序列化
- 定义:把一个数据类型转换成 字符串、byets类型的过程就是序列化用途:1.需要把一个数据类型存储在文件中2.需要把一个数据类型通过网络传输的时候
1 import json
2 stu = {'name':'何青松','sex':'male'}
3 ret = json.dumps(stu) # 序列化的过程
4 print(stu,type(stu))#{'name': '何青松', 'sex': 'male'} <class 'dict'>
5 print(ret,type(ret))#{"name": "u4f55u9752u677e", "sex": "male"} <class 'str'>
6 d = json.loads(ret) # 反序列化的过程
7 print('d-->',d,type(d))#d--> {'name': '何青松', 'sex': 'male'} <class 'dict'>
1 lst = [1,2,3,4,'aaa','bbb']
2 ret = json.dumps(lst) # 序列化的过程
3 print(lst,type(lst))#[1, 2, 3, 4, 'aaa', 'bbb'] <class 'list'>
4 print(ret,type(ret))#[1, 2, 3, 4, "aaa", "bbb"] <class 'str'>
5 d = json.loads(ret) # 反序列化的过程
6 print('d-->',d,type(d))#d--> [1, 2, 3, 4, 'aaa', 'bbb'] <class 'list'>
json
优点
所有的语言都通用
缺点
只支持非常少的数据类型
对数据类型的约束很苛刻
字典的key必须是字符串,且所有的字符串都必须是用''表示
只支持:数字 字符串 列表 字典
1 反面教材:由于字典的key是数字1,经过序列化和反序列化后变成‘1’
2 stu = {'name':'何青松','sex':'male',1:('a','b')}
3 ret = json.dumps(stu) # 序列化的过程
4 print(ret,type(ret))#{"name": "u4f55u9752u677e", "sex": "male", "1": ["a", "b"]} <class 'str'>
5 d = json.loads(ret) # 反序列化的过程
6 print('d-->',d,type(d))#d--> {'name': '何青松', 'sex': 'male', '1': ['a', 'b']} <class 'dict'>
1 import json
2 dic = {'name':'何青松','sex':'male'}
3 str_dir1 = json.dumps(dic,ensure_ascii=False)#加上ensure_ascii=False,为了正常写入中文
4 str_dir2 = json.dumps(dic)
5 print(str_dir1)#{"name": "何青松", "sex": "male"}
6 print(str_dir2)#{"name": "u4f55u9752u677e", "sex": "male"}
7 with open('json_file','w',encoding='utf-8') as f:
8 f.write(str_dir1)
能不能多次向一个文件中dump,可以,但是不能多次load。
1 dic = {'name':'何青松','sex':'male'}
2 with open('json_file','w',encoding='utf-8') as f:
3 json.dump(dic,f,ensure_ascii=False)
4 json.dump(dic,f,ensure_ascii=False)
5 json.dump(dic,f,ensure_ascii=False)
6 json.dump(dic,f,ensure_ascii=False)
7 json.dump(dic,f,ensure_ascii=False)
8
9 with open('json_file','r',encoding='utf-8') as f:
10 dic = json.load(f)#JSONDecodeError: Extra data: line 1 column 31 (char 30)
方法 dump load 这两个方法 是完全和文件打交道的
2 dic = {'name':'何青松','sex':'male'}
3 with open('json_file','w',encoding='utf-8') as f:
4 json.dump(dic,f,ensure_ascii=False)
5
6 with open('json_file','r',encoding='utf-8') as f:
7 dic = json.load(f)
8 print(dic,dic['name'])
1 我有需求向文件中写入多个字典,用dumps和loads。
2 def my_dumps(dic):
3 with open('json_file', 'a', encoding='utf-8') as f:
4 dic_str = json.dumps(dic)
5 f.write(dic_str + '
')
6 dic1 = {'name':'何青松','sex':'male'}
7 dic2 = {'name':'关亮何','sex':'male'}
8 dic3 = {'name':'何思浩','sex':'male'}
9 my_dumps(dic1)
10 my_dumps(dic2)
11 my_dumps(dic3)
12 with open('json_file','r',encoding='utf-8') as f:
13 for line in f:
14 dic = json.loads(line.strip())
15 print(dic['name'])
json格式化
sort_keys:将数据根据keys的值进行排序。
indent:应该是一个非负的整型,如果是0,或者为空,则一行显示数据,
否则会换行且按照indent的数量显示前面的空白,这样打印出来的json数据也叫pretty-printed json
separators:分隔符,实际上是(item_separator, dict_separator)的一个元组,默认的就是(‘,’,’:’);
这表示dictionary内keys之间用“,”隔开,而KEY和value之间用“:”隔开。
1 import json
2 data = {'username':['李华','二愣子'],'sex':'male','age':16}
3 json_dic2 = json.dumps(data,sort_keys=True,indent=4,separators=(',',':'),ensure_ascii=False)
4 print(json_dic2)
pickle
1 import pickle
2 stu = {'name':'何青松','sex':'male',1:('a','b')}
3 ret = pickle.dumps(stu)
4 print(ret)#b'x80x03}qx00(Xx04x00x00x00nameqx01X x00x00x00xe4xbdx95xe9x9dx92x
5 d = pickle.loads(ret)
6 print(d,type(d))#{'name': '何青松', 'sex': 'male', 1: ('a', 'b')} <class 'dict'>
1 import pickle
2 class Course():
3 def __init__(self,name,price):
4 self.name = name
5 self.price = price
6 python = Course('python',29800)
7 linux = Course('linux',25800)
8 mysql = Course('mysql',18000)
9 ret = pickle.dumps(python)
10 print(ret)#b'x80x03c__main__
Course
qx00)x81qx01}qx02(Xx04x00x00
11 p = pickle.loads(ret)
12 print(p.name,p.price)#python 29800
13 with open('pickle_file','wb') as f:
14 pickle.dump(python,f)
15 with open('pickle_file','rb') as f:
16 course = pickle.load(f)
17 print(course.name)
操作文件文件必须以+b打开
在load的时候 如果这个要被load的内容所在的类不在内存中,会报错
pickle支持多次dump和多次load(需要异常处理)
1 import pickle
2 class Course():
3 def __init__(self,name,price):
4 self.name = name
5 self.price = price
6 python = Course('python',29800)
7 linux = Course('linux',25800)
8 mysql = Course('mysql',18000)
9 def my_dump(course):
10 with open('pickle','ab') as f:
11 pickle.dump(course,f)
12 my_dump(python)
13 my_dump(linux)
14 my_dump(mysql)
15 with open('pickle','rb') as f:
16 while True:
17 try:
18 content = pickle.load(f)
19 print(content.name)
20 except EOFError:
21 break
时间模块
三种格式
时间戳时间 浮点数 秒为单位
1970.1.1 0:0:0 英国伦敦时间
1970.1.1 8:0:0 东8区
结构化时间 元组
格式化时间 str数据类型的
1 fmt1 =time.strftime('%H:%M:%S')
2 fmt2 =time.strftime('%Y-%m-%d')
3 fmt3 =time.strftime('%y-%m-%d')
4 fmt4 =time.strftime('%c')
5 print(fmt1)#15:30:12
6 print(fmt2)#2018-09-04
7 print(fmt3)#18-09-04
8 print(fmt4)#Tue Sep 4 15:30:12 2018
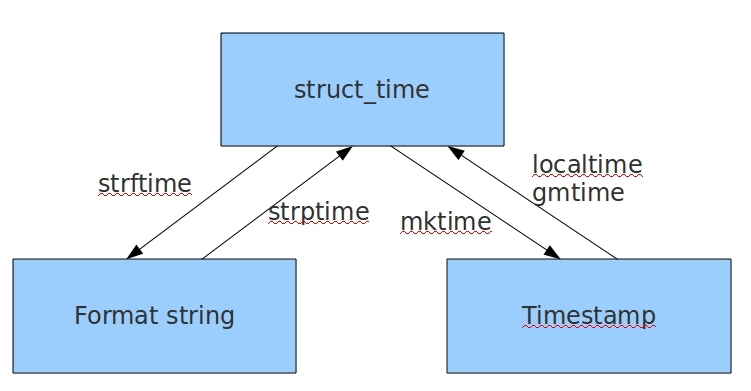
str_time = '2018-8-8'
struct_time = time.strptime(str_time,'%Y-%m-%d')
print(struct_time)#time.struct_time(tm_year=2018, tm_mon=8, tm_mday=8, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=2, tm_yday=220, tm_isdst=-1)
timestamp = time.mktime(struct_time)
print(timestamp)#1533657600.0
timestamp = 1500000000
struct_time = time.localtime(timestamp)
fmt_time = time.strftime('%Y-%m-%d %H:%M:%S',struct_time)
print(fmt_time)#2017-07-14 10:40:00
写函数,计算本月1号的时间戳时间
通过我拿到的这个时间,能迅速的知道我现在所在时间的年 月
1 def get_timestamp():
2 fmt_time = time.strftime('%Y-%m-1')
3 struct = time.strptime(fmt_time,'%Y-%m-%d')
4 res = time.mktime(struct)
5 return res
6 ret = get_timestamp()
7 print(ret)
随机数模块
1 import random
2 # 取随机小数 *
3 print(random.random()) #(0,1)
4 print(random.uniform(2,3)) #(n,m)
5
6 # 取随机整数 ****
7 print(random.randint(1,2)) # [1,2],可以去到1或者2
8 print(random.randrange(1,2)) # [1,2)取不到2
9 print(random.randrange(1,100,2))#取100以内的奇数
1 lst = [1,2,3,4,5,('a','b'),'cc','dd']
2 ret = random.choice(lst)#随机取一个
3 print(ret)
4 ret = random.choice(range(100))
5 print(ret)
6 ret = random.sample(lst,3)#列表元素任意3个组合
7 print(ret)
1 # 乱序 ***
2 lst = [1,2,3,4,5,('a','b'),'cc','dd']
3 random.shuffle(lst)
4 print(lst)
抢红包:
1 def lucky_money(money,num):
2 ret = random.sample(range(1,money*100),num-1)
3 ret.sort()
4 ret.insert(0,0)
5 ret.append(money*100)
6 for i in range(len(ret)-1):
7 money = ret[i+1] - ret[i]
8 yield money/100
10 for money in lucky_money(2,5):
11 print(money)
验证码应用:
每一位上出现的内容既可以是数字 也可以是字母
随机生成一个数字 一个大写字母 一个小写字母
1 def get_code(n):
2 code = ''
3 for i in range(n):
4 num = str(random.randint(0,9))
5 alpha_upper = chr(random.randint(65, 90))
6 alpha_lower = chr(random.randint(97, 122))
7 c = random.choice([num,alpha_upper,alpha_lower])
8 code += c
9 return code
10 ret = get_code()
11 print(ret)
进阶版
1 def get_code(n = 6,alph_flag = True):
2 code = ''
3 for i in range(n):
4 c = str(random.randint(0,9))
5 if alph_flag:
6 alpha_upper = chr(random.randint(65, 90))
7 alpha_lower = chr(random.randint(97, 122))
8 c = random.choice([c,alpha_upper,alpha_lower])
9 code += c
10 return code
11 ret = get_code()
12 print(ret)
OS模块:
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.system("bash command") 运行shell命令,直接显示
os.popen("bash command).read() 运行shell命令,获取执行结果
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.path
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) 返回path的大小
stat 结构:
st_mode: inode 保护模式
st_ino: inode 节点号。
st_dev: inode 驻留的设备。
st_nlink: inode 的链接数。
st_uid: 所有者的用户ID。
st_gid: 所有者的组ID。
st_size: 普通文件以字节为单位的大小;包含等待某些特殊文件的数据。
st_atime: 上次访问的时间。
st_mtime: 最后一次修改的时间。
st_ctime: 由操作系统报告的"ctime"。在某些系统上(如Unix)是最新的元数据更改的时间,在其它系统上(如Windows)是创建时间(详细信息参见平台的文档)。
stat 结构
os.sep 输出操作系统特定的路径分隔符,win下为"\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"
",Linux下为"
"
os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
1 print('-->cwd : ',os.getcwd())
2 open('file','w').close() 文件在执行这个文件的目录下创建了不是当前被执行的文件所在的目录,而是执行这个文件所在的目录
工作目录在哪儿,所有的相对目录文件的创建,都是在哪儿执行这个文件,就在哪儿创建,可以用__file__规避
6 os.chdir('D:骑士计划PYTHON1期day23')#切换到当前目录
7 open('file3','w').close()
8 print('-->cwd : ',os.getcwd())
collections模块
在内置数据类型(dict、list、set、tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等。
1.namedtuple: 生成可以使用名字来访问元素内容的tuple
2.deque: 双端队列,可以快速的从另外一侧追加和推出对象
3.Counter: 计数器,主要用来计数
4.OrderedDict: 有序字典
5.defaultdict: 带有默认值的字典
使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序。
如果要保持Key的顺序,可以用OrderedDict:
1 from collections import OrderedDict
2 dd = OrderedDict([('a',1),('k1','v1')])
3 for k in dd:
4 print(k,dd[k])
5 dd['k2'] = 'v2'
6 print(dd)
注意,OrderedDict的Key会按照插入的顺序排列,不是Key本身排序:
defaultdict
有如下值集合 [11,22,33,44,55,66,77,88,99,90...],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。
from collections import defaultdict
values = [11, 22, 33,44,55,66,77,88,99,90]
my_dict = defaultdict(list)
for value in values:
if value>66:
my_dict['k1'].append(value)
else:
my_dict['k2'].append(value)
使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict:
>>> from collections import defaultdict
>>> dd = defaultdict(lambda: 'N/A')
>>> dd['key1'] = 'abc'
>>> dd['key1'] # key1存在
'abc'
>>> dd['key2'] # key2不存在,返回默认值
'N/A'
namedtuple
from collections import namedtuple
birth = namedtuple('Struct_time',['year','month','day'])
b1 = birth(2018,7,5)
print(type(b1))#<class '__main__.Struct_time'>
print(b1.year)#2018
print(b1.month)
print(b1.day)
print(b1)#Struct_time(year=2018, month=7, day=5)
# 可命名元组非常类似一个只有属性没有方法的类
# ['year','month','day']是对象属性名
# Struct_time是类 的名字
# 这个类最大的特点就是一旦实例化 不能修改属性的值
deque
from collections import deque
dq = deque()
dq.append(1)
dq.append(2)
dq.appendleft(3)#从左增加
print(dq)#deque([3, 1, 2])
print(dq.pop())#2
print(dq.popleft())#3 从左边删
print(dq)#deque([1])
import queue
q = queue.Queue() # 队列
q.put(1)
q.put(2)
q.put('aaa')
q.put([1,2,3])
q.put({'k':'v'})
print(q.get())#1
print(q.get())#2
hashlib
摘要算法
它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示)。
不同的字符串通过这个算法的计算得到的密文总是不同的
相同的算法 相同的字符串 获得的结果总是相同的
注意:
1.文件操作 : f.readlines()浪费内存
2.md5_obj不能重复使用
hashlib 摘要算法
多种算法
md5算法 :32位16进制的数字字符组成的字符串
应用最广大的摘要算法
效率高,相对不复杂,如果只是传统摘要不安全
sha算法 :40位的16进制的数字字符组成的字符串
sha算法要比md5算法更复杂
且shan n的数字越大算法越复杂,耗时越久,结果越长,越安全
算法不可逆
MD5算法:
举例:md5_obj = hashlib.md5()
# md5_obj.update(b'alex3714')
md5_obj.update('999'.encode('utf-8'))
ret = md5_obj.hexdigest()
print(ret,type(ret),len(ret))
'hello,world'分段加密和一次加密效果一样:
import hashlib
md5_obj = hashlib.md5()
md5_obj.update('hello,world'.encode('utf-8'))
ret = md5_obj.hexdigest()
print(ret)#3cb95cfbe1035bce8c448fcaf80fe7d9
md5_obj = hashlib.md5()
md5_obj.update('hello'.encode('utf-8'))
md5_obj.update(',world'.encode('utf-8'))
ret = md5_obj.hexdigest()
print(ret)#3cb95cfbe1035bce8c448fcaf80fe7d9
登录验证应用:
def get_md5(s):
md5_obj = hashlib.md5()
md5_obj.update(s.encode('utf-8'))
ret = md5_obj.hexdigest()
return ret
usrname = input('username : ')
passwd = input('password : ')
with open('userinfo') as f:
for line in f:
usr,pwd = line.strip().split('|')
if usrname == usr and get_md5(passwd) == pwd:
print('登录成功')
break
else:
print('登录失败')
sha算法:
sha_obj = hashlib.sha512()
sha_obj.update('alex3714'.encode('utf-8'))
ret = sha_obj.hexdigest()
print(len(ret),ret)
动态加盐
每一个用户创建一个盐 - 用户名
def get_md5(user,s):
md5_obj = hashlib.md5(user.encode('utf-8'))#加入用户名
md5_obj.update(s.encode('utf-8'))
ret = md5_obj.hexdigest()
return ret
print(get_md5('alex','alex3714'))
文件的一致性校验应用:
import os
import hashlib
def get_file_md5(file_path,buffer = 1024):
md5_obj = hashlib.md5()
# file_path = r'3.习题讲解2.mp4' # 路径里不能有空格
file_size = os.path.getsize(file_path)
with open(file_path,'rb') as f:
while file_size:
content = f.read(buffer) # 1024 1024 1024 。。。 5
file_size -= len(content) # 5 -=5
md5_obj.update(content)
return md5_obj.hexdigest()
print(get_file_md5( r'3.习题讲解2.mp4'))
logging模块
import logging
logging.basicConfig(level=logging.INFO)
logging.debug('debug message') # 计算或者工作的细节
logging.info('info message') # 记录一些用户的增删改查的操作
logging.warning('input a string type') # 警告操作
logging.error('error message') # 错误操作
logging.critical('critical message') # 批判的 直接导致程序出错退出的
# 简单配置
logging.basicConfig(level=logging.INFO,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
datefmt='%c',
filename='test.log')
logging.warning('input a string type') # 警告操作
logging.error('EOF ERROR ') # 警告操作
logging.info('小明买了三斤鱼') # 警告操作
# 对象的配置
# 解决中文问题
# 同时向文件和屏幕输出内容
# 先创建一个log对象 logger
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
# 还要创建一个控制文件输出的文件操作符
fh = logging.FileHandler('mylog.log',encoding='utf-8')
# 还要创建一个控制屏幕输出的屏幕操作符
sh = logging.StreamHandler()
# 要创建一个格式
fmt = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
fmt2 = logging.Formatter('%(asctime)s - %(name)s[line:%(lineno)d] - %(levelname)s - %(message)s')
# 文件操作符 绑定一个 格式
fh.setFormatter(fmt)
# 屏幕操作符 绑定一个 格式
sh.setFormatter(fmt2)
sh.setLevel(logging.WARNING)
# logger对象来绑定:文件操作符, 屏幕操作符
logger.addHandler(sh)
logger.addHandler(fh)