目录
- 定义
- BLEU算法详解
- NLTK实现
一、定义
BLEU (其全称为Bilingual Evaluation Understudy), 其意思是双语评估替补。所谓Understudy (替补),意思是代替人进行翻译结果的评估。尽管这项指标是为翻译而发明的,但它可以用于评估一组自然语言处理任务生成的文本。
它是用于评估候选句子(candidate)和参考句子(reference)的差异的指标.它的取值范围在0.0到1.0之间, 如果两个句子完美匹配(perfect match), 那么BLEU是1.0, 反之, 如果两个句子完美不匹配(perfect mismatch), 那么BLEU为0.0.原论文可见【1】,IBM出品。
二、BLEU算法详解
2.1 主要公式
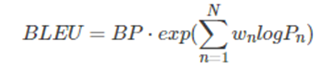
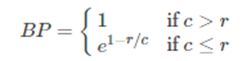
其中:BP(Brevity Penalty),翻译过来就是"过短惩罚"。由BP的公式可知取值范围是(0,1],候选句子越短,越接近0。c 表示候选句子长度,r 表示参考句子长度。
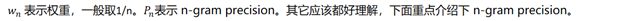
2.2 n-gram precision
candinate: the cat sat on the mat
reference: the cat is on the mat

三、NLTK实现
可以直接用工具包实现,代码如下:
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
from nltk.translate.bleu_score import sentence_bleu, corpus_bleu
from nltk.translate.bleu_score import SmoothingFunction
reference = [['The', 'cat', 'is', 'on', 'the', 'mat']]
candidate = ['The', 'cat', 'sat', 'on', 'the', 'mat']
smooth = SmoothingFunction() # 定义平滑函数对象
score = sentence_bleu(reference, candidate, weight=(0.25,0.25, 0.25, 0.25), smoothing_function=smooth.method1)
corpus_score = corpus_bleu([reference], [candidate], smoothing_function=smooth.method1)
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
代码说明:NLTK中提供了两种计算BLEU的方法,实际上在sentence_bleu中是调用了corpus_bleu方法
注意reference和candinate连个参数的列表嵌套不要错了(我的理解: 比Sentence的都多加了一个维度)
weight参数是设置不同的n−gram的权重,weight中的数量决定了计算BLEU时,会用几个n−gram,以上面为例,会用1−gram,2−gram,3−gram,4−gram(默认是4-gram,并且是均值,也就是不写参数也会是本例一样的效果)。SmoothingFunction是用来平滑log函数的结果的,防止fn=0时,取对数为负无穷。
参考文献
【1】来源 BLEU: a Method for Automatic Evaluation of Machine Translation
【2】机器翻译评价指标 — BLEU算法:https://www.cnblogs.com/jiangxinyang/p/10523585.html