目录
- RNN概述
- RNN模型
- RNN前向传播
- RNN反向传播算法
- 其它RNN
一、RNN概述
RNN(Recurrent Neural Network)是一类用于处理序列数据的神经网络。
首先我们要明确什么是序列数据,摘取百度百科词条:时间序列数据是指在不同时间点上收集到的数据,这类数据反映了某一事物、现象等随时间的变化状态或程度。这是时间序列数据的定义,当然这里也可以不是时间,比如文字序列,但总归序列数据有一个特点——后面的数据跟前面的数据有关系。
常见的序列有:一段连续的语音,一段连续的手写文字,一条句子等。这些序列比较长,且长度不一,比较难直接的拆分成一个个独立的样本来通过DNN/CNN进行训练。
说明:基础的神经网络只在层与层之间建立权连接,RNN最大的不同之处就是在层之间的神经元之间也建立的权连接
二、RNN模型
RNN模型有比较多的变种,这里介绍最主流的RNN模型结构如下:
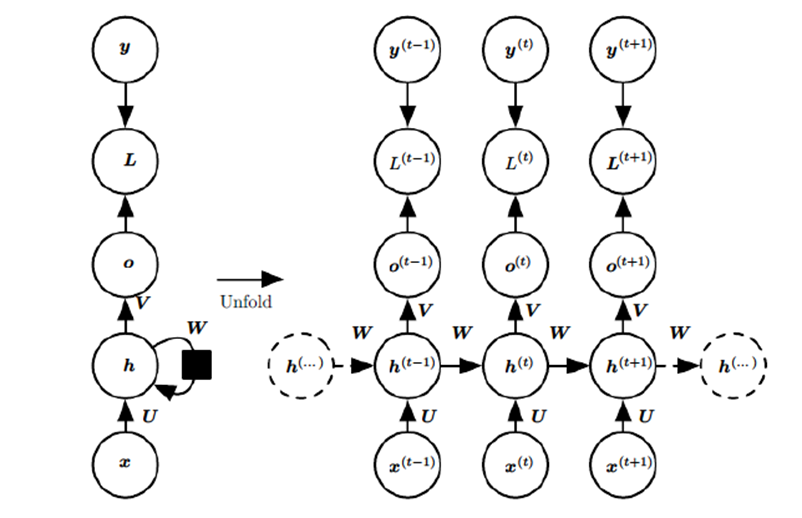
图中每个箭头代表做一次变换,也就是说箭头连接带有权值。左侧是折叠起来的样子,右侧是展开的形式,左侧中h旁边的箭头代表此结构中的"循环"体现在隐层。右图体现了按照时间展开的情形,也是本文重点关注的对象。
这幅图描述了在序列索引号t 附近RNN的模型。其中:
1)x(t)代表在序列索引号 t 时训练样本的输入。同样的,x(t-1) 和 x(t+1) 代表在序列索引号 t−1 和 t+1 时训练样本的输入。
2)h(t) 代表在序列索引号 t 时模型的隐藏状态。h(t)由x(t)和 h(t-1) 共同决定。
3)o(t) 代表在序列索引号 t 时模型的输出。o(t)只由模型当前的隐藏状态 h(t) 决定。
4)L(t) 代表在序列索引号 t 时模型的损失函数,模型整体的损失函数是所有的L(t)相加和。
5)y(t) 代表在序列索引号 t 时训练样本序列的真实输出。
6)U,W,V这三个矩阵就是我们的模型的线性关系参数,它在整个RNN网络中是共享的。也正是因为是共享的,它体现了RNN的模型的"循环反馈"的思想。
三、RNN前向传播
循环网络的前向传播算法非常简单,对于t时刻:

其中ϕ(.)为激活函数,一般来说会选择tanh函数,b为偏置。则 t 时刻的输出:
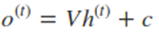
最终模型的预测输出为:
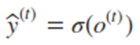
其中σ为激活函数,激活函数通常选择softmax函数。
四、RNN反向传播算法
BPTT(back-propagation through time)算法是常用的训练RNN的方法,其实本质还是BP算法,只不过RNN处理时间序列数据,故叫随时间反向传播。BPTT的中心思想和BP算法相同,沿着需要优化的参数的负梯度方向不断寻找更优的点直至收敛。当然这里的BPTT和DNN中的BP算法也有很大的不同点,即这里所有的 U, W, V 在序列的各个位置是共享的,反向传播时我们更新的是相同的参数。
对于RNN,由于我们在序列的每个位置都有损失函数,因此最终的损失L为:

对V求偏导:

而在求W和U的时候就比较的复杂了。在反向传播时,在某一序列位置 t 的梯度损失由当前文职的输出对应的梯度损失和序列索引位置 t + 1 时的梯度损失两部分共同决定的。对于W在某一序列位置 t 的梯度损失需要反向传播一步步的计算。
比如以t=3 时刻为例:
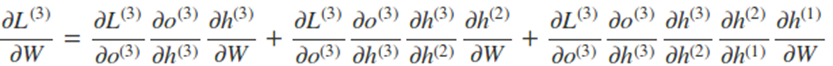
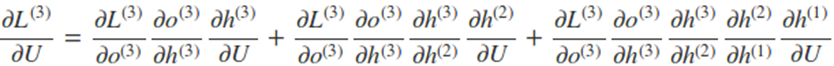
因此,在某个时刻的对 W 或是 U 的偏导数,需要追溯这个时刻之前所有时刻的信息。根据上面的式子可以归纳出 L 在 t 时刻对 W 和 U 偏导数的通式:

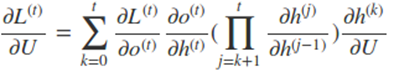
而对于里面的乘积部分,我们引入激活函数,则可以表示为:

或者是
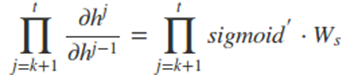
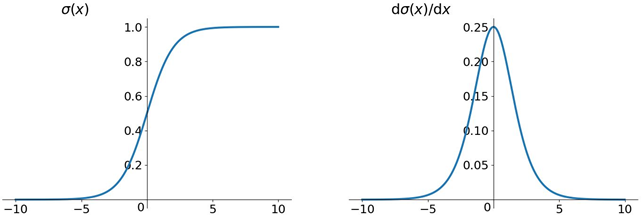
然而对于 Sigmoid 函数和 tanh 函数及其导数有以下的特点
sigmoid 函数及其导数
tanh 函数及其导数
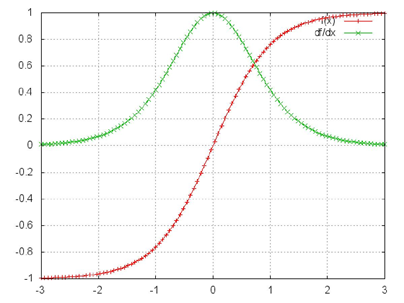
我们从中观察到,sigmoid 函数的导数范围是(0, 0.25], tanh 函数的导数范围是 (0, 1] ,它们的导数最大都不大于 1。因此在上面求梯度的乘积中,随着时间序列的不断深入,小数的累乘就会导致梯度越来越小,直到接近于 0,这就会引起梯度消失现象。梯度消失就意味着那一层的参数再也不更新了,则模型的训练毫无意义。Relu 函数一定程度上可以解决梯度消失的问题,但是容易引起梯度爆炸的问题。此外 tanh 函数的收敛速度要快于 sigmoid 函数,而且梯度消失的速度要慢于 sigmoid 函数。
RNN的特点本来就是能"追根溯源"利用历史数据,现在告诉我可利用的历史数据竟然是有限的,这就令人非常难受,解决"梯度消失"是非常必要的。解决"梯度消失"的方法主要有:
1、选取更好的激活函数
2、改变传播结构
关于第一点,一般选用ReLU函数作为激活函数,ReLU函数的图像为:
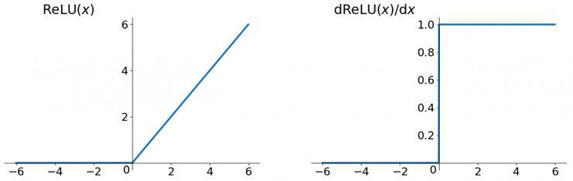
ReLU函数的左侧导数为0,右侧导数恒为1,这就避免了"梯度消失"的发生。但恒为1的导数容易导致"梯度爆炸",但设定合适的阈值可以解决这个问题。还有一点就是如果左侧横为0的导数有可能导致把神经元学死,不过设置合适的步长(学习旅)也可以有效避免这个问题的发生。
关于第二点,LSTM结构可以解决这个问题。下一篇文章进行展开描述。
五、其它RNN
以上是RNN的标准结构,然而在实际中这一种结构并不能解决所有问题,例如我们输入为一串文字,输出为分类类别,那么输出就不需要一个序列,只需要单个输出。如图:
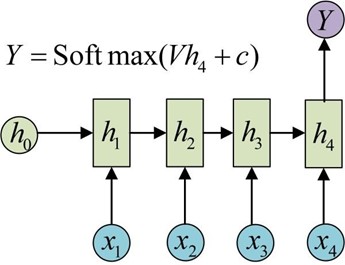
同样的,我们有时候还需要单输入但是输出为序列的情况。那么就可以使用如下结构:
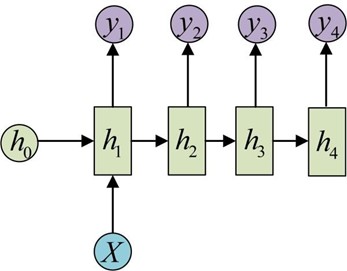
更多其他类型:https://blog.csdn.net/qq_16234613/article/details/79476763
主要参考:
https://blog.csdn.net/zhaojc1995/article/details/80572098
https://www.cnblogs.com/pinard/p/6509630.html#!comments
附件一:手写推导
