转 http://www.sohu.com/a/136487507_505779
导读:Google 的 Protocol Buffers 在数据编码的效率上似乎被神化了,一直流传性能是 JSON 等本文格式 5 倍以上,本文通过代码测试来比较 JSON 与 PB 具体的性能差别到底是多少。作者陶文,转载请注明来自高可用架构「ArchNotes」
陶文,技术极简主义者。认为好的技术是应该是对开发者友好的。一直致力于用技术改进研发效率和开发者体验。jsoniter [4] 作者,jsoniter 就来自于要不要用 Thrift 替代 JSON 的思考。我认为通过引入 IDL 和高效率的编解码库,可以让 HTTP + JSON 这样对开发者体验有好处的技术长久地生存下去。

拿 JSON 衬托 Protobuf 的文章真的太多了,经常可以看到文章中写道:“快来用 Protobuf 吧,JSON 太慢啦”。但是 Protobuf 真的有那么牛么?我想从 JSON 切换到 Protobuf 怎么也得快一倍吧,要不然对不起付出的切换成本?
然而,DSL-JSON 居然声称在 Java 语言里, JSON 可以和那些二进制的编解码格式性能不相上下 [1]!
这太让人惊讶了!虽然你可能会说,咱们能不用苹果和梨来做比较了么,两个东西根本用途完全不一样,用 Protobuf 是冲着跨语言无歧义的 IDL 的去的,才不仅仅是因为性能!这个我同意,但是仍然有那么多人盲目相信 Protobuf 一定会快很多,因此我觉得还是有必要通过本文彻底终结一下这个关于速度的传说。
DSL-JSON 的博客里只给了他们的测试结论,但是没有给出任何原因,以及优化的细节。这很难让人信服数据是真实的。你要说 JSON 比二进制格式更快,真的是很反直觉的事情。稍微琢磨一下这个问题,就可以列出好几个 Protobuf 应该更快的理由:
-
更容容易绑定值到对象的字段上。JSON 的字段是用字符串指定的,相比之下字符串比对应该比基于数字的字段 tag 更耗时。
-
JSON 是文本的格式,整数和浮点数应该更占空间而且更费时。
-
Protobuf 在正文前有一个大小或者长度的标记,而 JSON 必须全文扫描无法跳过不需要的字段。
但是仅凭这几点是不是就可以盖棺定论了呢?未必,也有相反的观点:
-
如果字段大部分是字符串,占到决定性因素的因素可能是字符串拷贝的速度,而不是解析的速度。在这个评测 [2] 中,我们看到不少库的性能是非常接近的。这是因为测试数据中大部分是由字符串构成的。
-
影响解析速度的决定性因素是分支的数量。因为分支的存在,解析仍然是一个本质上串行的过程。虽然 Protobuf 里没有 [] 或者 {},但是仍然有类似的分支代码的存在。如果没有这些分支的存在,解析不过就是一个 memcpy 的操作而已。只有 Parabix 这样的技术才有革命性的意义,而 Protobuf 相比 JSON 只是改良而非革命。
-
也许 Protobuf 是一个理论上更快的格式,但是实现它的库并不一定就更快。这取决于优化做得好不好,如果有不必要的内存分配或者重复读取,实际的速度未必就快。
有多个 benchmark 都把 DSL-JSON 列到前三名里,有时甚至比其他的二进制编码更快。经过我仔细分析,原因出在了这些 benchmark 对于测试数据的构成选择上。因为构造测试数据很麻烦,所以一般评测只会对相同的测试数据,去测不同的库的实现。这样就使得结果是严重倾向于某种类型输入的。比如 [3]选择的测试数据的结构是这样的

点击图片可以放大浏览
无论怎么去构造 small/medium/large 的输入,benchmark 仍然是存在特定倾向性的。而且这种倾向性是不明确的。比如 medium 的输入,到底说明了什么?medium 对于不同的人来说,可能意味着完全不同的东西。所以,在这里我想改变一下游戏的规则。不去选择一个所谓的最现实的配比,而是构造一些极端的情况。这样,我们可以一目了然的知道,JSON 的强项和弱点都是什么。通过把这些缺陷放大出来,我们也就可以对最坏的情况有一个清晰的预期。具体在你的场景下性能差距是怎样的一个区间内,也可以大概预估出来。
好了,废话不多说了。JMH 撸起来。benchmark 的对象有以下几个:
-
Jackson:Java 程序里用的最多的 JSON 解析器。benchmark 中开启了 AfterBurner 的加速特性。
-
DSL-JSON:世界上最快的 Java JSON 实现
-
Jsoniter: 我抄袭 DSL-JSON 写的实现。特别申明:我是 Jsoniter 的作者。这里提到的所有关于Jsoniter 的评测数据都不应该被盲目相信。大部分的性能优化技巧是从 DSL-JSON 中直接抄来的。
-
Fastjson:在中国很流行的 JSON 解析器
-
Protobuf:在 RPC (远程方法调用)里非常流行的二进制编解码格式
-
Thrift:另外一个很流行的 RPC 编解码格式。这里 benchmark 的是 TCompactProtocol
Decode Integer
先从一个简单的场景入手。毫无疑问,Protobuf 非常擅长于处理整数

| 库 | 相比 Jackson | ns/op |
| Protobuf | 8.20 | 22124.431 |
| Thrift | 6.6 | 27232.761 |
| Jsoniter | 6.45 | 28131.009 |
| DSL-JSON | 4.48 | 40472.032 |
| Fastjson | 2.1 | 86555.965 |
| Jackson | 1 | 181357.349 |
从结果上看,似乎优势非常明显。但是因为只有 1 个整数字段,所以可能整数解析的成本没有占到大头。所以,我们把测试调整对象调整为 10 个整数字段。再比比看

点击图片可以放大浏览
| 库 | 相比 Jackson | ns/op |
| Protobuf | 8.51 | 71067.990 |
| Thrift | 2.98 | 202921.616 |
| Jsoniter | 3.22 | 187654.012 |
| DSL-JSON | 1.43 | 422839.151 |
| Fastjson | 1.4 | 432494.654 |
| Jackson | 1 | 604894.752 |
这下优势就非常明显了。毫无疑问,Protobuf 解析整数的速度是非常快的,能够达到 Jackson 的 8 倍。
DSL-JSON 比 Jackson 快很多,它的优化代码在这里

点击图片可以放大浏览
整数是直接从输入的字节里计算出来的,公式是 value = (value << 3) + (value << 1) + ind; 相比读出字符串,然后调用 Integer.valueOf ,这个实现只遍历了一遍输入,同时也避免了内存分配。
在这个基础上做了循环展开
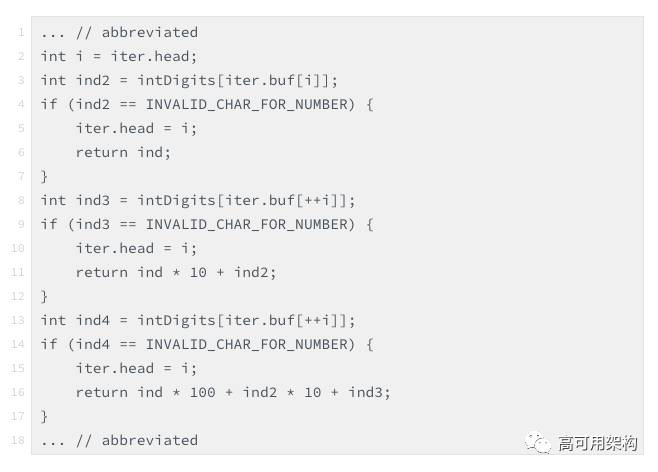
点击图片可以放大浏览
Encode Integer
编码方面情况如何呢?和编码一样的测试数据,测试结果如下:
| 库 | 相比 Jackson | ns/op |
| Protobuf | 2.9 | 121027.285 |
| Thrift | 0.17 | 2128221.323 |
| Jsoniter | 2.02 | 173912.732 |
| DSL-JSON | 2.18 | 161038.645 |
| Fastjson | 0.81 | 431348.853 |
| Jackson | 1 | 351430.048 |
不知道为啥,Thrift 的序列化特别慢。而且别的 benchmark 里 Thrift 的序列化都是算慢的。我猜测应该是实现里有不够优化的地方吧,格式应该没问题。整数编码方面,Protobuf 是 Jackson 的 3 倍。但是和 DSL-JSON 比起来,好像没有快很多。
这是因为 DSL-JSON 使用了自己的优化方式,和 JDK 的官方实现不一样

点击图片可以放大浏览
这段代码的意思是比较令人费解的。不知道哪里就做了数字到字符串的转换了。过程是这样的,假设输入了19823,会被分解为 19 和 823 两部分。然后有一个 `DIGITS` 的查找表,根据这个表把 19 翻译为 "19",把 823 翻译为 "823"。其中 "823" 并不是三个byte分开来存的,而是把 bit 放到了一个integer里,然后在 writeBuf 的时候通过位移把对应的三个byte解开的

点击图片可以放大浏览
这个实现比 JDK 自带的 Integer.toString 更快。因为查找表预先计算好了,节省了运行时的计算成本。
Decode Double
解析 JSON 的 Double 就更慢了。

| 库 | 相比 Jackson | ns/op |
| Protobuf | 13.75 | 92447.958 |
| Thrift | 7.30 | 174052.307 |
| Jsoniter | 4.2 | 302453.323 |
| Jsoniter () | 3.25 | 390812.895 |
| DSL-JSON | 2.53 | 502287.602 |
| Fastjson | 1.2 | 1055454.855 |
| Jackson | 1 | 1271311.735 |
Protobuf 解析 double 是 Jackson 的 13 倍。毫无疑问,JSON 真的不适合存浮点数。
DSL-Json 中对 Double 也是做了特别优化的

点击图片可以放大浏览
浮点数被去掉了点,存成了 long 类型,然后再除以对应的 10 的倍数。如果输入是 3.1415,则会变成 31415/10000。
Encode Double
把 double 编码为文本格式就更困难了。
| 库 | 相比 Jackson | ns/op |
| Protobuf | 12.71 | 143346.157 |
| Thrift | 0.87 | 2093533.015 |
| Jsoniter (6 digits) | 6.5 | 280252.226 |
| Jsoniter () | 6.68 | 272843.205 |
| DSL-JSON | 1.23 | 1483965.621 |
| Fastjson | 1.06 | 1722392.219 |
| Jackson | 1 | 1822478.053 |
解码 double 的时候,Protobuf 是 Jackson 的 13 倍。如果你愿意牺牲精度的话,可以选择只保留 6 位小数。在这个取舍下,可以好一些,但是 Protobuf 仍然是 的两倍。
保留 6 位小数的代码是这样写的。把 double 的处理变成了长整数的处理。

点击图片可以放大浏览
到目前来看,我们可以说 JSON 不是为数字设计的。如果你使用的是 Jackson,切换到 Protobuf 的话可以把数字的处理速度提高 10 倍。然而 DSL-Json 做的优化可以把这个性能差距大幅缩小,解码在 3x ~ 4x 之间,编码在 1.3x ~ 2x 之间(前提是牺牲 double 的编码精度)。
因为 JSON 处理 double 非常慢。所以 提供了一种把 double 的 IEEE 754 的二进制表示(64个bit)用 编码之后保存的方案。如果希望提高速度,但是又要保持精度,可以使用 FloatSupport.enableEncodersAndDecoders();

点击图片可以放大浏览
对于 0.123456789 就变成了 "OWNfmt03P78"
Decode Object
我们已经看到了 JSON 在处理数字方面的笨拙丑态了。在处理对象绑定方面,是不是也一样不堪?前面的 benchmark 结果那么差和按字段做绑定是不是有关系?毕竟我们有 10 个字段要处理那。这就来看看在处理字段方面的效率问题。
为了让比较起来公平一些,我们使用很短的 ascii 编码的字符串作为字段的值。这样字符串拷贝的成本大家都差不到哪里去。所以性能上要有差距,必然是和按字段绑定值有关系。

| 库 | 相比 Jackson | ns/op |
| Protobuf | 2.52 | 68666.658 |
| Thrift | 2.74 | 63139.324 |
| Jsoniter | 5.78 | 29887.361 |
| DSL-JSON | 5.32 | 32458.030 |
| Fastjson | 1.71 | 101107.721 |
| Jackson | 1 | 172747.146 |
如果只有一个字段,Protobuf 是 Jackson 的 2.5 倍。但是比 DSL-JSON 要慢。
我们再把同样的实验重复几次,分别对应 5 个字段,10个字段的情况。

| 库 | 相比 Jackson | ns/op |
| Protobuf | 1.3 | 276972.857 |
| Thrift | 1.44 | 250016.572 |
| Jsoniter | 2.5 | 143807.401 |
| DSL-JSON | 2.41 | 149261.728 |
| Fastjson | 1.39 | 259296.397 |
| Jackson | 1 | 359868.351 |
在有 5 个字段的情况下,Protobuf 仅仅是 Jackson 的 1.3x 倍。如果你认为 JSON 对象绑定很慢,而且会决定 JSON 解析的整体性能。对不起,你错了。

| 库 | 相比 Jackson | ns/op |
| Protobuf | 1.22 | 462167.920 |
| Thrift | 1.12 | 503725.605 |
| Jsoniter | 2.04 | 277531.128 |
| DSL-JSON | 1.84 | 307569.103 |
| Fastjson | 1.18 | 477492.445 |
| Jackson | 1 | 564942.726 |
把字段数量加到了 10 个之后,Protobuf 仅仅是 Jackson 的 1.22 倍了。看到这里,你应该懂了吧。
Protobuf 在处理字段绑定的时候,用的是 switch case:

点击图片可以放大浏览
这个实现比 Hashmap 来说,仅仅是稍微略快而已。DSL-JSON 的实现是先 hash,然后也是类似的分发的方式:

点击图片可以放大浏览
使用的 hash 算法是 FNV-1a。

是 hash 就会碰撞,所以用起来需要小心。如果输入很有可能包含未知的字段,则需要放弃速度选择匹配之后再查一下字段是不是严格相等的。有一个解码模式
DYNAMIC_MODE_AND_MATCH_FIELD_STRICTLY,它可以产生下面这样的严格匹配的代码:

点击图片可以放大浏览
即便是严格匹配,速度上也是有保证的。DSL-JSON 也有选项,可以在 hash 匹配之后额外加一次字符串 equals 检查。
| 库 | 相比 Jackson | ns/op |
| Jsoniter (hash mode) | 2.13 | 274949.346 |
| Jsoniter (strict mode) | 1.95 | 300524.989 |
| DSL-JSON (hash mode) | 1.91 | 305812.208 |
| DSL-JSON (strict mode) | 1.71 | 343203.344 |
| Jackson | 1 | 585421.314 |
关于对象绑定来说,只要字段名不长,基于数字的 tag 分发并不会比 JSON 具有明显优势,即便是相比最慢的 Jackson 来说也是如此。
Encode Object
废话不多说了,直接比较一下三种字段数量情况下,编码的速度
只有 1 个字段
| 库 | 相比 Jackson | ns/op |
| Protobuf | 1.22 | 57502.775 |
| Thrift | 0.86 | 137094.627 |
| Jsoniter | 2.06 | 57081.756 |
| DSL-JSON | 2.46 | 47890.664 |
| Fastjson | 0.92 | 127421.715 |
| Jackson | 1 | 117604.479 |
有 5 个字段
| 库 | 相比 Jackson | ns/op |
| Protobuf | 1.68 | 127933.179 |
| Thrift | 0.46 | 467818.566 |
| Jsoniter | 2.54 | 84702.001 |
| DSL-JSON | 2.68 | 80211.517 |
| Fastjson | 0.98 | 219373.346 |
| Jackson | 1 | 214802.686 |
有 10 个字段
| 库 | 相比 Jackson | ns/op |
| Protobuf | 1.72 | 194371.476 |
| Thrift | 0.38 | 888230.783 |
| Jsoniter | 2.59 | 129305.086 |
| DSL-JSON | 2.56 | 130379.967 |
| Fastjson | 1.06 | 315267.365 |
| Jackson | 1 | 334297.953 |
对象编码方面,Protobuf 是 Jackson 的 1.7 倍。但是速度其实比 DSL-Json 还要慢。
优化对象编码的方式是,一次性尽可能多的把控制类的字节写出去。

点击图片可以放大浏览
可以看到我们把 "field1": 作为一个整体写出去了。如果我们知道字段是非空的,则可以进一步的把字符串的双引号也一起合并写出去。

点击图片可以放大浏览
从对象的编解码的 benchmark 结果可以看出,Protobuf 在这个方面仅仅比 Jackson 略微强一些,而比 DSL-Json 要慢。
Decode Integer List
Protobuf 对于整数列表有特别的支持,可以打包存储

设置 [packed=true]

| 库 | 相比 Jackson | ns/op |
| Protobuf | 2.92 | 249888.105 |
| Thrift | 3.63 | 201439.691 |
| Jsoniter | 2.97 | 245837.298 |
| DSL-JSON | 1.97 | 370897.998 |
| Fastjson | 0.89 | 820099.921 |
| Jackson | 1 | 730450.607 |
对于整数列表的解码,Protobuf 是 Jackson 的 3 倍。然而比 DSL-Json 的优势并不明显。
在 里,解码的循环被展开了:

点击图片可以放大浏览
对于成员比较少的情况,这样搞可以避免数组的扩容带来的内存拷贝。
Encode Integer List
Protobuf 在编码数组的时候应该有优势,不用写那么多逗号出来嘛。
| 库 | 相比 Jackson | ns/op |
| Protobuf | 1.35 | 159337.360 |
| Thrift | 0.45 | 472555.572 |
| Jsoniter | 1.9 | 112770.811 |
| DSL-JSON | 2.19 | 97998.250 |
| Fastjson | 0.66 | 323194.122 |
| Jackson | 1 | 214409.223 |
Protobuf 在编码整数列表的时候,仅仅是 Jackson 的 1.35 倍。虽然 Protobuf 在处理对象的整数字段的时候优势明显,但是在处理整数的列表时却不是如此。在这个方面,DSL-Json 没有特殊的优化,性能的提高纯粹只是因为单个数字的编码速度提高了。
Decode Object List
列表经常用做对象的容器。测试这种两种容器组合嵌套的场景,也很有代表意义。

| 库 | 相比 Jackson | ns/op |
| Protobuf | 1.26 | 1118704.310 |
| Thrift | 1.3 | 1078278.555 |
| Jsoniter | 2.91 | 483304.365 |
| DSL-JSON | 2.22 | 635179.183 |
| Fastjson | 1.12 | 1260390.104 |
| Jackson | 1 | 1407116.476 |
Protobuf 处理对象列表是 Jackson 的 1.3 倍。但是不及 DSL-JSON。
Encode Object List
| 库 | 相比 Jackson | ns/op |
| Protobuf | 2.22 | 328219.768 |
| Thrift | 0.38 | 1885052.964 |
| Jsoniter | 3.63 | 200420.923 |
| DSL-JSON | 3.87 | 187964.594 |
| Fastjson | 0.85 | 857771.520 |
| Jackson | 1 | 727582.950 |
Protobuf 处理对象列表的编码速度是 Jackson 的 2 倍。但是 DSL-JSON 仍然比 Protobuf 更快。似乎 Protobuf 在处理列表的编码解码方面优势不明显。
Decode Double Array
Java 的数组有点特殊,double[]是比 List<Double>更高效的。使用 double 数组来代表时间点上的值或者坐标是非常常见的做法。然而,Protobuf 的 Java 库没有提供 double[]的支持,repeated 总是使用 List<Double>。我们可以预期 JSON 库在这里有一定的优势。

| 库 | 相比 Jackson | ns/op |
| Protobuf | 5.18 | 207503.316 |
| Thrift | 6.12 | 175678.703 |
| Jsoniter | 4.83 | 222818.772 |
| Jsoniter () | 3.63 | 296262.142 |
| DSL-JSON | 2.8 | 383549.289 |
| Fastjson | 0.58 | 1866460.535 |
| Jackson | 1 | 1075423.265 |
Protobuf 在处理 double 数组方面,Jackson 与之的差距被缩小为 5 倍。Protobuf 与 DSL-JSON 相比,优势已经不明显了。所以如果你有很多的 double 数值需要处理,这些数值必须是在对象的字段上,才会引起性能的巨大差别,对于数组里的 double,优势差距被缩小。
在 里,处理数组的循环也是被展开的。

点击图片可以放大浏览
这避免了数组扩容的开销。
Encode Double Array
再来看看 double 数组的编码
| 库 | 相比 Jackson | ns/op |
| Protobuf | 15.63 | 107760.788 |
| Thrift | 0.54 | 3125678.472 |
| Jsoniter (6 digits) | 6.74 | 249945.866 |
| Jsoniter () | 7.11 | 236991.658 |
| DSL-JSON | 1.14 | 1478332.248 |
| Fastjson | 1.08 | 1562377.465 |
| Jackson | 1 | 1684935.837 |
Protobuf 可以飞快地对 double 数组进行编码,是 Jackson 的 15 倍。在牺牲精度的情况下,Protobuf 只是 的 2.3 倍。所以,再次证明了,JSON 处理 double 非常慢。如果用 编码 double,则可以保持精度,速度和牺牲精度时一样。
Decode String
JSON 字符串包含了转义字符的支持。Protobuf 解码字符串仅仅是一个内存拷贝。理应更快才对。被测试的字符串长度是 160 个字节的 ascii。
| 库 | 相比 Jackson | ns/op |
| Protobuf | 1.85 | 173680.548 |
| Thrift | 2.29 | 140635.170 |
| Jsoniter | 2.4 | 134067.924 |
| DSL-JSON | 2.27 | 141419.108 |
| Fastjson | 1.14 | 281061.212 |
| Jackson | 1 | 321406.155 |
Protobuf 解码长字符串是 Jackson 的 1.85 倍。然而,DSL-Json 比 Protobuf 更快。这就有点奇怪了,JSON 的处理负担更重,为什么会更快呢?
先尝试捷径
DSL-JSON 给 ascii 实现了一个捷径:

点击图片可以放大浏览
这个捷径里规避了处理转义字符和utf8字符串的成本。
JVM 的动态编译做了特殊优化
在 JDK9 之前,java.lang.String 都是基于 `char[]` 的。而输入都是 byte[]并且是 utf-8 编码的。所以这使得,我们不能直接用 memcpy 的方式来处理字符串的解码问题。
但是在 JDK9 里,java.lang.String 已经改成了基于`byte[]`的了。从 JDK9 的源代码里可以看出:

点击图片可以放大浏览
使用这个虽然被废弃,但是还没有被删除的构造函数,我们可以使用 Arrays.copyOfRange 来直接构造 java.lang.String 了。然而,在测试之后,发现这个实现方式并没有比 DSL-JSON 的实现更快。
似乎 JVM 的 Hotspot 动态编译时对这段循环的代码做了模式匹配,识别出了更高效的实现方式。即便是在 JDK9 使用 +UseCompactStrings 的前提下,理论上来说本应该更慢的 byte[] => char[] => byte[] 并没有使得这段代码变慢,DSL-JSON 的实现还是最快的。
如果输入大部分是字符串,这个优化就变得至关重要了。Java 里的解析艺术,还不如说是字节拷贝的艺术。JVM 的 java.lang.String 设计实在是太愚蠢了。在现代一点的语言中,比如 Go,字符串都是基于 utf-8 byte[]的。
Encode String
类似的问题,因为需要把 char[] 转换为 byte[],所以没法直接内存拷贝。
| 库 | 相比 Jackson | ns/op |
| Protobuf | 0.96 | 262077.921 |
| Thrift | 0.99 | 252140.935 |
| Jsoniter | 1.5 | 166381.978 |
| DSL-JSON | 1.38 | 181008.120 |
| Fastjson | 0.74 | 339919.707 |
| Jackson | 1 | 250431.354 |
Protobuf 在编码长字符串时,比 Jackson 略微快一点点。一切都归咎于 char[]。
跳过数据结构
JSON 是一个没有 header 的格式。因为没有 header,JSON 需要扫描每个字节才可以定位到所需的字段上。中间可能要扫过很多不需要处理的字段。

消息用 PbTestWriteObject 来编码,然后用 PbTestReadObject 来解码。field1 和 field2 的内容应该被跳过。
| 库 | 相比 Jackson | ns/op |
| Protobuf | 5.05 | 152194.483 |
| Thrift | 5.43 | 141467.209 |
| Jsoniter | 3.75 | 204704.100 |
| DSL-JSON | 2.51 | 305784.845 |
| Fastjson | 0.4 | 1949277.734 |
| Jackson | 1 | 768840.597 |
Protobuf 在跳过数据结构方面,是 Jackson 的 5 倍。但是如果跳过长的字符串,JSON 的成本是和字符串长度线性相关的,而 Protobuf 则是一个常量操作。
总结
最后,我们把所有的战果汇总到一起。
| 场景 | Protobuf V.S. Jackson | Protobuf V.S. Jsoniter | Jsoniter V.S Jackson |
| Decode Integer | 8.51 | 2.64 | 3.22 |
| Encode Integer | 2.9 | 1.44 | 2.02 |
| Decode Double | 13.75 | 3.27 | 4.2 |
| Encode Double | 12.71 | 1.96 (只保留小数点后6位) | 6.5 |
| Decode Object | 1.22 | 0.6 | 2.04 |
| Encode Object | 1.72 | 0.67 | 2.59 |
| Decode Integer List | 2.92 | 0.98 | 2.97 |
| Encode Integer List | 1.35 | 0.71 | 1.9 |
| Decode Object List | 1.26 | 0.43 | 2.91 |
| Encode Object List | 2.22 | 0.61 | 3.63 |
| Decode Double Array | 5.18 | 1.47 | 4.83 |
| Encode Double Array | 15.63 | 2.32 (只保留小数点后6位) | 6.74 |
| Decode String | 1.85 | 0.77 | 2.4 |
| Encode String | 0.96 | 0.63 | 1.5 |
| Skip Structure | 5.05 | 1.35 | 3.75 |
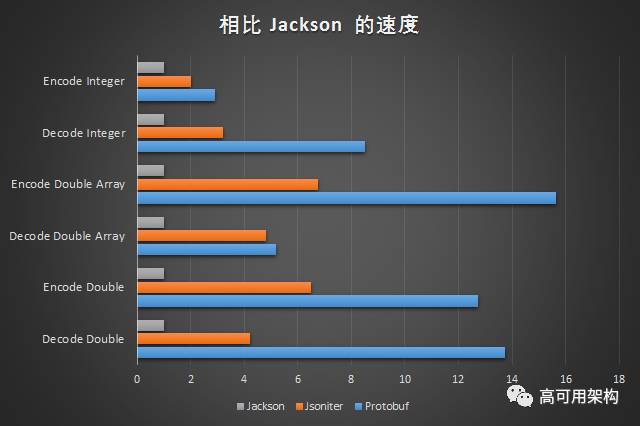
编解码数字的时候,JSON 仍然是非常慢的。把这个差距从 10 倍缩小到了 3 倍多一些。
JSON 最差的情况是下面几种:
-
跳过非常长的字符串:和字符串长度线性相关。
-
解码 double 字段:Protobuf 优势明显,是 的 3.27 倍,是 Jackson 的 13.75 倍。
-
编码 double 字段:如果不能接受只保留 6 位小数,Protobuf 是 Jackson 的 12.71 倍。如果接受精度损失,Protobuf 是 的 1.96 倍。
-
解码整数:Protobuf 是 的 2.64 倍,是 Jackson 的 8.51 倍。
如果你的生产环境中的 JSON 没有那么多的 double 字段,都是字符串占大头,那么基本上来说替换成 Protobuf 也就是仅仅比 提高一点点,肯定在 2 倍之内。如果不幸的话,没准 Protobuf 还要更慢一点。