1.查询优化
2.慢查询日志
3.批量数据脚本
4.show profile
5.全局查询日志
1.查询优化
- 分析:
1)观察,至少跑一天的慢sql 查询,看看生产的慢sql情况
2)开启慢查询日志,设置阙值(比如超过5秒的sql,就是慢查询sql,并将他抓取出来)。
3)explain + sql 分析
4)show profile
5)运维经理 或 DBA,进行sql数据库服务器参数调优。
- 总结:
1)慢查询的开启并捕获
2)explain + 慢 sql的查询
3)show profile 查询sql 在 mysql 服务器中执行的细节 和生命周期
4)sql 数据库服务器调优
- 永远小表驱动大表
- 类似嵌套循环Nested Loop
- case 热身
- 案例:

- 结论:

- order by 关键字优化
- order by 子句,尽量使用index 排序,避免使用file short排序
建表:
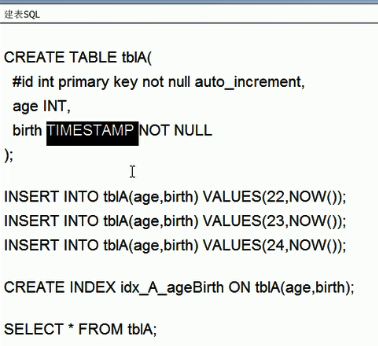
- 案例(正确)

- 结论:使用到 Extra 使用到 using where 和 using index
- 案例(错误)

- 结论:使用到一部分索引,但是 Extra 有严重使用到 fileshort(重新排序)
- MySQL 支持俩种方式的排序,FileSort 和 index,Index 效率高,它指mysql 索引本身完成排序。
- fileSort 方式效率低
- order by 满足俩种情况,会使用Index方式排序:
- order by 语句使用使用索引最左前列
- 使用where 子句 与 order by 子句条件列 组合满足索引最左前列
- 尽可能在索引列上完成排序操作,按照索引创建的最佳左前缀
- 如果索引不在索引列上,file short 有俩种算法:mysql 启动双路排序 和 单路排序 【比较基础,非计算机同学可多看下。】
- 双路排序
- mysql 4.1 版本之前使用双路排序,字面意思 扫描俩次磁盘,最终得到数据。
- 读取行指针order by列对他们进行排序,然后扫描已经排序好的列表.
- 从磁盘读取排序字段在buffer 进行排序,在从磁盘取其他字段。
- 取一批数据对磁盘进行俩次扫描,众所周知,I/O时很耗时的,所以在mysql4.1之后,出现单路排序。
- 单路排序
- 从磁盘读取查询所有列,按照order by列,在buffer 对他们进行排序,然后扫描排序后的列表进行输出。并且把随机IO变成顺序IO,但是它会更多的空间,占用内存比较大。
- 结论延申出的问题
- 由于单路是后出的,总体而言好过双路排序
- 但是用单路排序的问题
- 在short_buffer 中,方法B要比方法A占用的空间更多,因为方法b是把所有的字段都取出,所以有可能取出的数据大于 short buffer的容量,导致每次只能取出short_buffer容量的数据,进行排序(创建tem文件,多路合并)排序完再取short buffer容量的大小,再排……,从而导致多次IO的操作。
- 本来想节省IO操作的,结果导致大量的IO操作。
- 优化策略:
- 增大 short_buffer_ size 参数
- 增大 max_length_for_short_data 参数
- why
- 提高 order by 的速度
- 1)order by时,select * 是大禁忌,只需要query 需要的字段。
- 1.1)当query 字段的大小总和小于 max_length_for_short_data 而且排序字段 TEXT | BLOB类型时,会使用单路排序,否则使用多路排序(老算法)
- 1.2)俩种算法都有可能超过short_buffer 的容量,超出后 会创建tem文件,进行合并排序,导致多次IO,但是用单路排序算法会更大些,所以要提高 short_buffer_ size
- 2)尝试提高 short_buffer_ size
- 不管用那种算法,提高这个参数,都会提高效率,当然,要根据系统能力去提高,因为这个参数是针对每个进程。
- 3)尝试 提高 max_length_for_short_data
- 提高这个参数,会增加使用改进算法的概率。但是如果设置太高,数据总量超出 short_buffer_ size 的概率增大,明显症状高的IO活动和低的处理器使用率。
- 小总结(排序使用索引):

- group by 关键字优化
- group by实质 是先排序后分组,遵照索引创建的最佳左前缀原则
- 当无法使用索引列,增大 max_length_for_short_data 和 short_buffer_ size 参数的设置。
- where 高于having,能写在where 限定的条件就不要去限定having
2.慢查询日志
- 是什么?
- mysql的慢查询日志是 mysql 提供的一种日志记录,它用来记录在 mysql 中响应时间超过阙值的语句,具体指 long_query_time 值的sql,则会被记录到慢查询日志中。
- long_query_time 默认值 10秒
- 结合 explain 进行全面分析
- 怎么玩?
- 说明
MySQL 数据库没有开启慢查询日志(默认),需要手动开启配置参数。
调优需要开启该参数,非调优关闭该参数,因为开启慢查询日志后,会影响性能。
慢查询日志支持将日志记录写入文件。
- 查看是否开启 及 如何开启
- 默认 show variables likes '%show_query_log%'
- 开启 set global show_query_log =1;
- set global show_query_log =1 ; mysql重启后会失效
- 案例:

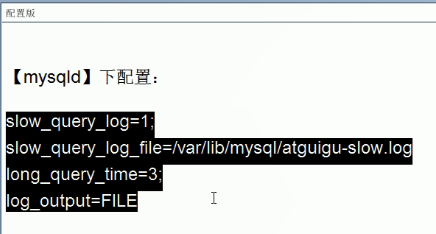
- 慢日志查询永久生效,配置my.cnf 文件
- 添加:

- 关于慢查询的参数 show_query_log_file,它指定慢查询日志文件从放的路径,系统默认会给一个缺省的文件 host_name-slow.log(没有指定 show_query_log_file)。
- 开启慢查询日志后,什么样的sql才会记录到慢查询日志里面

- case
- 查看当前多少秒 算慢sql
- show variables like 'long_query_time'
- 设置慢的阙值时间
- set global long_query_time=3
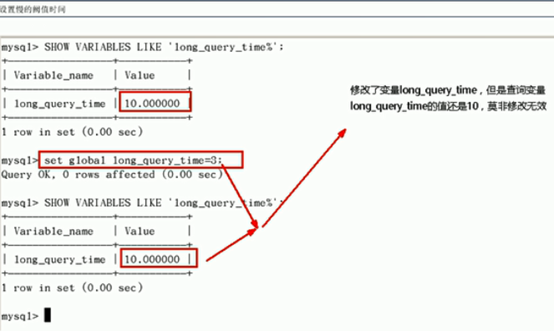
- 为什么设置后,看不出变化
- 需要重新开一个,新的绘画窗口,show variables like 'long_query_time' (查询慢sql的时间)
- show global variables like 'long_query_time';
- 记录慢sql 并后续分析


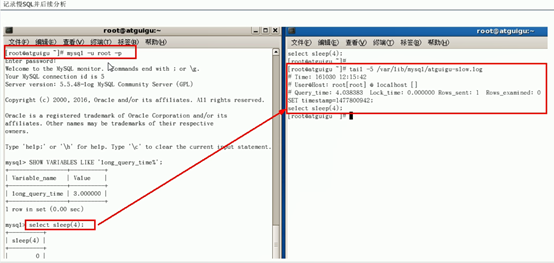
- 查询当前系统中有多少慢sql
- show global status like '%Slow_queries%'

- 配置版 :#永久生效。
- 日志分析工具 mysqldumpslow
- 查看 mysqldumpslow 帮助信息 :mysqldumpslow --help

- 工作常用参考

3.批量数据脚本
- 建表


- 设置log_bin_trust_function_creators


- 创建函数,保证每条记录数据都不同
- 随机产生字符串

- 随机产生部门编号

|
关键字 |
作用 |
|
|
DELIMITER |
表示修改sql结束语句 |
|
|
CREATE FUNCTION |
表示创建函数 |
|
|
DEFAULT |
默认取值 |
|
|
BEGIN |
|
|
|
DECLARE |
定义一个变量 |
|
|
WHILE |
while循环 |
|
|
SET |
|
|
| CONCAT |
连接 |
|
|
END WHILE |
|
|
|
RETURN |
返回值 |
|
|
END $$ |
结束 |
|
|
INT |
数据类型 整型 |
|
|
SUBTHING |
截取字符串 |
|
|
FLOOR |
|
|
|
RAND() |
|
|
- 创建存储过程
- 创建往emp表中插入数据的存储过程

- 创建往dept表中插入数据的存储过程

|
关键字 |
作用 |
|
CREATE PROCEDURE |
|
|
|
|
|
|
|
- 调用存储过程
- dept

- emp

- DELIMITER ;
- CALL insert_emp();
4.show profile
- 是什么?
- 是mysql提供可以用来分析当前会话中语句执行消耗资源的情况。可以用与sql的调优测量。

- 分析步骤:
- 1.是否支持,查看当前mysql版本是否支持

- 2.开启功能,默认关闭

- 查询 ->开启 profilling

- 3.运行sql
- select * from emp group by id%10 limit 150000;
- select * from emp group by id%20 order by 5;
- 4.查看结构,show profile;

- 5.诊断sql,show profile cpu,block io for query 上一步前面的问题sql数字号码;
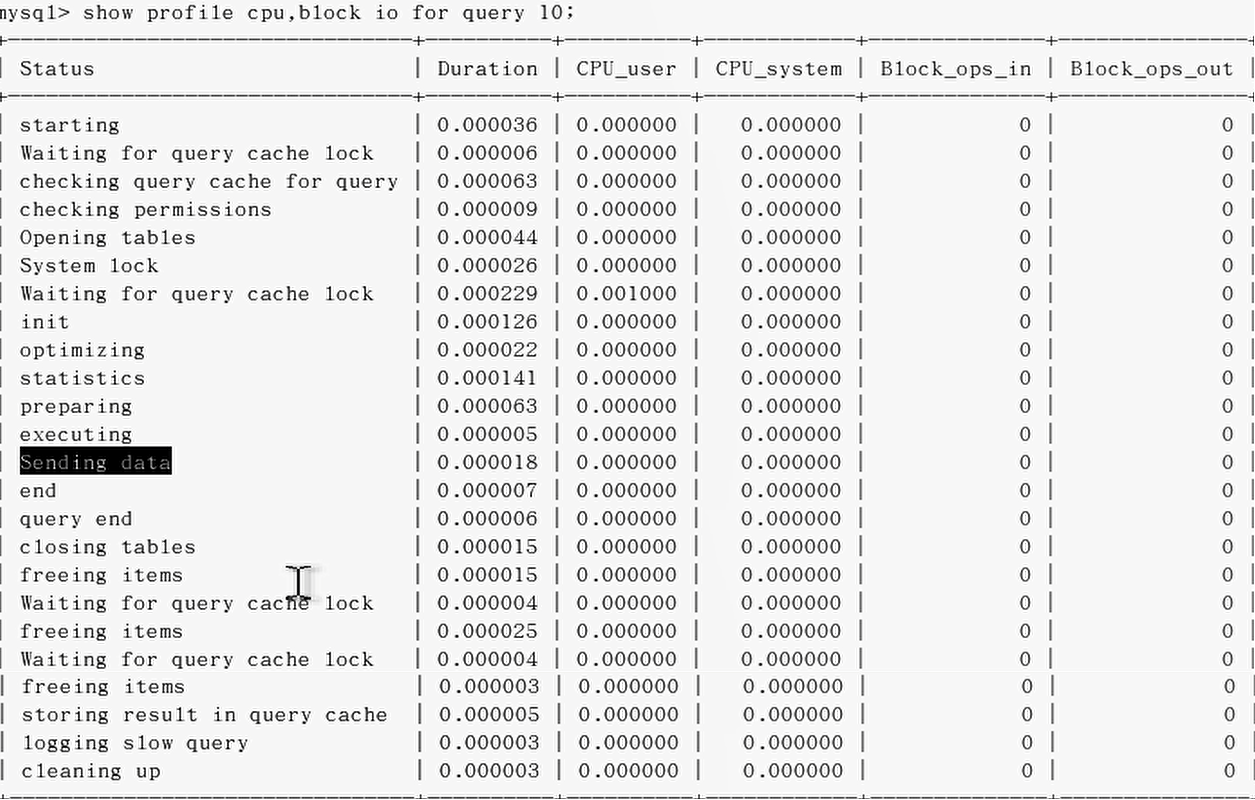
- 参数备注(type)

- 6.日常开发注意的结论
- converting HEAP to MyISAM 查询结果太大,内存都不够用,往磁盘上般。
- Creating tep table 创建临时表

- copying to tep table on disk 把内存中的临时表复制到磁盘,危险!!!
- locked 锁
5.全局查询日志【在测试环境中使用】
- 配置启用

- 编码启用

- 永远不要在生产环境开启这个功能!!!