爬虫简介
近年来,随着网络应用的逐渐扩展和深入,如何高效的获取网上数据成为了无数公司和个人的追求,在大数据时代,谁掌握了更多的数据,谁就可以获得更高的利益,而网络爬虫是其中最为常用的一种从网上爬取数据的手段。
网络爬虫,即Web Spider,是一个很形象的名字。如果把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。网络蜘蛛是通过网页的链接地址来寻找网页的。从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。
爬虫的价值
互联网中最有价值的便是数据,比如天猫商城的商品信息,链家网的租房信息,雪球网的证券投资信息等等,这些数据都代表了各个行业的真金白银,可以说,谁掌握了行业内的第一手数据,谁就成了整个行业的主宰,如果把整个互联网的数据比喻为一座宝藏,那我们的爬虫课程就是来教大家如何来高效地挖掘这些宝藏,掌握了爬虫技能, 你就成了所有互联网信息公司幕后的老板,换言之,它们都在免费为你提供有价值的数据。
robots.txt协议
如果自己的门户网站中的指定页面中的数据不想让爬虫程序爬取到的话,那么则可以通过编写一个robots.txt的协议文件来约束爬虫程序的数据爬取。robots协议的编写格式可以观察淘宝网的robots(访问www.taobao.com/robots.txt即可)。但是需要注意的是,该协议只是相当于口头的协议,并没有使用相关技术进行强制管制,所以该协议是防君子不防小人。但是我们在学习爬虫阶段编写的爬虫程序可以先忽略robots协议。
爬虫的基本流程
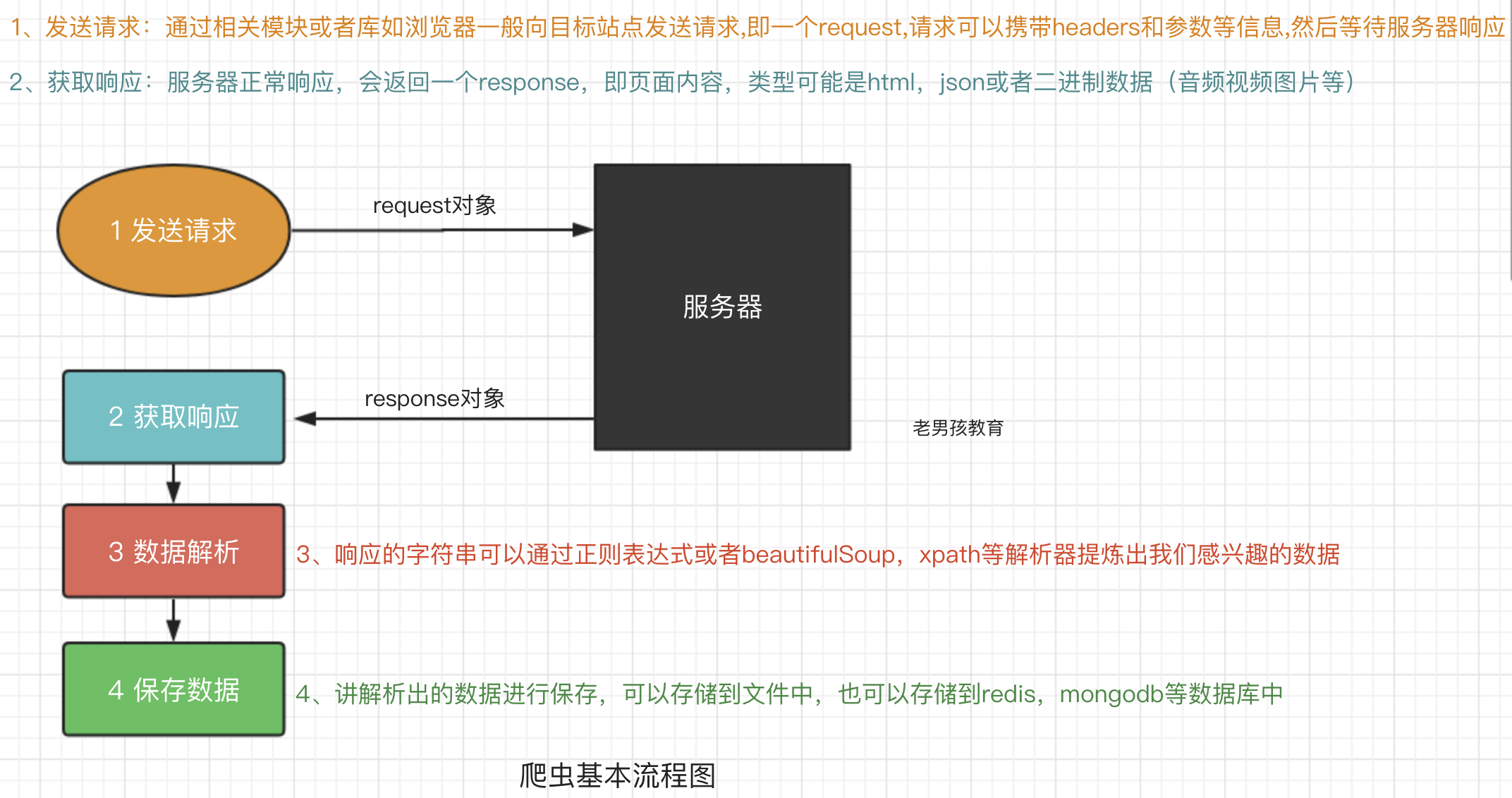
requests模块
Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库,Requests它会比urllib更加方便,可以节约我们大量的工作。一句话,requests是python实现的最简单易用的HTTP库,建议爬虫使用requests库。默认安装好python之后,是没有安装requests模块的,需要单独通过pip安装
requests模块支持的请求
import requests requests.get("http://httpbin.org/get") requests.post("http://httpbin.org/post") requests.put("http://httpbin.org/put") requests.delete("http://httpbin.org/delete") requests.head("http://httpbin.org/get") requests.options("http://httpbin.org/get")
get请求
1 基本请求
import requests response=requests.get('https://www.jd.com/',) with open("jd.html","wb") as f: f.write(response.content)
2 含参数请求
import requests response=requests.get('https://s.taobao.com/search?q=手机') response=requests.get('https://s.taobao.com/search',params={"q":"美女"})
3 含请求头请求
import requests response=requests.get('https://dig.chouti.com/', headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36', } )
4 含cookies请求
import uuid import requests url = 'http://httpbin.org/cookies' cookies = dict(sbid=str(uuid.uuid4())) res = requests.get(url, cookies=cookies) print(res.text)
post请求
data参数
requests.post()用法与requests.get()完全一致,特殊的是requests.post()多了一个data参数,用来存放请求体数据
response=requests.post("http://httpbin.org/post",params={"a":"10"}, data={"name":"yuan"})
发送json数据
import requests res1=requests.post(url='http://httpbin.org/post', data={'name':'yuan'}) #没有指定请求头,#默认的请求头:application/x-www-form-urlencoed print(res1.json()) res2=requests.post(url='http://httpbin.org/post',json={'age':"22",}) #默认的请求头:application/json print(res2.json())
response对象
常见属性
import requests respone=requests.get('https://sh.lianjia.com/ershoufang/') # respone属性 print(respone.text) print(respone.content) print(respone.status_code) print(respone.headers) print(respone.cookies) print(respone.cookies.get_dict()) print(respone.cookies.items()) print(respone.url) print(respone.history) print(respone.encoding)
编码问题
import requests response=requests.get('http://www.autohome.com/news') response.encoding='gbk' #汽车之家网站返回的页面内容为gb2312编码的,而requests的默认编码为ISO-8859-1,如果不设置成gbk则中文乱码 with open("res.html","w") as f: f.write(response.text)
下载二进制文件(图片,视频,音频)
import requests response=requests.get('http://bangimg1.dahe.cn/forum/201612/10/200447p36yk96im76vatyk.jpg') with open("res.png","wb") as f: f.write(response.content) # 比如下载视频时,如果视频100G,用response.content然后一下子写到文件中是不合理的 for line in response.iter_content(): f.write(line)
解析json数据
import requests import json response=requests.get('http://httpbin.org/get') res1=json.loads(response.text) #太麻烦 res2=response.json() #直接获取json数据 print(res1==res2)
Redirection and History
默认情况下,除了 HEAD, Requests 会自动处理所有重定向。可以使用响应对象的 history 方法来追踪重定向。Response.history 是一个 Response 对象的列表,为了完成请求而创建了这些对象。这个对象列表按照从最老到最近的请求进行排序。
import requests r = requests.get('http://github.com') print(r.history)
另外,还可以通过 allow_redirects 参数禁用重定向(默认开启)处理:
response=requests.get("http://www.autohome.com.cn/beijing/", allow_redirects=False) print(response)
requests进阶用法
代理
一些网站会有相应的反爬虫措施,例如很多网站会检测某一段时间某个IP的访问次数,如果访问频率太快以至于看起来不像正常访客,它可能就会会禁止这个IP的访问。
所以我们需要设置一些代理服务器,每隔一段时间换一个代理,就算IP被禁止,依然可以换个IP继续爬取。
res=requests.get('http://httpbin.org/ip', proxies={'http':'110.83.40.27:9999'}).json() print(res)
爬虫案例
豆瓣网电影top250
# 获取豆瓣top250所有电影的名称,url,评分,评论数 import requests import re import json import time from concurrent.futures import ThreadPoolExecutor tpe=ThreadPoolExecutor() # 1 发送请求,获取相应 def get_page(url): res=requests.get(url) return res # 2 解析数据 def parser(res): reg=re.compile('<div class="item">.*?<a href="(?P<url>.*?)">.*?<span class="title">(?P<title>.*?)</span>.*?<span class="rating_num".*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)人评价</span>',re.S) ret_iter=reg.finditer(res.text) print("ret_iter",ret_iter) return ret_iter # 3 存储数据 def store(ret_iter): # 存储文件中 movie_info={} for i in ret_iter: print("OK") print(i.group("url")) print(i.group("title")) print(i.group("rating_num")) print(i.group("comment_num")) movie_info["url"]=i.group("url") movie_info["title"]=i.group("title") movie_info["rating_num"]=i.group("rating_num") movie_info["comment_num"]=i.group("comment_num") with open("douban.txt",'a',encoding="utf8") as f: f.write(json.dumps(movie_info,ensure_ascii=False)+" ") def spider_movie(url): res=get_page(url) ret_iter=parser(res) store(ret_iter) def main(): for i in range(10): url = "https://movie.douban.com/top250?start=%s&filter="%i*25 tpe.submit(spider_movie,url) if __name__ == '__main__': start = time.time() main() print("cost time:%s" % (time.time() - start))
github的home页
import requests import re #第一步: 请求获取token,以便通过post请求校验 session=requests.session() res=requests.get("https://github.com/login") authenticity_token=re.findall('name="authenticity_token" value="(.*?)"',res.text)[0] print(authenticity_token) # 第二步 构建post请求数据 data={ "login": "yuanchenqi0316@163.com", "password":"yuanchenqi0316", "commit": "Sign in", "utf8": "✓", "authenticity_token": authenticity_token } headers={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36" } res=requests.post("https://github.com/session",data=data,headers=headers,cookies=res.cookies.get_dict()) with open("github.html","wb") as f: f.write(res.content)