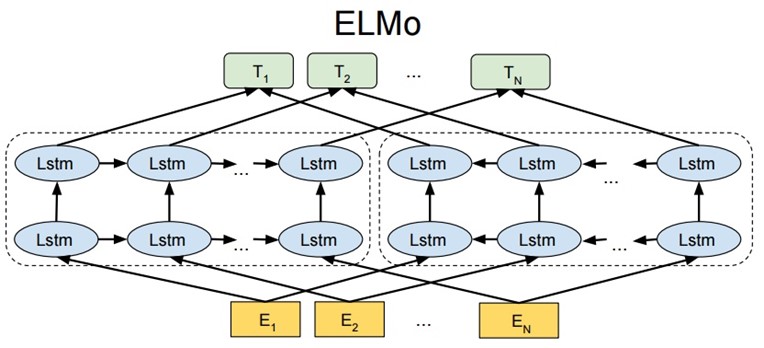
ELMO 基于语言模型的,确切的来说是一个 Bidirectional language models,也是一个 Bidirectional LSTM结构。我们要做的是给定一个含有N个tokens的序列。分为以下三步:
第一步:得到word embedding,即上图的E。所谓word embedding就是一个n*1维的列向量
第二步:送入双向LSTM模型中;
第三步:将lstm的输出hk,与上下文矩阵W′相乘,再将该列向量经过softmax归一化。其中,假定数据集有V个单词,W′是|V|*m的矩阵,hk是m*1的列向量,于是最终结果是|V|*1的归一化后向量,即从输入单词得到的针对每个单词的概率。
3.2 公式解析
前向表示:

后向表示相似:

biLM训练过程中的目标就是最大化:
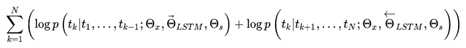
两个网络里都出现了Θx和Θs,两个网络共享的参数。
其中Θx表示映射层的共享,表示第一步中,将单词映射为word embedding的共享,就是说同一个单词,映射为同一个word embedding。
Θs表示第三步中的上下文矩阵的参数,这个参数在前向和后向lstm中是相同的。
ELMo对于每个token tk, 通过一个L层的biLM计算2L+1个表征(representations),这是输入第二阶段的初始值:
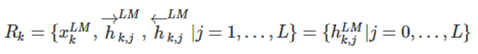
其中下标解释: k 表示单词位置,j 表示所在层,j=0 表示输入层。故整体可用右侧的 h 表示。具体如下:
是对token进行直接编码的结果(这里是字符通过CNN编码), 代表 , 是每个biLSTM层输出的结果。在实验中还发现不同层的biLM的输出的token表示对于不同的任务效果不同.最上面一层的输出是用softmax来预测下面一个单词
应用中将ELMo中所有层的输出R压缩为单个向量, , 最简单的压缩方法是取最上层的结果做为token的表示:, 更通用的做法是通过一些参数来联合所有层的信息:
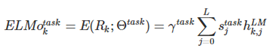
其中 是softmax标准化权重, 是缩放系数,允许任务模型去缩放整个ELMO向量。文中提到γ在不同任务中取不同的值效果会有较大的差异, 需要注意, 在SQuAD中设置为0.01取得的效果要好于设置为1时。
四、ELMO步骤
ELMO的使用主要有三步:
1)在大的语料库上预训练 biLM 模型。模型由两层bi-LSTM 组成,模型之间用residual connection 连接起来。而且作者认为低层的bi-LSTM层能提取语料中的句法信息,高层的bi-LSTM能提取语料中的语义信息。
2)在我们的训练语料(去除标签),fine-tuning 预训练好的biLM 模型。这一步可以看作是biLM的domain transfer。
3)利用ELMO 产生的word embedding来作为任务的输入,有时也可以即在输入时加入,也在输出时加入。
五、总结
4.1 优势
- 多义词方面的极大改善;
-
效果提升:6 个 NLP 任务中性能都有幅度不同的提升,最高的提升达到 25% 左右,而且这 6 个任务的覆盖范围比较广,包含句子语义关系判断,分类任务,阅读理解等多个领域,这说明其适用范围是非常广的,普适性强,这是一个非常好的优点。

4.2 劣势
- 那么站在现在这个时间节点看,ELMo有什么值得改进的缺点呢?首先,一个非常明显的缺点在特征抽取器选择方面,ELMo 使用了 LSTM 而不是新贵 Transformer,Transformer 是谷歌在 17 年做机器翻译任务的"Attention is all you need"的论文中提出的,引起了相当大的反响,很多研究已经证明了 Transformer 提取特征的能力是要远强于 LSTM 的;
- 训练时间长,这也是RNN的本质导致的,和上面特征提取缺点差不多;
- ELMo采取双向拼接这种融合特征的能力可能比 Bert 一体化的融合特征方式弱,但是,这只是一种从道理推断产生的怀疑,目前并没有具体实验说明这一点。
参考文献
【0】原始论文: https://arxiv.org/pdf/1802.05365.pdf
【1】一种新的embedding方法--原理与实验:https://zhuanlan.zhihu.com/p/37915351
【2】从Word Embedding到Bert模型——自然语言处理预训练技术发展史: https://www.jiqizhixin.com/articles/2018-12-10-8
【3】ELMo原理解析及简单上手使用: https://zhuanlan.zhihu.com/p/51679783