MySql性能优化学习笔记
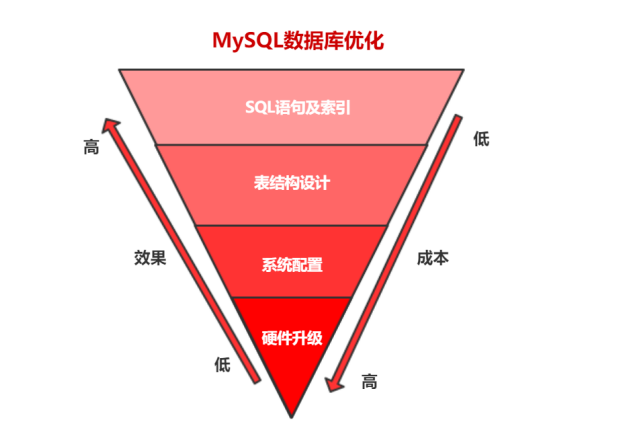
数据库优化维度有四个:
硬件升级、系统配置、表结构设计、sql语句及索引。
一、系统配置优化
1.1 保证从内存中读取数据
MySQL会在内存中保存一定的数据,通过LRU算法将不常访问的数据保存在硬盘中。所以优化方向是尽可能扩大内存中的数据量,将数据保存在内存中,可以提升Mysql性能。通过扩大innode_buffer_pool_size,能够最大限度降低磁盘操作。
通过show global status like 'innode_buffer_pool_pages_%';查看innode_buffer_pool_size大小。以docker的mysql8.0.18为例:
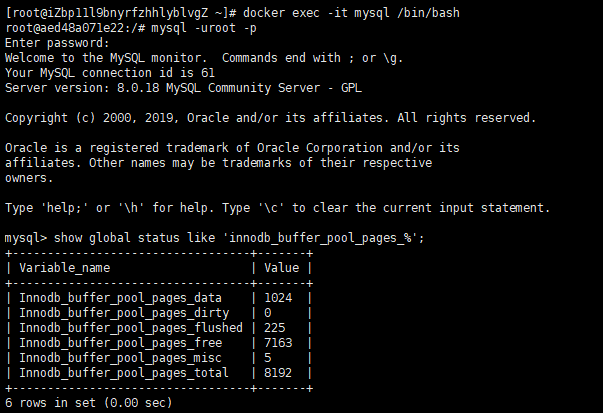
如果Innodb_buffer_pool_pages_free为0则表示已经用光。
innode_buffer_pool_size理论上可以扩大到内存的3/4或4/5
修改my.cnf
innode_buffer_pool_size = 750M进行修改
1.2 数据预热
默认情况,仅仅有某条数据被读取一次,才会缓存在 innodb_buffer_pool。所以,数据库刚刚启动,须要进行数据预热,将磁盘上的全部数据缓存到内存中。数据预热能够提高读取速度。
mysql数据预热脚本
SELECT DISTINCT
CONCAT('SELECT ',rowlist,' FROM ',db,'.',tb,
' ORDER BY ',rowlist,';') selectSql
FROM
(
SELECT
engine,table_schema db,table_name tb,
index_name,GROUP_CONCAT(column_name ORDER BY seq_in_index) rowlist
FROM
(
SELECT
B.engine,A.table_schema,A.table_name,
A.index_name,A.column_name,A.seq_in_index
FROM
information_schema.statistics A INNER JOIN
(
SELECT engine,table_schema,table_name
FROM information_schema.tables WHERE
engine='InnoDB'
) B USING (table_schema,table_name)
WHERE B.table_schema NOT IN ('information_schema','mysql')
ORDER BY table_schema,table_name,index_name,seq_in_index
) A
GROUP BY table_schema,table_name,index_name
) AA
ORDER BY db,tb;
可以将脚本保存为xxx.sql
执行命令
mysql -urrot -p -AN < /rooot/xxx.sql > /root/xxx.sql
二、表结构设计优化
-
设计中间表
设计中间表,一般针对于统计分析功能或者实时性不高的需求
-
设计冗余字段
为减少关联查询,创建合理的冗余字段(需注意数据一致性的问题)
-
拆表
对于字段太多的大表,如有100多个字段
对于表中经常不被使用的字段或者存储数据比较多的字段
-
主键优化
每张表建议一个主键(主键索引),而且最好是int类型,建议自增主键。分布式系统可以雪花算法。
-
字段的设计
数据库中的表越小,查询的速度越快,因此在创建表的时候,为了更好的性能,可以将表中的字段的宽度设的尽可能小。尽量把字段设计为NOTNULL,这样在执行查询时,数据库不用去比较Null值。
三、sql语句及索引优化
3.1 EXPLAIN执行计划
在日常工作中,我们会有时会开慢查询去记录一些执行时间比较久的SQL语句,找出这些SQL语句并不意味着完事了,些时我们常常用到explain这个命令来查看一个这些SQL语句的执行计划,查看该SQL语句有没有使用上了索引,有没有做全表扫描,这都可以通过explain命令来查看。所以我们深入了解MySQL的基于开销的优化器,还可以获得很多可能被优化器考虑到的访问策略的细节,以及当运行SQL语句时哪种策略预计会被优化器采用。
如explain selcct * from tb_test的执行结果

Explain 执行计划包含字段信息如下:分别是 id、select_type、table、partitions、type、possible_keys、key、key_len、ref、rows、filtered、Extra 12个字段
id
SELECT识别符,表示查询中执行select子句或者操作表的顺序,id的值越大,代表优先级越高,越先执行。
- id相同时,执行顺序由上至下
- 子查询中id越大优先级越高,越先被执行
- 在所有组中,id值越大,优先级越高,越先执行
select_type
表示select子句的类型
- SIMPLE
- 表示最简单的select查询,不包含子查询或union
- PRIMARY
- 子查询中最外层查询,查询中若包含任何复杂的子部分,最外层的select被标记为PRIMARY)
- UNION
- UNION中的第二个或后面的SELECT语句
- SUBQUERY
- 当 select 或 where 列表中包含了子查询,该子查询被标记为:SUBQUERY
- DERIVED
- 派生表的SELECT, FROM子句的子查询,在 from 列表中包含的子查询会被标记为derived
- UNION RESULT
- UNION的结果,union语句中第二个select开始后面所有select
- DEPENDENT SUBQUERY
- 子查询中的第一个SELECT,依赖于外部查询
table
查询的表名,并不一定是真实存在的表,有别名显示别名,也可能为临时表
type
对表访问方式,表示MySQL在表中找到所需行的方式,又称“访问类型”。常用的类型有: system > const > eq_ref > ref > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL(从左到右,性能从好到坏)一个好的sql语句最好达到range级别,杜绝出现all级别。
- system
- 当表仅有一行记录时(系统表),数据量很少,往往不需要进行磁盘IO,速度非常快
- const
- 表示查询时索引命中 primary key 主键或者 unique 唯一索引,或者被连接的部分是一个常量(const)值。这类扫描效率极高,返回数据量少,速度非常快
- eq_ref
- 查询时命中主键primary key 或者 unique key索引, type 就是 eq_ref
- ref
- 表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值,区别于eq_ref ,ref表示使用非唯一性索引,会找到很多个符合条件的行
- ref_or_null
- 这种连接类型类似于 ref,区别在于 MySQL会额外搜索包含NULL值的行
- index_merge
- index_merge:使用了索引合并优化方法,查询使用了两个以上的索引
- range
- 使用索引选择行,仅检索给定范围内的行。简单点说就是针对一个有索引的字段,给定范围检索数据。在where语句中使用 bettween...and、<、>、<=、in 等条件查询 type 都是 range
- index
- Index 与ALL 其实都是读全表,区别在于index是遍历索引树读取,而ALL是从硬盘中读取
- all
- 将遍历全表以找到匹配的行,性能最差
possible_keys
指出MySQL能使用哪个索引在表中找到记录,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用(该查询可以利用的索引,如果没有任何索引显示 null)
该列完全独立于EXPLAIN输出所示的表的次序。这意味着在possible_keys中的某些键实际上不能按生成的表次序使用。
如果该列是NULL,则没有相关的索引。在这种情况下,可以通过检查WHERE子句看是否它引用某些列或适合索引的列来提高你的查询性能。如果是这样,创造一个适当的索引并且再次用EXPLAIN检查查询
key
key列显示MySQL实际决定使用的键(索引),必然包含在possible_keys中
key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度(key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的),不损失精确性的情况下,长度越短越好。
ref
常见的有:const,func,null,字段名。
当使用常量等值查询,显示const,当关联查询时,会显示相应关联表的关联字段。如果查询条件使用了表达式、函数,或者条件列发生内部隐式转换,可能显示为func,其他情况null
rows
以表的统计信息和索引使用情况,估算要找到我们所需的记录,需要读取的行数。
这是评估SQL 性能的一个比较重要的数据,mysql需要扫描的行数,很直观的显示 SQL 性能的好坏,一般情况下 rows 值越小越好。
explain
不适合在其他列中显示的信息,Explain 中的很多额外的信息会在 Extra 字段显示
3.2 使用explain查询索引使用情况
创建一个表:
CREATE TABLE tbiguser (
id INT PRIMARY KEY auto_increment,
nickname VARCHAR ( 255 ),
loginname VARCHAR ( 255 ),
age INT,
sex CHAR ( 1 ),
STATUS INT,
address VARCHAR ( 255 )
);
创建函数插入一千万条左右数据
CREATE PROCEDURE test_insert () BEGIN
DECLARE
i INT DEFAULT 1;
WHILE
i <= 10000000 DO
INSERT INTO tbiguser
VALUES
( NULL, concat( 'zy', i ), concat( 'zhaoyun', i ), 23, '1', 1, 'beijing' );
SET i = i + 1;
END WHILE;
COMMIT;
END;
查询数量
SELECT COUNT(*) FROM tbiguser
结果:10000000
使用explain查看索引使用情况
SELECT * FROM tbiguser WHERE nickname = 'zy2因为数据量很大所以这条sql语句将会很慢,(在我的机器上跑需要3.007s,可以根据自己机器配置自行修改数据数量)
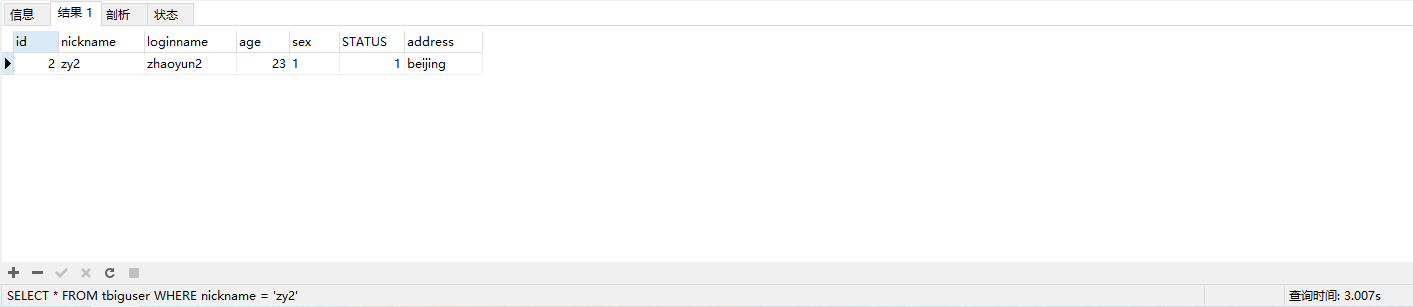
这时我们通过explain查询这条sql的执行计划
EXPLAIN SELECT * FROM tbiguser WHERE nickname = 'zy2'
可以看到:

这时type=all是用全表扫描的,然后我们给nickname加上普通索引
再次查询,可以看到优化效果还是十分明显的
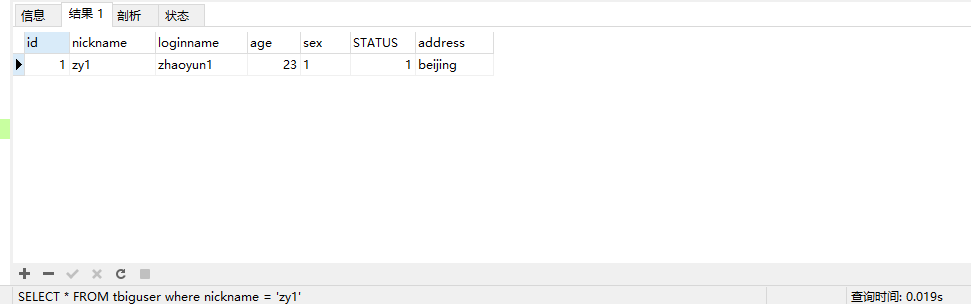
我们再看explain计划:

可以看到查询级别优化到了ref
如果我们再加入一个查询条件,如下图:
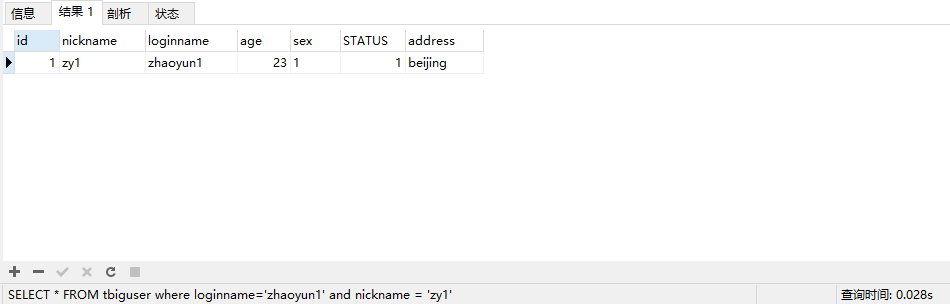
mysql会自动先查询索引进行优化,所以查询速度依旧不慢,下图为explain

常见增加索引的地方:
-
where字段可以加索引
-
组合索引
两个或更多个列上的索引,对于复合索引,Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。例如索引是key index (a,b,c). 可以支持a | a,b| a,b,c 3种组合进行查找,但不支持 b,c进行查找 .当最左侧字段是常量引用时,索引就十分有效。复合索引的结构与电话簿类似,人名由姓和名构成,电话簿首先按姓氏对进行排序,然后按名字对有相同姓氏的人进行排序。
-
索引下推
Extra的值为Using index condition,表示已经使用了索引下推。索引下推简称ICP,在Mysql5.6的版本上推出,用于优化查询。在使用ICP的情况下,如果存在某些被索引的列的判断条件时,MySQL服务器将这一部分判断条件传递给存储引擎,然后由存储引擎通过判断索引是否符合MySQL服务器传递的条件,只有当索引符合条件时才会将数据检索出来返回给MySQL服务器。举个例子:
当我们创建一个用户表(userinfo),其中有字段:id,name,age,addr。我们将name,age建立联合索引,当我们执行:
select * from userinfo where name like "ming%" and age=20;如果不使用索引下推,则在索引内部首先通过name进行查找,在联合索引name,age树形查询结果可能存在多个,然后再拿着id值去回表查询,整个过程需要回表多次
我们是在索引内部就判断age是否等于20,对于不等于20跳过。因此在联合索引name,age索引树只匹配一个记录,此时拿着这个id去主键索引树种回表查询全部数据,整个过程就回一次表。
-
覆盖索引
MySQL官网,类似的说法出现在explain查询计划优化章节,即explain的输出结果Extra字段为Using index时,能够触发索引覆盖。即只需要在一棵索引树上就能获取SQL所需的所有列数据,无需回表,速度更快。
-
on两边
-
排序
-
分组统计
3.3 SQL语句中IN包含的值不应该过多
MySQL对于IN做了相应的优化,即将IN中的常量全部存储在一个数组里面,而且这个数组是排好序的。但是如果数值较多,产生的消耗也是比较大的.
3.4 select语句务必指明字段
SELECT * 增加很多不必要的消耗(CPU、IO、内存、网络带宽);减少了使用覆盖索引的可能性;当表结构发生改变时,前端也需要更新。所以要求直接在select后面接上字段名。
3.5 当只需要一条数据时,使用limit
limit可以停止全表扫描。
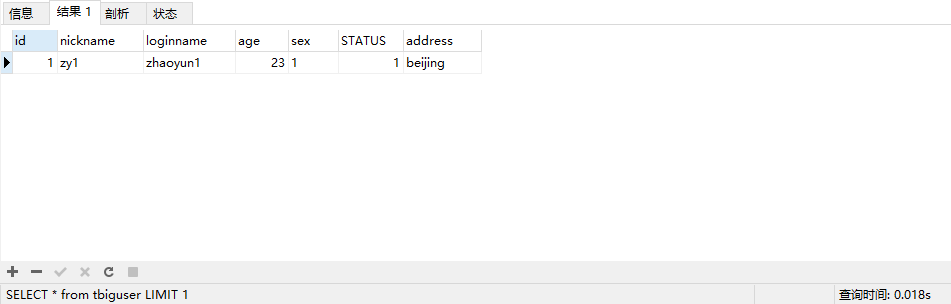
3.6 排序的字段需要加索引
排序的字段加不加索引以下面的两句sql语句为例:
EXPLAIN select * from tbiguser WHERE loginname ='zhaoyun999' ORDER BY id
EXPLAIN select * from tbiguser WHERE loginname ='zhaoyun999' ORDER BY loginname
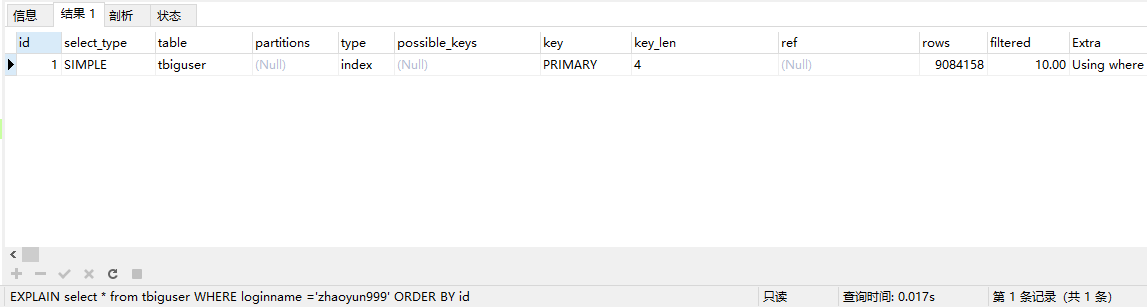
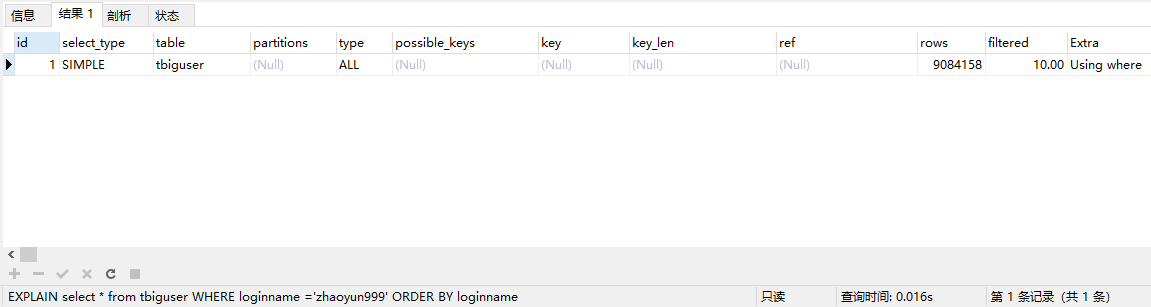
其中id有索引而loginname没有索引,所以两个语句的级别也会有差别
3.7 如果限制条件中其他字段没有索引,尽量少用or
比如下面nickname有索引但loginname没有索引,select * from tbiguser WHERE loginname ='zhaoyun999' or nickname = 'zy999'
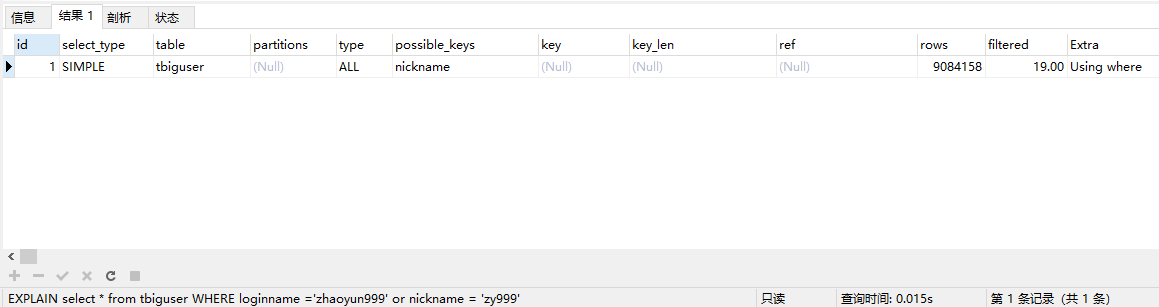
可以使用下面的语句保证一个索引的生效
select * from tbiguser WHERE loginname ='zhaoyun999' union all select * from tbiguser WHERE nickname = 'zy999'
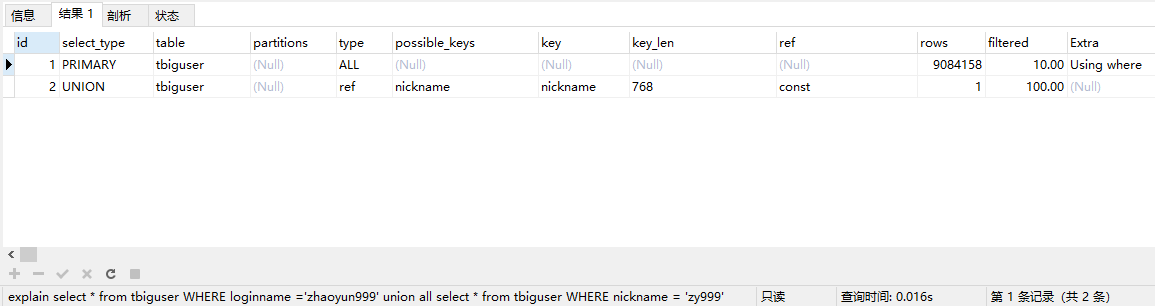
3.8 使用union all代替union
union和union all的差异主要是前者需要将结果集合并后再进行唯一性过滤操作,这就会涉及到排序,增加大量的CPU运算,加大资源消耗及延迟。当然,union all的前提条件是两个结果集没有重复数据。
3.9 区分in和exists
例:select * from t1 where id in (select id from t2);
上面的语句等同于
select * from t1 where exists(select * from t2 where t2.id=t1.id);
区分in和exists主要是造成了驱动顺序的改变(这是性能变化的关键),如果是exists,那么以外表为驱动表,先被访问,如果是in,那么先执行子查询。所以in适合于外表大而内表小的情况,exists相反。
3.10 limit分页优化
分页使用 limit m,n 尽量让m 小
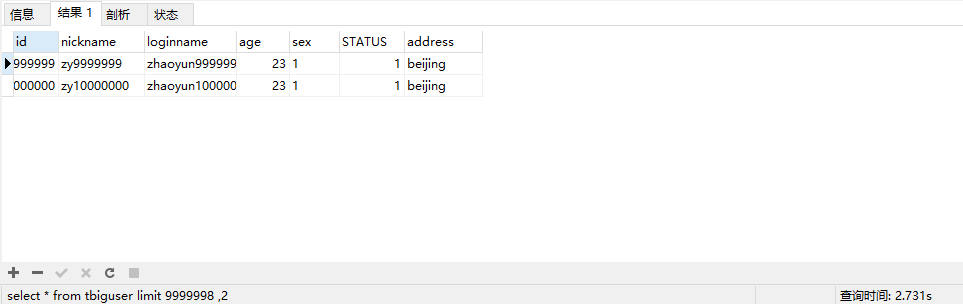
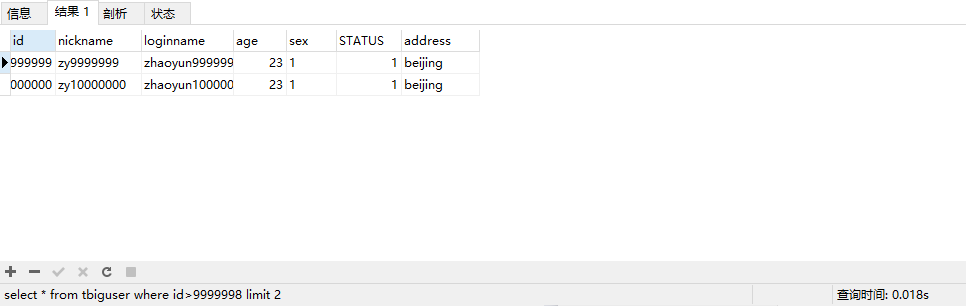
比如如下两个sql语句,可以取前一页的最大行数的id,然后根据这个最大的id来限制下一页的起点
select * from tbiguser limit 9999998 ,2
select * from tbiguser where id>9999998 limit 2
运行结果:
3.11 不建议使用%前缀模糊查询
例如LIKE“%name”或者LIKE“%name%”,这种查询会导致索引失效而进行全表扫描。但是可以使用LIKE“name%”。
3.12 避免在where子句中对字段进行表达式操作
例如:
select id,loginname from igtbuser where age*2=36;
可以修改为:
select id,loginname from igtbuser where age=36/2;
3.13 避免隐式类型转换
where子句中出现column字段的类型和传入的参数类型不一致的时候发生的类型转换,建议先确定where中的参数类型。
例如可以where age=18而不是where age='18'
3.14 join优化
LEFT JOIN A表为驱动表,INNER JOIN MySQL会自动找出那个数据少的表作用驱动表,RIGHT JOIN B表为驱动表。
1.mysql中没有 full join 所以可以使用以下sql语句
select * from A left join B on B.name =A.name where B.name is null union all select * from B
2.尽量使用inner join,避免left join:
参与联合查询的表至少为2张表,一般都存在大小之分。如果连接方式是inner join,在没有其他过滤条件的情况下MySQL会自动选择小表作为驱动表,但是left join在驱动表的选择上遵循的是左边驱动右边的原则,即left join左边的表名为驱动表。
3.利用小表去驱动大表
类似循环嵌套
for(int i=5;.......)
{
for(int j=1000;......)
{
}
}
如果小的循环在外层,对于数据库连接来说就只连接5次,进行5000次操作,如果1000在外,则需要进行1000次数据库连接,从而浪费资源,增加消耗。
四、索引优化实例
4.1 创建表
使用之前的tbiguser表,里面有一千万条数据
创建tbuser1和tbuser2两个表并增加一下重复数据
CREATE TABLE tuser1 ( id INT PRIMARY KEY auto_increment, NAME VARCHAR ( 255 ), address VARCHAR ( 255 ) );
CREATE TABLE tuser2 ( id INT PRIMARY KEY auto_increment, NAME VARCHAR ( 255 ), address VARCHAR ( 255 ) );
INSERT INTO
test.tuser1(id,NAME,address) VALUES (1, 'zhangfei', 'tianjing');
INSERT INTOtest.tuser1(id,NAME,address) VALUES (2, 'zhaoyun', 'tianjing');
INSERT INTOtest.tuser1(id,NAME,address) VALUES (3, 'guanyu', 'guangzhou');
INSERT INTOtest.tuser1(id,NAME,address) VALUES (4, 'guanyu', 'xian');
INSERT INTOtest.tuser1(id,NAME,address) VALUES (5, 'guanyu', 'jilin');
INSERT INTOtest.tuser1(id,NAME,address) VALUES (6, 'guanyu', 'jilin');
INSERT INTOtest.tuser1(id,NAME,address) VALUES (7, 'guanyu', 'jilin');
INSERT INTOtest.tuser1(id,NAME,address) VALUES (8, 'guanyu', 'jilin');
INSERT INTOtest.tuser1(id,NAME,address) VALUES (9, 'guanyu', 'jilin');
INSERT INTOtest.tuser1(id,NAME,address) VALUES (10, 'guanyu', 'jilin');
INSERT INTOtest.tuser1(id,NAME,address) VALUES (11, '1', '1');
INSERT INTOtest.tuser1(id,NAME,address) VALUES (12, '1', '1');
INSERT INTOtest.tuser1(id,NAME,address) VALUES (13, '1', '1');
INSERT INTOtest.tuser1(id,NAME,address) VALUES (14, '1', '1');
INSERT INTOtest.tuser1(id,NAME,address) VALUES (15, '1', '1');
INSERT INTOtest.tuser1(id,NAME,address) VALUES (16, '1', '1');
INSERT INTOtest.tuser1(id,NAME,address) VALUES (17, '1', '1');
INSERT INTOtest.tuser1(id,NAME,address) VALUES (18, '1', '1');
INSERT INTOtest.tuser1(id,NAME,address) VALUES (19, '1', '1');
INSERT INTOtest.tuser1(id,NAME,address) VALUES (20, '1', '1');
INSERT INTOtest.tuser2(id,NAME,address) VALUES (1, 'zhangfei', 'shandong');
INSERT INTOtest.tuser2(id,NAME,address) VALUES (2, 'zhaoyun', 'shandong');
INSERT INTOtest.tuser2(id,NAME,address) VALUES (3, 'guanyu', 'guangzhou');
INSERT INTOtest.tuser2(id,NAME,address) VALUES (4, 'guanyu', 'shenzhen');
INSERT INTOtest.tuser2(id,NAME,address) VALUES (5, 'guanyu', 'hebei');
INSERT INTOtest.tuser2(id,NAME,address) VALUES (6, 'guanyu', 'jilin');
INSERT INTOtest.tuser2(id,NAME,address) VALUES (7, 'guanyu', 'jilin');
INSERT INTOtest.tuser2(id,NAME,address) VALUES (8, 'guanyu', 'jilin');
INSERT INTOtest.tuser2(id,NAME,address) VALUES (9, 'guanyu', 'jilin');
INSERT INTOtest.tuser2(id,NAME,address) VALUES (10, 'guanyu', 'jilin');
INSERT INTOtest.tuser2(id,NAME,address) VALUES (11, '1', '1');
INSERT INTOtest.tuser2(id,NAME,address) VALUES (12, '12', '1');
INSERT INTOtest.tuser2(id,NAME,address) VALUES (13, '1', '1');
INSERT INTOtest.tuser2(id,NAME,address) VALUES (14, '1', '1');
INSERT INTOtest.tuser2(id,NAME,address) VALUES (15, '1', '1');
INSERT INTOtest.tuser2(id,NAME,address) VALUES (16, '1', '1');
INSERT INTOtest.tuser2(id,NAME,address) VALUES (17, '1', '1');
INSERT INTOtest.tuser2(id,NAME,address) VALUES (18, '1', '1');
INSERT INTOtest.tuser2(id,NAME,address) VALUES (19, '1', '1');
INSERT INTOtest.tuser2(id,NAME,address) VALUES (20, '1', '1');
4.2 需求
tbiguser表按照地区分组统计求和,要求是在tuser1表和tuser2表中出现过的地区
按照需求写出sql
SELECT
count( id ) num,
address
FROM
tbiguser
WHERE
address IN ( SELECT DISTINCT address FROM tuser1 )
GROUP BY
address
UNION
SELECT
count( id ) num,
address
FROM
tbiguser
WHERE
address IN ( SELECT DISTINCT address FROM tuser2 )
GROUP BY
address
执行sql可以看到需要7.026s
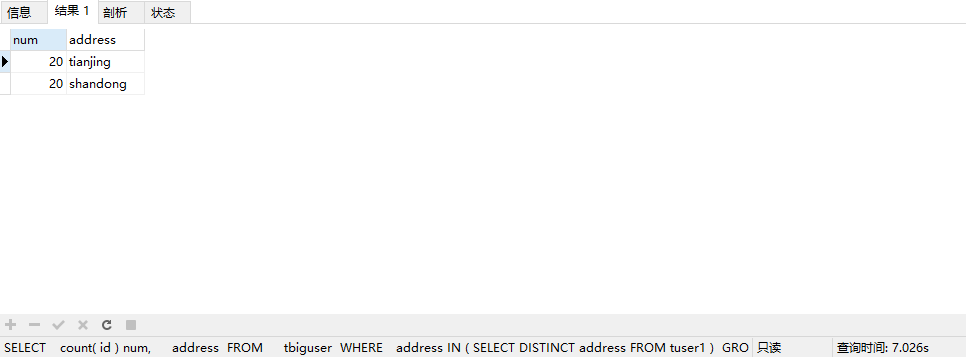
4.3 优化
使用explain查看索引使用情况

type:为ALL 说明没有索引,全表扫描
Using temporary:说明使用了临时表
Using where:用户要的字段不完全覆盖,在Server层进行了全表扫描和过滤
Using join buffer(Block Nested Loop):关联没有索引,有关联优化
可以看到全部都是all,而且还有using temporary这些都是需要优化的。
由于原始sql语句大量使用了address所以我们可以增加索引,第一次优化:在三个表的address字段上都增加normal索引,之后再次执行sql语句
结果是5.657秒
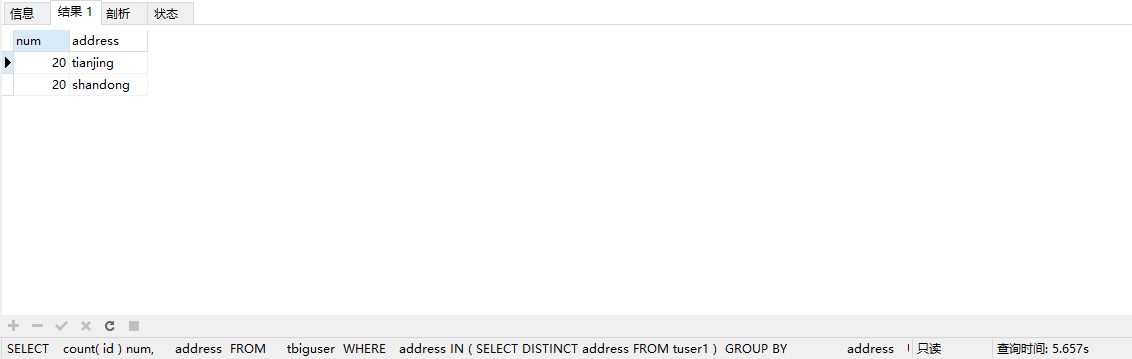
执行explain

Using index ,说明用到了索引 : 覆盖索引
Using temporary :有临时表
Using where :用户要的字段不完全覆盖,在Server层进行了全表扫描和过滤
第二次优化
因为address有索引,所以使用or。
SELECT
count( id ) num,
address
FROM
tbiguser
WHERE
address IN ( SELECT DISTINCT address FROM tuser1 )
OR address IN ( SELECT DISTINCT address FROM tuser2 )
GROUP BY
address
执行sql语句发现用了3.035s
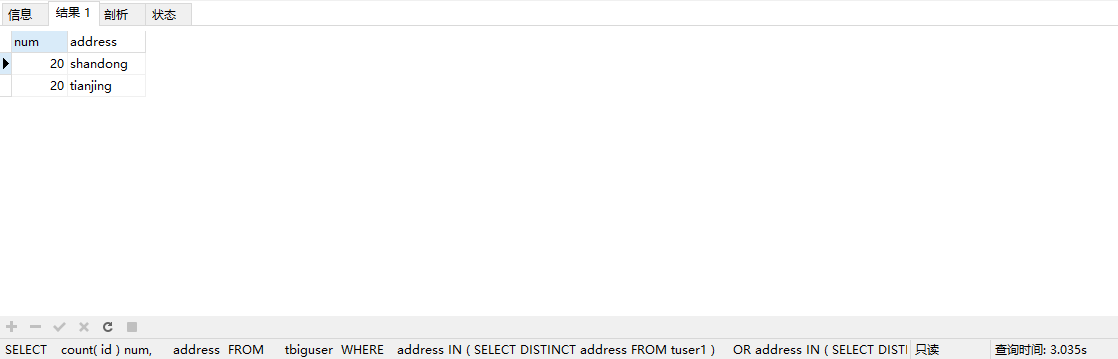
我们在执行explain

type:index
没有了临时表
我们会发现这时没有临时表了,而且对比两次explain发现使用union之后会有两次908万多的查询,而使用or之后只有一次。(这里or两端都是address都是有索引的,所以不会使索引失效)
第三次优化
从第二次优化的explain可以看出,索引只是使用了覆盖索引,rows=908万多,说明还是几乎进行了全表扫描。
所以我们可以利用address做关联,过滤数据
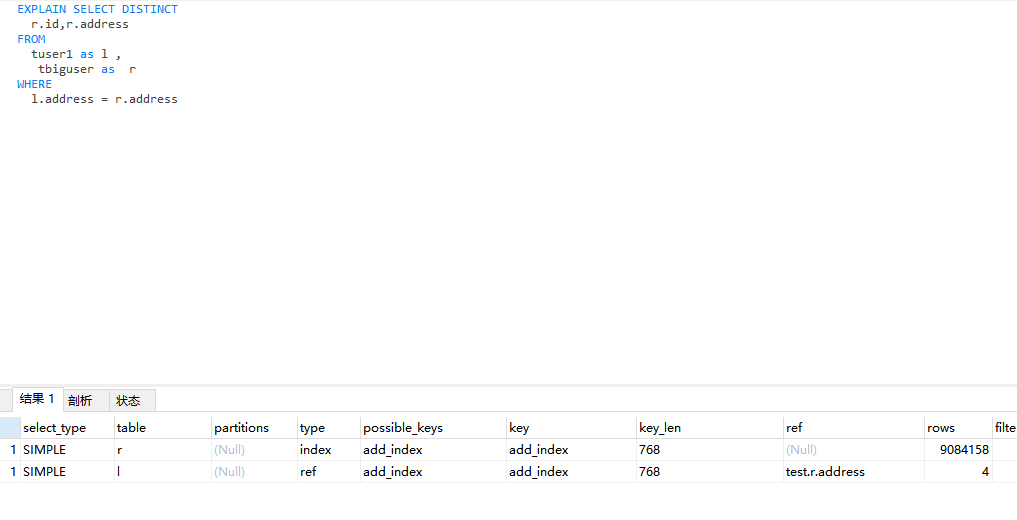
SELECT DISTINCT
r.*
FROM
tuser1 l,
tbiguser r
WHERE
l.address = r.address
执行结果:仅用了0.021s
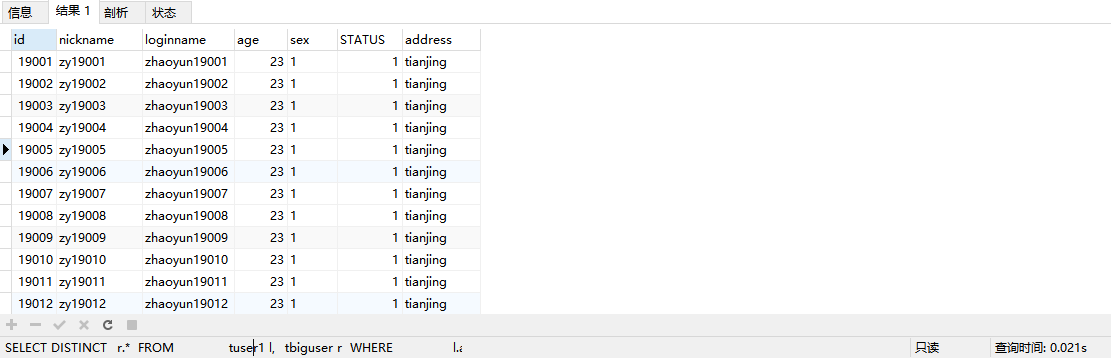
我们对上面的sql语句进行explain

可以看到type=ref且rows=4542079,说明使用了address索引进行了关联
同理对tuser2表也可以这样处理
SELECT DISTINCT
r.*
FROM
tuser2 l,
tbiguser r
WHERE
l.address = r.address
我们对这两次过滤出来的数据进行合并结果集
SELECT DISTINCT
r.*
FROM
tuser1 l,
tbiguser r
WHERE
l.address = r.address
UNION all
SELECT DISTINCT
r.*
FROM
tuser2 l,
tbiguser r
WHERE
l.address = r.address
查询结果:
我们对这个结果集进行分组求和即可
SELECT
count( t.id ),
t.address
FROM
(
SELECT DISTINCT
r.*
FROM
tuser1 l,
tbiguser r
WHERE
l.address = r.address UNION ALL
SELECT DISTINCT
r.*
FROM
tuser2 l,
tbiguser r
WHERE
l.address = r.address
) t
GROUP BY
t.address
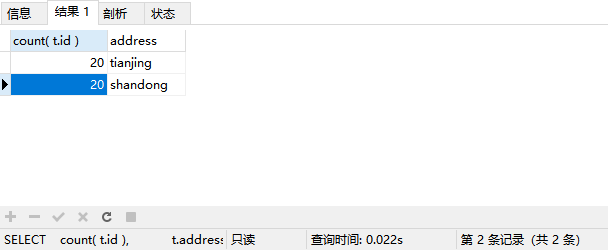
可以看到仅需要0.022s就可以查询到结果。
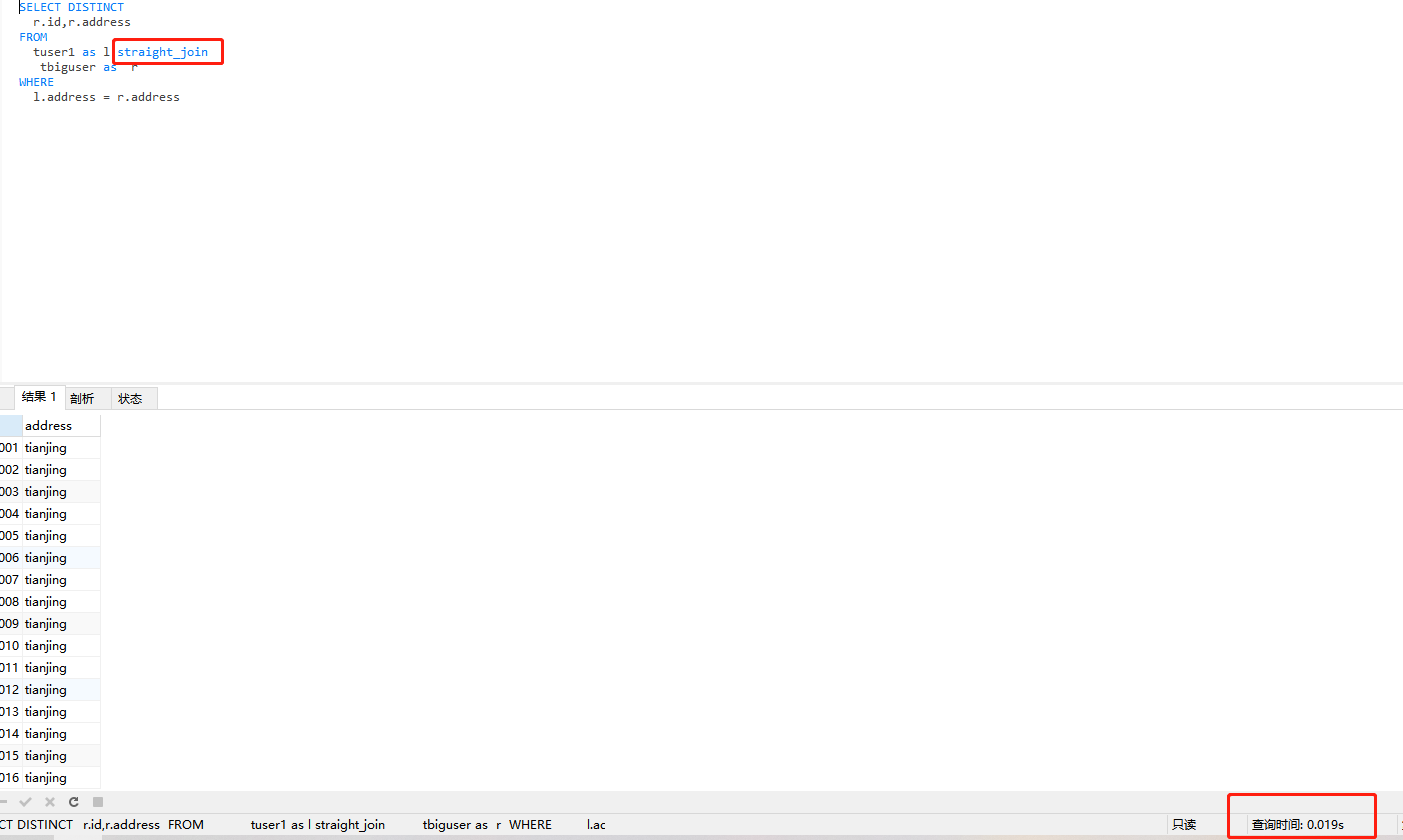
PS:可以使用straight_join强行指定驱动表,因为我重启mysql再次执行第三次优化的sql语句发现内连接查询时,mysql自动使用大表做了驱动表,导致sql语句执行了26s,如下:
所以我强制使用小表做驱动表才解决这个问题。
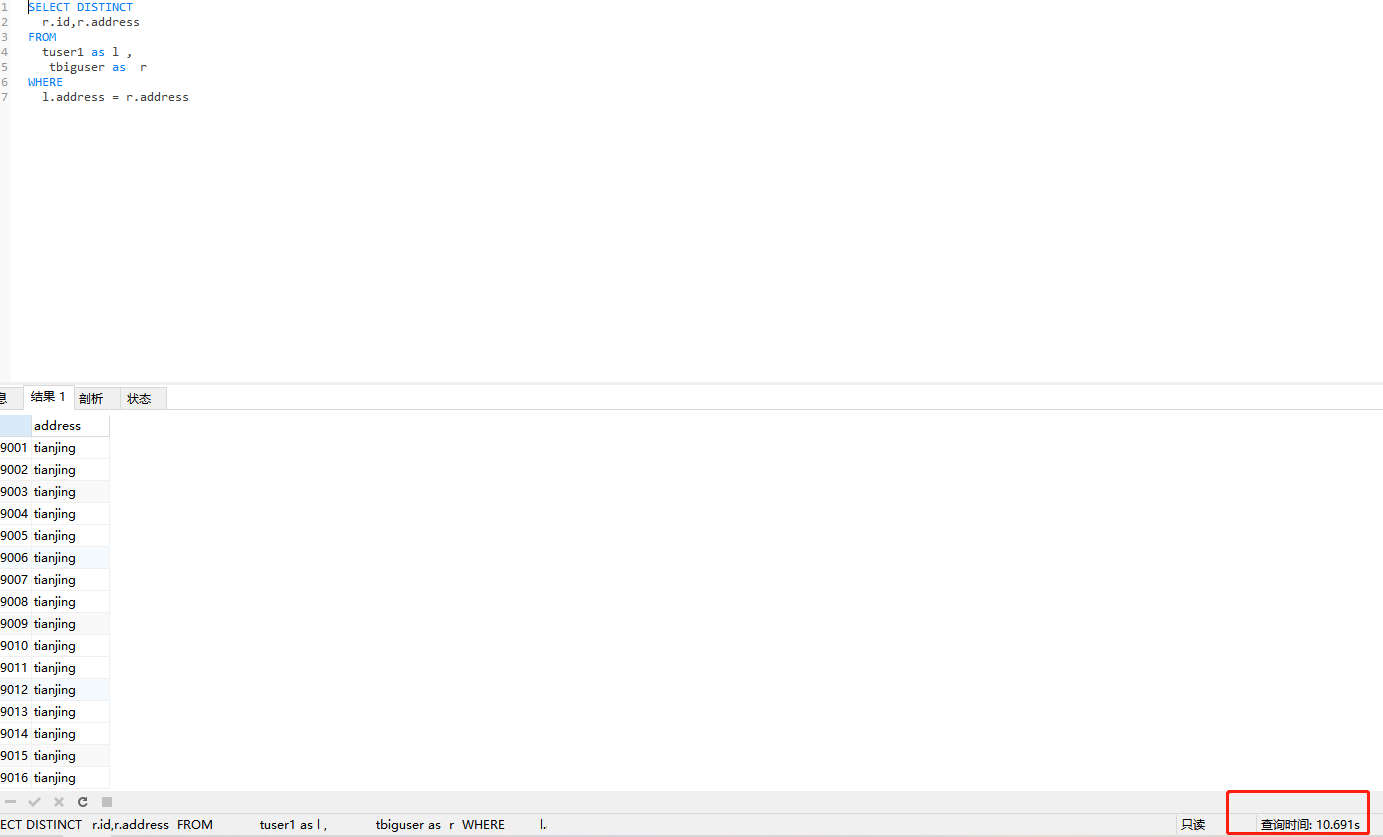
优化总结:
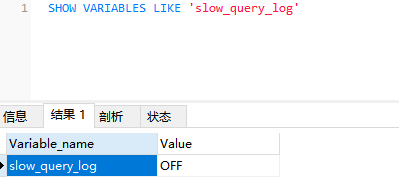
开启慢查询日志,定位运行慢的SQL语句
1.使用
SHOW VARIABLES LIKE 'slow_query_log'查看是否开启慢查询日志
2.设置慢查询日志的位置
set global slow_query_log_file=' /usr/share/mysql/sql_log/mysql-slow.log'3.开启慢查询日志
set global slow_query_log=1;关闭则设置为0
利用explain执行计划,查看SQL执行情况
关注索引使用情况:type
关注Rows:行扫描
关注Extra:没有信息最好
加索引后,查看索引使用情况,index只是覆盖索引,并不算很好的使用索引
如果有关联尽量将索引用到eq_ref或ref级别
复杂SQL可以做成视图,视图在MySQL内部有优化,而且开发也比较友好
对于复杂的SQL要逐一分析,找到比较费时的SQL语句片段进行优化