资料来源:
原理:https://blog.51cto.com/wn2100/2238996
原理:https://www.cnblogs.com/ilifeilong/p/7002687.html
主备库配置:https://blog.csdn.net/silenceray/article/details/54692908
postgres主备切换之文件触发方式:https://blog.csdn.net/m15217321304/article/details/88850146
参考:流复制延迟参数https://cloud.tencent.com/developer/article/1524114
一、PostgreSQL通过WAL日志构建高可靠性原理:
PostgrepSQL在数据目录的子目录pg_xlog子目录中维护了一个WAL日志文件,可以把WAL日志备份到另外一台备份服务器,通过重做WAL日志的方式在备服务器上恢复数据(类似Oracle的redo日志)。
WAL日志复制到另外一台备份服务器可以有两种方式:
1、 WAL日志文件复制
此种方式是写完一个WAL日志后,才把WAL日志文件拷贝到备份数据库中。这样通常备份会落后主库一个WAL日志文件,当主数据库发生故障时,主数据库的WAL文件并没有填充完毕未传输(默认16MB)、或者时延等原因导致WAL文件没有传输完毕,会导致被数据库可能存在一定的数据丢失。此种方式是postgreSQL9.0前版本主要提供的WAL日志复制机制。
采用此方式的WAL复制,需要:
- 主数据库的wal_level配置为archive或以上。
- PostgreSQL 9.1之后提供了一个很方便的工具pg_basebackup,使用完成一次基础备份到备数据库。
- 后续产生WAL文件,可以通过archive_command参数调度命令传输至备机。
2、流复制(Streaming Replication)
流复制是PostgreSQL 9.0之后才提供的新的传递WAL日志的方法。通过流复制,备库不断的从主库同步相应的数据,并在备库apply每个WAL record,这里的流复制每次传输单位是WAL日志的record。它的好处是只要主库一产生日志,就会马上传递到备库,同WAL日志文件相比有更低同步延迟。
同时PostgreSQL9.0之后提供了Hot Standby能力,备库在应用WAL record的同时也能够提供只读服务。
PostgreSQL的流复制最多支持1主8备、支持级联复制(主->备1,备1->备2)。
PostgreSQL流复制的核心部分由walsender,walreceiver和startup三个进程组成:
- walreceiver启动后通过recovery.conf文件中的primary_conninfo参数信息连向主库,主库通过连接参数replication=true启动walsender进程。
- walreceiver执行identify_system命令,获取主库systemid/timeline/xlogpos等信息,执行TIMELINE_HISTORY命令拉取history文件。
- 执行wal_startstreaming开始启动流复制,通过walrcv_receive获取WAL日志,期间也会回应主库发过来的心跳信息(接收位点、flush位点、apply位点),向主库发送feedback信息(最老的事务id),避免vacuum删掉备库正在使用的记录。
- 执行walrcv_endstreaming结束流复制,等待startup进程更新receiveStart和receiveStartTLI,一旦更新,重新进入2/3/4步骤。
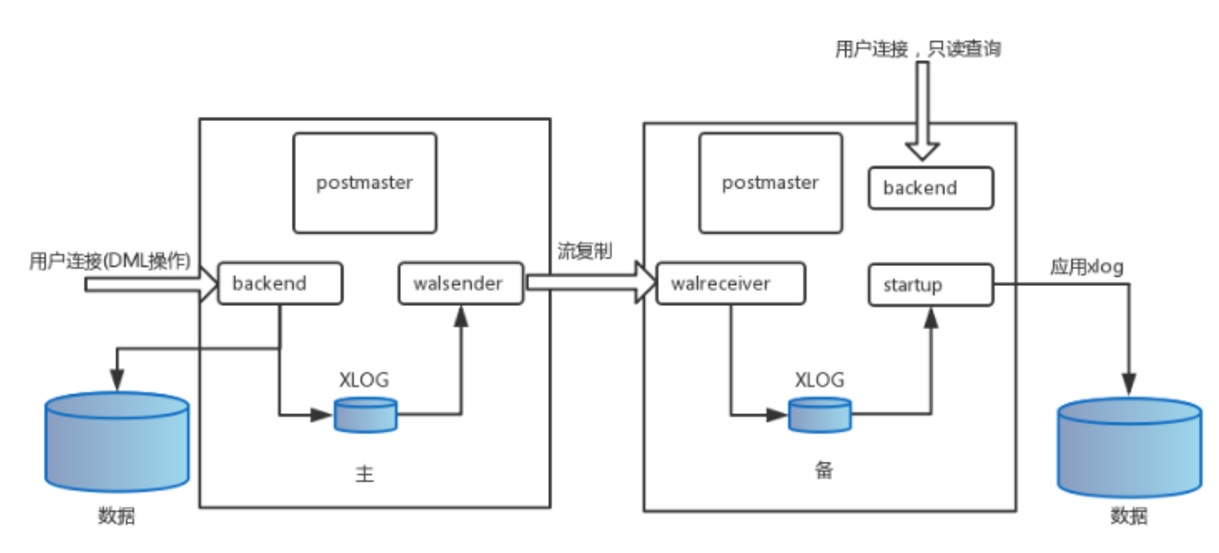
WAL流复制支持同步、异步方式:
- 异步流复制模式中,主库提交的事务不会等待备库接收WAL日志流并返回确认信息,因此异步流复制模式下主库与备库的数据版本上会存在一定的处理延迟,延迟的时间主要受主库压力、备库主机性能、网络带宽等影响,当正常情况下,主备的延迟通常在毫秒级的范围内,当主库宕机,这个延迟就主要受到故障发现与切换时间的影响而拉长,不过虽然如此,这些数据延迟的问题,可以从架构或相关自动化运维手段不断优化设置。
- 同步流复制模式中,要求主库把WAL日志写入磁盘,同时等待WAL日志记录复制到备库、并且WAL日志记录在任何一个备库写入磁盘后,才能向应用返回Commit结果。一旦所有备库故障,在主库的应用操作则会被挂起,所以此方式建议起码是1主2备。
二、搭建PostgreSQL数据库异步流复制环境
前提,数据库安装完毕。以主、备库如下规划为例:
|
主库地址/端口 |
10.10.10.1 / 5432 |
|
备库地址/端口 |
10.10.10.2 / 5432 |
|
备主流复制用户名/密码 |
u_standby / standby123 |
|
数据库用户名 |
postgre |
PostgreSQL主备数据库的同步设置主要涉及如下文件:
- pg_hba.conf postgresql 主库访问规则文件
- postgresql.conf postgresql 主库配置文件
- recovery.conf postgresql 备库访问主库配置文件
- .pgpass postgresql 备库访问主库的密码文件
正常主备流复制情况下:
- 主库需要pg_hba.conf、postgresql.conf
- 备库需要recovery.conf、.pgpass
实际操作中,建议主、备库上都配置这四个文件,因为主、备库角色是随着倒换变更的。注:recovery.conf文件在备库上是recovery.conf,在主库上配置为recovery.done。
主库配置:
1、 配置postgresql.conf
wal_level = hot_standby # minimal, replica, or logical 使得日志支持Streaming Replication
max_wal_senders = 2 # max number of walsender processes 这个设置了可以最多有几个流复制连接,几个并发的standby数据库就设置几个
wal_keep_segments = 256 设置流复制保留的最多的xlog数目,不要设置太小导致WAL日志还没有来得及传送到standby就被覆盖。一个WAL文件默认16M
hot_standby = on # "on" allows queries during recovery 设置为备库时是否支持可读
logging_collector = on
log_directory = 'pg_log'
log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log'
2、 配置pg_hba.conf
# TYPE DATABASE USER ADDRESS METHOD
host all all 127.0.0.1/32 trust
host all all ::1/128 trust
host replication u_standby 10.10.10.0/32 trust
其中:
1) u_standby为在主库上创建的用于备库连接主库进行流复制的用户,此用户需要用户需要有REPLICATION权限和LOGIN权限。开户如:
create user u_standby SUPERUSER LOGIN password 'standby123';
2) 10.10.10.0/32为备库地址段+掩码;也可配置为具体的standby数据库地址+掩码,可配置多条。用于指定哪些地址的standby数据用哪个用户名/密码到主库获取WAL日志数据。使用地址段格式,则地址段内的IP都可以无密码对此数据库进行访问,安全性可能会降低。因此,在生产环境中建议严格按照具体主机IP方式配置。
3、 (可选)配置recovery.done、.pgpass
同备库recovery.conf、.pgpass配置。recovery.conf中如下IP、端口、用户名要对应备库信息:
primary_conninfo = 'host=10.10.10.1 port=5432 user=u_standby' 备库连接主库地址、端口、用户名、密码
4、 配置完毕需重启数据库
pg_ctl restart -m fast
进行主库->备库基础备份:
1、 关闭备库,并清空数据
$pg_ctl stop -m fast
rm -rf /var/lib/pgsql/data/*
2、 进行一次主库数据基本备份到备库
方式一(在主库操作):
//开启备份功能,pg_start_backup() 函数会在主库上发起一个在线备份,命令执行后,将数据文件压缩拷贝到备份节点上:
$postgres=# select pg_start_backup('backup0001')
//将data目录下的数据远程拷贝到备库的data目录下
$scp -r /opt/pgsql/data/* 10.10.10.2:/opt/pgsql/data/
//关闭备份功能
$postgres=# select pg_stop_backup()
方式二(9.0版本后引入了pg_basebackup工具,在备库操作):
pg_basebackup工具支持对主库发起一个基准备份,发起备份需要超级用户权限或REPLICATION权限,注意max_wal_senders参数配置,因为pg_basebackup工具将消耗至少一个WAL发送进程。
//如下IP为主库地址
pg_basebackup -h 10.10.10.1 -U u_standby -F p -x -P -R -D /var/lib/pgsql/9.5/data/ -1 rep_backup //-R 表示会在备份结束后自动生成recovery.conf文件,这样就避免了手动创建。
备库配置:
1、 修改postgresql.conf
hot_standby = on # "on" allows queries during recovery 设置为备库时是否支持可读
2、 配置recovery.conf
standby_mode = on
recovery_target_timeline = 'latest'
primary_conninfo = 'host=10.10.10.1 port=5432 user= u_standby password=standby123 ' 本库为备库会,连接主库地址、端口、用户名、密码
3、 设置连接主库密码.pgpass
10.10.10.1: 5432:replication: u_standby:standby123 //备库都主库同步WAL日志使用
10.10.10.2: 5432:replication: u_standby:standby123 //倒换后,主库降备库,新备库使用
4、 配置完毕需重启数据库
pg_ctl start
结果检查:
1、 配置成功后,可以查看主、备库的walsender、walreceiver进程。
ps -ef | grep wal
主库:
postgres 6939 6935 0 23:16 ? 00:00:00 postgres: wal writer process
postgres 6983 6935 0 23:42 ? 00:00:00 postgres: wal sender process repuser 172.17.0.5(45910) streaming 0/3000140
备库:
postgres 26481 26479 0 23:42 ? 00:00:00 postgres: wal receiver process streaming 0/3000140
三、PostgreSQL的同步流复制
同步流复制配置内容类似异步流复制,差异点在于:
1、 主库的postgresql.conf文件,增加:
synchronous_standby_names = 'standby001'
synchronous_standby_names是设置同步流复制的备库的主机名,该名称会在备库中的参数中指定。
2、 备库的recoveryt.conf文件
primary_conninfo = 'host=192.168.100.32 port=5866 user=tbing application_name=standby001'
application_name参数就是设置的同步流复制备库的主机名,该参数值和主库的synchronous_standby_names的参数值一致。
3、 检查流复制状态
执行:
select * from pg_stat_replication
返回:
sync_state | sync 表示同步流复制
sync_state | async 表示异步流复制
四、PostgreSQL主备数据库切换
1、识别当前库主、备角色:
方式一:
postgres=# select pg_is_in_recovery(); 结果是f则为主库,t为备库。
方式二:
pg_controldata 结果为cluster state是in production则为主库;结果为cluster state是in archive recovery则为备库。
方式三:
Select pid, application_name, client_addr, client_port, state, sync_state from pg_stat_replication 查询到结果为主库,查询不到结果为备库。
2、主备倒换
在PostgreSQL如主库出现异常时,备库如何激活。有2种方式:
方式一:使用pg_ctl promote来激活(PostgreSQL9.1后支持)
(1)关闭主库(模拟主库故障):
$ pg_ctl stop -m fast
(2)在备库上执行pg_ctl promote命令激活备库
如果recovery.conf变成recovery.done表示备库已切换成主库
(3)原主库变备库
在新备库上创建recovery.conf、.pgpass文件,内容参考前文章节。启动新备库:
$ pg_ctl start
方式二:备库在recovery.conf文件中有个配置项trigger_file,是激活standby的触发文件,通过检测这个文件是否存在,存在则激活standby为master。
(1)在recovery.conf中配置触发器文件地址,修改本参数后需要重启备库:
recovery_target_timeline = 'latest'
standby_mode = on
primary_conninfo = 'host=10.10.10.1 port=5432 user= u_standby password=standby123 '
trigger_file = '/home/postgres/pg11/trigger'
(2)停掉原主库,会发现原备库变为可读写。
$ pg_ctl stop -m fast
(3)在备库创建trigger_file
$ touch /home/postgres/pg11/trigger
(4)发现原备库变为主库,方法参考“识别当前库主、备角色”。
3、故障的原主库,重新作为备库使用
在异步流复制(async)模式下,主库故障切换后,可能存在原主库故障时还有数据没来及的复制到备库,这些数据将丢失。(注:PostgreSQL的Streaming Replication是以事务为单位,即使数据未同步完毕,也不会出现备库某个事务只恢复一半的情况,因此事务一致性还是可以保证的。)
此种情况下,原主库的最后一个事务时间戳比复制到原备库(新主库)的事务时间戳更新。比如:倒换前最后几个事务是100/101/102,故障前流复制到100事务,则故障切换后,原主库中最新一个事务是102,原备库(新主库)中复制的最后一个事务是100,后续新主库(原备库)将在100的基础上,进行新的事务操作。原主库数据、新主库数据出现分叉点。因此,如果希望原主库恢复服务后作为新备库运行,则需要:
方式一:删库,重搭新备库(详细参考前文备库配置过程)
1、 关闭库,并清空数据(清楚数据即可,不需要重装数据库)
pg_ctl stop -m fast
rm -rf /var/lib/pgsql/data/*
2、 新备库进行数据基本备份
pg_basebackup ….
3、 启动新备库
pg_ctl start
方式二:采用pg_rewind降级为备库,继续服务
如果你的数据库到达TB级别,采用方式一的全量数据基础备份将花费数个小时。为了解决此问题,PostgreSQL9.5引入了pg_rewind功能。原主库(新备库)可以通过pg_rewind操作实现故障时间线的回退。回退后再从新主库中获取最新的后续数据。此时,原主库的数据无须进行重新全量初始化就可以继续进行Streaming Replication,并作为新的Slave使用。
详见pg_rewind使用说明。