对于分布式来说最重要的莫过于所有副本数据的一致性。
在monitor节点中,存在着Leader和Peon两种角色。当客户端发出读命令时可以由相应的Peon或者Leader返回。一旦发生修改动作,所有的消息会第一时间发送给Leader节点,然后由Leader节点分发给Peon节点。
paxos算法保证了一次修改操作只能批准一个值,从而保证了分布式系统副本的一致性。
多个节点之间存在两种通讯模型:共享内存(Shared memory)、消息传递(Messages passing),Paxos是基于消息传递的通讯模型的。
paxos转换时机:
1.monitor启动时,paxos初始化;
2.monitor进入bootstrap时,paxos的restart ;
3.monitor根据选举结果,paxos对应初始化为leader或peon;
4.monitor异常后,paxos recovery阶段;
5.monitor运行过程中,paxos决议;
概念说明
1.1 Epoch
每次选举产生新的leader,也会产生新的epoch。不选举则不会修改epoch。 一个leader当选期间,发送的所有消息,都会带有这个epoch。 如果由于网络分割等现象,有新的选举发生,则根据epoch就发现leader已经变了。 注意,按照paxos论文描述,没有Leader也是可以正常运行的,只是可能降低效率。 没有leader则不需要epoch
1.2 PN(Proposal Number)
Leader当选后,会首先执行一次phase 1过程,以确定PN。 在其为leader期间, 所有的phase 2操作都共用一个PN。所以省略了大量的phase 1操作,这也是 paxos能够减小网络开销的原因。 “Paxos made simple”文中说:
“A newly chosen leader executes phase 1 for infinitely many instances of the consensus algorithm”。
PN是必须的,无论是否有leader,都必须有PN
1.3Version
可以理解成Paxos的instance ID,或者raft的logID
1.4持久化
对比raft,虽然ceph的复制也可以看成一个个log的追加,但是所有信息都写在k/v中,而不是写log文件,比如instanceID为X的log,在k/v存储中,其key是X,value是log的内容。其他各种需要持久化的值,都写在k/v存储中。
1.5其他需要持久化的数据结构
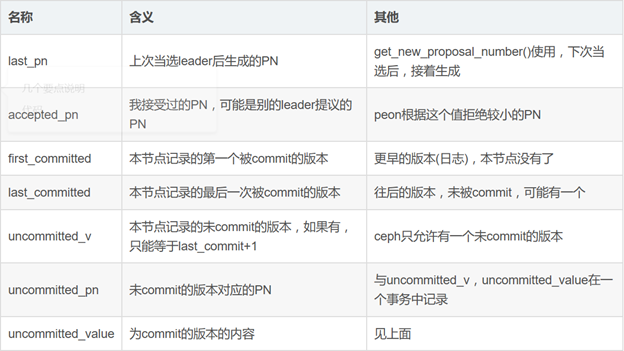
上述三个“uncommitted”开头的值,可能压根就不存在,比如正常关机,全部都commit了。
uncommitted_value:
* If the system fails in-between the accept replies from the Peons and the
* instruction to commit from the Leader, then we may end up with accepted
* but yet-uncommitted values. During the Leader's recovery, it will attempt
* to bring the whole system to the latest state, and that means committing
* past accepted but uncommitted values.
*
* This variable will hold an uncommitted value, which may originate either
* on the Leader, or learnt by the Leader from a Peon during the collect
* phase.
1.6 Ceph的Paxos存在如下几个状态:
1) Recovery状态:Leader选举结束后进入该状态。该状态的目的是同步Quorum成员间的状态;
2) Active状态:即空闲状态,没有执行Paxos算法审批提案;
3) Updating状态:正在执行Paxos算法审批提案;
4) Updating Previous状态:正在执行Paxos算法审批旧提案,旧提案即Leader选举之前旧Leader提出但尚未批准的提案。
流程
phase1 交互过程
paxos的recovery过程
Phase1,目的是就PN达成一致,包括三个步骤,如下:
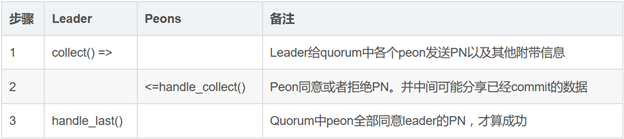
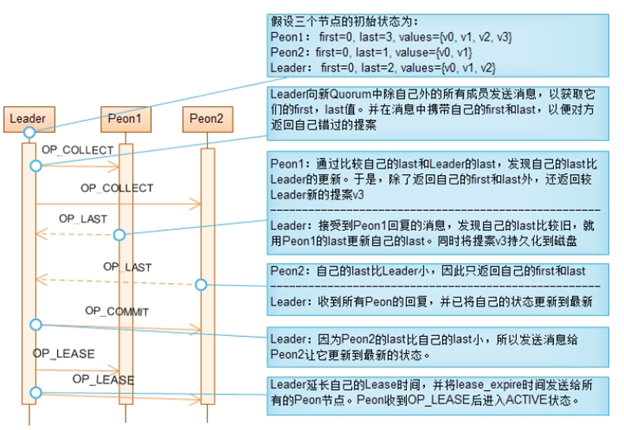
在Leader选举成功后,Leader和Peon都进入Recovery阶段。该阶段的目的是为了保证新Quorum的所有成员状态一致,这些状态包括:最后一个批准(Committed)的提案,最后一个没批准的提案,最后一个接受(Acceppted)的提案。每个节点的这些状态都持久化到磁盘。对旧Quorum的所有成员来说,最后一个通过的提案应该都是相同的,但对不属于旧Quorum的成员来说,它的最后一个通过的提案是落后的。
同步已批准提案的方法是,Leader先向新Quorum的所有Peon节点发送OP_COLLECT消息,并在消息中携带Leader自己的第1个和最后1个批准的提案的值的版本号。Peon收到OP_COLLECT消息后,将自己的第1个和最后1个批准的提案的值的版本号返回给Leader,并且如果Peon的最后1个批准的版本号大于Leader最后一个批准的版本号时,将所有在大于Leader最后一个版本号的提案值发送给Leader。Leader将根据这些信息填补自己错过的提案。这样,当Leader接收到所有Peon对OP_COLLECT消息的回应后,也就将自己更新到了最新的状态。这时Leader又反过来将最新状态同步到其它节点。
为获取新Quorum所有成员中的最大提案号,Leader在发送OP_COLLECT消息时,提出它知道的最大的提案号,并将该提案号附加在OP_COLLECT消息中。如果Peon已接受的最大提案号大于Leader提出的提案号,则拒绝接受Leader提出的提案号并将自己已接受的最大提案号通过OP_LAST消息发送给Leader。Leader收到OP_LAST消息后,发现自己的提案号不是最大时,就在Peon接受的最大提案号的基础上提出更大的提案号,重新进入Recovery阶段。这样,最终可以获取到最大的提案号。
总而言之,Recovery阶段的目的是让新Quorum中所有节点处于一致状态。实现这一目的的方法分成两步:首先,在Leader节点收集所有节点的状态,通过比较得到最新状态;然后,Leader将最新状态同步给其它节点。有两个比较重要的状态,最后一次批准的提案和已接受的最大提案号。
注意 区分提案号(proposal number)、提案值(value)、提案值的版本号(value version)这三个概念。提案号由Leader提出,为避免不同Leader提出的提案号不冲突,同个Leader提出的提案号是不连续的。提案的值的版本号是连续的。
|
函数 void Paxos::leader_init()
void Paxos::peon_init() void Paxos::collect(version_t oldpn) void Paxos::handle_collect(MMonPaxos *collect) void Paxos::handle_last(MMonPaxos *last) void Paxos::handle_commit(MMonPaxos *commit)
Paxos属性 uncommitted_v、uncommitted_pn、uncommitted_value last_committed、accepted_pn
配置 OPTION(mon_lease, OPT_FLOAT, 5) // Lease租期 |
Phase2
paxos的propose过程
Phase 2,即正常工作过程中的Propose、accept和commit过程。

从begin()到commit_finish()称为一轮,即一次提议的完成过程。
串行化提议:
Ceph的paxos实现,每次只允许一个提议在执行中,即上面提到 的一轮完成才能执行下一轮。在这个过程中,会有多次写盘操作。
这个过程实际上比较慢。对于ceph自身来说,osd等的状态变更, 不频繁,无需极高的paxos性能。 但是如果用于做用于分布式数据
库等系统的日志,这种方式则有不足。
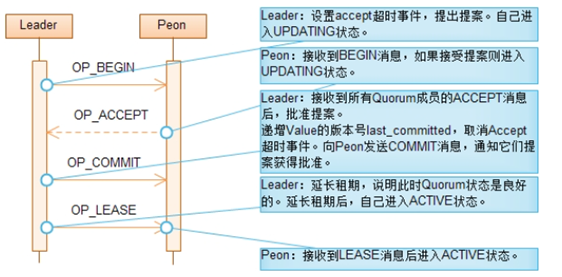
Lease阶段
Paxos算法分成两个阶段,第一个阶段为Prepare阶段。在这阶段中,(a)Proposer选择它知道的最大提案号n,并向所有Acceptor发送Prepare消息。(b)Acceptor承诺不再接受编号小于n的提案,(c)并返回它接受的编号小于n的提案中编号最大的提案给Proposer。这个过程中,如果Proposer选择的不是最大的提案号,那么Acceptor将拒绝Proposer的提案,而Proposer遭到拒绝后会提出编号更大的提案。这样循环反复,Proposer最终可以提出编号最大的提案。另外,Acceptor返回接受的编号小于n的提案中编号最大的提案给Proposer的目的是为让Proposer决定新提出的提案的值。对Ceph而言,由于Leader可以控制提案的进度,运行一次Paxos算法只有一个提案在审批,每次算法Leader都能够由自己决定提案的值,所以Peon不必返回接受的编号小于n的提案中编号最大的提案。
Ceph中Paxos算法的实现,省略了Prepare阶段,并且Leader选举成功后每次执行算法使用同一个提案号。在Prepare阶段要完成(a)、(b)和(c)三件事,前两件事在Recovery阶段完成,Leader和Peon的已接受的最大提案号保持相同。最后一件事情,由于Leader的存在不需要做。
Paxos算法的第二阶段为Accept阶段。在这个阶段中,(d)Proposer根据在Prepare阶段中学习到的知识提出提案。(e)Acceptor根据接受到的提案的提案号决定拒绝还是接受。最后,(f)Proposer根据反馈情况决定提案是否得到批准。对Ceph来说,每次算法只有一个提案所以可以直接决定提案的值,因此不必关心(d)。对(e)和(f)的实现和标准Paxos算法保持一致。
propose的触发条件:
a.ConfigKeyService服务在修改或删除key/value值;
b.Paxos以及PaxosService对数据做trim;
c.PaxosService的各种服务,更新map;
在此仅以PaxosService更新map为例:客户端发来修改请求到底是个什么过程呢?
其他需要monitor协作的模块构建与mon通讯的对象,然后发送消息给mon: monc->send_mon_message(m);
|
monitor收到消息后,进入Monitor::handle_forward() extract the original message and put it into the regular dispatch function

具体代码过程
Phase1 recovery阶段
Paxos::collect() leader发起collect
{1
state = STATE_RECOVERING;
清空一些值:
|
uncommitted_v uncimmitted_pn uncommitted_value peer_first_committed peer_last_committed |
若DBStore中存在pending的proposal,那么其version一定为last_committed+1;
|
uncommitted_pn=pending pn; uncommitted_v=last_committed+1; 找到uncommitted_v对应的uncommitted_value; |
否则uncommitted_pn=accepted_pn;
生成新的pn,自己先accept:accepted_pn=get_new_proposal_numble();
{2
每个monitor有自己的rank,把rank作为自己产生的PN的低位数,则各自不同;
比如,rank=5的,产生的只可能是105, 205, 305等,即n*100 +5;
update. make it unique among all monitors;
第n次选举后产生的pn值为100*n+rank(leader);
持久化到DBStore中;
2}
给quorum中的成员发送 OP_COLLECT消息,包含last_committed,first_committed,accepted_pn;
设置超时处理 collect_timeout();
1}
Paxos::handle_collect() peon 收到OP_COLLECT消息后
{1
state = STATE_RECOVERING;
reset_lease_timeout();设置 last超时,超时重新选举;
若我的最新的版本+1 比leader的第一个版本还旧,重新bootstrap();
若我之前接受的PN小于发送者的PN,则同意,accept_pn=接收的PN;
如果对方的last_committed比我的小,把自己已经commit的分享给它share_state();
{2
这里面并没有进行消息传递,只是把两个版本之间的内容给打包进了msg,随着msg的其他内容一起发送;
2}
若存在pending_v=last_committed+1这个版本即pending的proposal,那么要把 uncommitted_pn和pending_v对应的value都放到OP_LAST消息中告诉leader;
1}
Paxos::handle_last() leader收到OP_LAST后
{1
自己比peon的first_committed落后很多,重新bootstrap();
调用store_state()处理对方的share_state分享的已经commit的数据;
{2
???
2}
若对方版本太旧,没法同步,那么重新bootstrap();
若对方比我旧但在可同步范围,发送OP_COMMIT消息,share_state()分享已经commit的数据;
若peon接受过的PN比自己的accepted_pn大,那么提高PN值,重新collect();
若peon接受了自己的PN,记录下peon同时发送的uncommitted_pn, value,v;
若quorum中所有都接受自己的PN,(num_last == mon->get_quorum().size()),
若存在未commit的value(uncommitted_value),(uncommitted_v == last_committed+1)则state = STATE_UPDATING_PREVIOUS,开始propose过程:begin(uncommitted_value);
【STATE_UPDATING_PREVIOUS是对应刚当选后,发现有uncommitted_value,并且是下一个版本(last_committed+1)】
{3
3}
正常情况下extend_lease() leader 延长自己的lease时间,并将lease_expire时间发送给所有peon;
{4
发送OP_LEASE信息(last_committed,first_committed,lease_expire)
4}
do_refresh() 一个paxos过程结束后,需要让上层的各个service(monitor)刷新状态;
{5
5}
finish_round() 已经完成一轮的提议,状态设置为STATE_ACTIVE,清理过量日志
{6
state = STATE_ACTIVE;//不是active是不会去propose的;
清理过量日志 trim();
propose_pending(); //表决下一个等待提案,并将状态置为updating;
6)
1}
Paxos::handle_commit() peon 收到OP_COMMIT后
{1
//将修改写入后端存储
store_state(commit);
//刷新PaxosService服务
(void)do_refresh();
1}
Paxos::handle_lease() peon 收到OP_LEASE后
{1
warn_on_future_time()检查OP_LEASE消息的时间戳和当前时间差,判断是否超出允许的mon_clock_drift_allowed;
更新自己的lease_expire;
设置状态为STATE_ACTIVE;
发送OP_LEASE_ACK消息(last_committed,first_committed,ceph_clock_now(),feature_map?);
1}
Paxos::handle_lease_ack() leader 收到OP_LEASE_ACK后
{1
处理feature_map;
等quorum中所有都回复后,timer.cancel_event(lease_ack_timeout_event);
warn_on_future_time();
1}
Paxos::lease_ack_timeout() 若lease timeout了
{1
mon->bootstrap();
1}
Phase2 propose阶段
数据概览
首先我们分析的版本是0.94.7的版本,也就是目前Hammer最新的版本。对于leveldb中的数据,我们需要来一个感性的认识,请看下面数据,由于数据太多这里仅仅列出了key:

可以看到这里有paxos,有monmap,osdmap,mdsmap,auth,logm,和上一篇(Ceph Monitor基础架构与模块详解)中的Monitor的架构图很像。paxos记录了每次propose的value,具体可以这么来看:

以paxos:1869为例,paxos为prefix,1869为key。可以将不同的prefix当做不同的表,里面的key是主键,其存储的值是value,这里paxos:1869存储的就是Monitor一致同意的1869次决议。所有的状态的变化都是从这个决议里产生的。
那我们有什么方式可以查看决议的内容呢?我们可以通过如下命令先将数据从leveldb中导出来:

然后使用ceph-dencoder工具来查看:
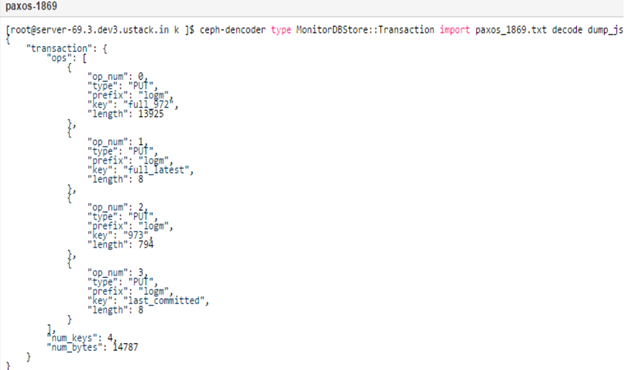
从上面的数据输出我们可以得出一下几点:
- paxos:1869存储的是MonitorDBStore::Transaction序列化后的数据
- Monitor的Transaction和Osd的Transaction类似,都封装了多个op的操作
- log通过paxos来保持一致性,所以这里有,同理osdmap,monmap,pgmap等都应该Transaction里
- 这里仅仅是paxos决议的值,但是上面有osdmap的key,那么osdmap:num的val应该也是和paxos里相应的内容一样
- Paxos应该有Trim机制,因为如果数据一致这么存下去,不是办法
Paxos更新一个值的流程
1、Leader
1)设置new_value =v,v中值就是我们上面看到的paxos:1869中的值,都是kv。
2)将自己加入到同意者集合。
3)生成MonitorDBStore::Transaction, 以paxos为前缀,last_commited+1 的key来将v写入到leveldb中,同时更新pending_v,和pending_pn。
4)将new_value, last_commited和accepted_pn发送给quorum中的所有成员。
2、Peon
1)判断自己的accepted_pn和Leader发送过来的accepted_pn是否相等,如果小于就忽略,认为是旧一轮的决议。
2)判断自己last_commited是否和leader发送过来的相关,如果不相关,就是出现了不一致,直接assert。
3)同Leader中的3)。
4)将accpted_pn 和 last_commited发送给Leader。
3、Leader
1)判断Peon发送过来的pn是不是和自己的accepted_pn一致,如果不等可能有则返回。
2)判断last_commited,如果Peon发送过来的last_commited比last_commted -1 小,则认为是旧一轮的消息,丢弃。
3)判断Peon是否在同意者结合,如果不在就加入,如果在,说明一个Peon发送了两次accept消息,Leader直接assert。
4)当接受者结合和quorum结合一样的时候,也就是大多数人都同意了,Leader提交决议。
5)更新leveldb中的last_commited为last_commited + 1。
6)将new_value中的数据都展开封装成transaction,然后写入,插入回调。
7)当Leader完成本地的提交之后,调用回调向quorum中的所有成员发送commit消息 。
4、Peon
1)在接收到commit消息之后,进行内部提交。
这里有几点需要说明的是:
在决议的过程中其实提交了Leader提交了两次,一次是直接将决议当做bl写入paxos的prefix中,另一次是将bl解析出来(bl里的内容都是封装的小的op操作)在写入bl里封装的prefix的库中。
所有的update操作的请求都会路由到Leader,也就是说无论你有3个,或者5个,在处理update请求的时候只会是1个。
OSDMap的管理
这里我们以OSDMap为例,来看看它是如何从生成到进库的。
当有osd up或者down的时候,monitor会感知到。当消息走到prepare_update的时候,会在各自的prepare函数经过各种处理,最终会将更新纪录到pending_inc中。因为OSDMap的更新全纪录在pending_inc这个变量里。然后在dispatch中,会判断是不是要走决议流程,如果走了决议流程之后会首先将pending_inc中的内容encode进transaction,这里调用了一个很重要的函数encode_pending。在这个函数里将pending_inc中该有的内容都塞进了transaction。当有了这个transaction之后,就是会走我们上面讲的Paxos决议流程了。最终这些决议会持久化到leveldb中。
从上面我们可以看到Monitor的架构,这里虽然讲的是OSDMonitor怎么处理消息的,但是MDSMonitor,MonMapMonitor都是一样的。Update操作改变自己的pending_inc,然后在encode_pending的时候生成transaction,然后就是走决议流程。
同样可以通过以下命令将osdmap拿出来看看:
