转自 http://element-ui.cn/news/show-44900.aspx
文章目录
- 1.IOMMU
- 1.1 IOMMU功能简介
- 1.2 IOMMU作用
- 1.3 IOMMU工作原理
- 1.4 Source Identifier
- 2.VFIO
- 2.1 概念介绍
- 2.2 使用示例
- 3.设备透传分析
- 3.1 虚机地址映射
- 3.2 设备透传实现
1.IOMMU
1.1 IOMMU功能简介
IOMMU主要功能包括DMA Remapping和Interrupt Remapping,这里主要讲解DMA Remapping,Interrupt Remapping会独立讲解。对于DMA Remapping,IOMMU与MMU类似。IOMMU可以将一个设备访问地址转换为存储器地址,下图针对有无IOMMU情况说明IOMMU作用。
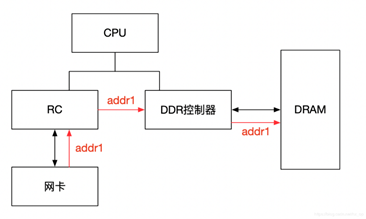
在没有IOMMU的情况下,网卡接收数据时地址转换流程,RC会将网卡请求写入地址addr1直接发送到DDR控制器,然后访问DRAM上的addr1地址,这里的RC对网卡请求地址不做任何转换,网卡访问的地址必须是物理地址。

对于有IOMMU的情况,网卡请求写入地址addr1会被IOMMU转换为addr2,然后发送到DDR控制器,最终访问的是DRAM上addr2地址,网卡访问的地址addr1会被IOMMU转换成真正的物理地址addr2,这里可以将addr1理解为虚机地址。
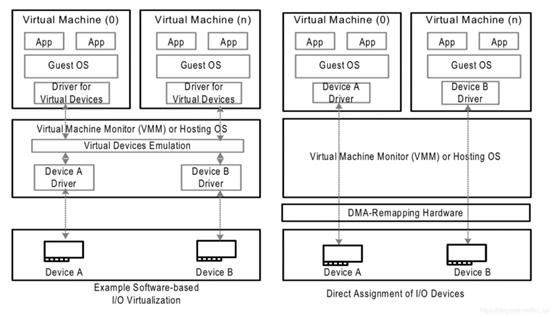
左图是没有IOMMU的情况,对于虚机无法实现设备的透传,原因主要有两个:
- 一是因为在没有IOMMU的情况下,设备必须访问真实的物理地址HPA,而虚机可见的是GPA;
- 二是如果让虚机填入真正的HPA,那样的话相当于虚机可以直接访问物理地址,会有安全隐患。
所以针对没有IOMMU的情况,不能用透传的方式,对于设备的直接访问都会有VMM接管,这样就不会对虚机暴露HPA。
右图是有IOMMU的情况,虚机可以将GPA直接写入到设备,当设备进行DMA传输时,设备请求地址GPA由IOMMU转换为HPA(硬件自动完成),进而DMA操作真实的物理空间。IOMMU的映射关系是由VMM维护的,HPA对虚机不可见,保障了安全问题,利用IOMMU可实现设备的透传。这里先留一个问题,既然IOMMU可以将设备访问地址映射成真实的物理地址,那么对于右图中的Device A和Device B,IOMMU必须保证两个设备映射后的物理空间不能存在交集,否则两个虚机可以相互干扰,这和IOMMU的映射原理有关,后面会详细介绍。
1.2 IOMMU作用
根据上一节内容,总结IOMMU主要作用如下:
- 屏蔽物理地址,起到保护作用。典型应用包括两个:一是实现用户态驱动,由于IOMMU的映射功能,使HPA对用户空间不可见,在vfio部分还会举例。二是将设备透传给虚机,使HPA对虚机不可见,并将GPA映射为HPA.
- IOMMU可以将连续的虚拟地址映射到不连续的多个物理内存片段,这部分功能于MMU类似,对于没有IOMMU的情况,设备访问的物理空间必须是连续的,IOMMU可有效的解决这个问题
1.3 IOMMU工作原理
前面简单介绍了IOMMU的映射功能,下面讲述IOMMU到底如何实现映射的,为便于分析,这里先不考虑虚拟化的场景,以下图为例,阐述工作原理。
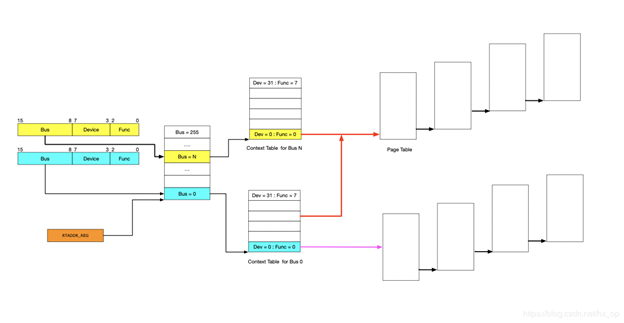
IOMMU的主要功能就是完成映射,类比MMU利用页表实现VA->PA的映射,IOMMU也需要用到页表,那么下一个问题就是如何找到页表。在设备发起DMA请求时,会将自己的Source Identifier(包含Bus、Device、Func)包含在请求中,IOMMU根据这个标识,以RTADDR_REG指向空间为基地址,然后利用Bus、Device、Func在Context Table中找到对应的Context Entry,即页表首地址,然后利用页表即可将设备请求的虚拟地址翻译成物理地址。这里做以下说明:
- 图中红线的部门,是两个Context Entry指向了同一个页表。这种情况在虚拟化场景中的典型用法就是这两个Context Entry对应的不同PCIe设备属于同一个虚机,那样IOMMU在将GPA->HPA过程中要遵循同一规则 ?????
- 由图中可知,每个具有Source Identifier(包含Bus、Device、Func)的设备都会具有一个Context Entry。如果不这样做,所有设备共用同一个页表,隶属于不同虚机的不同GPA就会翻译成相同HPA,会产生问题,
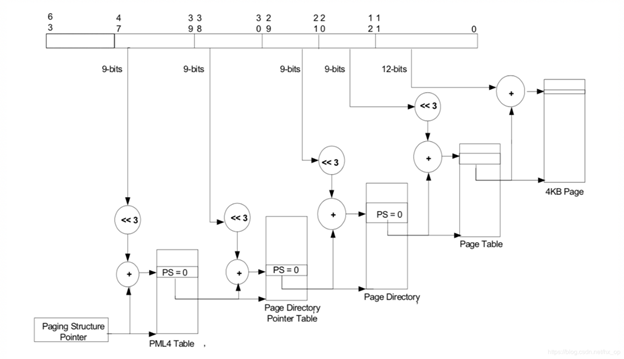
有了页表之后,就可以按照MMU那样进行地址映射工作了,这里也支持不同页大小的映射,包括4KB、2MB、1GB,不同页大小对应的级数也不同,下图以4KB页大小为例说明,映射过程和MMU类似,不再详细阐述。
1.4 Source Identifier
在讲述IOMMU的工作原理时,讲到了设备利用自己的Source Identifier(包含Bus、Device、Func)来找到页表项来完成地址映射,不过存在下面几个特殊情况需要考虑。
- 对于由PCIe switch扩展出的PCI桥及桥下设备,在发送DMA请求时,Source Identifier是PCIe switch的,这样的话该PCI桥及桥下所有设备都会使用PCIe switch的Source Identifier去定位Context Entry,找到的页表也是同一个,如果将这个PCI桥下的不同设备分给不同虚机,由于会使用同一份页表,这样会产生问题,针对这种情况,当前PCI桥及桥下的所有设备必须分配给同一个虚机,这就是VFIO中组的概念,下面会再讲到。
- 对于SRIO-V,之前介绍过VF的Bus及devfn的计算方法,所以不同VF会有不同的Source Identifier,映射到不同虚机也是没有问题的
2.VFIO
#########Virtual Function I/O (VFIO) 是一种现代化的设备直通方案,它充分利用了VT-d/AMD-Vi技术提供的DMA Remapping和Interrupt Remapping特性, 在保证直通设备的DMA安全性同时可以达到接近物理设备的I/O的性能。 用户态进程可以直接使用VFIO驱动直接访问硬件,并且由于整个过程是在IOMMU的保护下进行因此十分安全, 而且非特权用户也是可以直接使用。 换句话说,VFIO是一套完整的用户态驱动(userspace driver)方案,因为它可以安全地把设备I/O、中断、DMA等能力呈现给用户空间。
为了达到最高的IO性能,虚拟机就需要VFIO这种设备直通方式,因为它具有低延时、高带宽的特点,并且guest也能够直接使用设备的原生驱动。 这些优异的特点得益于VFIO对VT-d/AMD-Vi所提供的DMA Remapping和Interrupt Remapping机制的应用。 VFIO使用DMA Remapping为每个Domain建立独立的IOMMU Page Table将直通设备的DMA访问限制在Domain的地址空间之内保证了用户态DMA的安全性, 使用Interrupt Remapping来完成中断重映射和Interrupt Posting来达到中断隔离和中断直接投递的目的。
2.1. VFIO 框架简介
整个VFIO框架设计十分简洁清晰,可以用下面的一幅图描述:
+--------------------------------------------------------------+
| VFIO interface |
+--------------------------------------------------------------+
| vfio_iommu | vfio_pci |
+--------------------------------------------------------------+
| iommu driver | pci_bus driver |
+--------------------------------------------------------------+
最上层VFIO Interface Layer,它负责向用户态提供统一访问的接口,用户态通过约定的ioctl设置和调用VFIO的各种能力。
中间层分别是vfio_iommu和vfio_pci:
vfio_iommu是VFIO对iommu层的统一封装主要用来实现DMA Remapping的功能,即管理IOMMU页表的能力。
vfio_pci是VFIO对pci设备驱动的统一封装,它和用户态进程一起配合完成设备访问直接访问,具体包括PCI配置空间模拟、PCI Bar空间重定向,Interrupt Remapping等。
最下面的一层则是硬件驱动调用层:
iommu driver是与硬件平台相关的实现,例如它可能是intel iommu driver或amd iommu driver或者ppc iommu driver或者arm SMMU driver;
pci_bus driver: 而同时vfio_pci会调用到host上的pci_bus driver来实现设备的注册和反注册等操作。
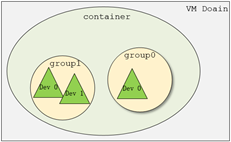
在了解VFIO之前需要了解3个基本概念:device, group, container,它们在逻辑上的关系如上图所示。
- Group 是IOMMU能够进行DMA隔离的最小硬件单元,一个group内可能只有一个device,也可能有多个device,这取决于物理平台上硬件的IOMMU拓扑结构。 设备直通的时候一个group里面的设备必须都直通给一个虚拟机。 不能够让一个group里的多个device分别从属于2个不同的VM,也不允许部分device在host上而另一部分被分配到guest里, 因为就这样一个guest中的device可以利用DMA攻击获取另外一个guest里的数据,就无法做到物理上的DMA隔离。 另外,VFIO中的group和iommu group可以认为是同一个概念。
- Device 指的是我们要操作的硬件设备,不过这里的“设备”需要从IOMMU拓扑的角度去理解。如果该设备是一个硬件拓扑上独立的设备,那么它自己就构成一个iommu group。 如果这里是一个multi-function设备,那么它和其他的function一起组成一个iommu group,因为多个function设备在物理硬件上就是互联的, 他们可以互相访问对方的数据,所以必须放到一个group里隔离起来。值得一提的是,对于支持PCIe ACS特性的硬件设备,我们可以认为他们在物理上是互相隔离的。
- Container 是一个和地址空间相关联的概念,这里可以简单把它理解为一个VM Domain的物理内存空间。对于用户态驱动,Container可以是多个Group的集合。
从上图可以看出,一个或多个device从属于某个group,而一个或多个group又从属于一个container。 如果要将一个device直通给VM,那么先要找到这个设备从属的iommu group,然后将整个group加入到container中即可。关于如何使用VFIO可以参考内核文档:vfio.txt
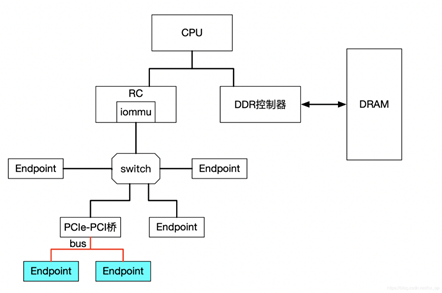
上图中PCIe-PCI桥下的两个设备,在发送DMA请求时,PCIe-PCI桥会为下面两个设备生成Source Identifier,其中Bus域为红色总线号bus,device和func域为0。这样的话,PCIe-PCI桥下的两个设备会找到同一个Context Entry和同一份页表,所以这两个设备不能分别给两个虚机使用,这两个设备就属于一个Group。
2.2 VFIO 数据结构关系
Linux内核设备驱动充分利用了“一切皆文件”的思想,VFIO驱动也不例外,VFIO中为了方便操作device, group, container等对象将它们和对应的设备文件进行绑定。 VFIO驱动在加载的时候会创建一个名为/dev/vfio/vfio的文件,而这个文件的句柄关联到了vfio_container上,用户态进程打开这个文件就可以初始化和访问vfio_container。 当我们把一个设备直通给虚拟机时,首先要做的就是将这个设备从host上进行解绑,即解除host上此设备的驱动,然后将设备驱动绑定为“vfio-pci”, 在完成绑定后会新增一个/dev/vfio/$groupid的文件,其中$groupid为此PCI设备的iommu group id, 这个id号是在操作系统加载iommu driver遍历扫描host上的PCI设备的时候就已经分配好的,可以使用readlink -f /sys/bus/pci/devices/$bdf/iommu_group来查询。 类似的,/dev/vfio/$groupid这个文件的句柄被关联到vfio_group上,用户态进程打开这个文件就可以管理这个iommu group里的设备。 然而VFIO中并没有为每个device单独创建一个文件,而是通过VFIO_GROUP_GET_DEVICE_FD这个ioctl来获取device的句柄,然后再通过这个句柄来管理设备。
VFIO框架中很重要的一部分是要完成DMA Remapping,即为Domain创建对应的IOMMU页表,这个部分是由vfio_iommu_driver来完成的。 vfio_container包含一个指针记录vfio_iommu_driver的信息,在x86上vfio_iommu_driver的具体实现是由vfio_iommu_type1来完成的。 其中包含了vfio_iommu, vfio_domain, vfio_group, vfio_dma等关键数据结构(注意这里是iommu里面的),
- vfio_iommu可以认为是和container概念相对应的iommu数据结构,在虚拟化场景下每个虚拟机的物理地址空间映射到一个vfio_iommu上。
- vfio_group可以认为是和group概念对应的iommu数据结构,它指向一个iommu_group对象,记录了着iommu_group的信息。
- vfio_domain这个概念尤其需要注意,这里绝不能把它理解成一个虚拟机domain,它是一个与DRHD(即IOMMU硬件)相关的概念, 它的出现就是为了应对多IOMMU硬件的场景,我们知道在大规格服务器上可能会有多个IOMMU硬件,不同的IOMMU硬件有可能存在差异, 例如IOMMU 0支持IOMMU_CACHE而IOMMU 1不支持IOMMU_CACHE(当然这种情况少见,大部分平台上硬件功能是具备一致性的),这时候我们不能直接将分别属于不同IOMMU硬件管理的设备直接加入到一个container中, 因为它们的IOMMU页表SNP bit是不一致的。 因此,一种合理的解决办法就是把一个container划分多个vfio_domain,当然在大多数情况下我们只需要一个vfio_domain就足够了。 处在同一个vfio_domain中的设备共享IOMMU页表区域,不同的vfio_domain的页表属性又可以不一致,这样我们就可以支持跨IOMMU硬件的设备直通的混合场景。
经过上面的介绍和分析,我们可以把VFIO各个组件直接的关系用下图表示(点击看完整图片),读者可以按照图中的关系去阅读相关代码实现。
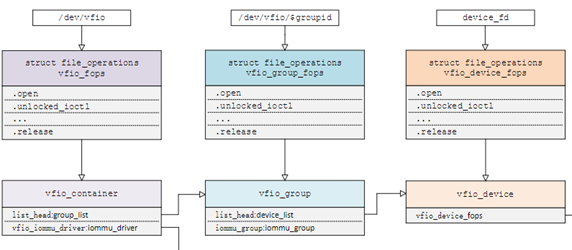
VFIO就是内核针对IOMMU提供的软件框架,支持DMA Remapping和Interrupt Remapping,这里只讲DMA Remapping。VFIO利用IOMMU这个特性,可以屏蔽物理地址对上层的可见性,可以用来开发用户态驱动,也可以实现设备透传。
2.3 使用示例
这里先以简单的用户态驱动为例,在设备透传小节中,在分析如何利用vfio实现透传。
1 int container, group, device, i; 2 struct vfio_group_status group_status = 3 { .argsz = sizeof(group_status) }; 4 struct vfio_iommu_type1_info iommu_info = { .argsz = sizeof(iommu_info) }; 5 struct vfio_iommu_type1_dma_map dma_map = { .argsz = sizeof(dma_map) }; 6 struct vfio_device_info device_info = { .argsz = sizeof(device_info) }; 7 8 /* Create a new container */ 9 container = open("/dev/vfio/vfio", O_RDWR); 10 11 if (ioctl(container, VFIO_GET_API_VERSION) != VFIO_API_VERSION) 12 /* Unknown API version */ 13 14 if (!ioctl(container, VFIO_CHECK_EXTENSION, VFIO_TYPE1_IOMMU)) 15 /* Doesn't support the IOMMU driver we want. */ 16 17 /* Open the group */ 18 group = open("/dev/vfio/26", O_RDWR); 19 20 /* Test the group is viable and available */ 21 ioctl(group, VFIO_GROUP_GET_STATUS, &group_status); 22 23 if (!(group_status.flags & VFIO_GROUP_FLAGS_VIABLE)) 24 /* Group is not viable (ie, not all devices bound for vfio) */ 25 26 /* Add the group to the container */ 27 ioctl(group, VFIO_GROUP_SET_CONTAINER, &container); 28 29 /* Enable the IOMMU model we want */ // type 1 open | attatch 30 ioctl(container, VFIO_SET_IOMMU, VFIO_TYPE1_IOMMU); 31 32 /* Get addition IOMMU info */ 33 ioctl(container, VFIO_IOMMU_GET_INFO, &iommu_info); 34 35 /* Allocate some space and setup a DMA mapping */ 36 dma_map.vaddr = mmap(0, 1024 * 1024, PROT_READ | PROT_WRITE, 37 MAP_PRIVATE | MAP_ANONYMOUS, 0, 0);//这里的0是什么意思?不一般是文件描述符吗 fd=open(...)?? 38 dma_map.size = 1024 * 1024; 39 dma_map.iova = 0; /* 1MB starting at 0x0 from device view */ 40 dma_map.flags = VFIO_DMA_MAP_FLAG_READ | VFIO_DMA_MAP_FLAG_WRITE; 41 42 ioctl(container, VFIO_IOMMU_MAP_DMA, &dma_map);//把iova地址转换到vaddr对应的物理地址?? 43 44 /* Get a file descriptor for the device */ 45 device = ioctl(group, VFIO_GROUP_GET_DEVICE_FD, "0000:06:0d.0"); 46 47 /* Test and setup the device */ 48 ioctl(device, VFIO_DEVICE_GET_INFO, &device_info);
对于dev下Group就是按照上一节介绍的Group划分规则产生的,上述代码描述了如何使用VFIO实现映射,对于Group和Container的相关操作这里不做过多解释,主要关注如何完成映射,下图解释具体工作流程。
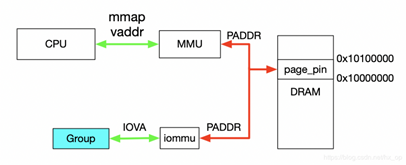
首先,利用mmap映射出1MB字节的虚拟空间,因为物理地址对于用户态不可见,只能通过虚拟地址访问物理空间。然后执行ioctl的VFIO_IOMMU_MAP_DMA命令,传入参数主要包含vaddr及iova,其中iova代表的是设备发起DMA请求时要访问的地址,也就是IOMMU映射前的地址,vaddr就是mmap的地址。VFIO_IOMMU_MAP_DMA命令会为虚拟地址vaddr找到物理页并pin住(因为设备DMA是异步的,随时可能发生,物理页面不能交换出去),然后找到Group对应的Contex Entry,建立页表项,页表项能够将iova地址映射成上面pin住的物理页对应的物理地址上去,这样对用户态程序完全屏蔽了物理地址,实现了用户空间驱动。IOVA地址的00x100000对应DRAM地址0x100000000x10100000,size为1024 * 1024。一句话概述,VFIO_IOMMU_MAP_DMA这个命令就是将iova通过IOMMU映射到vaddr对应的物理地址上去。
3.设备透传分析
设备透传就是由虚机直接接管设备,虚机可以直接访问MMIO空间,VMM配置好IOMMU之后,设备DMA读写请求也无需VMM借入,需要注意的是设备的配置空间没有透传,因为VMM已经配置好了BAR空间,如果将这部分空间也透传给虚机,虚机会对BAR空间再次配置,会导致设备无法正常工作。
3.1 虚机地址映射
在介绍透传之前,先看下虚机的GPA与HVA和HPA的关系,以及虚机是如何访问到真实的物理地址的,过程如下图。
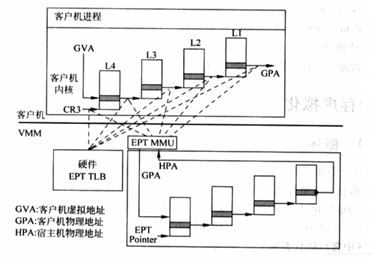
一旦页表建立好后,整个映射过程都是硬件自动完成的,对于上图有如下几点说明:
- 对于虚机内的页表,完成GVA到GPA的映射,虽然整个过程都是硬件自动完成,但有一点要注意下,在虚机的中各级页表也是存储在HPA中的,而CR3及各级页表中装的地址都是GPA,所以在访问页表时也需要借助EPT(extension page table?),上图中以虚线表示这个过程
- 利用虚机页表完成GVA到GPA的映射后,此时借助EPT实现GPA到HPA的映射,这里没有什么特殊的,就是一层层页表映射
- 看完上图,有没有发现少了点啥,是不是没有HVA。单从上图整个虚机寻址的映射过程来看,是不需要HVA借助的,硬件会自动完成GVA->GPA->HPA映射,那么HVA有什么用呢?这里从下面两方面来分析:
1)Qemu利用iotcl控制KVM实现EPT的映射,映射的过程中必然要申请物理页面。Qemu是应用程序,唯一可见的只是HVA,这时候又需要借助mmap了,Qemu会根据虚机的ram大小,即GPA大小范围,然后mmap出与之对应的大小,即HVA。通过KVM_SET_USER_MEMORY_REGION命令控制KVM,与这个命令一起传入的参数主要包括两个值,guest_phys_addr代表虚机GPA地址起始,userspace_addr代表上面mmap得到的首地址(HVA)。传入进去后,KVM就会为当前虚机GPA建立EPT映射表实现GPA->HPA,同时会为VMM建立HVA->HPA映射。
2)当vm_exit发生时,VMM需要对异常进行处理,异常发生时VMM能够获取到GPA,有时VMM需要访问虚机GPA对应的HPA,VMM的映射和虚机的映射方式不同,是通过VMM完成HVA->HPA,且只能通过HVA才能访问HPA,这就需要VMM将GPA及HVA的对应关系维护起来,这个关系是Qemu维护的,这里先不管Qemu的具体实现(后面会有专门文档介绍),当前只需要知道给定一个虚机的GPA,虚机就能获取到GPA对应的HVA。下图描述VMM与VM的地址映射关系。

3.2 设备透传实现
在前面介绍VFIO的使用实例时,核心思想就是IOVA经过IOMMU映射出的物理地址与HVA经过MMU映射出的物理地址是同一个。对于设备透传的情况,先上图,然后看图说话。
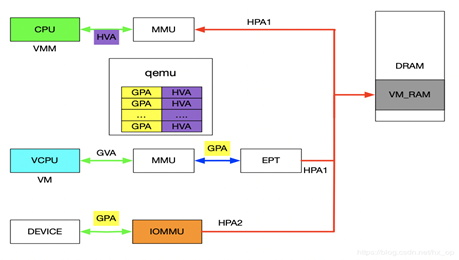
先来分析一下设备的DMA透传的工作流程,一旦设备透传给了虚机,虚机在配置设备DMA时直接使用GPA。此时GPA经由EPT会映射成HPA1,GPA经由IOMMU映射的地址为HPA2,此时的HPA1和HPA2必须相等,设备的透传才有意义。下面介绍在配置IOMMU时如何保证HPA1和HPA2相等,在VFIO章节讲到了VFIO_IOMMU_MAP_DMA这个命令就是将iova通过IOMMU映射到vaddr对应的物理地址上去。对于IOMMU来讲,此时的GPA就是iova,我们知道GPA经由EPT会映射为HPA1,对于VMM来讲,这个HPA1对应的虚机地址为HVA,那样的话在传入VFIO_IOMMU_MAP_DMA命令时讲hva作为vaddr,IOMMU就会将GPA映射为HVA对应的物理地址及HPA1,即HPA1和HPA2相等。上述流程帮助理清整个映射关系,实际映射IOMMU的操作很简单,前面提到了qemu维护了GPA和HVA的关系,在映射IOMMU的时候也可以派上用场。注:IOMMU的映射在虚机启动时就已经建立好了,映射要涵盖整个GPA地址范围,同时虚机的HPA对应的物理页都不会交换出去(设备DMA交换是异步的)。
本文链接http://element-ui.cn/news/show-44900.aspx