前言:在调试DPDK时,在发送完一定数量的包后,通过内存统计rte_mempool_count()计算出的值,也就是mempool中剩余的mbuf的数量并没有回升,那么就有一个问题,从mempool中分配的mbuf什么时候才被还回给mempool?没还的部分都在哪?
I.
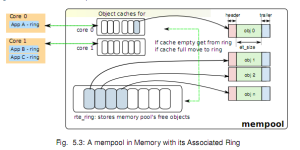
先回答第二个问题,对于多核系统,可能会存在对于mempool的并发访问,虽然DPDK实现了无锁的ring,但无锁的实现是基于CAS(Compare And Set),频繁的访问仍然会影响效率。所以,对于每个核,都可以在创建mempool时,选择为每个核分配Cache,这样,在对应的核上申请和释放mbuf时,就会优先从本地Cache中使用,这样,就会有一部分mbuf驻存在Cache。
II.
同样是出于效率问题,在收发包队列中可以设置长度和一些阈值,tx_free_thresh就是其中一个。具体是因为在网卡硬件读取完发包描述符后,并且DMA完成传送后,硬件会根据发送结果回写标记来通知软件发包过程完成。这样,这些发包描述符就可以释放和再次使用了,对应的mbuf也就可以释放。问题就在这里,如果每次发送完都进行释放,就可能会影响效率,这样,通过设置tx_free_thresh,只有在可以重新分配的发包描述符数量少于tx_free_thresh后,才会释放那些发送完成的描述符和mbuf。所以,可以看出,一部分mbuf驻存在网卡发送队列中。
在知道了Mbuf都被存放在哪后,就知道了何时会被重新放到Mempool。针对存在Cache的情况,可以具体参考官方文档,在Cache,ring,和Mempool的关系中可以找到答案。针对第二种在NIC queue中的情况,则是在低于tx_free_thresh值时释放描述符和Mbuf。
下面给出这个问题的相关的问答对话:
Q: When are mbufs released back to the mempool?
When running l2fwd the number of available mbufs returned by
rte_mempool_count() starts at 7680 on an idle system.
As traffic commences the count declines from 7680 to 5632 (expected).
When traffic stops the count does not climb back to the starting value,
indicating that idle mbufs are not returned to the mempool.
For the LCORE cache the doc states
“While this may mean a number of buffers may sit idle on some core’s cache,
the speedat which a core can access its own cache for a specific memory pool withoutlocksprovides performance gains”which makes sense.
Is this also true of ring buffers?
We need to understand when packets are released back to the mempool and
with l2fwd it appears that they never are, at least not all of them.
Thanks!
On 12/17/2013 07:13 PM, Schumm, Ken wrote:
When running l2fwd the number of available mbufs returned by
rte_mempool_count() starts at 7680 on an idle system.
As traffic commences the count declines from 7680 to
5632 (expected).
A: You are right, some mbufs are kept at 2 places:
in mempool per-core cache: as you noticed, each lcore has
a cache to avoid a (more) costly access to the common pool.
also, the mbufs stay in the hardware transmission ring of the
NIC. Let’s say the size of your hw ring is 512, it means that
when transmitting the 513th mbuf, you will free the first mbuf
given to your NIC. Therefore, (hw-tx-ring-size * nb-tx-queue)
mbufs can be stored in txhw rings.
Of course, the same applies to rx rings, but it’s easier to see
it as they are filled when initializing the driver.
When choosing the number of mbufs, you need to take a value
greater than (hw-rx-ring-size * nb-rx-queue) + (hw-tx-ring-size *
nb-tx-queue) + (nb-lcores * mbuf-pool-cache-size)
Is this also true of ring buffers?
No, if you talk about rte_ring, there is no cache in this
structure.
Regards,
Olivier
Q: Do you know what the reason is for the tx rings filling up and holding on
to mbufs?
It seems they could be freed when the DMA xfer is acknowledged instead of
waiting until the ring was full.
Thanks!
Ken Schumm
A:Optimization to defer freeing.
Note, there is no interrupts with DPDK so Transmit done can not be detected
until the next transmit.
You should also look at tx_free_thresh value in the rte_eth_txconf
structure.
Several drivers use it to control when to free as in:
ixgbe_rxtx.c:
static inline uint16_t
tx_xmit_pkts(void *tx_queue, structrte_mbuf **tx_pkts,
uint16_t nb_pkts)
{
structigb_tx_queue *txq = (structigb_tx_queue *)tx_queue;
volatile union ixgbe_adv_tx_desc *tx_r = txq->tx_ring;
uint16_t n = 0;
/*
Begin scanning the H/W ring for done descriptors when the
number of available descriptors drops below tx_free_thresh. For
each done descriptor, free the associated buffer.
*/
if (txq->nb_tx_free
ixgbe_tx_free_bufs(txq);