abstract
在本文中,我们研究了来自预先训练的语言模型(如BERT)的上下文嵌入的建模能力 ,如E2E-ABSA任务。具体来说,我们建立了一系列简单而又有洞察力的神经基线来处理E2E-ABSA。实验结果表明,即使是一个简单的线性分类层,我们的BERT-based结构也可以超越最先进的作品。此外,我们也标准化了比较研究,一致地使用一个保留的开发数据集进行模型选择,这在很大程度上被以前的工作所忽略。因此,我们的工作可以作为一个基于bert的E2E-ABSA基准。
一、 Introduction
简单介绍来源:基于方面的情感分析(ABSA)是发现用户对某一方面的情感或看法,通常以明确提到的方面术语的形式出现(Mitchell et al., 2013;或隐含体范畴(Wang et al., 2016),来自用户生成的自然语言文本(Liu, 2012)。最流行的ABSA基准数据集来自SemEval ABSA challenge (Pontiki et al., 2014, 2015, 2016),其中提供了几千个带有金标准aspect sentiment annotation的review语句。

表1总结了与ABSA相关的三个现有研究问题。第一个是最初的ABSA,旨在预测句子对特定方面的情感极性。与这个分类问题相比,第二个问题和第三个问题,即意见词提取(AOWE)【1】。端到端向方面的情感分析(E2E-ABSA)
【2】【3】【4】【5】【6】(Ma et al., 2018a; Schmitt et al., 2018; Li et al., 2019a; Li and Lu,2017, 2019),都与一个序列标记问题有关。准确地说,AOWE的目标是从给定方面的句子中提取出具体方面的意见词。E2E-ABSA的目标是联合检测相位术语/类别和相应的相位情感。
许多由任务未知的预先训练的单词嵌入层和任务特定的神经结构组成的神经模型已经被提出用于原始的ABSA任务(即方面级别的情感分类)(Tang et al., 2016;Wang et al., 2016; Chen et al., 2017; Liu and Zhang, 2017; Ma et al., 2017, 2018b; Majumder et al., 2018; Li et al., 2018; He et al., 2018; Xue and Li, 2018; Wang et al., 2018; Fan et al., 2018;Huang and Carley, 2018; Lei et al., 2019; Li et al., 2019b; Zhang et al., 2019【7】)但这些模型的准确性或F1评分的提高已经达到了瓶颈。一个原因是与任务无关的嵌入层,通常是一个用Word2Vec初始化的线性层
(Mikolov et al., 2013【8】) or GloVe (Pennington et al., 2014),只提供上下文无关的单词级特性,这对于捕获句子中的复杂语义依赖关系是不够的。同时,现有数据集的大小太小,无法训练复杂的特定于任务的体系结构。因此,引入了一个上下文感知的word embedding层,它预先在具有深度的大型数据集上训练LSTM(McCann et al., 2017; Peters et al., 2018;Howard and Ruder, 2018) or Transformer (【9】【10】Radford et al., 2018, 2019; 【11】Devlin et al., 2019;【12】 Lample and Conneau, 【13】2019; Yang et al., 2019;【14】 Dong et al., 2019) 对于微调使用标记数据的轻量级特定于任务的网络具有进一步提高性能的良好潜力。
Xu et al. (2019); Sun et al. (2019); Song et al.(2019); Yu and Jiang (2019); Rietzler et al. (2019);Huang and Carley (2019); Hu et al. (2019a)已经进行了一些初步的尝试,将深度上下文的单词嵌入层与原始ABSA任务的下游神经模型结合起来,并建立了新的最先进的结果。它鼓励我们探索使用这种情景化的嵌入来完成更困难但更实际的任务的潜力,i.e. E2E-ABSA(表1中的第三个任务)。请注意,我们的目标不是开发特定于任务的体系结构,相反,我们的重点是检查E2E-ABSA上下文嵌入的潜力,以及预测E2E-ABSA标签的各种简单层。
在本文中,我们研究了BERT (【11】Devlin et al., 2019)的建模能力,它是最流行的预训练语言模型之一【12】Transformer(Vaswani et al., 2017),关于E2E-ABSA的任务。具体来说,【13】 Li et al. (2019a)对E2E-ABSA的研究启发,它使用一个序列标记器来预测方面的边界和方面的情感,我们为序列标记问题建立了一系列简单但有洞察力的神经基线,并使用BERT或deem BERT作为特征提取器对特定于任务的组件进行微调 。我们也标准化了比较研究,一致地使用一个保留的开发数据集进行模型选择。在现有的大多数中,忽略了 ABSA (Tay et al., 2018).

二、Model
在这篇论文中,我们主要关注方面的术语水平端到端基于方面的情感分析(E2E-ABSA)设置问题。这个任务可以表述为一个序列标记问题。 我们的模型的总体架构如图1所示。给定输入标记序列:
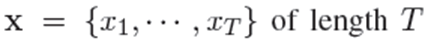
我们首先使用L个Transformer的BERT分量来计算相应的上下文表示,其中dim_h表示表示向量的维数。
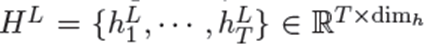

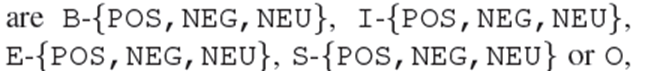
表示方面的开始,方面的内部,方面的结束,单个词的方面,分别具有积极的、消极的或中性的感情,以及方面的外部。
2.1 BERT as Embedding Layer
与传统的基于Word2Vec或GloVebased的嵌入层(只为每个标记提供一个独立于上下文的表示)相比,BERT嵌入层将句子作为输入,并使用来自整个句子的信息来计算标记级表示。首先,我们打包输入特性
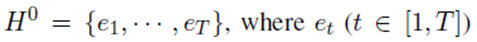

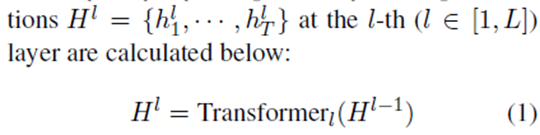

2.2 Design of Downstream Model
在获得BERT表示后,我们设计了一个神经层,称为E2E-ABSA层如图1,在BERT embedded layer的顶层,用于求解E2E-ABSA的任务。我们研究了E2E-ABSA层的几种不同设计,即线性层、递归神经网络、自我注意网络和条件随机场层。
线性层
得到的token表示法可以直接用softmax激活函数反馈到线性层,计算token级预测:

递归神经网络

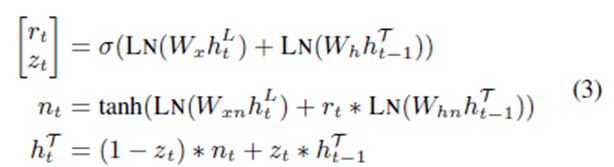

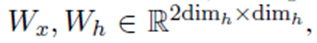
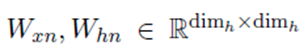
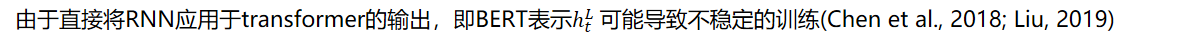
我们添加了额外的层标准化 (Ba et al., 2016),记为LN,计算gate的时候。然后,通过引入一个softmax层,得到了预测结果
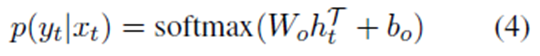
Self-Attention Network

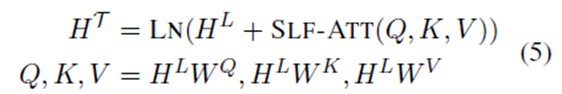
其中:SLF-ATT与 Self-Attention 和 Attention的点乘是相同的【12】 (Vaswani et al.,2017)。
另一种变体是transformer层(称为TFM),它和bert内的transformer encoder层有相同的结构。TFM的计算过程如下
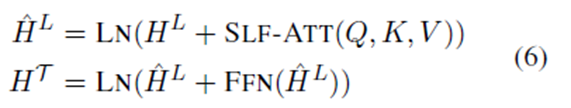
其中FFN 指的是 the point-wise feed-forward networks 【12】(Vaswani et al., 2017).再次,一个线性层与softmax激活堆叠在设计输出预测的SAN/TFM层(与式(4)相同)
条件随机场层

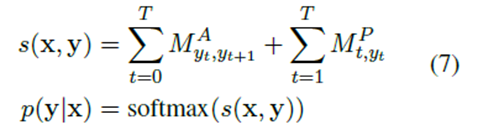

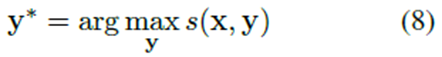
这里通过Viterbi搜索得到解决方案
3 Experiment
3.1 Dataset and Settings
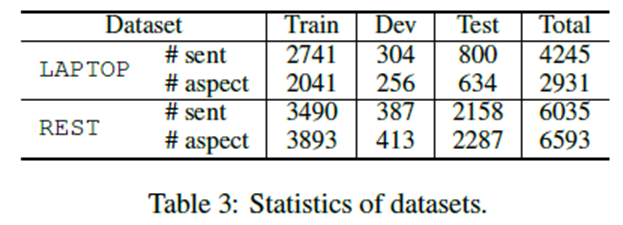
我们实验基于两个评论数据集: SemEval (Pontiki et al., 2014,2015 ,2016>但在【13】Li et al. (2019a)中重新准备。统计结果见表3。
使用预先训练的"bert-base-uncased"模型(https://github.com/huggingface/transformers)。式中,transformer层数L = 12,隐藏尺寸dim_h为768。在下游E2E-ABSA组件中,我们始终使用单层架构,并将任务特定表示的维度设置为dimh。学习率为2e-5。批处理大小设置25 for LAPTOP and 16 for REST。我们将模型训练到1500步。在训练1000步后,我们根据每100步的微观平均F1得分对开发集进行模型选择。按照这些设置,我们用不同的随机种子训练5个模型,并报告平均结果。
我们与现有的模型进行比较,包括定制的E2E-ABSA模型(【13】Li et al., 2019a;Luo et al., 2019; He et al., 2019),和竞争力的LSTM-CRF序列标记模型(Lample et al., 2016; Ma and Hovy, 2016; Liu et al., 2018)--3.2对比数据用到了
3.2 Main Results
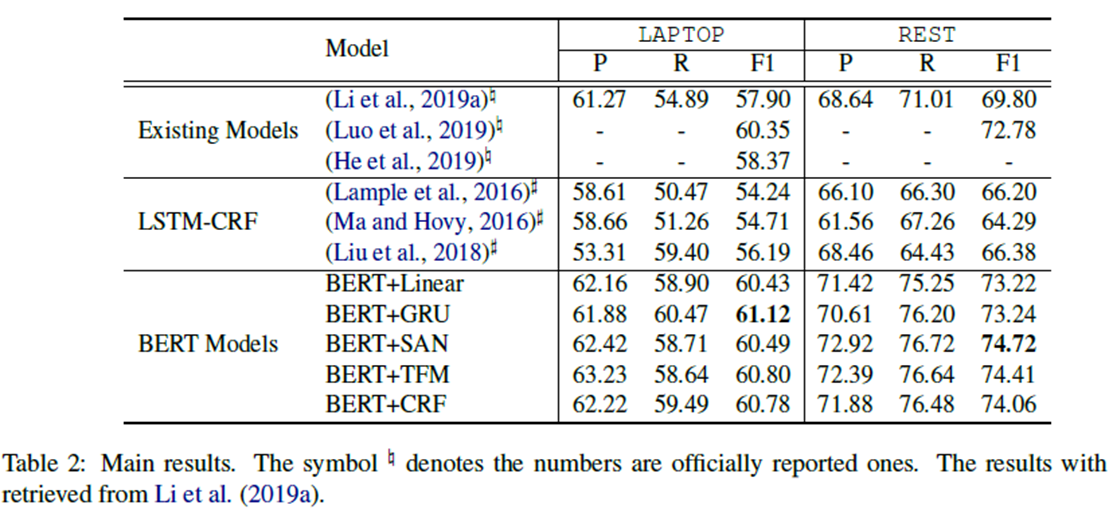
(另外说一句,这个大佬直接用了别人的试验过的数据,比较节省时间)
从表2中,我们惊奇地发现,仅仅引入一个简单的token级分类器,即BERT- linear,在不使用BERT的情况下已经超过了现有的工作,这表明BERT表示编码任意两个token之间的关联,在很大程度上缓解了线性E2E-ABSA层的上下文独立性问题。略强一些E2E-ABSA层带来了更好的性能,验证了合并上下文有助于序列建模的假设。
3.3 Over-parameterization问题
尽管我们使用最小的预培训 BERT模型,它仍然是过度参数化的任务(110M参数),这自然提出了一个问题:基于bert的模型是否倾向于过度适合小的训练集,针对这个问题,我们对BERT-GRU、BERT-TFM和BERT-CRF进行了3000步的训练,观察了开发集上F1措施的波动情况。 如图2所示,开发集上的F1得分相当稳定,并且不会随着训练的进行而大幅下降,这表明基于bert的模型对过度拟合具有非常强的鲁棒性。
3.4 Finetuning BERT or Not
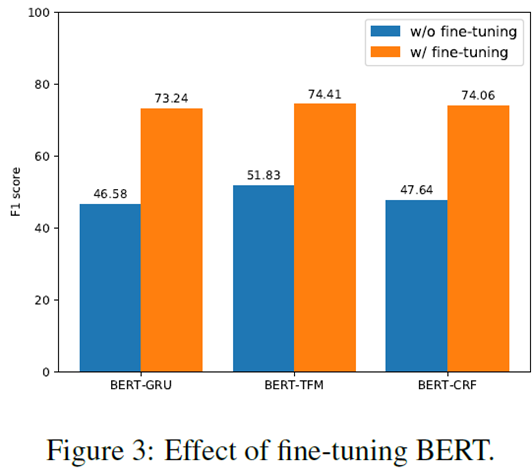
我们还研究了微调对最终性能的影响,具体来说,我们使用BERT来计算上下文化的toekn表示,但是在训练阶段保持BERT组件的参数不变。Figure3说明基于BERT的模型和保持BERT不变的模型的比较结果。显然,一般的BERT表示对于下游任务来说远远不能令人满意,而特定于任务的微调对于利用BERT的优势来提高性能是至关重要的。
4 Conclusion
在本文中,我们研究了嵌入BERT组件在(E2EABSA)的有效性。具体来说,我们将探索BERT嵌入组件和不同的神经模模型融合,并在两个基准数据集上进行了大量的实验。实验结果表明BERT-based 模型捕捉基于方面的情绪和它们对过度拟合的健壮性方面有很好表现。
参考文献:
【1】Zhifang Fan, Zhen Wu, Xin-Yu Dai, Shujian Huang,and Jiajun Chen. 2019. Target-oriented opinion
words extraction with target-fused neural sequence labeling. In NAACL, pages 2509–2518.
【2】Dehong Ma, Sujian Li, and Houfeng Wang. 2018a.Joint learning for targeted sentiment analysis. In EMNLP, pages 4737–4742.
【3】Martin Schmitt, Simon Steinheber, Konrad Schreiber,and Benjamin Roth. 2018. Joint aspect and polarity classification for aspect-based sentiment analysis with end-to-end neural networks. In EMNLP, pages 1109–1114.
【4】Xin Li, Lidong Bing, Piji Li, and Wai Lam. 2019a. A unified model for opinion target extraction and target sentiment prediction. In AAAI, pages 6714–6721.
【5】Hao Li and Wei Lu. 2017. Learning latent sentiment scopes for entity-level sentiment analysis. In AAAI, pages 3482–3489.
【6】Hao Li and Wei Lu. 2019. Learning explicit and implicit structures for targeted sentiment analysis.
【7】arXiv preprint arXiv:1909.07593.Jie Zhou, Jimmy Xiangji Huang, Qin Chen, Qinmin Vivian Hu, TingtingWang, and Liang He. 2019. Deep learning for aspect-level sentiment classification:Survey, vision and challenges. IEEE Access.
【8】Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. 2013. Distributed representations of words and phrases and their compositionality.In NeurIPS, pages 3111–3119.
【9】Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving language understanding by generative pre-training.
【10】Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners. OpenAI Blog, 1(8).
【11】Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of
deep bidirectional transformers for language understanding. In NAACL, pages 4171–4186. ---建议阅读
【12】Guillaume Lample and Alexis Conneau. 2019. Crosslingual language model pretraining. arXiv preprint arXiv:1901.07291.
【13】Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell,Ruslan Salakhutdinov, and Quoc V Le.
2019. Xlnet: Generalized autoregressive pretraining for language understanding. arXiv preprint
arXiv:1906.08237.
【14】Li Dong, Nan Yang, Wenhui Wang, Furu Wei, Xiaodong Liu, Yu Wang, Jianfeng Gao, Ming
Zhou, and Hsiao-Wuen Hon. 2019. Unified language model pre-training for natural language
understanding and generation. arXiv preprint arXiv:1905.03197.
【12】Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In NeurIPS, pages 5998–6008.---建议阅读
【13】Xin Li, Lidong Bing, Piji Li, and Wai Lam. 2019a. A unified model for opinion target extraction and target sentiment prediction. In AAAI, pages 6714–6721.
【14】Kyunghyun Cho, Bart van Merri¨enboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger
Schwenk, and Yoshua Bengio. 2014. Learning phrase representations using RNN encoder–decoder
for statistical machine translation. In EMNLP, pages 1724–1734. ---建议阅读
【15】Sepp Hochreiter and J¨urgen Schmidhuber. 1997. Long short-term memory. Neural computation, 9(8):1735–1780. ---建议阅读