一、环境搭建
1、安装第三方包nltk
pip intall nltk==3.4.5
2、安装 nltk_data
nltk_data 存放了很多语料数据, 包括大量的数据集,本文中就是用到了其中的 positive_tweets 和 negative_tweets 两个数据集来训练模型
安装方式有两种, 离线和在线, 推荐【使用离线】, 因为数据量很大, 在线下载通常会失败
[ a ] 在线下载
python交互式命令行中输入
import nltk nltk.download()
执行后会弹出下载窗口, 如果不需要全量下载, 选择对应分类下, 进行点击下载即可,
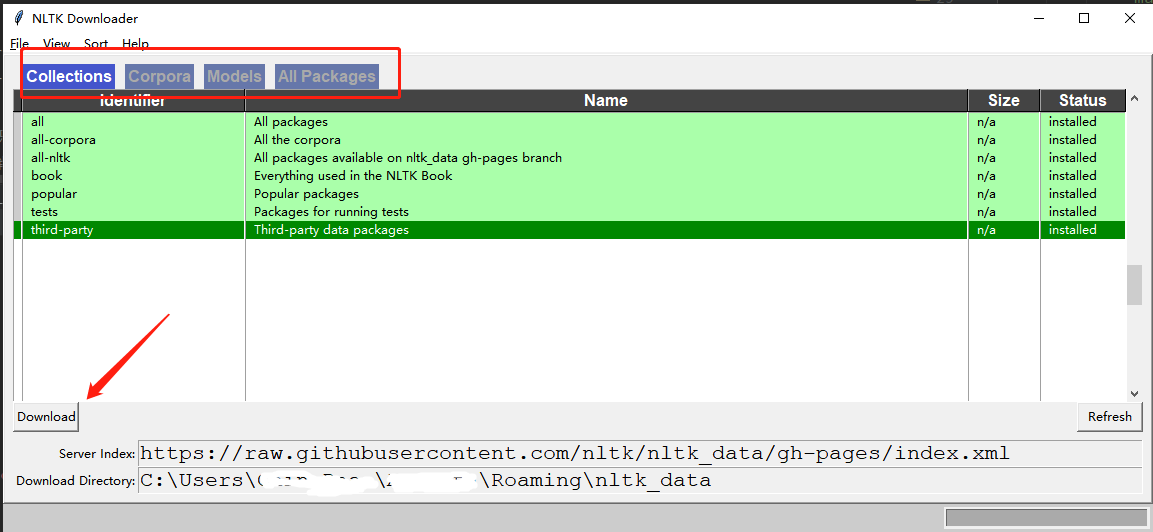
下载成功后会相应提示 installed 或者指定包进行下载, 同样还是python交互式命令行输入
import nltknltk.download('punkt')
[ b ] 离线下载 (推荐使用)
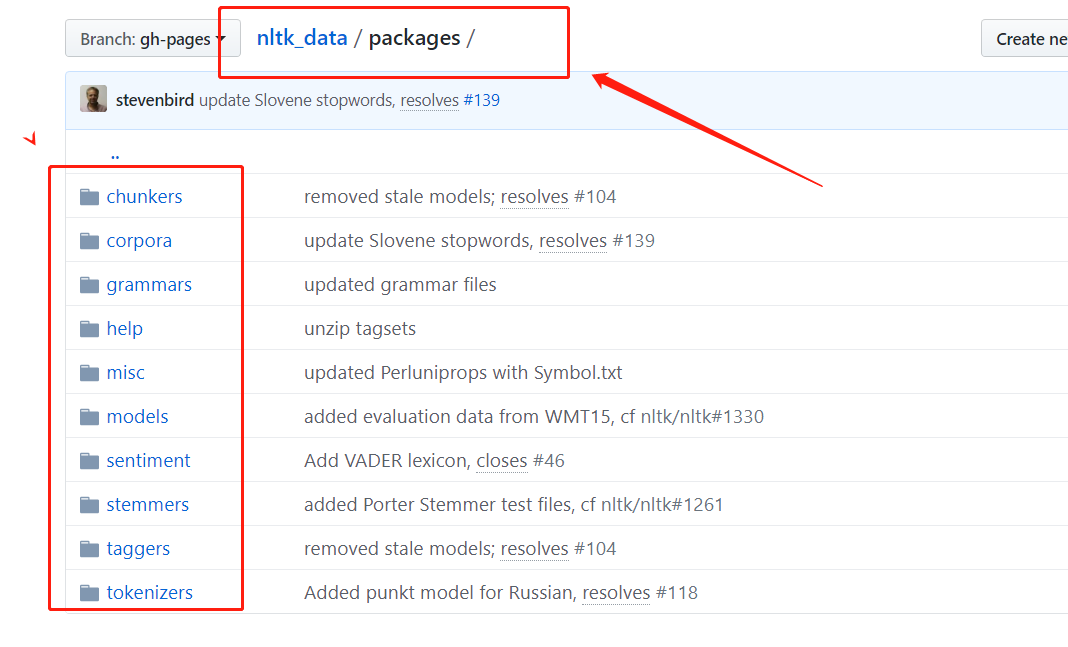
GitHub 下载地址:https://github.com/nltk/nltk_data
主要用到的是packages 文件夹下的内容

这就是全部的nltk_data 的内容
下载后需要进行简单配置
1、 将下载的packages 文件夹重命名为nltk_data

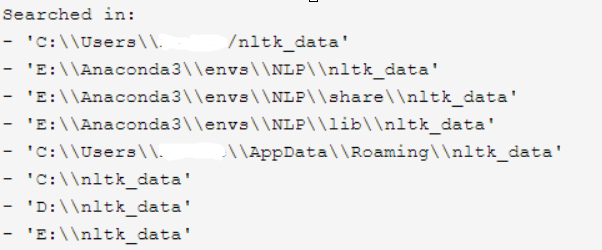
2、将重命名后的 nltk_data文件夹放置到nltk可以找到的路径下, 查看方法为 :
nltk_data文件夹放置到nltk可以找到的路径下, 查看方法为 :
>>>from nltk import data >>>data.find('.') FileSystemPathPointer('C:\Users\用户\AppData\Roaming\nltk_data') # 会输出本地加载路径, 直接放置在Roaming下即可
或者出现以下输出, 将nltk_data文件夹放在任意目录下也可以
到此, 环境就已经准备好啦~~~
二、步骤
-
分词
-
数据预处理
-
构造模型数据
-
训练模型
-
使用模型进行预测分析
三、加载数据集
导包
import re import string import random from nltk.corpus import twitter_samples from nltk.tag import pos_tag, pos_tag_sents from nltk.stem.wordnet import WordNetLemmatizer from nltk.corpus import stopwords from nltk import FreqDist
加载数据集:
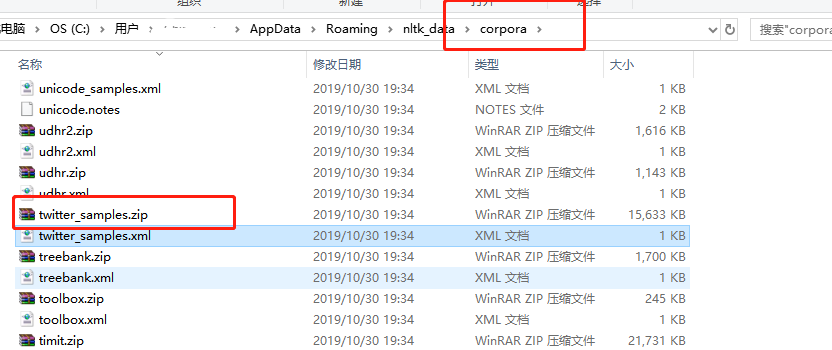
使用的是twitter_samples下的 negative_tweets.json:【5000条带有负面情感的推文】 和 positive_tweets.json:【5000条带有正面情感的推文 用于训练模型】,可以讲压缩包解压出来, 看下里面的json 文件的内容
使用代码获取推文内容
positive_tweets = twitter_samples.strings('positive_tweets.json')
negative_tweets = twitter_samples.strings('negative_tweets.json') # 可以打印看下分析的推文内容
四、分词
# 分词 po_fenci_res = fenci(po_file_name)[:2] be_fenci_res = fenci(ne_file_name)[:2] # 数据量比较大, 所以仅取前2条 print('积极分词结果: {}'.format(po_fenci_res)) print('消极分词结果: {}'.format(be_fenci_res)) # 积极分词结果: [['#FollowFriday', '@France_Inte', '@PKuchly57', '@Milipol_Paris', 'for', 'being', 'top', 'engaged', 'members', 'in', 'my', 'community', 'this', 'week', ':)'], ['@Lamb2ja', 'Hey', 'James', '!', 'How', 'odd', ':/', 'Please', 'call', 'our', 'Contact', 'Centre', 'on', '02392441234', 'and', 'we', 'will', 'be', 'able', 'to', 'assist', 'you', ':)', 'Many', 'thanks', '!']] # 消极分词结果: [['hopeless', 'for', 'tmr', ':('], ['Everything', 'in', 'the', 'kids', 'section', 'of', 'IKEA', 'is', 'so', 'cute', '.', 'Shame', "I'm", 'nearly', '19', 'in', '2', 'months', ':(']]
五、数据规范化
数据规范化包括以下步骤
- 词性标注
- 垃圾数据处理
- 词性还原
def cleaned_list_func(evert_tweet): """ 数据预处理 :param evert_tweet: 每条推文 / 每条待分析的英文句子 :return: 处理后的单词, 一维列表 """ new_text = [] cixing_list = pos_tag(evert_tweet) # [('', 'NN'), ('', 'NNS'), ()] print('每条推文的词性标注结果:{}'.format(cixing_list)) for word, cixing in cixing_list: word = re.sub('http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+#]|[!*(),]|(?:[0-9a-fA-F][0-9a-fA-F]))+', '', word) # 去掉网址的正则规则 word = re.sub('(@[A-Za-z0-9_]+)', '', word) # 去掉人民的规则, 带有@的部分 if cixing.startswith('NN'): # 将标注的词性进行判断, 替换为英文的标准词性表示 pos = 'n' elif cixing.startswith('VB'): pos = 'v' else: pos = 'a' lemmatizer = WordNetLemmatizer() # 使用WordNetLemmatizer类下的lemmatize方法进行词性还原
new_word = lemmatizer.lemmatize(word, pos)
if len(new_word) > 0 and new_word not in string.punctuation and new_word.lower() not in stopwords.words('english'):
new_text.append(new_word.lower())
return new_text
# 数据规范化
positive_cleaned_list = []
negative_cleaned_list = []
for i in po_fenci_res:
positive_cleaned = cleaned_list_func(i)
positive_cleaned_list.append(positive_cleaned)
print('处理后的积极推文结果: {}'.format(positive_cleaned_list))
print('原积极数据对比: {}'.format(positive_tweets[:2]))
经过词性标注的结果为
# 每条推文的词性标注结果:[('#FollowFriday', 'JJ'), ('@France_Inte', 'NNP'), ('@PKuchly57', 'NNP'), ('@Milipol_Paris', 'NNP'), ('for', 'IN'), ('being', 'VBG'), ('top', 'JJ'), ('engaged', 'VBN'), ('members', 'NNS'), ('in', 'IN'), ('my', 'PRP$'), ('community', 'NN'), ('this', 'DT'), ('week', 'NN'), (':)', 'NN')]
数据处理后的推文及原数据的对比
# 处理后的积极推文结果: [['#followfriday', 'top', 'engage', 'member', 'community', 'week', ':)'], ['hey', 'james', 'odd', ':/', 'please', 'call', 'contact', 'centre', '02392441234', 'able', 'assist', ':)', 'many', 'thanks']] # 原积极数据对比: ['#FollowFriday @France_Inte @PKuchly57 @Milipol_Paris for being top engaged members in my community this week :)', '@Lamb2ja Hey James! How odd :/ Please call our Contact Centre on 02392441234 and we will be able to assist you :) Many thanks!']
六、构造模型数据
def get_tweets_for_model(clean_tokens_list, tag): """ 准备模型数据 :param clean_tokens_list: 处理后的推文 二维列表 :param tag: 标签类别 :return: 一维列表, 元素是二元元组 """ li = [] for every_tweet in clean_tokens_list: data_dict = dict([token, True] for token in every_tweet) # {'':true,'':true} li.append((data_dict, tag)) return li
# 准备模型数据
po_for_model = get_tweets_for_model(positive_cleaned_list, 'Positive')
ne_for_model = get_tweets_for_model(negative_cleaned_list, 'Negative')
print('为模型准备的积极数据: {}'.format(po_for_model))
print('为模型准备的消极数据: {}'.format(ne_for_model))
此时数据结构为
# 为模型准备的消极数据: [({'hopeless': True, 'tmr': True, ':(': True}, 'Negative'), ({'everything': True, 'kid': True, 'section': True, 'ikea': True, 'cute': True, 'shame': True, "i'm": True, 'nearly': True, '19': True, '2': True, 'month': True, ':(': True}, 'Negative')]
七、准备训练集和测试集
model_data = po_for_model + ne_for_model random.shuffle(model_data) # 打乱 train_data = model_data[:7000] # 前7000作为训练集 test_data = model_data[7000:] # 其余作为测试机, 测试训练出来的模型准确度
八、训练和测试模型
def train_model(train_data, test_data): """ 训练及测试模型 :param train_data: 训练集 :param test_data: 测试集 :return: 训练后的模型 """ from nltk import classify from nltk import NaiveBayesClassifier model = NaiveBayesClassifier.train(train_data) print('模型准确率为: {}'.format(classify.accuracy(model, test_data))) print(model.show_most_informative_features(10)) return model
# 训练及测试模型
model = train_model(train_data, test_data)
九、使用模型预测数据
def test(model, test_text): """ 使用训练好的模型预测数据 :param model: :param test_text: 待分析的句子 :return: """ from nltk.tokenize import word_tokenize custom_tokens = cleaned_list_func(word_tokenize(test_text)) result = dict([token, True] for token in custom_tokens) yuce_res = model.classify(result) print('内容: {} 预测结果: {}'.format(test_text, yuce_res))
test_list = [
"I was sad on the day you went away,I'm not the man your heart is missing,that's why you go away I know.",
"My heart is being cut by the knife that is called MISSING YOU. NOthing in the world can destroy me except losing you. My memory of you devours every cell of my blood",
"I will always be there for you.",
'I fuck you fuck your mother fuck your father fuck your family',
"Don't worry when you are not recognized, but strive to be worthy of recognition.",
"The power of imagination makes us infinite.",
"The glow of one warm thought is to me worth more than money."
]
for i in test_list:
test(model, i)
预测结果为
模型准确率为: 0.9943333333333333 Most Informative Features sad = True Negati : Positi = 35.1 : 1.0 follower = True Positi : Negati = 20.6 : 1.0 bam = True Positi : Negati = 20.1 : 1.0 arrive = True Positi : Negati = 18.6 : 1.0 x15 = True Negati : Positi = 17.3 : 1.0 blog = True Positi : Negati = 16.7 : 1.0 followed = True Negati : Positi = 15.5 : 1.0 damn = True Negati : Positi = 15.4 : 1.0 top = True Positi : Negati = 15.3 : 1.0 appreciate = True Positi : Negati = 13.9 : 1.0 None 内容: I was sad on the day you went away,I'm not the man your heart is missing,that's why you go away I know. 预测结果: Negative 内容: My heart is being cut by the knife that is called MISSING YOU. NOthing in the world can destroy me except losing you. My memory of you devours every cell of my blood 预测结果: Negative 内容: I will always be there for you. 预测结果: Negative 内容: I fuck you fuck your mother fuck your father fuck your family 预测结果: Negative 内容: Don't worry when you are not recognized, but strive to be worthy of recognition. 预测结果: Positive 内容: The power of imagination makes us infinite. 预测结果: Negative 内容: The glow of one warm thought is to me worth more than money. 预测结果: Positive
由于训练集数据量有限, 所以预测结果也不一定完全准确
十、在此献上全部代码
import random import re import string from nltk.corpus import twitter_samples from nltk.tag import pos_tag, pos_tag_sents from nltk.stem.wordnet import WordNetLemmatizer from nltk.corpus import stopwords from nltk import FreqDist def fenci(file): return twitter_samples.tokenized(file) def cleaned_list_func(evert_tweet): new_text = [] cixing_list = pos_tag(evert_tweet) for word, cixing in cixing_list: word = re.sub('http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+#]|[!*(),]|(?:[0-9a-fA-F][0-9a-fA-F]))+', '', word) word = re.sub('(@[A-Za-z0-9_]+)', '', word) if cixing.startswith('NN'): pos = 'n' elif cixing.startswith('VB'): pos = 'v' else: pos = 'a' lemmatizer = WordNetLemmatizer() new_word = lemmatizer.lemmatize(word, pos) if len(new_word) > 0 and new_word not in string.punctuation and new_word.lower() not in stopwords.words('english'): new_text.append(new_word.lower()) return new_text def get_all_words(clean_tokens_list): for tokens in clean_tokens_list: for token in tokens: yield token def get_tweets_for_model(clean_tokens_list, tag): li = [] for every_tweet in clean_tokens_list: data_dict = dict([token, True] for token in every_tweet) li.append((data_dict, tag)) return li def train_model(train_data, test_data): from nltk import classify from nltk import NaiveBayesClassifier model = NaiveBayesClassifier.train(train_data)return model def test(model, test_text): from nltk.tokenize import word_tokenize custom_tokens = cleaned_list_func(word_tokenize(test_text)) result = dict([token, True] for token in custom_tokens) if __name__ == '__main__': po_file_path = 'positive_tweets.json' ne_file_path = 'negative_tweets.json' positive_tweets = twitter_samples.strings(po_file_path) negative_tweets = twitter_samples.strings(ne_file_path) po_fenci_res = fenci(po_file_path) be_fenci_res = fenci(ne_file_path) positive_cleaned_list = [] negative_cleaned_list = [] for i in po_fenci_res: positive_cleaned = cleaned_list_func(i) positive_cleaned_list.append(positive_cleaned) for j in be_fenci_res: negative_cleaned = cleaned_list_func(j) negative_cleaned_list.append(negative_cleaned) po_for_model = get_tweets_for_model(positive_cleaned_list, 'Positive') ne_for_model = get_tweets_for_model(negative_cleaned_list, 'Negative') model_data = po_for_model + ne_for_model random.shuffle(model_data) train_data = model_data[:7000] test_data = model_data[7000:] model = train_model(train_data, test_data) test_list = [ "I was sad on the day you went away,I'm not the man your heart is missing,that's why you go away I know.", "My heart is being cut by the knife that is called MISSING YOU. NOthing in the world can destroy me except losing you. My memory of you devours every cell of my blood", "I will always be there for you.", 'I fuck you fuck your mother fuck your father fuck your family', "Don't worry when you are not recognized, but strive to be worthy of recognition.", "The power of imagination makes us infinite.", "The glow of one warm thought is to me worth more than money." ] for i in test_list: test(model, i)
以上内容为简单分析, 初学,有任何问题欢迎留言讨论~~