https://www.bilibili.com/video/BV1sE411P7Qr/?spm_id_from=333.788.recommend_more_video.1





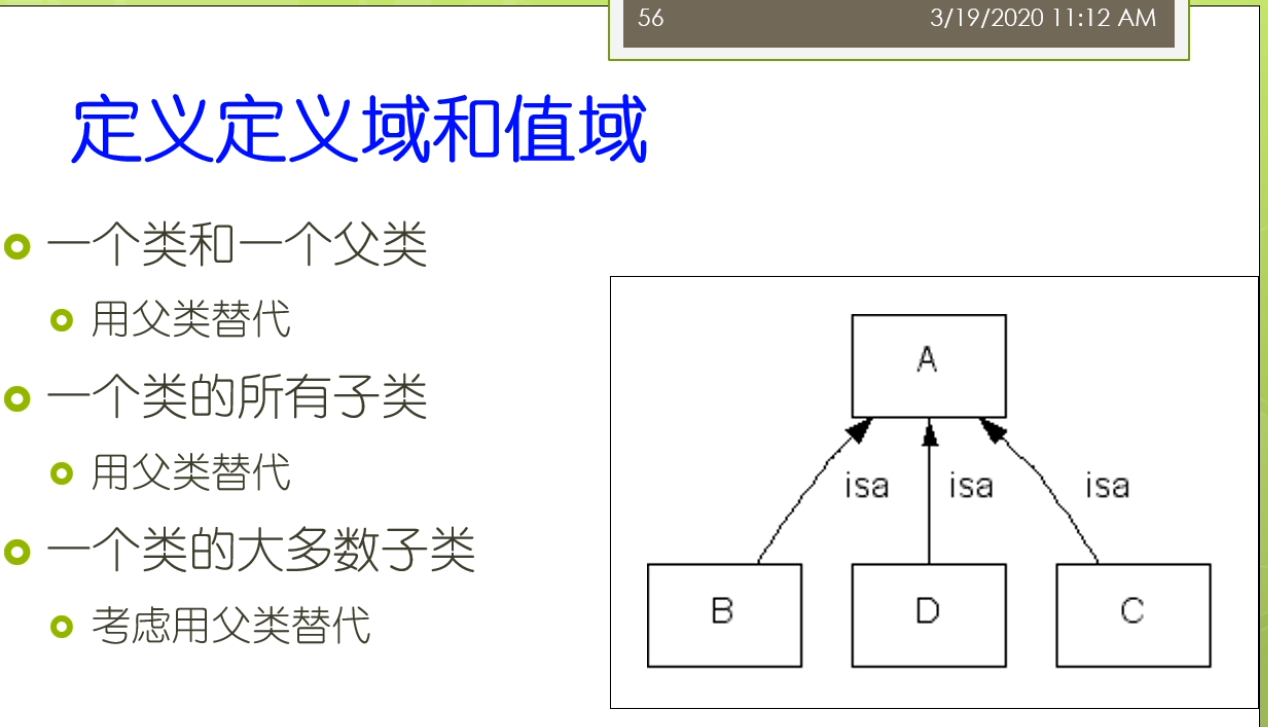
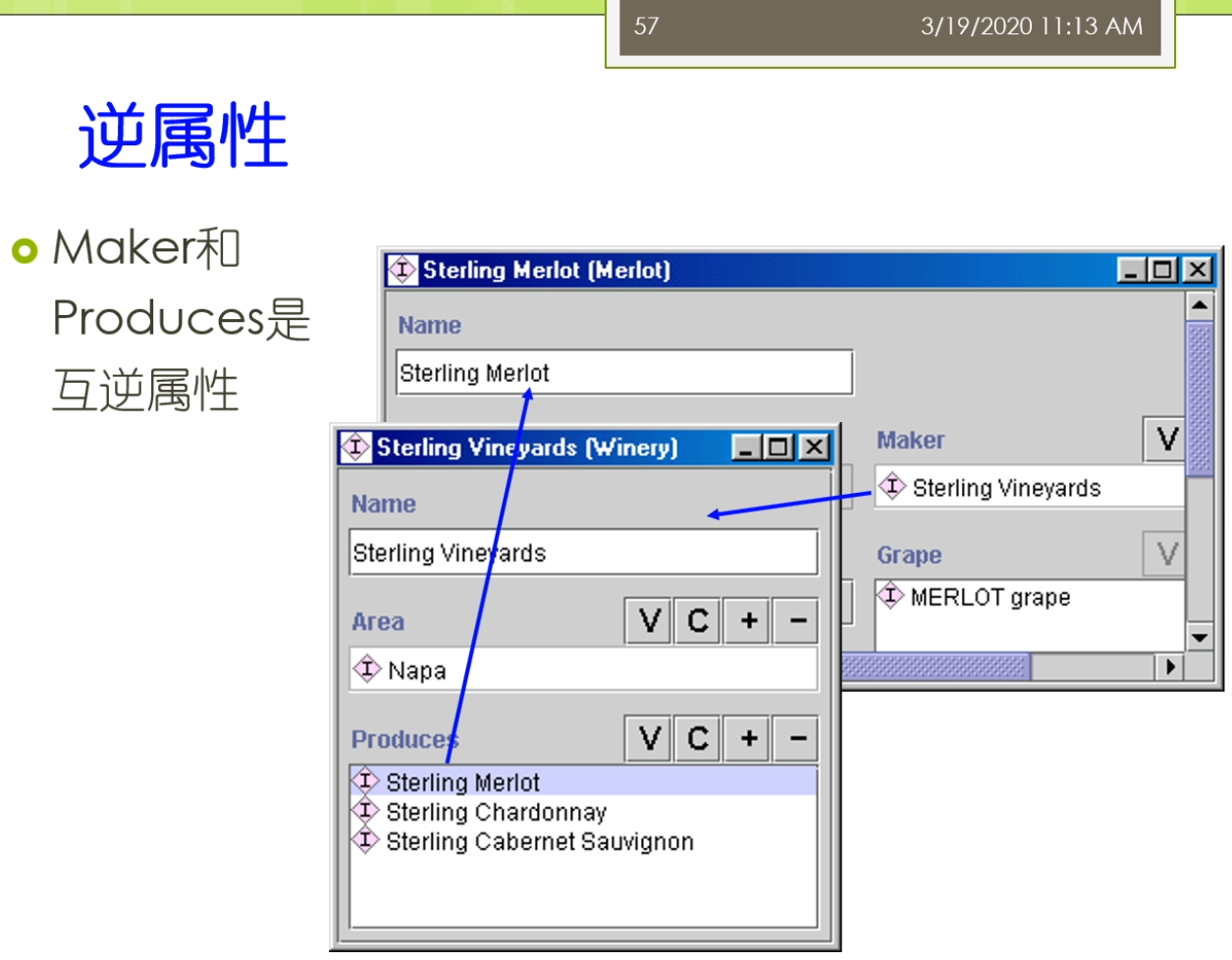
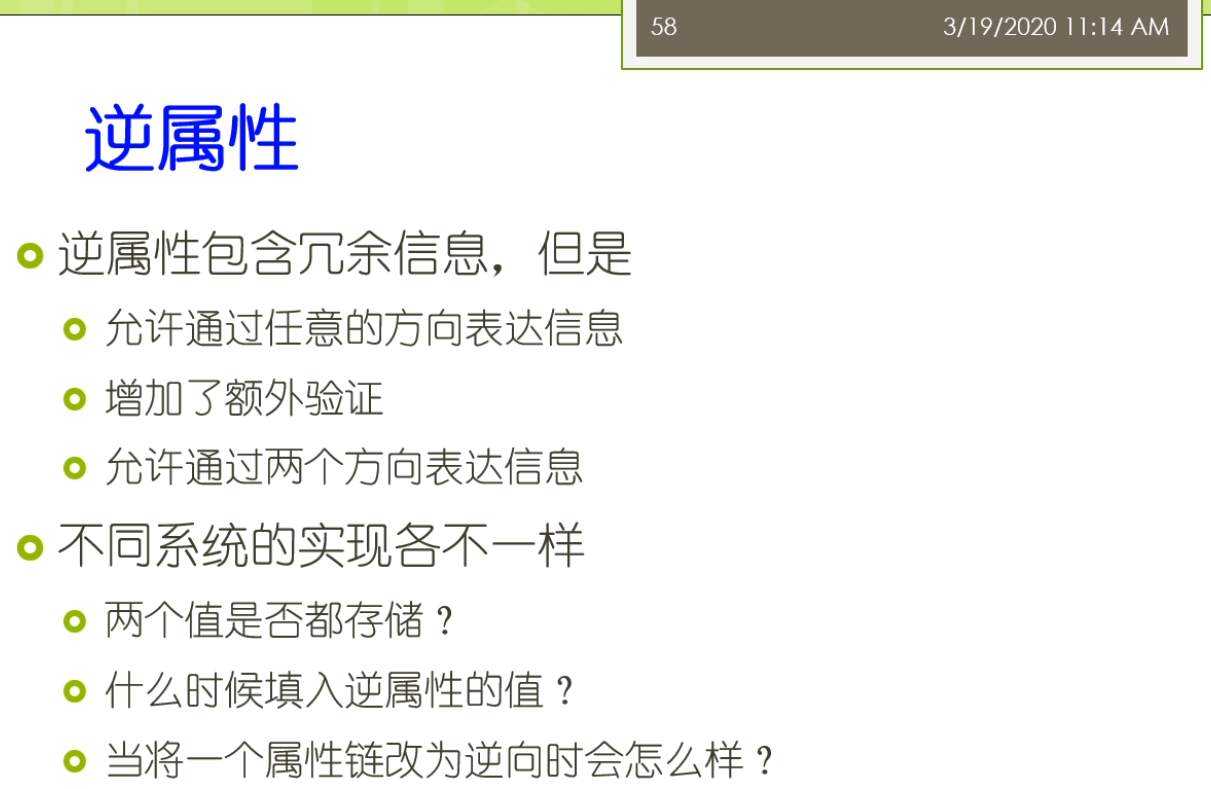

各位同学,我们继续开始上课了啊。那我们刚才讲到了这个成员的一个最佳的一个规模的问题。那么我们还有一些呢这个命名习惯的一些问题,这个人也是对于我们的一些这个非英语国家的这种不是用英语作为母语国家的一些人呢经常会造成一个困惑的地方。这个地方呢,比如说我们举了一个例子,我们班有人定义了这样的一个结构,说wine来是winds的一种。几个子类,十大奶这个来是一个不太好的这样一种电影。或者你把外卖订着第一层这个wine的一个实例,这个人也不是那么特别好。一般来讲来自各类来来讲我们的命名的习惯了都是要不然呢都使用单数或者来,要不然呢都使用复数这样一个表示来实际上来更好一点。而不要把单数的作为复数的一个子类。这个呢不是一个很好的这种命名方法。那么所以呢具体来讲呢,比如说你有一种具体的一种葡萄酒,那么你可能给出了他的名字,然后呢你说他是vine的一个实例vi的一个实例,这样的比较好。那么累了,在实际上累了,代表的是领域中间的一个概念。而不是来代表的概念的这个名字叫什么,这个来体现了我们说雨往他背后的一种哲学。也就是说我描述的是真实世界,而不是仅仅的是一些字符串。所以呢这些类名呢实际上是可以改变,但是呢它仍然指向了相同的这个概念。而且呢需要注意的是相同概念的同意名字来他可能不是不同的类。也就是说比如说我们这儿定义了一个中文的学生,我们又给了一个叫英文的叫student。那么他们实际上只是这个概念的他的不同的名字,那么而不是做他们是不同的概念。那么在许多系统里面,它实际上是允许将这些同义词作为类定义的一个部分的。那么在这里我们可以看到,我们假设我们处理好了上面的这些内容之后呢,我们实际上呢可以这个在这里给出一个葡萄酒的一个完整的一个类层次结构。就像我们这儿的过程里面,我们说这个我们这里主要都使用了一个单数的形式,我说why,然后呢下面呢我定义好了一些分类,然后来每一个分类下面的又有数量合适的鞋子类。并且对他们进行了一些很好的命名等等。那么在接下来我们稍微回到一下我们的属性。那么在这个属性里面我们会定义了这个定义域和这个值域。那么在这里我们可以看到我们有一些定义域,比如说这个属性,它的定义域是一个类。那么它的值域来是一些允许的这个值。我当定义一个属性的定义域或者值域的时候了,一般来讲呢,我们会去寻找最一般的累。作为他的定义域或者值域。比如说我们考虑味道这样的一个属性。这里的这个定义域可能是红葡萄酒,白葡萄酒和这个玫瑰葡萄酒。我们也可以去考虑了,它的定义域的就是这个葡萄酒。一般来讲,难道我们选择这个最一般的这样的一个类来作为他的电影预览会更好一点?同样的,我们考虑比如说酿酒厂的这个生产属性,我们做这个红葡萄酒,白葡萄酒,玫瑰葡萄酒,那么一个酿酒厂都可以生产。那么这时候我们直欲来也可以的,这一一个最一般的累,比如说它生产的就是葡萄酒。那么所以呢我们可以说比如说我去定义定义域或者值域的时候,一个类和一个父类,一般我们会用父类来去替代他一个类来他的所有子类。我们也可以来去用复利来去替代作为他的电影玉或者值域。那么有一种特殊情况,可能它的值域或者定义域只是一个类的大多数子类,满足那么并不是所有的这个子类都买了。那么这个时候啊实际上在实际使用中键我们也可以考虑来用这个父类作为替代。使得我们的整个定义啊相对来讲比较简单清晰,虽然这个背后了他不是所有的这个纸,这个纸类都可以满足这样的一个情况。另外我们在这个区打VR里面,我们还说了我们可以去定义一些叫逆属性,比如说我们做maker和produces。那么他是互利的两个属性,你的一个葡萄酒他的这个生产商是某一个葡萄酒厂,那么意味着这个葡萄油厂来生产的某种葡萄酒。所以呢这个时候呢我可以定义一种互利的这种事情。那么逆属性呢它包含的是一些冗余的信息,因为你如果定义了一个属性,那么你也包含了他的这个逆属性,那么这时候实际上是一种冗余的信息。但是呢这个力属性它通过冗余的这样一个定义,它也可以有一些好处。比如说它允许通过任意的这个方向来表达这个信息。也就意思是这个任意的方向里面这两个属性啊你都可以去表达。那么它增加了一些额外的验证,你如果定义了两个这个互利的属性,那么你只写了一个方向的这样的一个取值。那么另外一个方向呢你可以作为一个验证。那么看一看这个定义是不是出现了矛盾还是没有矛盾。而且呢它可以充允许的通过两个方向呢去表达信息,因为我们刚来的这个maker和produces那么他实在是不同的这样一个这个字符的这样这个文本的表达。所以呢在这时候呢,他可以通过了不同的方向去表达这个信息。但是大家需要注意的是这个在内系统啊,不同的系统呢,它的内部实现它不太一样。比如说我现在有个东西去解析,会去存储它的时候。比如说我对于这种逆属性,我两个值是否都存储,还是我只要存储一个方向。那么或者说我什么时候应该填入力属性的这个纸袋是我在存储的时候就把这个力属性的职业填进去,还是说我如果以后查询的时候我知道这个是个逆属性,我查询的时候我动态的把这个钢材它的相对应的这个值调换一下次序,那么我就把它返回了。另外呢还有如果我现在将一个这个属性练改成立项的时候,这个时候我又应该去怎么样处理的?这个地方来,大家需要注意的是在殴打边儿第一版里面,我们没有讲到这个属性练的东西。但是在第二版里面他们增加了这个一个新的概念,叫属性炼属性炼,就是比如说这个呃一个学生,那么他呢可能有一个学校。这样的一个属性。那么这个属性呢他又有个取值叫国家又有个属性叫国家,比如说张三,他是南京大学的学生,然后这个南京大学他又有一个属性叫这个国家,那么就是脏灾难等于来张粘在他的国家了,或者他的这个国籍,但是中国等等的这样的形成的一个属性练了这样的关系。那么这个属性练呢是这个多个属性形成的这种首尾相接的这种结构。另外,还有一些情况下有一些默认值。默认值是一个实例被创建时分配的一个属性值。默认值的可以被修改,默认指的是属性的这个长剑职带着他不是必须的值。比如说一个葡萄酒的这个酒体,它的默认值来可以是满。







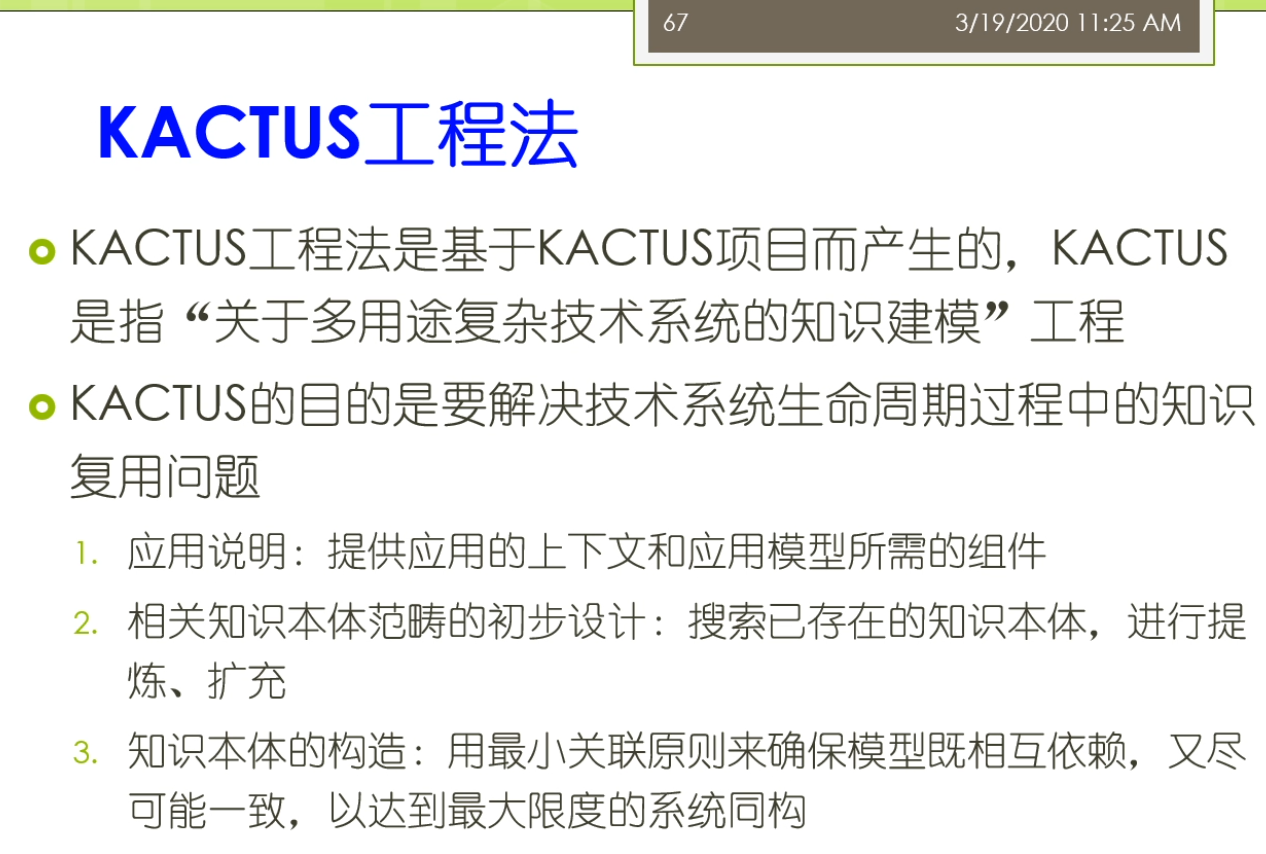
因为呢我们还可以的有一些限制的范围。比如说我们这里要考虑的是一个本体,他不应该包含某一个领域的这个所有的信息。那么这时候你就需要考虑,比如说我对于我的需求来讲,我不需要具体化或者泛化比这个应用需求更多的一些需求。那么我可以稍微有些犯法,那么为了我的这个定义的完整性等等,但是在我不需要考虑的特别多。否则的话呢就变成我们一开始说的这个无穷无尽的这个问题。另外呢还有一个方面,对于一个类来讲,我不要考虑的是不需要包含一个类的所有可能的这个属性。那么你只需要包含的是一些最重要的属性以及待可能是应用需要的这些属性。而对于当前的一些应用,或者我们当前的考虑的这个领域来讲,那么他不需要的这些属性,那么你可能呢就不需要去增加了。比如说我们刚才说的这个葡萄酒的例子里面,我们说可能葡萄酒的原料是有个葡萄,那么这个葡萄里面我们可能就去定义的他的一些这个产地呀,然后他的一些这个这个一些特征那不就可以了。但是比如说这个葡萄的一些这个生理这个这个这个植物的这个分类,那么等等的这些东西我们就不需要再去考虑的特别多。那么因为这个不是我们定义葡萄酒葡萄酒厂所需要的一些内容。那么另外呢我们还可能呢要去限制一些这个范围,比如说我有一些这个酒和这个食物。那么这个酒和食物他不应该去包含的,比如说我们刚才说这个酒瓶大小。标签的颜色,我最喜欢的一些食物或者这个葡萄酒。或者一个实验,生物实验本体应该包含这个生物体。那么实验者那么这时候又说了这个实验者是不是生物体的一个子类。等等的这些东西需要你做好这样的一个范围的限制。否则的话呢,那么这个开发的说法你的成本很高难度也很大。因为你要考虑很多很多不相关的一些东西。那么你们两不说这个类层次很明显的它具有这个传递性,比如说我们说b是a的子类,c是b的子类,那么我们很可能很容易得到selection a的这个字。一个累啊,他的直接的负累了,就是他最近的这个夫人。那么前面呢我们大体上啊讲的是这个呃斯坦福七部法的一些相关的开发的过程。那么这个斯坦福七步法来这个相对来讲比较简单,那么感兴趣的同学可以在这个网上能找到她有一个专门的叫101的这个课程。那么在国外这个101这个课程就是最基础的入门的第一位。第一节课,比如说这个计算机的同学可能有这个cs101,要不然就是最基础的一个一个课程能把本体这儿来,他也有这个相应的101的课程,要不要主要就讲的是这个本体的这个构建。那么除了这个斯坦福我们俗称的这个七步法身上还有其他的一些本体构建的方法。那么这里呢我们简单的呢做一些这个介绍,这个呢第一个来叫这个叫多伦多的这样的一个叫透露的这个法。或者再也称未来就要这个格林跟fox的评价法。它主要用于构建的是关于的企业建模过程中的这个知识本体。他是由加拿大的这个多伦多实验室多得多,大学的一个叫企业集成实验室研制。他使用载一个一阶谓词逻辑带进行集成。那么这里面呢它的本体包括了企业设计的本体,工程的本体是计划的本体,服务的本体啊等等的,这些东西它都包含在。那么这个流程呢我们可以简单的来看一下,他可能包括首先呢你要去定义直接可能的应用和所有解决方案。提供了一些潜在的非形式化的对象和关系的语义表示。他要将系统能够回答的问题来作为约束条件,包括系统能解决什么问题,如何解决。由于在是在这个知识本体没有形式化之前进行的,所以呢又被称为叫非形式化的这个系统的利益问题。然后呢他要去进行术语的形式化,他从这种非形式化系统能力问题中间去提取非形式化的速率。然后用知识本体形式化来语言进行第一。然后呢这就形成了形式化的系统能能力问题,一旦这个知识本体的这个类的概念得到定义,这个系统呢能力问题就脱离的非形式化。演变成形式化的能力问题。他将这些行规则了他将规则形式化为这个公里,也就是说,术语定义所遵循的公理用一阶谓词表示。包括定义的语义或者解释,最终带他去调整这个解决方案,使得这个本起来去玩的。那么从这个过程里面大家可以看到它和这个斯坦福七步法实在是也比较类似,它主要也是关注这个能力问题。但是他在这个能力问题的定义的过程中间,他就起把它区分成了这个非形式化的能力问题和这个形式化的能力问题。那么逐步来进行这个看法。那么另外呢还有这个叫这个mass ontology的这个方法,那么它主要用于构建了这个化学知识本体,这个方法来是被马德里理工大学大学理工分校这个人工智能图书馆所采用的一种方法。他来相对来讲呢这个里面的主要流程就包括了管理阶段,比如说这个阶段的系统规划,包括任务的进展情况,需要的资源。如何来保证质量等等。开发阶段的分为规范,说明概念化,形式化执行以及维护五个步骤。那么维护阶段呢包括知识的获取,系统的集成,评价文档,说明管理,配置在五个步骤。那么另外呢还有一些方法,有的称为叫这个股价,那么它是专门用来构建企业本体。友称未来就要这个企业法,它是建立在企业本体,建立在企业本体基础上,它是相关的商业企业间术语和定义的一个集合。这个方法来他只提供了一个开发本体的一个指导的方针。在这里他几个过程包括了比如说他要确定只是本体应用的这个目的。和这个范围,他根据所研究的领域或者任务建立了相应的领域本体。或者了过程本体领域越大所见的这个知识本体越大。因此在需要限制本体工程的这个领域饭这个和我们刚才讲四汉服七步法里面的第一步是比较类似的。那么它还有知识本体的一个分析,它定义本体啊,所有术语的意义和术语间的关系,这个步骤的需要学科专家的参与。对该领域的越了解,所间的本体啊就越完善,还要有来知识本体的表示。一般来用语音模型表示知识本体。那么知识本体的一个评价,他要建立知识本体的评价标准嘛,是清晰的,一致的,完善的,可扩展的。清晰性美就是本体中的术语,应该被无歧义的定义。一致性带指的是素与之间的逻辑上的一致性,完整性来指的是本体宗的概念及关系的应该是完整的。In包含了该领域所有的概念,但是在很难达到应该来要不断完善。最后呢,这个可扩展性指的是本体应用的能够扩展,在该领域发展过程中间呢能够加入新的概念。那么第五步也是这个知识本体的建立,对所有的这个知识本体按上面的标准进行检验,符合要求,以文件的形式存放,否则那就转到前面的步骤。往复循环,直到在所有的步骤的检验结果均达到了这个要求为止。另外还有一些方法,这个叫cakes这个方法,那么它是基于一个项目产生的。那么主要呢是指关于多用途复杂技术系统的一个知识建模的过程。这里来主要来他要解决的是技术系统,现在命周期过程中间的知识复用问题,包括应用说明相关的知识,本体范围的初步的设计,还有知识本体的构造,这只热了就不详细说了。还有哪像这个census方法?










三色是方法,它主要呢这个开发用于自然源处理的一个问题。那么这个班级来共包括了电子科学领域七万多个概念。为了我能站在这个三色是基础上构造特定领域的知识,必须要把不相关的这个术语从中间剪除掉。嗯。这时回来他就定义了相关的一些裁剪这样的,不过那么还有来这个id,f这个方法,那么他也是主要面向这个企业去做。那么他的步骤来主要有定义这个课题,组织队伍收集数据分析数据。只是本体初步开发,粉底优化了和验证。那么在这个过程中间,那么它又有相应的一些东西,那么感兴趣的同学了,可厚了可以进行进一步的去看一看,你要来就由于时间关系的我们就不详细的去讲。那么前面呢我看的主要都是一些本体开发的这个方法,那么实际上呢在这个开发过程中间了,那么他们的基本不等式比较类似。那么这个里面呢又产生了一些相映的这个研究问题,这样我们来稍微来拓展一下。第一个就是本体啊,这个工程里面它的内容怎么生成?第二个呢就是怎么样去分析和评价,还包括了怎么样进行维护。怎么样嘞?选择合适的本体语言怎么样呢?有这个相应的工具。第一个我们来看一看有一些概念成为来叫顶层本体。这里的和顶层本体的这个底层到底是什么意思上他有好多的。比如说对于对象,我们可以分为有形的,无形的,那么对于一些中主要的东西,比如过程,事件,演员角色,agent的组织空间,边界,位置,时间等等。相对来讲呢这些东西呀都是一些比较泛的比较抽象的一些概念。那么鸡血了可能的比较适合于表达了这个顶层。那么对于这个顶层本体的工作了,迟到挨锤破亿了,他有一个这个专门的工作。他的目标但是设计一个上层的本体,那么这个过程呢是融合现有的这个上层的已有的本体去做的。那么在这里就会有一个最主要的问题是知识获取。我们之前说到知识工程的主要的瓶颈就是支持过去。那么可以通过共享和重用来缓和一些这个问题,因为你如果去重庆了,别人的那么你就没有这个知识获取的这样的困难。但是在这个过程中间是让我们还需要用到很多自动的知识获取的技术。特别是现代的在我们的整个万维网还进去,那么在许多情况下,你很难完全通过手工的方式去订,那么你需要有一些自动化的方法去处理。比如说我们有语言学的这个技术,我们可以从这个本体中间文本中间的这个本体获取。我们还有一些机器学习的方法,我可以从结构化的文档中生成本子,比如说XML的文档。我还可以来要探索这个外部结构,通过抓取结构化的网站来生成这个本体。所以呢这个知识获取的这个自动化的这个知识获取的技术在现在的整个的这个知识获取或者这个本体的研究过程中间这个来是一个比较重要的,也比较流热的一个研究方向。比如说特别是现在我们随着这个深度学习的这样一个星期之后,有很多关于基于深度学习的一些知识获取或者抽取的这个技术。比如说你可以用这个关系抽取的技术,或者我们说这个槽填充的语义槽填充,那这个技术等等的这些东西都可以用作我们在这个知识获取。另外俩在这个本体定义之后,我们还会有许多的这个分析的分析的工作呢,时代有分成两类。第一类呢是关于这个正确性的。比如说我们要去分析这个语义的一致性,比如说违反属性约束的。有没有出现那层次结构,中间有没有这种循环定义形成了这个环。有没有使用但是未定义的这个术语,比如说我们刚才说张三是一个这个研究生,刚才也是个学生,那么我们就说张三是一个这个人。但是这个人这个我们没有去定给忘掉了,这个要去检查村,还有呢有一些这个我们说的激素约束,他们之间是不是存在不满足的情况。比如说我们说最小的技术约束的数量大于的最大约束的塑料这些分析工作了。这个是检查我们羽翼的一致性,还有一些分析工作了是分析我们这个本体的一些风格。比如说有没有只有一个子类的这个类有没有没有定义的这个类和属性?或者呢就是这个累啊,他没有定义这个具体的一些这些这些东西,他只给的这个类,她说她是一个类,然后这个类下面有什么样的一些属性,他没有去讲。还有有没有没有约束的属性?比如说没有定义取出取值范围,在取值类型没有激素等等。那么这方面的他时当不是说他出现了错误,而只是说它的这个订这个去分享他这个风格可能呢会对于你对这个本体来做进一步的改进。那么原来并没有错,但是在可能不是那么好,那么需要进一步的改进。这几点有许多自动分析的一些工作。那么比如说这个这个斯坦福的这个k sl的做做开发的这个这个工具,以及在原来这个大梦的有个管理data,sb可以把这个本体的这个输入进去,它可以进行改这个验证。那么实际上呢这个评价呢是本体设计总监最困难的一个问题,因为这个评价有很很多个方面呢,这个主观性。那么好坏呢那么取决于了一些这个个人的这样的一个主观的判断。那么最好的一种测试的就是对设计出的本体呀放到实际的这个环境中间去使用。如果在这个实际的应用中间它没有发现问题,那么就证明了这个本体开发了是比较好的,如果发现但还是有问题,那么证明你这个本体的设计还是存在的,一些不足需要进一步的去改进。那么另外这里面我们还有本体的维护的问题,比如说我们有本体的融合的问题。那么他也可以称为来叫本体的匹配的问题,比如说会存在两个或者多个重叠的本体。我要创建,现在我要创建出来一个新的本体,把这两个这个重复的本体或者这个合并一下。那么还有本体的映射。那么这实话两个本体中间可能有一些这个相同的概念,相同的属性我要把它找到。还可能呢这个本体还会出现版本的这个控制和演化。那么一个本体的这个多个版本和实力数据件是不是兼容?这个脸也很重要,比如说你原来定义的一个属性叫maker。那么在下一个版本中间你没有这个属性啊或者这个属性换了名字了。那么你原来的实力数据可能就在新版本上就用不起来了,因为你没有这个相应的这个属性的点。所以这个时候呢也需要考虑这个剪辑。那么关于本体语言,那么这时候选择的时候会有什么?是一个合适的表达能力?比如说我这个本体语言,我是基于的这个描述裸机的还是基于描述逻辑更一般的那个子集的更小的一个子集的。我怎么是合适的语义?比如说是基于这个意见裸机的,那么什么时候对这个语言来做了过多的这个假设了?那么使得这个语言呢不太使用了或者过于简化了。或者过于复杂了,现在那么另外呢,我们还会考虑一些开发工具,比如说能支持各种本体语言,它的表达能力如何?它的可用性如何?值当的越来越多的这个专家呢会参与到本体开发的过程中,就这个开发工具的那么会长重要,因为这些专家他布置不一定啊是计算机的这个专家,他也不一定会写程序。所以然你的这个开发工具越好用,那么使得的这个知识获取啊或者这个知识的本体的定义就会越好。那么在这个课里面呢我们就选了这样子的protete觉得软件,那么这个实际上已经是目前比较好的一个本体开发的工具。这个如果来在这个早几年前大家去使用这个的时候,你会发现这个工具软件那么相对来讲还是比较难用的。那么这个工具软件经常会这个不断的出现各种bug,有着你写了一个本体。那么你还没来得及保存这个软件崩溃了,那么你的所有数据就丢掉了,所以来这个工具还是很重要的。


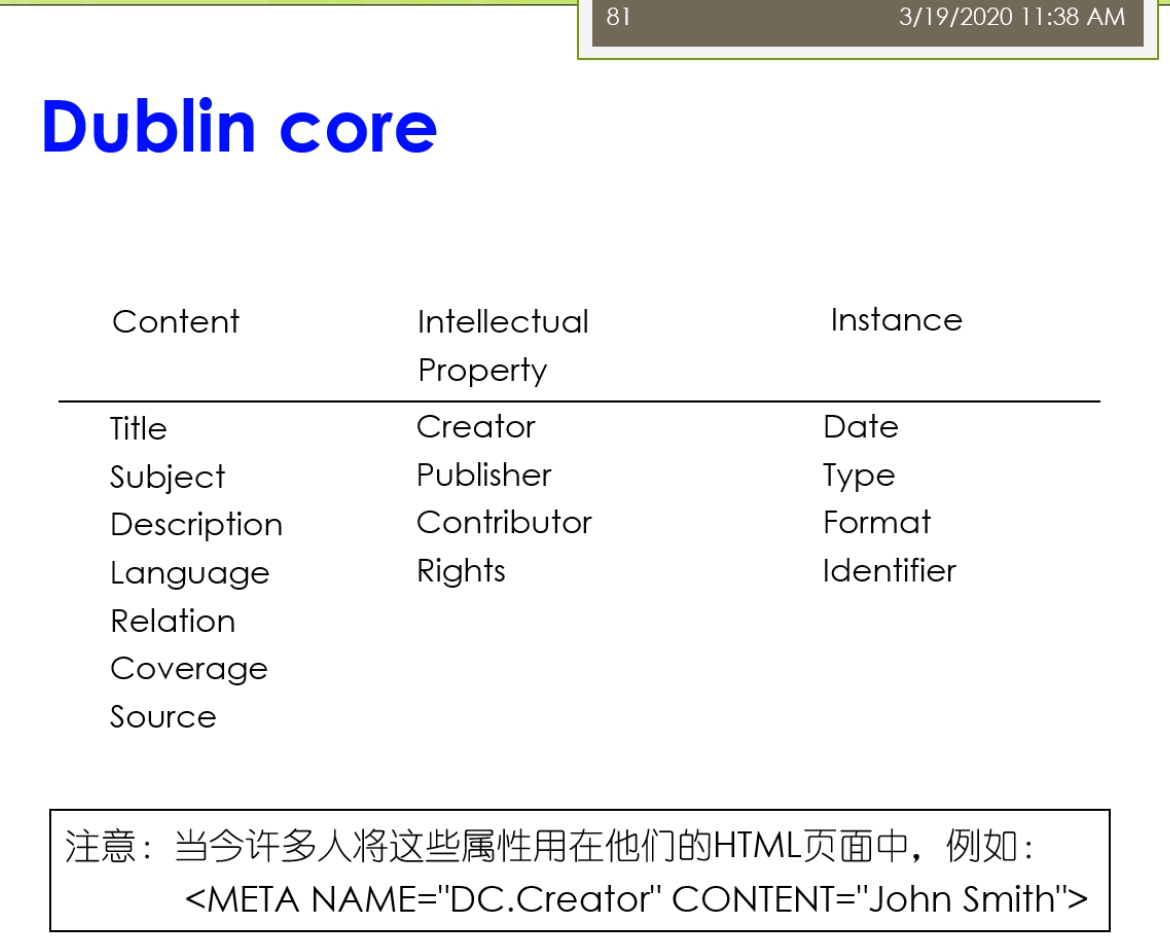


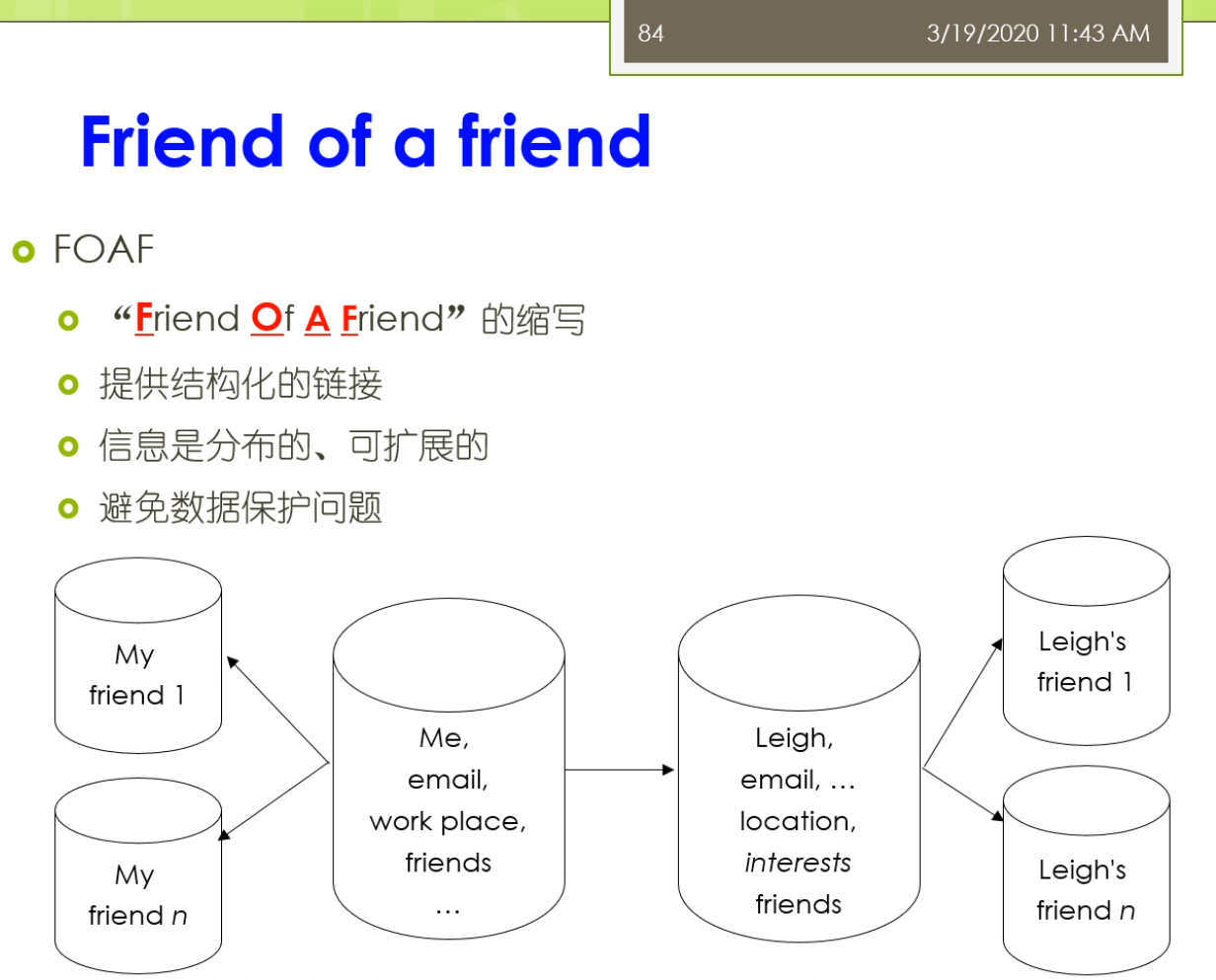

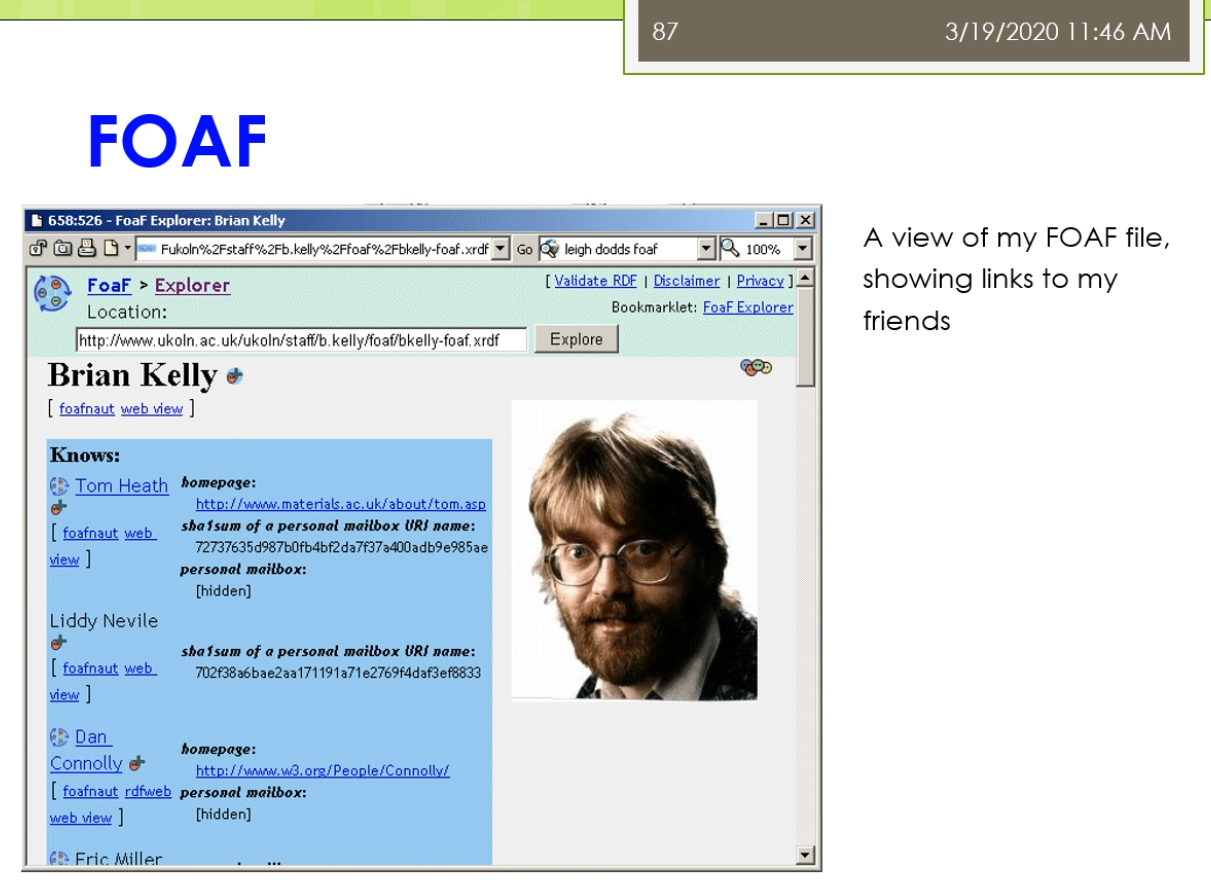
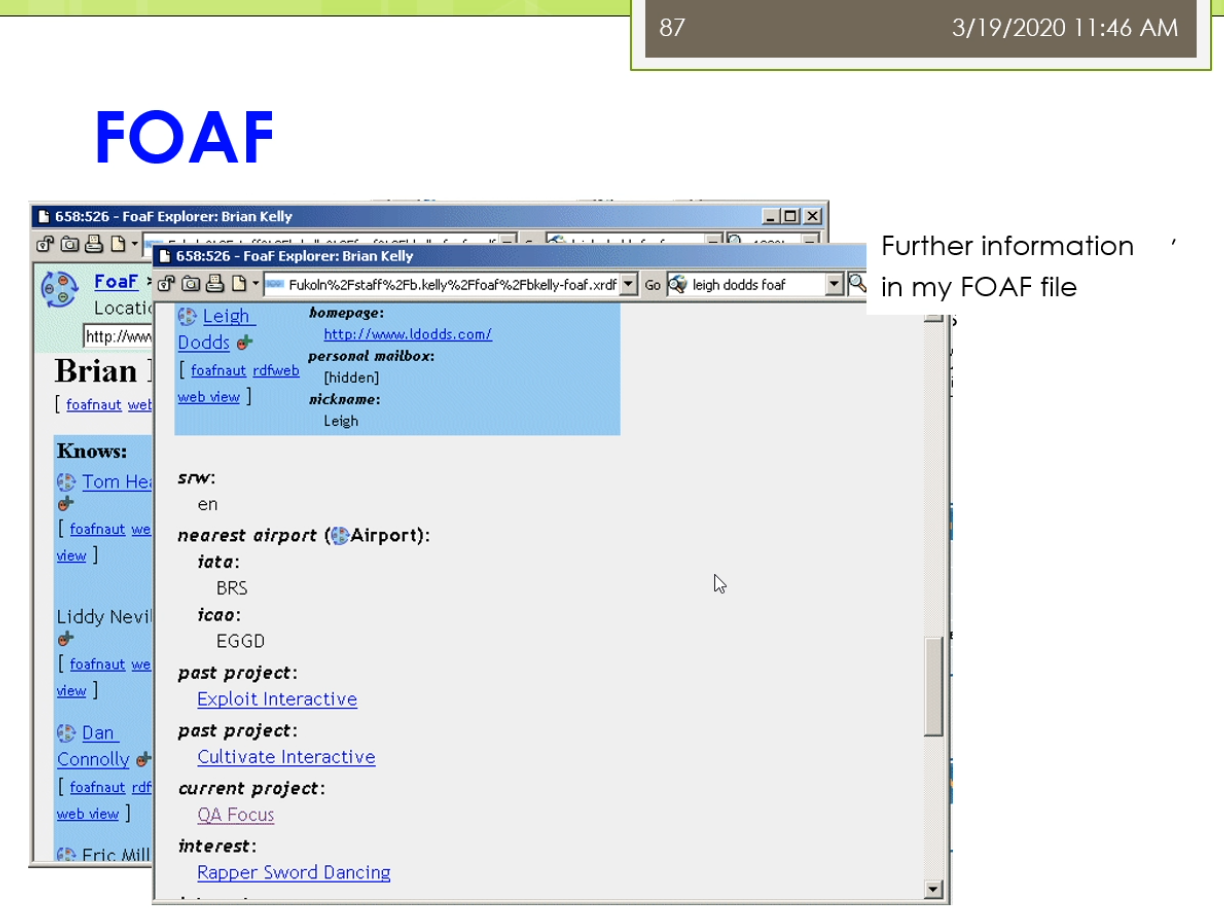
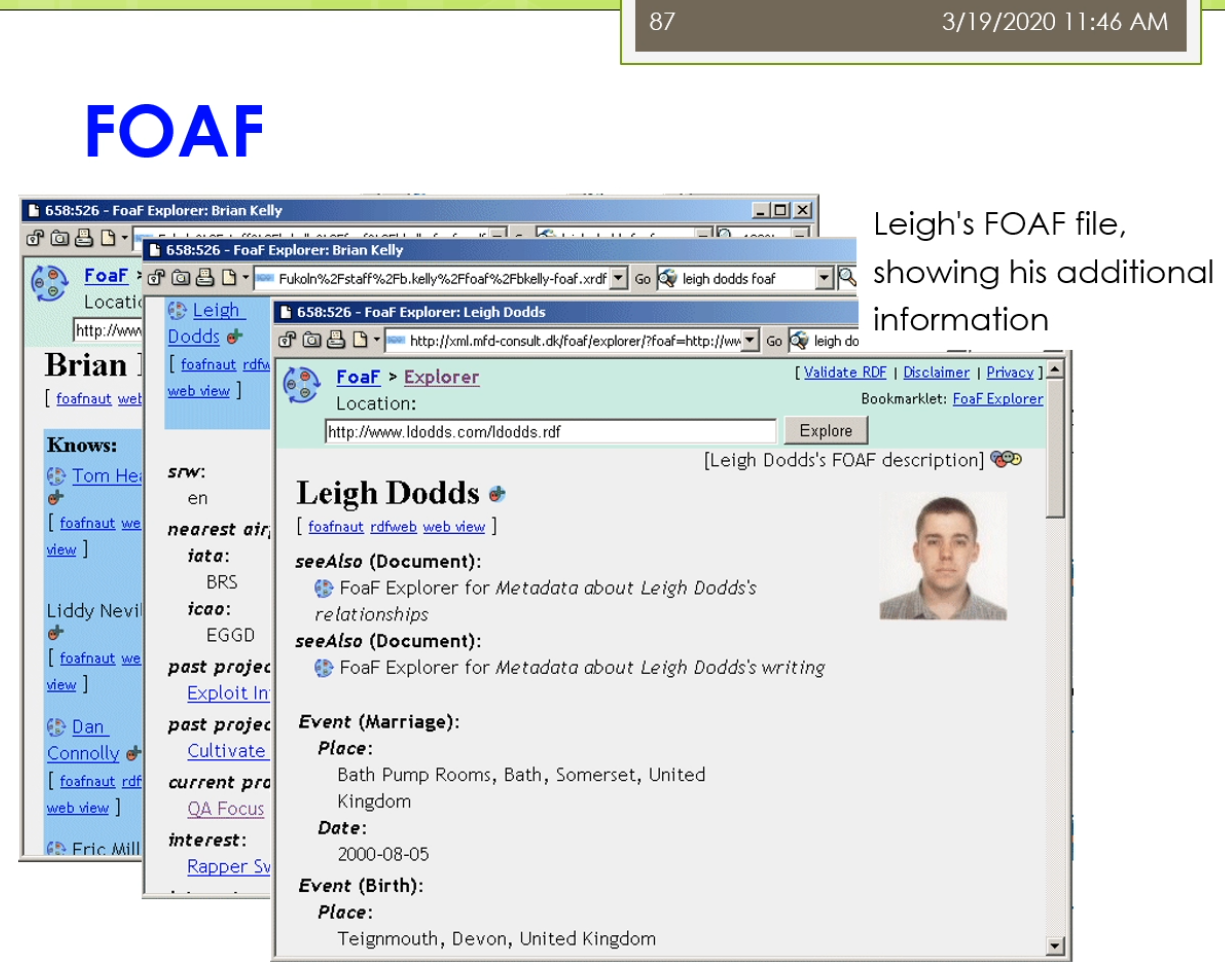


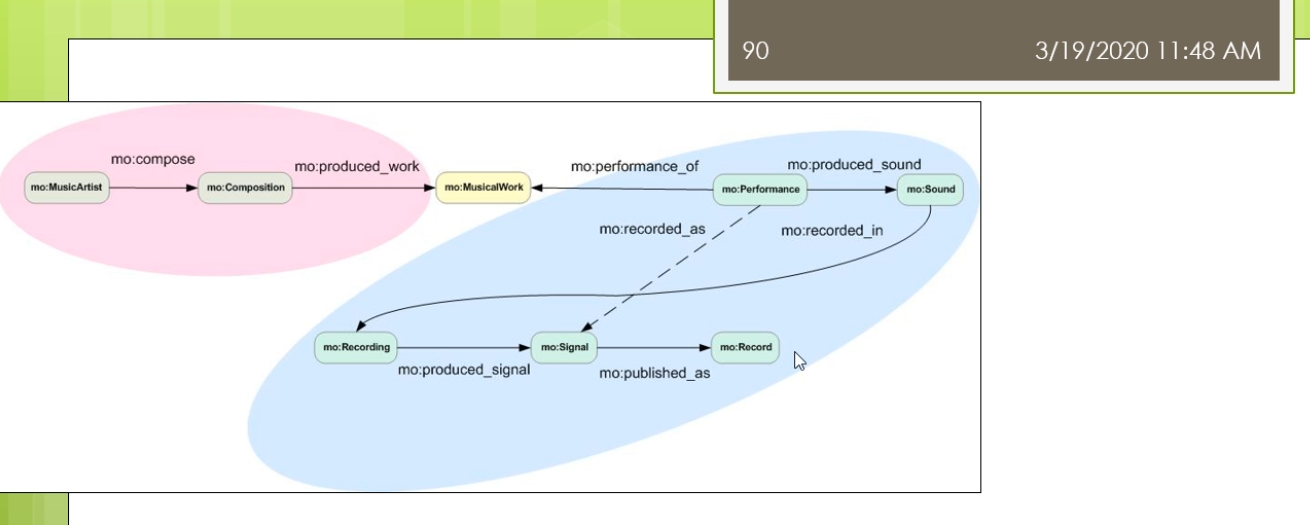
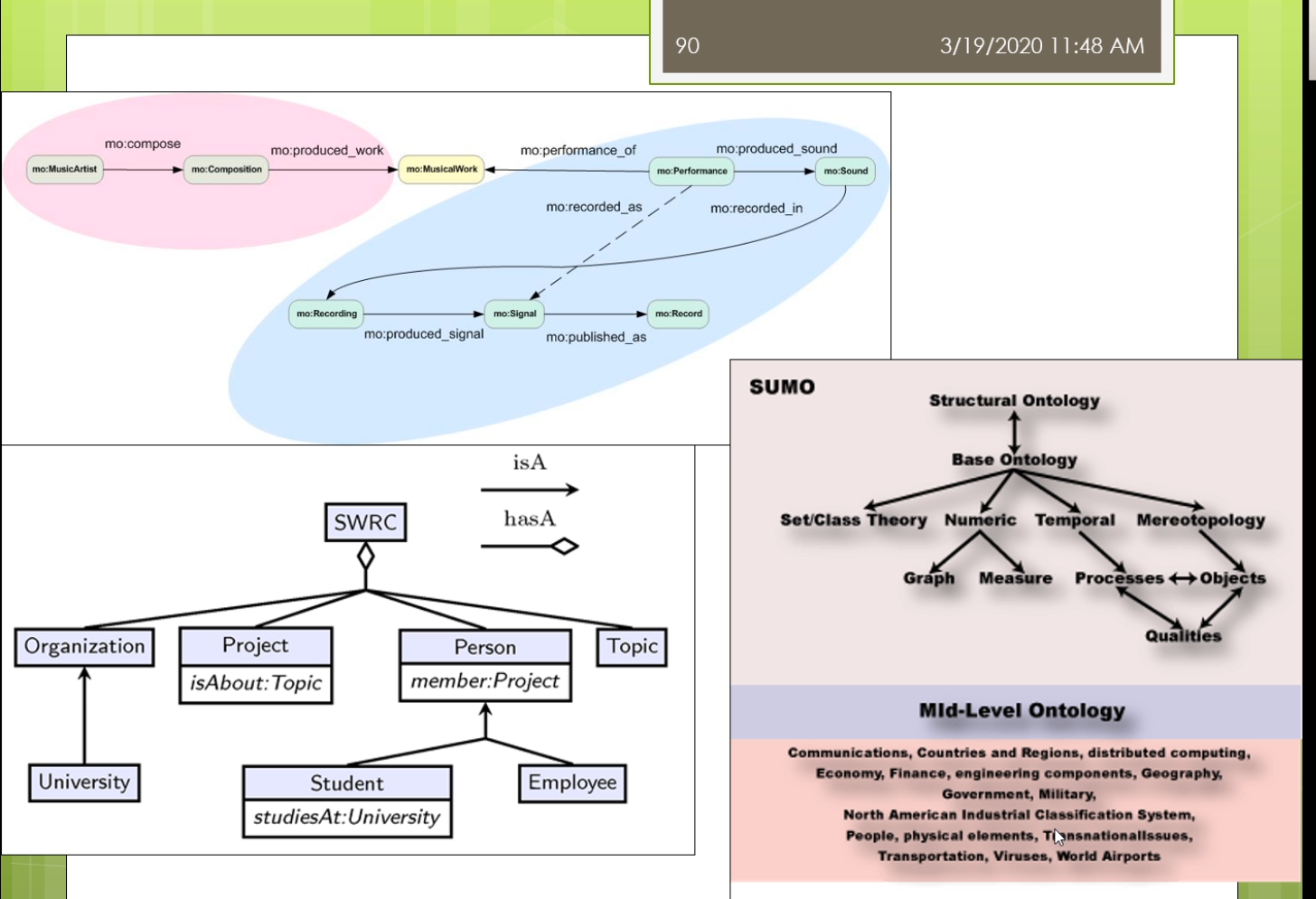


那么在这里我们还有一些这个最后呢我们会稍微来介绍一些关于常用的一些本体,我们做一点点这个简单的介绍。那么这个本体来里面我们常用的一些本体也是在我们的这个本体自己本体定义的过程中,也也经常可以重用他们的。那么包括了比如说第一个我们称为叫这个dc,简称叫dc十大全身,那就要这个Dublin core。这样的一个本体,这个本体来是数字图书馆中间常用的。他使用了一组来简单的15个核心元素的这个元素据数据集合。那么主要用于来描述数字对象馆藏的管理和元素,记得交换。在15巷来源数据啊,他不仅仅的适用于电子文件目录,也是用语的各种电子化的公务文档,目录,产品,商品产品等等,具有很好的实用性。那么他在这个都不Lincoln是一个叫dumpling core metadata的这个组织拟定了。它是用于的标识电子资源的一种简要目录模式也出现了,就在北美,欧洲,亚洲,澳洲二十多个国家来认同了。不早这个图书馆,博物馆,政府机构,商业组织唻,都正在或者准备采用。1994年就提出了有这个DCMI这个组织了去维护,现在已经成为了ISO标准这个IETF的标准等等。他主要呢解决了电子资源的一个标准问题。那么实现的手段可以很多,因为他迟到是一个元素聚在这个图书馆领域,中间呢使用的比较多,效果最好的了是通过XML。或者这个啊df这两种技术手段去实现。那么IDF来我们前面讲的他是要闻于以往的这个数据模型。所以呢这个dc的这样一个东西啊,那么他也成为了一个本体,在我们的羽翼网里面的劲,当时。我们来看一看这个里面它主要讲的是一些什么东西。那么他主要的分为三类。第一类呢是叫内容,第二个呢叫知识产权,第三个来教一些具体的实例。在内容里面主要有这七个,包括了这个标题,包括了他的主题,他的描述,他的语言,他的一些关系,它的覆盖面,它的源来自啦。知识产权这儿呢有这个相应的创建者,发布者,贡献者和他的版权。以及带他还有一些相关的日期,他的类型,他的这个格式,他的一个标识符。总共来这15个暑期。现在呢这些属性呢实际上在他许多人啊会把这些属性的用在自己的这个HTML页面。比如说这个HTML页面,如果大家去写的话,现在会发现很多人会在这个头上会写着一个叫manta,一个元素句所name等于dc点create,所以现在我添加了一条源数据所这个网页它的创建者是什么呢?它的内容是这个John Smith虽然它的创建者是一个叫这个僵尸missed这样的人。那么这样我们的这个本体定义的时候了,我们也可以或者在XML定义的时候呢也可以使用这样的一个形式。我们可以说有个book。Books,books下面呢是一个这个组,这个collection是一个我们坐在一个集合这个集合里面呢,那么它下面每一本书对于具体的每一本书它的描述的是这样。她说她的title是什么,他的房间卷是什么?它的发布日期是什么?它是有哪一个这个出版社发布的。这实话大家需要注意的是,你在使用这些东西的时候,你需要定义一个dc的命名空间,我们说的XML,ns namespace。Dc表明了这个dc的命名空间是这个我不说都不能靠了这样的命名空间。那么另外我们还常见的不经常看到的是在一个本体第一的时候,在本体对于这个本体本身的这个秒我们前面已经看到过,比如说我们说对于一个本体自身而言,我们也可以描述这个是关于一个什么的本体。他的描述的信息是什么?第二个呢我们比较常见的一个这个这个本体的被称为来叫friend of a friend,叫fourth,简称。那么他使上来提供的是一种结构化的链接,面向的来说我们的社交网络。他在这里面呢因为信息啊他是分布的可扩散的,他也避免了数据保护的请问题。在这呢那我们可以看到它主要呢有这样几可以定义的一些相关的一些这个属性,有个email,workplace friend等等。他也有一些那这个对象属性,比如说你的一个friend的取值,但是具体的其他的一些friend。或者是另外一个人,这个人他还可能有些其他的属性,比如说他的这个兴趣爱好是什么?那么这个人他又有可以有一些新的朋友。这个呢for不来这样的一个东西啊,它也是有具体的一个这个相应的这个本体的。我们可以去定义一个,比如说我们现在写的一个person,我们定义了一个叫for person这个personal大家去看的。这个person嘛,我们会说他是一个匿名节点,这个让大家应该能看出。然后呢这个富婆了,这个人他的名字叫什么呢?叫Tiffany这个人。他有一个mailbox的一个校验码,现在呢有一些人他为了不想让别人知道自己的邮箱是什么。那么它不直接提供自己的邮箱,而是提供了一个邮箱的校验吧。这种情况意味着你如果认识这个人,你知道他的邮箱,你可以用工具软件去校验这个邮箱,是不是和这个校验码对于你,但是呢你如果不认识这个人,那么你也不能反推出来他的邮箱锻炼。另外他给出了他的homepage,然后他给出了他的一个自己的一个这个照片,然后他说呢这个人他认识另外一个人,这个人又是个地名节点,这个匿名节点里面大家可以看到匿名节点这个人他有一个自己的名字。他给了一个叫c also的结构,所以你可以参考这个人自己的一个for富的一个他的对于自己个人的饥饿这个信息的描述得一个一个不然的或friend等。虽然这个for服了也是用的很广的一个这个这个我们坐在一个常见的一个本体,它主要面向的是这个社交网络总监在下面。在这个里面呢,他主要定义的有这几类。比如说有这个我们说的这个basic。Basic里面主要有一些类,比如说agent person,还有一些属性有做内容。别称,然后呢他的title就说你是个doctor,homepage,mailbox mailbox的校验值。然后后来这个照片,然后呢你的一些兴安名啊等等的还可以定义的一些个人信息,比如说你的这些这些这个喔place啊,work,homepage啊,publication等等。还可以定义一些社交网络的东西。这个方法来由于定义的比较早,那么他这里主要是一些比如说还是ICQ,MSN等等的一些东西。但是现在大家会发现已经过时了,但是这个不影响你可以进行一些扩展。对吧?你可以把他的这个扩展扩展出来,那么定义一些新的,比如说你的什么微博号啊,微信号啊等等。还可以定义你的一些这个project和group1m的一些这个project和group,比如说你属于什么样的一些组织。然后呢另外呢也可以定义一些其他的一些document和这个图片先相关,所以整个画幅里面大体上的就分为了五大类的这个信息可以去定义。那么每个类里面的有些相关的一些概念和一些他们的属性。那么具体来讲啊,这个force实际上在许多的这个网站上已经有很多的应用,比如说我们可以看到这样的一个人,那么这个人呢他是当就是一个从网页上看,你看不出来它是什么,但是他背后的是基于自己的一个form定义的。他说他认识另外一个叫Tom has的这个人,这个人的他也有自己的方法。所以呢那么你就形成了这样的一个结果。那么就跳转的下面的一个地方那么又可以了,这个跳转的下一个这个号。所以呢就形成了我们做的这个啊df数据之间的这个链接。这个链接的你只是通过一个浏览器呈现出来,但是背后来链接的实际大师资格结构化的数据。那么最终那么这个方法能取得的这个效果实在就成为了我们做的这个数据之间的一种社交的,我在这个网络上很容易进行各种各样的分析。因为它是一种结构化的数据,那么不需要了,你通过网页中间的自然语言去识别这个命名实体以及它们之间的关系这些很不准确的动力去实现。那么这个呢就是一步一步的威胁。另外来除了这些之外,实际上还有很多的这个很流行的或者很通用的一些本体,我们这来简单的介绍一下,比如说像有这个music ontology。叫mo,那么它是面向音乐领域的,还有在这个semantic Web research community s WRC,那么它是面向于以往的研究组织的。还有来这个这个sumo和这个middle这样本体是一些上层本体和中层本体。那么另外呢还有比如说面向维基的这个本体觉滴bp,dear的ontology,或者面向地理信息的只有names这个本体。那么在生物医学领域就更多了,比如像gallon是一种解剖学的,还有这个fffma这些或者基因本体等等。那么这些本体有大有小,因为根据领域不同,比如说相映的相music的这个领域,她这个鱿鱼里面的概念不是很多,那么所以这个本起来相对来讲小一点。而像表哥基因那么这个里面因为分类特别多,那么他这个本起来就会很大。所以呢这些本体的他拾到大小有区别,但是在实际上他都已经在许多的各自的领域中间被这个广泛的应用起来。比如说我们这里可以看到这个呢是一个按摩的本体里面的主要的内容,按摩的主要内容包括了一个比如说作曲啊等等的,这边呢还有相应的这个performance表格里有个演唱会呀,专辑呀等等这些东西。那么这个呢s WRC是一个研究组织的他的一个这个问题。那么这个周末但是我们做的这个上层本体上成本仅里面主要定义的是一些比如说集合,集合盾,然后述职时间等等的一些东西,还有在这个忠诚的本体是对丧生本体的一些细化。虽然那么整个的这个内容呢,我们关于这Yeah,等等那些东西还有来这个忠诚的本体是对上层本体的一些细化。所以呢那么整个的这个内容呢,我们关于这个本体构建的这不把粉底工程的这个内容呢这个稍微来,我们基本上就介绍到这。那么大体上我们稍微回顾一下,我们一开始介绍了这个本体工程的狭义的定义和广义的定义。然后呢我们又讲了讲怎么是本体,那么以及结合我们之前的课我们讲过了这个呃啊df啊DFS后两辆不讲了,斯坦福的这个七步法怎么去开发本体?刚刚呢我们有稍微回顾了一下一些领域里面比较有代表性的一些问题。那么这个呢如果大家感兴趣的这边呢有一个这个扩展的阅读,那么是这个party这个软件它的一个后续的一个研究,那么称未来叫这个协作是的本体开发。因为之前呢这种本体啊工具软件那么都是单独单个人去使用。那么这个单个人去使用呢只能做很小的这个本体的看法。那么对于一个大的领域的问题开发,比如说我们做基因或者生物医学等等的这些本体,他有数以十万计的概念。那么一个人很难完成,所以这时回来就需要有协作,一个人本体的开发需要涉及到很多人共同参与的。那么这种情况下呢,这个协作市本级开发了就产生了,那么这里面就会有很多的问题,比如说大家开发过程中间不一致,或者怎么样交互,或者这个共享这个自己开发的结果。I包括了呢这个里面的potato,后来有一个这个外部的这个外部版的,使得大家来不用了一定去装这个工具软件。那么外部版的相对来讲呢比这个这个这个离线版的那么速度慢一点,行不?早期的时候呢它功能比较简单,但是现在的它的功能呢也组建了这个丰富起来。好,总体的我们今天的课来就上到这边,怎么大家记得我们这个课来,我不知道一次这个作业,就是这个作业的内容就是使用这个package。那么选择一个你熟悉的这个领域的构建一个这个本体,大家来这个呃通过使用的这个把这个本体的这个这个弄好。他们今天克莱就上到这边,我们就下课吧。