1.关于python GIL锁
2.多线程与爬虫 -
3.TCP与IO
4.协程
一、python有GIL锁
python拥有GLI锁,无疑对多核CPU下了战书,为了使用多线程课上学习加锁、递归锁、信号量、EVENT等知识点
这里有一点思考,Cpython作为脚本语言,速度没有C快,那对于强类型的JAVA相比呢?
这是一道leecode的题 :

python耗时:
java耗时:
速度天差地别,所以python不适合做计算密集型任务?那么为什么为有人用python做大数据分析和动不动就成百上千亿的科学计算呢?
python的特性在于语法简洁,开发效率高(一个月就能开发出一个网站,不知道比JAVA快了多少)。最关键还有一个胶水特性,它可以使用C/C++的底层功能:numpy,numba,opencv
利用上面的这几个库做了一个会一边播放动画,一边将每一帧图像转换成字符串图像的demo:
(换做没有使用numba之前,图像转成字符串图像需要花费2s,而现在只用不到20ms.)

二、多线程与爬虫
爬虫的基本操作应该是这样:
start_url -> 获取response -> 对页面进行解析 -> 对解析的内容进行处理 ->IO
多线程爬虫可以这样玩:
1.从start_url获取更多url,存放在一个list里
2.开辟新线程,对list里的url,不段进行解析,最后回调给主线程
3.主线程接收回调,进行IO操作
有点类似之后要学习的scrapy,或者说scrapy就是基于这个原理:
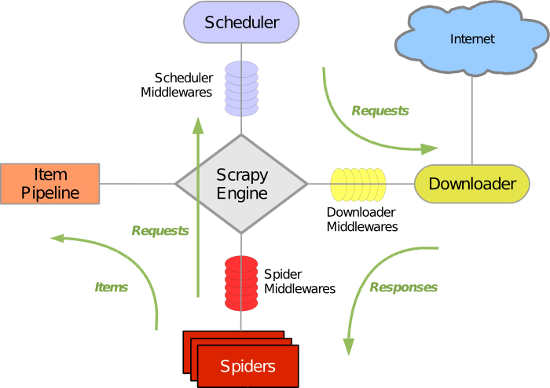
需要注意的是:
1.对服务器造成压力,相当于对服务器进行了攻击
2.有的网站需要遵循robats协议
3.今天课上也说了,有时候需要做一些反爬处理
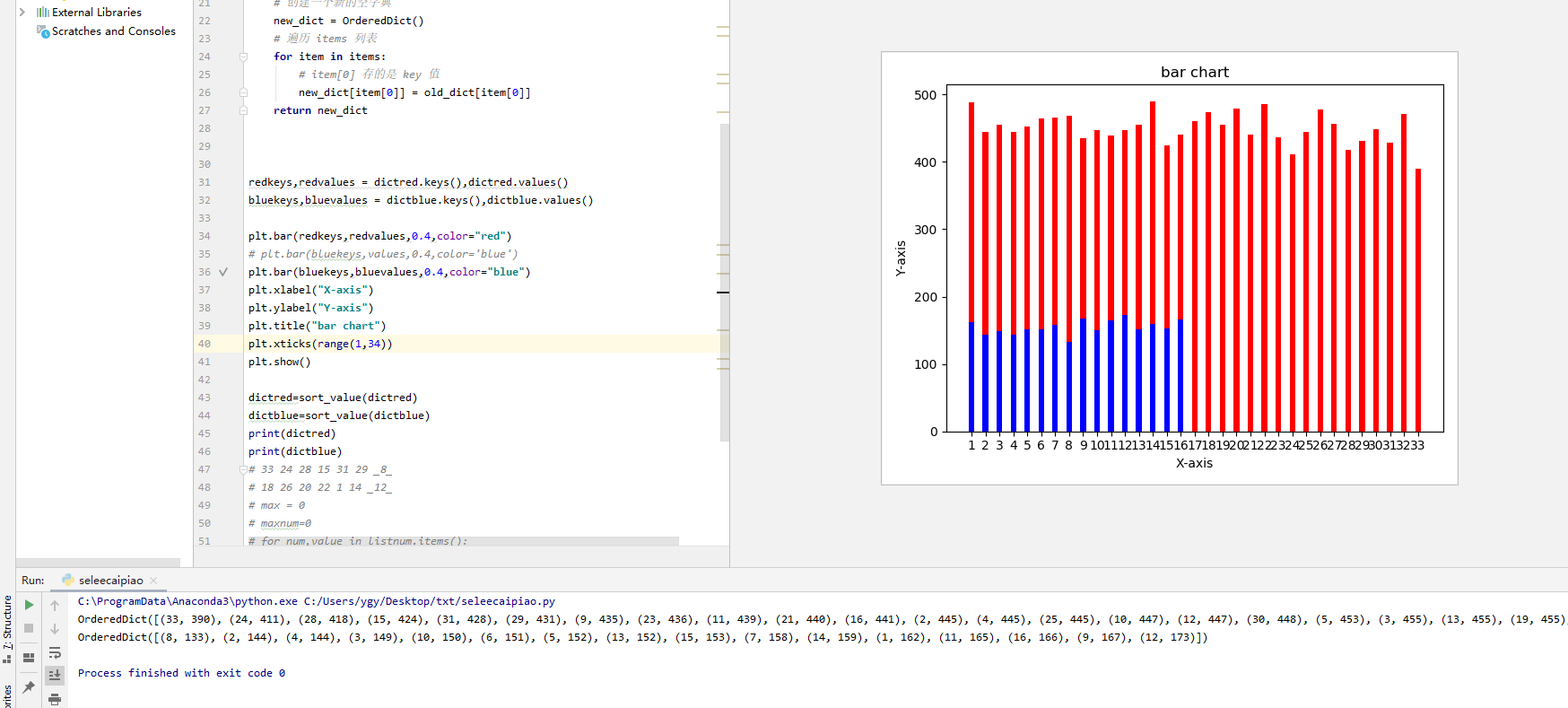
双色球每一个球出现的次数统计,爬虫demo:
三、Tcp(网络编程)与IO处理
之前布置的一个课后作业,要求“Tcp做到多并发”:
阻塞IO:
1.只用多线程解决:开启多线程,响应没有数量限制连接请求,容易造成加死
2.加上了线程池:使用线程池,减少创建和销毁线程的代价,将连接数量控制在一定范围之内
#基础版本 from socket import * server = socket(AF_INET, SOCK_STREAM) server.bind(('127.0.0.1',8081)) server.listen(5) while True: conn, addr = server.accept() print(addr) while True: try: data=conn.recv(1024) if not data:break conn.send(data.upper()) except ConnectionResetError: print("ConnectionResetError") break conn.close() server.close()
在非阻塞式IO中,用户进程其实是需要不断的主动询问kernel数据准备好了没有

从图中可以看出,当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。
四、协程
参考:
如果有几百万条url地址,需要把每个url对应的保存下来,需要怎么做?
1.单线程:如果进行一次网络请求的时间1s,那么运行一次的时间就是几十分钟
2.多线程:线程1遇到阻塞时,CPU可以切换到线程2操作,虽然切换增加了开销时间,但是效率肯定要优于单线程
3.多进程+多线程:如果是多核CPU,那么每个CPU又可以开启多条线程,相比单核,虽然增加了开辟线程的开销
4.多进程+协程:由于协程可以在单核的情况下处理IO问题,避开了对CPU切换的开销,但同时又能把CPU充分利用起来。